一种基于深度学习的短期水质水量预测方法及系统与流程
本发明涉及水环境保护与监测技术领域;尤其涉及一种基于深度学习的短期水质水量预测方法及系统。
背景技术:
水是人类社会最重要的资源之一,目前我国的黄河、松花江、淮河流域均存在轻度污染,而海河、辽河流域部分地区处于重度污染状态,及时的对水质水量进行预测,能够提前获知水质污染的可能性,以及水流量的异常,有助于及时发现区域内的水环境问题,为管理和维护当地水源地的水环境状况提供重要依据,也是近年来水环境保护和监测领域的研究热点之一。
目前国内对于水质水量预测的方法主要有:时间序列预测法、回归分析预测法、灰色系统预测法、数理统计预测法、人工神经网络预测法等,相对于其他4种方法,人工神经网络预测法凭借其可以摒弃客观因素的影响,只根据样本水质水量自身特点进行分析学习的优点在水质水量预测领域得到了广泛应用,目前常用的人工神经网络预测方法包括:bp神经网络、径向基函数神经网络、广义神经网络等。
河流水质水量变化具有渐变性、非线性、不稳定性以及复杂性等特点,目前运用于水质水量预测的神经网络模型,例如bp神经网络、径向基函数神经网络、广义神经网络在进行复杂时间序列预测时容易陷入局部最优。同时由于水质水量数据序列表现出的强非线性特征和弱线性特征,单一的预测模型对水质水量的弱线性特征难以充分处理,需要结合其他线性算法。
公开号为cn111027776a的发明专利申请公开了一种基于改进型长短期记忆lstm神经网络的污水处理水质水量预测方法,其通过对污水数据进行处理,构建lstm神经网络模型从而对待预测数据进行预测处理,得到水质情况,这种方法适用于解决长时间跨度水质时间序列预测,仅能有效表征水质时间序列中的非线性特征,但是自然水环境的水质时间序列同时具有强非线性特征和弱线性特征,且水质水量预测方面要求高时效性与及时性,而短期水质水量预测相较于长期水质水量预测更能及时预警水污染事件的发生。
技术实现要素:
本发明所要解决的技术问题在于提供一种基于长短期记忆神经网络对自然水环境进行短期水质水量预测的方法,以克服水质水量数据序列的强非线性特征和弱线性特征对水质水量预测技术的限制。
本发明是通过以下技术方案解决上述技术问题的:一种基于深度学习的短期水质水量预测方法,包括以下步骤:
步骤a:对原始水质水量数据进行预处理,将处理后的数据划分为训练集和测试集;
步骤b:将训练集输入lstm网络中进行训练,使用adam算法更新遗忘门、输入门和输出门的权重,以损失函数值和迭代次数作为训练终止条件,得到预测模型;
步骤c:基于原始水质水量数据使用预测模型预测测试集对应的预测值,并根据实际值与预测值计算预测误差;
步骤d:将预测误差输入arma模型中得到误差序列的误差修正模型;
步骤e:将待预测数据分别输入步骤b得到的预测模型和步骤d得到的误差修正模型,将结算结果几何相加得到预测值。
本发明通过lstm模型,充分挖掘水质水量数据之间的相互关联性,通过遗忘门、输出门等节点之间的结构,解决了传统神经网络方法在训练过程中由于长时间跨度数据的学习出现的梯度消失和梯度爆炸的问题。另一方面,由于水质水量数据序列呈现强非线性特征和弱线性特征,单一的预测模型难以充分处理水质水量的弱线性特征,需要结合其他的算法,而arma模型的特征可以作为lstm模型在处理线性数据的有效补充,lstm模型与arma模型相结合的方法,在单一预测模型的基础之上,具备更强的通用性和稳定性,使得水质水量预测结果更为稳健。
优选的,步骤a所述的原始水质数据包括物理指标,常规水质指标、金属含量、无机物含量、有机物含量、微生物含量、辐射量、水位、液位、流量、流速;原始水质数据的集合为以时序排列的参数集合。
优选的,步骤a所述的预处理包括缺失值处理和归一化处理,
所述缺失值处理的方式为使用之前两个时刻的平均值填充缺失值;
所述归一化处理的方法为:
其中,xt为t时刻的原始参数,xmin为序列中参数的最小值,xmax为序列中参数的最大值,xt为归一化后t时刻的参数;
预处理完成后按时序排列,以前70%作为训练集,后30%作为测试集。
优选的,所述lstm神经网络的计算公式为:
ft=σ(wf·[ht-1,xt]+bf)
it=σ(wi·[ht-1,xt]+bi)
ot=σ(wo·[ht-1,xt]+bo)
其中,h为lstm神经网络的输出,训练中以后一时刻的水质水量数据作为前一时刻水质水量数据的输出;f、i、o分别表示遗忘门、输入门和输出门;σ表示sigmoid函数,w和b分别表示权重和偏差矩阵;
损失函数为平均绝对误差,预设训练的最大迭代次数和损失函数值的阈值,通过adam算法更新权重,每次更新权值之后计算损失函数值,如果损失函数值小于等于阈值或训练次数达到最大迭代次数,则训练结束,将权重代入以上公式,计算出偏差矩阵;得到所述预测模型。
优选的,步骤c中根据原始水质水量数据使用预测模型计算测试集对应的预测数据,计算预测误差的公式为:
其中,yt为测试集的实际值,
优选的,步骤d中将测试集的预测误差σt输入arma模型,经过训练得到误差修正模型;对于待预测时刻的水质水量,使用步骤b中的预测模型计算预测值
其中,zt为待预测时刻的预测值。
本发明还提供了一种基于深度学习的短期水质水量预测系统,包括
预处理模块:对原始水质水量数据进行预处理,将处理后的数据划分为训练集和测试集;
预测模型训练模块:将训练集输入lstm网络中进行训练,使用adam算法更新遗忘门、输入门和输出门的权重,以损失函数值和迭代次数作为训练终止条件,得到预测模型;
预测误差计算模块:基于原始水质水量数据使用预测模型预测测试集对应的预测值,并根据实际值与预测值计算预测误差;
误差修正模型训练模块将预测误差输入arma模型中得到误差序列的误差修正模型;
计算模块:将待预测数据分别输入预测模型和误差修正模型,将结算结果几何相加得到预测值。
本发明提供的基于深度学习的短期水质水量预测方法及系统的优点在于:通过lstm神经网络和arma模型分别对待预测时刻的水质水量和预测误差进行计算,克服了由于水质水量历史数据序列的强非线性特征以及弱线性特征而无法进行有效预测的问题,通过lstm模型,充分挖掘水质水量数据之间的相互关联性,通过遗忘门、输出门等节点之间的结构,解决了传统神经网络方法在训练过程中由于长时间跨度数据的学习出现的梯度消失和梯度爆炸的问题。另一方面,由于水质水量数据序列呈现强非线性特征和弱线性特征,单一的预测模型难以充分处理水质水量的弱线性特征,需要结合其他的算法,而arma模型的特征可以作为lstm模型在处理线性数据的有效补充,lstm模型与arma模型相结合的方法,在单一预测模型的基础之上,具备更强的通用性和稳定性,使得水质水量预测结果更为稳健;相对于现有技术不仅能够表征自然水域水质水量时间序列中的非线性特征,同时也能表征水质水量时间序列中的线性特征。
附图说明
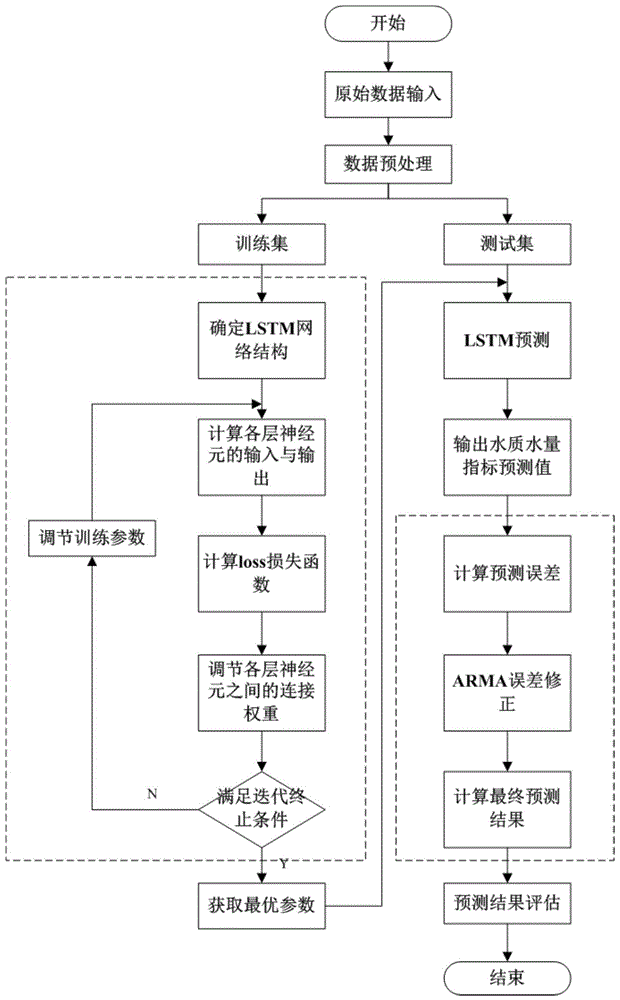
图1为本发明的实施例提供的基于深度学习的短期水质水量预测方法的流程图;
图2为本发明的实施例提供的基于深度学习的短期水质水量预测方法的效果对比图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本发明作进一步的详细说明。
如图1所示,本实施例提供了一种基于深度学习的短期水质水量预测方法,其中,短期水质水量预测是指水质水量监测时间比较短的时间序列预测,本实施例中所用水质水量时间序列监测频率为4h/次,从而能够及时的对水污染情况进行预警发现,具体包括以下步骤:
步骤a:对原始水质水量数据进行预处理,将处理后的数据划分为训练集和测试集;
其中,原始水质水量数据包括物理指标,常规水质指标、金属含量、无机物含量、有机物含量、微生物含量、辐射量、水位、液位、流量、流速;具体的,物理指标包括水温、ph、透过率、悬浮物、浊度;常规水质指标包括溶解氧含量、高锰酸盐指数、化学需氧量、五日生化需氧量、氨氮含量、总磷含量、总氮含量;金属含量包括铜、铁、锌、汞、铬、铅;无机物含量包括氟化物、卤化物、磷酸盐类、硫化物;有机物含量包括氰化物、挥发酚、石油类、阴离子表面活性剂;微生物含量包括粪大肠杆菌群;辐射量包括总α、总β、3h、14c、90sr活度浓度;所述水量数据包括水位、流量、流速等;原始水质水量数据的集合为以时序排列的参数集合;
所述的预处理包括缺失值处理和归一化处理,
所述缺失值处理的方式为使用之前两个时刻的平均值填充缺失值;
所述归一化处理的方法为:
其中,xt为t时刻的原始参数,xmin为序列中参数的最小值,xmax为序列中参数的最大值,xt为归一化后t时刻的参数;
预处理完成后按时序排列,以前70%作为训练集,后30%作为测试集。
步骤b:将训练集输入lstm网络中进行训练,计算公式为:
ft=σ(wf·[ht-1,xt]+bf)
it=σ(wi·[ht-1,xt]+bi)
ot=σ(wo·[ht-1,xt]+bo)
其中,h为lstm神经网络的输出,训练中输入为t时刻的水质水量数据,输出为t+1时刻的水质水量数据;f、i、o分别表示遗忘门、输入门和输出门;σ表示sigmoid函数,w和b分别表示权重和偏差矩阵;
损失函数为平均绝对误差(mae),训练前预设训练的最大迭代次数和损失函数值的阈值,通过adam算法更新遗忘门、输入门和输出门的权重,每次更新权值之后计算损失函数值,如果损失函数值小于等于阈值或训练次数达到最大迭代次数,则训练结束,将权重代入以上公式,计算出偏差矩阵;即得到所述预测模型。
其中,平均绝对误差的计算方法为:
其中n为样本个数,
步骤c:基于原始水质水量数据使用预测模型预测测试集中的预测值,然后计算预测误差,公式为:
其中,yt为t时刻测试集的实际值,
步骤d:将测试集的预测误差σt输入arma模型,arma(p,q)基本形式为:
其中{εt}为白噪声,
完整的训练过程为:
(1)首先通过adf检验验证误差序列的平稳性
主要方法为:比较1%、5%、10%不同程度拒绝原假设的统计值和adftestresult的大小,若adftestresult同时小于1%、5%、10%即说明非常好地拒绝该假设,本实例中通过实验得到adftestresult同时小于1%、5%、10%三个程度的统计值,说明水质水量时间序列的误差是平稳的;
(2)时间序列定阶,本实施实例中通过acf、pacf截尾判断识别arma模型的阶数,以最小信息量准则(akaikeinformationcriterion,aic)作为模型定阶的标准,通过不断实验选择aic较小的为最优模型,aic模型的计算公式为
(3)构建模型和预测,经过训练得到误差修正模型。
步骤e:将待预测数据分别输入步骤b得到的预测模型和步骤d得到的误差修正模型,将结算结果几何相加得到预测值;即
其中,zt为待预测时刻的预测值,
本实施例通过lstm神经网络和arma模型分别对待预测时刻的水质水量和预测误差进行计算,克服了由于水质水量历史数据序列的强非线性特征以及弱线性特征而无法进行有效预测的问题,通过lstm模型,充分挖掘水质水量数据之间的相互关联性,通过遗忘门、输出门等节点之间的结构,解决了传统神经网络方法在训练过程中由于长时间跨度数据的学习出现的梯度消失和梯度爆炸的问题。另一方面,由于水质水量数据序列呈现强非线性特征和弱线性特征,单一的预测模型难以充分处理水质水量的弱线性特征,需要结合其他的算法,而arma模型的特征可以作为lstm模型在处理线性数据的有效补充,lstm模型与arma模型相结合的方法,在单一预测模型的基础之上,具备更强的通用性和稳定性,使得水质水量预测结果更为稳健。
本实施例还引入了百分比误差(mape)对算法结果进行评估,计算公式为:
其中,n为总的预测时间数。
图2示出了使用本实施例提供的短期水质水量预测方法的预测结果与真实值的比对,可以看出本实施例提供的水质水量预测方法的预测结果与真实结果基本一致,经过比较,使用本实施例提供的lstm-arma模型的mape值为12.6%;lstm模型mape值为15%,因此本实施例提供的短期水质水量预测方法的效果明显优于lstm模型。
本实施例还提供了基于深度学习的短期水质水量预测系统,包括
预处理模块:对原始水质水量数据进行预处理,将处理后的数据划分为训练集和测试集;
预测模型训练模块:将训练集输入lstm网络中进行训练,使用adam算法更新遗忘门、输入门和输出门的权重,以损失函数值和迭代次数作为训练终止条件,得到预测模型;
预测误差计算模块:基于原始水质水量数据使用预测模型预测测试集对应的预测值,并根据实际值与预测值计算预测误差;
误差修正模型训练模块将预测误差输入arma模型中得到误差序列的误差修正模型;
计算模块:将待预测数据分别输入预测模型和误差修正模型,将结算结果几何相加得到预测值。
- 还没有人留言评论。精彩留言会获得点赞!