一种基于集成学习的大坝监测数据异常检测方法与流程
本发明属于大坝监测领域,特别涉及一种基于集成学习的大坝监测数据异常检测方法。
背景技术:
大坝监测数据异常检测对于水库能否正常运行至关重要,水库大坝安全监测要做到定时定点、规律系统,以观测数据的分析结果为主要依据,为水库安全运行提供服务。大坝异常数据检测是通过仪器观测和巡视检查对水利水电工程主体结构、地基基础、两岸边坡、相关设施以及周围环境所作的测量及观察;“检测”既包括对建筑物固定测点按一定频次进行的仪器观测,也包括对建筑物外表及内部大范围对象的定期或不定期的直观检查和仪器探查。通过观测仪器和设备,以及时取得反映大坝和基岩性态变化以及环境对大坝作用的各种异常数据。其目的是分析估计大坝的安全程度,以便及时采取措施,设法保证大坝安全运行。
基于学习的方法逐渐应用于异常检测,该类方法构造深度神经网络捕获数据关系。许多神经网络方法如长短记忆网络lstm、循环神经网络rnn、自编码器auto-encoder等,能有效捕获大坝监测数据时序关系,提高时序数据异常检测性能。在处理有标签的数据时,基于学习的方法表现出优越的性能,但是在异常检测这类无监督问题时表现受限。基于学习的方法通常需要大量的大坝监测数据样本,通过不断的迭代学习计算结果,在处理高维数据时计算消耗巨大。
集成学习能有效提升大坝监测数据异常检测性能,但是现有方法存在以下问题:(1)大多数方法不经过筛选,组合所有的基础检测模型。这类方法会导致集成方法准确性降低,因为对于不同的数据集,基础检测单元的性能也不同,不经选择直接组合会导致表现较差的基础模型降低整体性能;(2)在基础检测模型选择和组合中,通常会忽略大坝监测数据间的局部相关性,导致输出结果不是最优解;(3)在基础检测模型选择中,通常会考虑多样性和一致性,没有对二者进行平衡。
技术实现要素:
发明目的:为了克服现有技术中存在的大坝安全监测系统监测点多,数据量庞杂,人工判别异常数据点难度高且效率低问题,本发明提供一种基于集成学习的大坝监测数据异常检测方法,对海量高维数据进行特征学习,高效精确计算处理并得出检测结果。
技术方案:为实现上述目的,本发明提供一种基于集成学习的大坝监测数据异常检测方法,包括如下步骤:
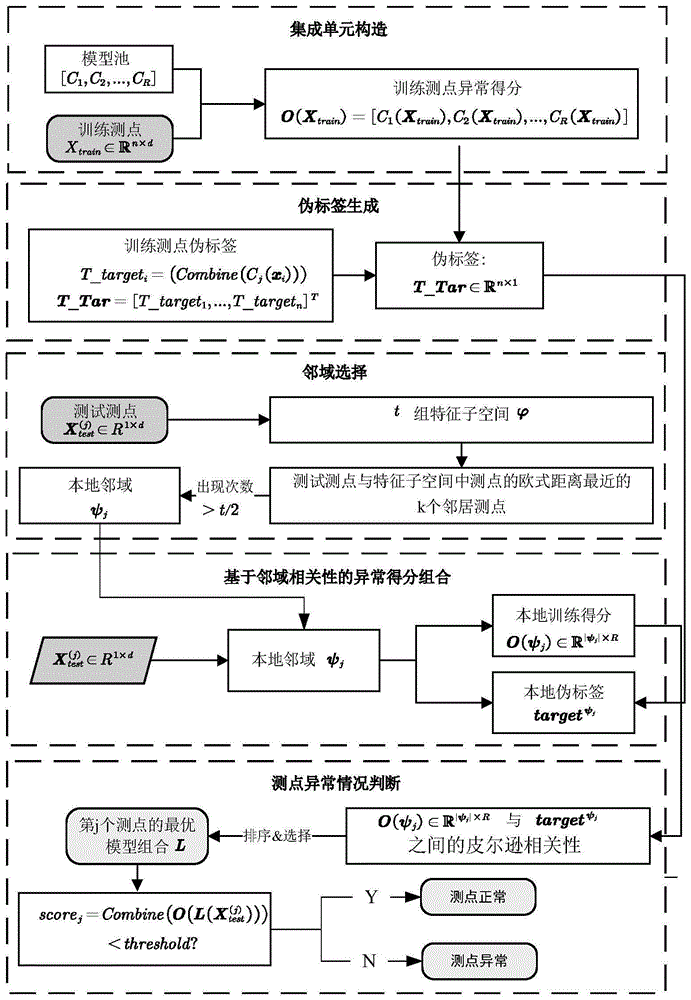
(1)大坝监测点的集成单元的构造:利用随机子采样构造不同的监测数据子集,并根据超参数多样性构造不同的模型组,训练得到异常检测模型池;
(2)伪真值标签的构造:基于异常检测模型池,采用集成一致性方法构造测点的伪真值标签;
(3)测点局部邻域空间生成:基于邻域相关性选择目标测点相关邻域,根据测点邻域的异常得分矩阵与从测点的伪真值标签间的皮尔逊相关性,选择最优模型组合;
(4)测点异常情况判断:计算测点在最优模型组合上的得分,判断测点异常情况。
进一步的,所述步骤(1)中集成单元构造的具体步骤如下:
(1.1)划分测点:在t0~t1时间段内,将大坝监测点划分为训练测点和测试测点;训练测点
(1.2)构造模型池:对同一异常检测模型c(例:stl分解,cart树等),使用r组不同的超参数,每一组超参数得到一个异常监测模型c′i;组合模型c′i得到模型池c′={c′1,...,c′i,...,c′r},其中r表示模型池中模型的个数,c′i表示第i组超参数初始化的模型。
(1.3)集成单元的训练:利用训练测点
进一步的,所述步骤(2)中构造伪真值标签的具体步骤如下:
(2.1)利用步骤(1)训练好的模型池,计算测点
其中
(2.2)根据步骤(2.1)得到的异常得分矩阵,将训练测点
(2.3)对于每一个训练测点进行步骤(2.2)的操作,得到所有n个训练测点的伪真值标签
进一步的,所述步骤(3)生成测试测点的局部空间具体步骤如下:
(3.1)考虑第j个测试测点
(3.2)对于选取的第i组特征子空间,在m个测试测点中找出在该组特征子空间中,且与测试测点
(3.3)对于测点
进一步的,所述步骤(4)测点异常情况判断具体步骤如下:
(4.1)根据步骤(3)中得到的测试测点
其中,ψji表示局部空间ψj中的第i个测点。
(4.2)根据(4.1)中生成的
(4.3)计算
(4.4)根据选择的l个模型,计算该测试测点
(4.5)异常测点判断:设置阈值threshold,当scorej<threshold时,表示
(4.6)对测试测点中的所有测点执行(3)(4)步操作,检测出所有测试测点中的所有异常测点。
本发明同时考虑全局和局部关系,提出基于邻域相关性和集成一致性的选择集成方法,首先根据多样性构造基础模型,然后考虑全局集成一致性计算出出大坝监测点的异常得分,最后考虑邻域相关性组合异常得分,根据异常得分判断大坝监测点是否为异常测点。
有益效果:本发明与现有技术相比具有以下优点:
本发明的集成方法在大坝监测数据异常检测中能有效降低偏差和方差,有更稳定的性能;
本发明考虑监测测点间的局部关系,不同的点根据其于邻域相关性和集成一致性的结果,得到更准确的判断
本发明可根据需求,动态选择和组合基础单元,有效降低基础模型偏差和方法,提高大坝监测数据异常检测的准确率和稳定性。
附图说明
图1为本发明的流程图;
图2为具体实施例中异常得分举证生成图;
图3为具体实施例中伪真值标签生成图;
图4为具体实施例中测点邻域构造图;
图5为具体实施例中测点异常情况判断图。
具体实施方式
下面结合具体实施例,进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
图1为本发明提供的基于集成学习的大坝异常数据检测方法的总体流程图,分为5个部分,包括大坝监测点的集成单元构造、伪真值标签的生成、测点领域选择、基于邻域相关性的异常得分组合、选择测点最优模型组合,判断测点的异常情况。
设大坝安全检测中包含的测点总数为n,定义所有测点集合x={xi|i=1,...,n},其中
得到异常得分矩阵过程如图2所示:(1)构造模型池:对同一异常检测模型c(例:stl分解,cart树等),使用r组不同的超参数,每一组超参数得到一个异常监测模型c′i。组合模型c′i得到模型池c′={c′1,...,c′i,...,c′r},其中r表示模型池中模型的个数。(2)利用训练测点
其中
伪真值标签的构造如图3所示:(1)根据异常得分矩阵,组合训练测点xi在r个模型上的输出结果,可以得到训练测点xi的伪真值标签。表示为:
测试测点领域构造如图4所示:(1)考虑第j个测试测点
测试测点异常情况判断如图5所示:(1)根据测试测点
其中,ψji表示局部空间ψj中的第i个测点。(2)根据
- 还没有人留言评论。精彩留言会获得点赞!