基于深度强化学习算法的人群疏散仿真方法及系统与流程
本公开涉及基于深度强化学习算法的人群疏散仿真方法及系统。
背景技术:
本部分的陈述仅仅是提供了与本公开相关的背景技术信息,不必然构成在先技术。
随着经济发展程度的不断提高,人们对于日常生活的安全需求也在不断提高。紧急情况下的人群疏散一直是不可忽视的话题。由于人群内微小的扰动都会对人群的快速疏散造成很大影响,安全隐患较大,如果不能对人群进行有效的控制,很容易导致人群拥挤踩踏事件。为此,通过模拟真实的人群疏散情况,为行人提供合理的疏散方案,制定最佳的疏散路径减少疏散时间,从而提前规避潜在的人群拥堵踩踏风险,具有重要意义。本研究旨在通过制定最佳的路径规划方案,提高疏散效率,预防各种突发情况下的人员伤亡。
人群疏散仿真模型主要有两种,宏观模型和微观模型。宏观模型从整体出发,不考虑个体行为的局部细节信息。微观模型从个体的角度考虑每个个体与环境的交互,可以弥补宏观模型对行人细节描述的不足。关于微观疏散模型,有社会力模型、元胞自动机模型、格子气模型等微观模型分类,它们从单个行人的角度进行建模,考虑到了行人流中个体的种种特征,从而可以更加详细的描述与反映复杂的行人运动。这其中,社会力模型不仅充分考虑到了人群的各种群体行为特征,而且比其他离散模型具有更加真实且精确的结果。但是原始社会力模型并没有考虑到人群疏散中存在的“群组”,“小团体”现象,而且当社会力模型运用于大规模人群疏散仿真时,疏散效率明显下降。
由于传统的微观模型运用在大规模人群疏散仿真时效果不好,所以引入了路径规划来解决这一问题。现阶段的研究大多将强化学习与路径规划结合起来,但由于人群运动是一个连续的过程,所以使用强化学习进行仿真时,会产生维度爆炸问题导致算法效率下降。深度强化学习不仅继承了强化学习的优点,还在其基础上引入了神经网络使其可以解决具有高维度状态空间的决策问题,使其相较于强化学习可以更加适用于人群疏散的应用。其中最为典型的就是多智能体深度确定性策略梯度算法(multi-agentdeepdeterministicpolicygradient),但是由于算法的复杂性过高,导致算法的收敛速度较慢,并且由于环境的复杂性,算法很难得到一个良好的结果。
技术实现要素:
本公开为了解决上述问题,提出了基于深度强化学习算法的人群疏散仿真方法及系统,在原本的多智能体深度确定性策略梯度算法的基础上引入对策略进行优化的交叉熵方法(cross-entropymethod)与对样本进行优化的数据剪枝算法(datapruningalgorithm),优化了算法的结果,加快了算法的收敛速度,能够更好地指导人群进行疏散,提高疏散效率。
为实现上述目的,本公开采用如下技术方案:
在一个或多个实施例中,提出了基于深度强化学习算法的人群疏散仿真方法,包括:
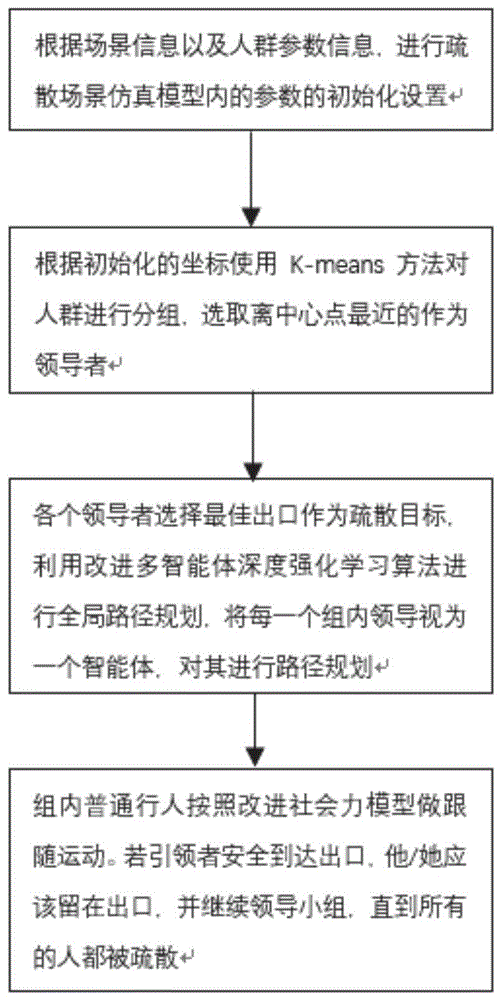
根据场景信息以及人群参数信息,进行疏散场景仿真模型内的参数的初始化设置;
对人群进行分组,并划分组内领导者;
各领导者选取最佳出口作为疏散目标,利用改进多智能体深度确定性策略梯度算法进行全局路径规划,获取最优疏散路径;
组内普通行人跟随该组内领导者运动。
进一步的,将每一组领导者视为智能体,利用改进多智能体深度确定性策略梯度算法进行全局路径规划,包括:
设定智能体的可移动方向和当前位置;
设定critic网络的奖励回报机制,对智能体的选择给与相应奖励;
每个智能体对应一个actor网络与一个critic网络,设置单独的经验池存放所有智能体每一步的经验,
训练critic网络和actor网络的模型参数,使用n个回合重复训练步骤,以智能体获取的回报值最大为目标,直至训练出每个智能体的优化路径;
对智能体的优化路径进行策略优化,获取最优疏散路径。
进一步的,在训练过程中,使用数据剪枝算法对经验池进行优化。
进一步的,采用交叉熵方法对智能体的优化路径进行策略优化,获取最优的疏散路径。
在一个或多个实施例中,提出了基于策略优化的深度强化学习算法的人群疏散仿真系统,包括:
初始化设置模块,根据场景信息以及人群参数信息,进行疏散场景仿真模型内的参数的初始化设置;
组内领导选取模块,实现对人群进行分组,选取组内领导者;
疏散仿真模块,以每个领导者选取最佳出口作为疏散目标,利用改进多智能体深度确定性策略梯度算法进行全局路径规划,获取最优疏散路径,组内普通行人跟随公该组内领导者运动。
在一个或多个实施例中,提出了一种电子设备,包括存储器和处理器以及存储在存储器上并在处理器上运行的计算机指令,所述计算机指令被处理器运行时,完成基于深度强化学习算法的人群疏散仿真方法所述的步骤。
在一个或多个实施例中,提出了一种计算机可读存储介质,用于存储计算机指令,所述计算机指令被处理器执行时,完成基于深度强化学习算法的人群疏散仿真方法所述的步骤。
与现有技术相比,本公开的有益效果为:
1、本公开考虑到现实情况中人群疏散过程人们存在的从众心理以及兴奋程度对人群的影响,将群组聚合力以及兴奋度的概念引入社会力模型中,与以往的模型相比,改进的社会力模型考虑了行人在疏散运动中的心理变化,使疏散仿真更加真实。
2、本公开考虑到人群疏散大规模计算的难度,采用分组与选择组中领导的方法,由改进的多智能体深度确定性策略梯度算法对领导者进行全局路径规划,组内行人使用改进后的社会力模型进行跟随运动,大大减少了计算量。
3、本公开将数据剪枝算法应用到多智能体深度确定性策略梯度算法中,提高了算法的性能,并通过加入交叉熵方法对算法策略进行优化,提高了算法的收敛速度,优化了算法的结果,提高了人群疏散的效率。
附图说明
构成本申请的一部分的说明书附图用来提供对本申请的进一步理解,本申请的示意性实施例及其说明用于解释本申请,并不构成对本申请的不当限定。
图1为本公开实施例1的流程图;
图2为本公开实施例1中改进多智能体深度确定性策略梯度算法的学习结构示意图;
图3为本公开实施例1人群疏散仿真场景图;
图4为本公开实施例1人群初始化后人群的随机分布情况图;
图5为本公开实施例1人群疏散示意图;
图6为本公开实施例1人群疏散接近出口的移动示意图。
具体实施方式:
下面结合附图与实施例对本公开作进一步说明。
应该指出,以下详细说明都是例示性的,旨在对本申请提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本申请所属技术领域的普通技术人员通常理解的相同含义。
需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本申请的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。
在本公开中,术语如“上”、“下”、“左”、“右”、“前”、“后”、“竖直”、“水平”、“侧”、“底”等指示的方位或位置关系为基于附图所示的方位或位置关系,只是为了便于叙述本公开各部件或元件结构关系而确定的关系词,并非特指本公开中任一部件或元件,不能理解为对本公开的限制。
本公开中,术语如“固接”、“相连”、“连接”等应做广义理解,表示可以是固定连接,也可以是一体地连接或可拆卸连接;可以是直接相连,也可以通过中间媒介间接相连。对于本领域的相关科研或技术人员,可以根据具体情况确定上述术语在本公开中的具体含义,不能理解为对本公开的限制。
实施例1
在该实施例中,公开了基于深度强化学习算法的人群疏散仿真方法,包括:
根据场景信息以及人群参数信息,进行疏散场景仿真模型内的参数的初始化设置;
对人群进行分组,并划分组内领导者;
各领导者选取最佳出口作为疏散目标,利用改进多智能体深度确定性策略梯度算法进行全局路径规划,获取最优疏散路径;
组内普通行人跟随该组内领导者运动。
进一步的,将每一组领导者视为智能体,利用改进多智能体深度确定性策略梯度算法进行全局路径规划,包括:
设定智能体的可移动方向和当前位置;
设定critic网络的奖励回报机制,对智能体的选择给与相应奖励;
每个智能体对应一个actor网络与一个critic网络,设置单独的经验池存放所有智能体每一步的经验,
训练critic网络和actor网络的模型参数,使用n个回合重复训练步骤,以智能体获取的回报值最大为目标,直至训练出每个智能体的优化路径;
根据获得的智能体的优化路径对改进多智能体深度确定性策略梯度算法进行策略优化;
利用优化后策略,获取智能体的最优疏散路径。
进一步的,在训练过程中,使用数据剪枝算法对经验池进行优化,具体为:计算输入经验池的一组数据的唯一性值,当计算的唯一性值大于设定阈值时,将该组数据输入经验池,当计算的唯一性值小于设定阈值时,将该组数据舍弃。
进一步的,采用交叉熵方法对改进多智能体深度确定性策略梯度算法进行策略优化的过程为:
将获得的每个智能体的优化路径,生成一个策略;
将生成的策略作为高斯分布的初始均值,计算高斯分布的期望,根据高斯分布的期望选取智能体的动作样本;
将高斯分布的期望和智能体的动作样本输入至critic网络中得到一个q函数值,根据q函数值从动作样本中选取精英样本,通过精英样本对高斯分布的期望和方差进行更新,实现改进多智能体深度确定性策略梯度算法的策略优化。
进一步的,采用k-means方法对人群进行分组,选取最接近群组中心点的个体为领导者。
进一步的,组内普通行人按照改进社会力模型跟随领导者运动,当领导者到达出口时,留在出口继续领导小组,直到所有的人都被疏散。
进一步的,当最终出口的疏散人数等于总人数时疏散过程结束,并实时存储疏散人群总数、疏散时间和人群疏散路径。
对基于深度强化学习算法的人群疏散仿真方法的具体步骤进行详细说明。
(1)根据场景信息以及人群参数信息,进行疏散场景仿真模型内的参数的初始化设置,如图3、图4所示。
根据设置的疏散场景参数信息,采用模型设计软件创建疏散场景模型和人物模型,将人物模型导入疏散场景模型中,形成场景仿真模型,并对创建的疏散场景模型进行渲染,其中,疏散场景模型为二维场景模型,包括疏散场景的所有房间和出口。
(2)使用k-means方法对人群进行划分,根据疏散人数将人群划分为γ组,并选择群组中最靠近中心点的个体作为领导者。
(3)各个领导者选择最佳出口作为疏散目标,将每一个组内领导视为一个智能体,利用改进多智能体深度确定性策略梯度算法对其进行全局路径规划。
其中,使用改进多智能体深度确定性策略梯度算法进行全局路径规划的具体操作如下:
设定智能体的可移动方向和当前位置:设定智能体的当前位置为智能体在场景里面的具体坐标;设定智能体的下一步移动方向可表示为(x,y),即智能体下一步移动方向的向量表示;
设定critic网络的奖励回报机制:各智能体与障碍物间的距离大于设定距离,则各个组内领导者从critic网络处得到的回报奖励为正值,若小于等于设定距离则给予的回报奖励为负值;如果智能体在最后找到整个疏散区域的最终出口,给予相应的奖励为正值,否则,给予相应的奖励为负值。
每一个智能体都对应两个神经网络,分别是actor网络与critic网络,设置单独的经验池来存放所有智能体每一步的经验,即{当前状态x,当前动作a1,...,an,奖励回报r1,...,rn,下一步的状态x_},其中x=(o1,o2,...,on),包含了所有智能体的观测状态,将经验池中的数据输入进神经网络来模拟q函数,使结果可以被精准的预测出来。
actor网络与critic网络分别用来计算q网络与策略网络的梯度,其中actor网络与critic网络都由两个结构相同,参数更新时间不同的网络构成,一个叫做online网络,一个叫做target网络。actor网络的两个网络参数表示为θq与θq′,critic网络的两个网络参数表示为θμ与θμ′,初始化θq与θμ参数,并将其复制到对应的θq′与θμ′中去,初始化经验池。
actor根据当前一组状态x输出一组动作值a,输入到环境中让它执行得到一个回报值r与下一个状态x_,将这一组数据{x,a1,...,an,r1,...,rn,x_}与经验池中的数据进行比对,如果相似度过高则舍弃这一组数据,否则将数据存入经验池中去作为online网络训练的数据集。再从经验池中随机采样n个数据作为online网络的一个小批量训练数据。
计算targetq值y,再通过y值计算均方差损失函数l(θi):
其中x=(o1,o2,...,on),i为第i次更新,包含了所有智能体的观测状态,
由于target网络参数是延迟更新,所以加入平衡因子τ的更新公式为:
训练actor网络与critic网络的模型参数,重复n个回合训练步骤,直至训练出多智能体的优化路径或达到最大迭代步数。
将获得的多智能体的优化路径,生成一个策略μ=πθ(s),计算其高斯分布n(μ,σ2),并从其中选出t个动作样本(a1,...,at),将动作样本集输入进critic网络进行评估,然后对策略进行优化,更新μ与σ:
将算法得到的策略进行输出,为最优疏散路径,得到一个全局的路径规划。
由于,经验池中的数据经过多轮训练之后具有重复性,而神经网络训练需要的是具有较大差异性的数据,所以本实施例使用数据剪枝算法对输入进经验池的数据进行处理。
当一组数据ei={x,a1,...,an,r1,...,rn,x_}产生时,我们计算其唯一性值ui,即:
其中ej为经验池中的其他经历,d为当前经验池的大小,s为一个距离函数,当唯一性值ui大于设定的阈值p时,判定它可以被输入进经验池;当ui小于设定的阈值p时,判定它不可以被输入进经验池。
由于多智能体深度确定性策略梯度算法在复杂环境下经过训练得出来的方法有时不能符合期望,所以我们引入交叉熵方法对算法的策略进行优化,并使用critic网络对结果进行更准确的评估。
当算法训练完成时,初始化σ2,使用算法得出来的确定性策略μ=πθ(s),针对每一个智能体计算其高斯分布n(μ,σ2),并从其中选出t个动作样本(a1,...,at);令a={μ}∪{a1,...,at},将a输入critic网络得到一个q函数
其中,
由于原本的多智能体深度确定性策略梯度算法存在算法复杂度高,收敛速度慢的问题,此外由于环境的复杂性,导致了算法可能无法得到理想的结果,所以本实施例在原本的多智能体深度确定性策略梯度算法的基础上引入对策略进行优化的交叉熵方法(cross-entropymethod)与对样本进行优化的数据剪枝算法(datapruningalgorithm),优化了算法的结果,加快了算法的收敛速度。改进多智能体深度确定性策略梯度算法的学习结构如图2所示。
(4)组内普通行人按照改进社会力模型做跟随运动,如图5所示。若引领者安全到达出口,他/她应该留在出口,并继续领导小组,直到所有的人都被疏散,如图6所示。其中使用的改进社会力模型的描述如下:
利用改进社会力模型计算组员与领导、组员与组内其他组员、组员与其他组的组员以及组员与环境的受力,进行运动的具体公式为:
其中,
我们在原始社会力公式里加入
改进了行人的实时期望速度
其中,x1、x2均为0到1之间的正常数,并且x1+x2=1。g(x)是分段函数,
所以期望速度的实时更新公式为:
群组聚合力公式如下:
其中,ci与di是聚合参数,表示个体之间的吸引力强度和行人之间的安全距离。rij是行人i与行人j之间的聚合概率;
σ值越大代表行人之间的关系越密切,rij是一个二维数组记录了行人i与j之间的关系值。聚合力由聚合概率加权来计算。聚合力的值越大,行人聚集的速度越快,聚集的距离越近。
最后当引领者安全到达出口,他/她应该留在出口,并继续领导小组,直到所有的人都被疏散。
本实施例的总体思路:根据场景信息以及人群参数信息,进行疏散场景仿真模型内的参数的初始化设置;使用k-means方法对人群进行分组,选取离群组中心点最近的作为领导者;各个领导者选择最佳出口作为疏散目标,利用改进多智能体深度确定性策略梯度算法进行全局路径规划,将每一个组内领导视为一个智能体,对其进行路径规划,,组内普通行人按照改进社会力模型做跟随运动,若引领者安全到达出口,他/她应该留在出口,并继续领导小组,直到所有的人都被疏散。
将数据剪枝算法应用到多智能体深度确定性策略梯度算法中,提高了算法的性能,并通过加入交叉熵方法对算法进行优化,提高了算法的收敛速度,优化了算法的结果,提高了人群疏散的效率。
考虑到现实情况中人群疏散过程人们存在的从众心理以及兴奋程度对人群的影响,将群组聚合力以及兴奋度的概念引入社会力模型中,与以往的模型相比,改进的社会力模型考虑了行人在疏散运动中的心理变化,使疏散仿真更加真实。
考虑到人群疏散大规模计算的难度,采用分组与选择组中领导的方法,由改进的多智能体深度确定性策略梯度算法对领导者进行全局路径规划,组内行人使用改进后的社会力模型进行跟随运动,大大加少了计算量。
实施例2
在该实施例中,公开了基于策略优化的深度强化学习算法的人群疏散仿真系统,包括:
初始化设置模块,根据场景信息以及人群参数信息,进行疏散场景仿真模型内的参数的初始化设置;
组内领导选取模块,实现对人群进行分组,选取组内领导者;
疏散仿真模块,以每个领导者选取最佳出口作为疏散目标,利用改进多智能体深度确定性策略梯度算法进行全局路径规划,获取最优疏散路径,组内普通行人跟随该组内领导者运动。
实施例3
一种电子设备,包括存储器和处理器以及存储在存储器上并在处理器上运行的计算机指令,所述计算机指令被处理器运行时,完成实施例1公开的基于深度强化学习算法的人群疏散仿真方法所述的步骤。
实施例4
一种计算机可读存储介质,用于存储计算机指令,所述计算机指令被处理器执行时,实施例1公开的基于深度强化学习算法的人群疏散仿真方法所述的步骤。
以上仅为本申请的优选实施例而已,并不用于限制本申请,对于本领域的技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本申请的保护范围之内。
上述虽然结合附图对本公开的具体实施方式进行了描述,但并非对本公开保护范围的限制,所属领域技术人员应该明白,在本公开的技术方案的基础上,本领域技术人员不需要付出创造性劳动即可做出的各种修改或变形仍在本公开的保护范围以内。
- 还没有人留言评论。精彩留言会获得点赞!