基于时延神经网络的锅炉参数建模方法与流程
本发明属于热工技术和人工智能技术领域,具体涉及基于时延神经网络的锅炉参数建模方法。
背景技术:
为了确保锅炉装置稳定、高效、绿色运行,需要获取锅炉尾部烟气中飞灰含碳量、含氧量和nox排放等参数的相关信息,实现对与系统安全生产、经济运行、环保排放密切相关的重要过程变量的实时监测和优化控制。但是,上述重要参数往往处于高温、高压、高粉尘、高腐蚀性的环境,难以直接测得。以燃煤电厂cems仪表为例,通过取样分析装置测得的数据只具有短期时效性,长期运行难免出现测点无信号,或者测量值误差超出允许范围,需要人工定期检查维护(相关行业标准规定每天用标准样气校准),探头定时吹扫,仪表定期校验等,消耗了大量的人力与物力。
目前,锅炉参数的神经网络建模方法普遍采用将对象黑箱化处理的通用建模方法:选取总燃料量、锅炉负荷、排烟温度、给煤机瞬时煤量(或给煤机开度)、二次风门开度、ccofa燃尽风开度、省煤器出口氧量、煤种特性参数、磨煤机通风量等辅助变量作为输入量来预测锅炉参数。但是,工业锅炉具有大惯性大迟延特点(正压直吹式制粉系统的纯迟延时间在25s以上,惯性时间在150s以上),剧烈的升降负荷过程中,由实时给煤量表征的炉膛实时进粉量严重失准。通用建模方法通过增加模型复杂程度力求达到理想训练效果,必然会造成模型训练时间长且测试(泛化)效果不佳。
技术实现要素:
本发明所要解决的技术问题是针对上述现有技术的不足,提供一种基于时延神经网络的锅炉参数建模方法。
为实现上述技术目的,本发明采取的技术方案为:
基于时延神经网络的锅炉参数建模方法,包括如下步骤:
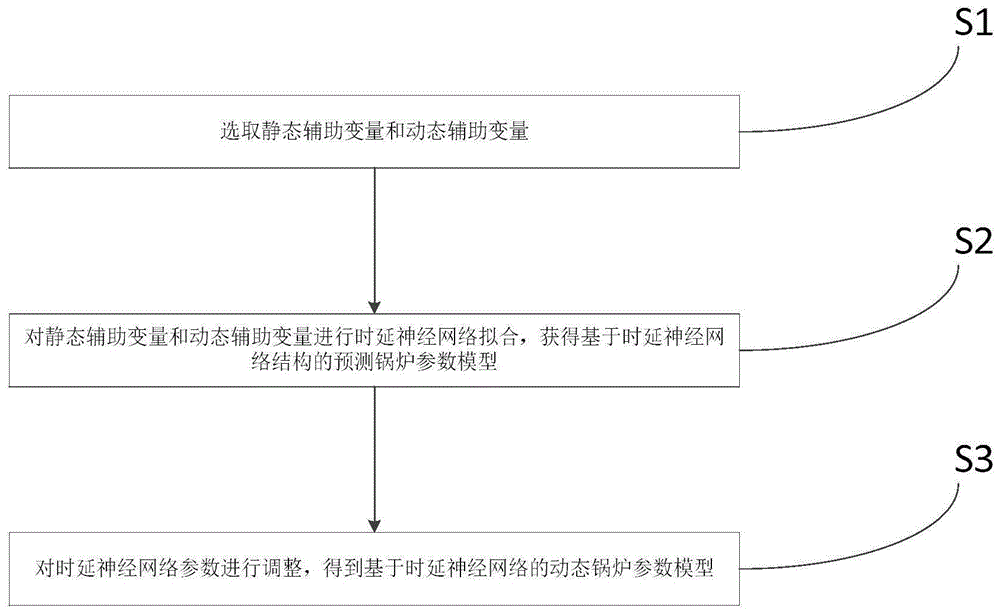
步骤s1:选取静态辅助变量和动态辅助变量;
步骤s2:对静态辅助变量和动态辅助变量进行时延神经网络拟合,获得基于时延神经网络结构的预测锅炉参数模型;
步骤s3:对时延神经网络参数进行调整,得到基于时延神经网络的动态锅炉参数模型。
为优化上述技术方案,采取的具体措施还包括:
进一步地,步骤s1中的静态辅助变量包括总燃料量、二次风门开度、ccofa燃尽风开度、省煤器出口氧量、煤种特性参数、磨煤机通风量;所述动态辅助变量为总燃料量的数量、分布密度、分布总长。
进一步地,总燃料量的数量包括若干个平均分布的时延单元,所述时延单元为一段时间内的瞬时总燃料量,后一个时延单元的时间段包含前面所有时延单元的时间段;所述分布密度为每50—70秒一个时延单元,所述分布总长为三至五分钟。
进一步地,步骤s2中的时延神经网络包括输入层、隐含层、输出层,所述输入层包括n个采样点,所述隐含层包括n个节点,所述输出层包括1个rbf神经网络输出;
s21:计算任意n个采样点{(xi,ti)|xi∈rn,ti∈r},i=1,2,...,n,结构为n-n-1的rbf神经网络输出为:
其中,wj(j=1,2,...,n)是第j个隐含层节点到输出层节点的权值;φj(x)(j=1,2,…,n)为第j个隐含层节点的高斯核函数,cj为核函数的数据中心,σj为该核函数的扩展常数;
s22:计算n个采样点的隐含层节点输出矩阵为:
s23:时延神经网络输出的实际输出矩阵为:y=φw
其中,w为连接隐含层与输出层的权值矩阵,y为rbf神经网络的实际输出矩阵,即为预测锅炉参数模型。
步骤s3具体为:
s31:实时采集锅炉尾气的代表数据,将数据分为待优化样本和检测样本,所述代表数据包括nox的含量、含碳量或含氧量;
s32:将时延神经网络输出值y和真实值t=(t1t2…tn)之间的误差平方和作为时延神经网络的训练目标误差函数:
s33:对时延神经网络参数进行优化,计算最优输出权值w,使时延神经网络输出值y和真实值t=(t1t2…tn)之间的误差平方和以及输出权值w范数最小;
通过矩阵φ的广义逆求得w的最优值:w=φ+t;
s34:以输出值y和真实值t的误差平方和为目标函数,通过梯度下降算法优化隐含层中的节点数据中心cj以及扩展常数σj,目标函数对cj和σj的梯度分别为:
数据中心cj以及扩展常数σj的更新公式为:
其中,η为学习率,k=1,2…,n;
s35:根据优化的输出权值、节点数据中心和扩展常数,计算得到基于时延神经网络的动态锅炉参数模型为:
其中,
s36:将检测样本代入动态锅炉参数模型进行检测验算。
本发明的有益效果:
本发明基于时延神经网络的锅炉参数建模方法,利用输入量动态化构造方法,融合静态建模和动态建模的优点,选取总燃料量的时延单元作为动态辅助变量,通过神经网络拟合,得到充分包含锅炉制粉系统动态特性的模型;
在设定相同的训练误差条件下,时延模型的内部神经元个数明显少于静态模型,模型结构更紧凑,训练时间更短,泛化能力更强。
附图说明
图1是本发明的流程示意图;
图2是锅炉参数估计值与仪表分析值结果对比图。
具体实施方式
以下结合附图对本发明的实施例作进一步详细描述。
如图1所示,本发明为基于时延神经网络的锅炉参数建模方法,其中:包括如下步骤:
步骤s1:选取静态辅助变量和动态辅助变量;
其中,静态辅助变量包括总燃料量、二次风门开度、ccofa燃尽风开度、省煤器出口氧量、煤种特性参数、磨煤机通风量;所述动态辅助变量为总燃料量的数量、分布密度、分布总长;
总燃料量的数量包括若干个平均分布的时延单元,所述时延单元为一段时间内的瞬时总燃料量,后一个时延单元的时间段包含前面所有时延单元的时间段;所述分布密度为每50—70秒一个时延单元,所述分布总长为三至五分钟。
其中优选方案:分布总长为三分钟,每分钟平均分为三个时延单元,分布密度为每二十秒一个时延单元。
步骤s2:对静态辅助变量和动态辅助变量进行时延神经网络拟合,获得基于时延神经网络结构的预测锅炉参数模型;
其中时延神经网络包括输入层、隐含层、输出层,所述输入层包括n个采样点,所述隐含层包括n个节点,所述输出层包括1个rbf神经网络输出;
s21:计算任意n个采样点{(xi,ti)|xi∈rn,ti∈r},i=1,2,...,n,结构为n-n-1的rbf神经网络输出为:
其中,wj(wj(j=1,2,...,n))是第j个隐含层节点到输出层节点的权值;φj(x)(j=1,2,…,n)为第j个隐含层节点的高斯核函数,cj为核函数的数据中心,σj为该核函数的扩展常数;
s22:计算n个采样点的隐含层节点输出矩阵为:
s23:时延神经网络输出的锅炉参数模型矩阵为:y=φw;
其中,w为连接隐含层与输出层的权值矩阵,y为rbf神经网络的实际输出矩阵,即为预测锅炉参数模型。
步骤s3:对时延神经网络参数进行调整,得到基于时延神经网络的动态锅炉参数模型。
s31:实时采集锅炉尾气的代表数据,将数据分为待优化样本和检测样本,所述代表数据包括nox的含量、含碳量或含氧量;
s32:将时延神经网络输出值y和待优化样本的真实值t=(t1t2…tn)之间的误差平方和作为时延神经网络的训练目标误差函数:
s33:对时延神经网络参数进行优化,计算最优输出权值w,使时延神经网络输出值y和真实值t=(t1t2…tn)之间的误差平方和以及输出权值w范数最小;
通过矩阵φ的广义逆求得w的最优值:w=φ+t;
s34:以输出值y和真实值t的误差平方和为目标函数,通过梯度下降算法优化隐含层中的节点数据中心cj以及扩展常数σj,目标函数对cj和σj的梯度分别为:
数据中心cj以及扩展常数σj的更新公式为:
其中,η为学习率,k=1,2…,n;
s35:根据优化的输出权值、节点数据中心和扩展常数,计算得到基于时延神经网络的动态锅炉参数模型为:
其中,
s36:将检测样本代入动态锅炉参数模型进行检测验算。
以某sg3099/27.46-m545型超超临界参数变压运行螺旋管圈直流炉的nox含量模型为试验对象,24小时内由负荷500mw升至1000mw,再由1000mw降至500mw的过程中scr反应器进口nox含量(干基标态,6%o2状态下)。
如图2所示为大样本下估计值与仪表分析值结果对比图,训练样本数目1000个,测试样本1000个,训练偏差目标仍设为0.3%。
通过与静态建模方法的仿真比较,统计数据表明动态建模方法以最精简的模型结构获得较好的的泛化能力:动态建模方法得出的模型网络神经元的数目比静态建模方法减少约30%,用时减少约30%,测试误差小于静态建模方法,即泛化能力更强。
以上仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!