一种遗传算法和蜻蜓算法相结合的多维数据特征选择方法与流程
本发明涉及一种属于机器学习的方法,更确切地说,本发明设计了一种遗传算法和蜻蜓算法相结合的多维数据特征选择方法。本发明不仅可以应用到机器学习领域,还可以推广到其他领域中,其他领域也属于本专利的保护范围。
背景技术:
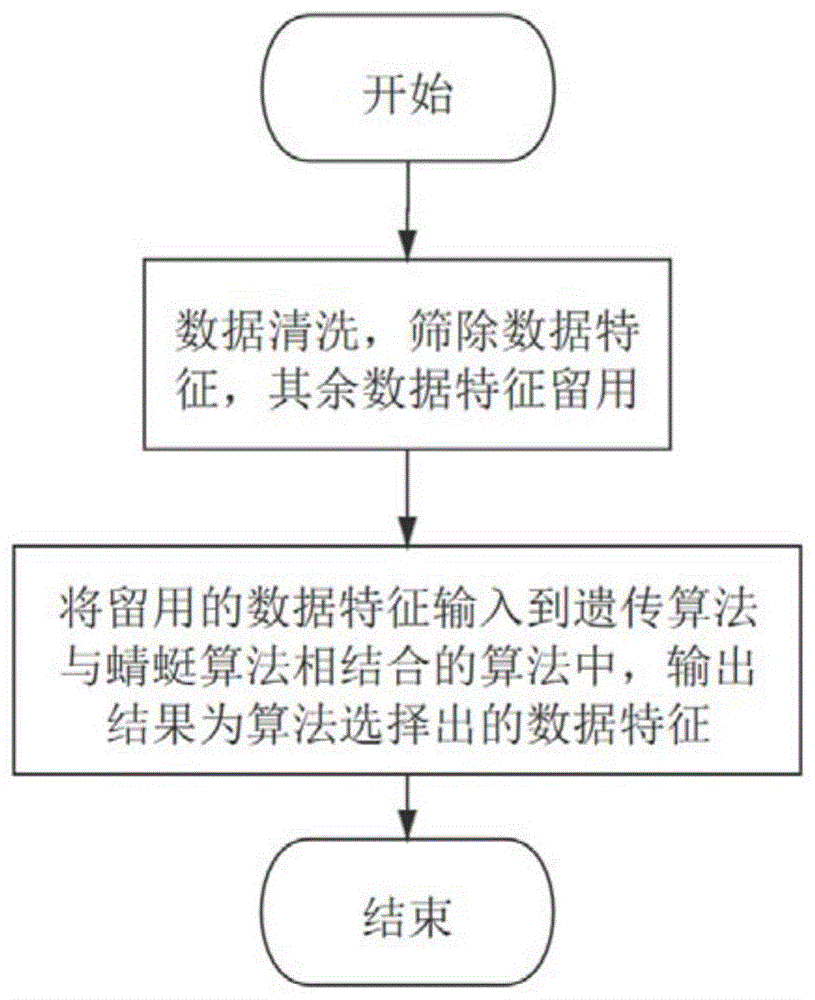
:机器学习是近些年来新兴学科,涉及多个领域。机器学习专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,不断改善自身性能。而机器学习中,数据集的选取尤为重要。对于数据集的选取,首先是要选取有足够多特征和样本的数据集,其次是要在数据集中进行特征选择。由于在特征选择过程中进行优化可以提高多种分类模型的准确率,因此如何选择出较好的特征组合是人们关注的重点。为了在大量数据中获取有效信息以得到有效的结果,在拿到数据时要先进行特征降维。特征降维的方法有特征选择和特征提取两种,特征提取是将原始特征集中的特征进行线性组合,使用新的特征代替初始特征,多用于图像处理方面;特征选择是在初始特征集中的d个特征,根据评价准则选出d(d<d)个特征,这d个特征可以得出最好的结果。特征提取和特征选择均可以达到降维目的,但是特征选择可以保存原始数据集中的物理特征,而特征提取后的新特征无法赋予其实际意义。目前针对特征选择过程已有很多研究成果。大多数研究者采用改变过滤条件的方法来处理数据集,也有研究者采用进化算法进行特征选择。进化算法,也可称为演化算法,灵感来自于大自然的生物进化。与传统的穷举法等优化算法相比,进化计算是一种成熟的具有高鲁棒性和广泛适用性的全局优化方法,具有自组织、自适应、自学习的特性,能够不受问题性质的限制,有效地处理复杂问题。遗传算法是一种成熟的进化算法,该算法是根据大自然中生物体进化规律而设计提出的。该算法通过数学的方式,利用计算机仿真运算,将问题的求解过程转换成类似生物进化中的染色体基因的交叉、变异等过程。在求解较为复杂的组合优化问题时,相对一些常规的优化算法,通常能够较快地获得较好的优化结果。研究者将遗传算法应用于特征选择过程中可以得出一个较好的特征组合,但是由于遗传算法存在过早收敛的问题,导致该特征组合很有可能不是最优解。针对这一问题,本发明设计了一种遗传算法和蜻蜓算法相结合的多维数据特征选择方法,减少了寻优时间,提高了模型准确率。技术实现要素:本发明所要解决的技术问题是优化现有的机器学习中特征选择方式,针对众多特征的多种组合可能性,提供了一种遗传算法和蜻蜓算法相结合的多维数据特征选择方法。一种遗传算法和蜻蜓算法相结合的多维数据特征选择方法,步骤如下:一、对于交通事故数据进行清洗,制作交通事故数据集,根据数据的每一维特征,将本维度特征中仅有单一值、数据缺失超过一半、信息熵值从大到小排在后三位的特征筛除,即所有数据进行模型训练时均不选取此特征,其余特征留用;二、将步骤一中的数据特征筛选结果作为一种遗传算法和蜻蜓算法相结合的多维数据特征选择方法的输入,输出结果为算法选择出的数据特征;所述的步骤二中,数据特征筛选结果作为一种遗传算法和蜻蜓算法相结合的多维数据特征选择方法的输入,输出结果为算法选择出的数据特征,其中一种遗传算法和蜻蜓算法相结合的多维数据特征选择方法是指:1)划分训练集和测试集交通事故数据集由各种渠道获得,收集好的车祸数据集分为训练集和测试集,在训练集和测试集中,根据交通事故的严重程度将数据分为轻微事故、严重事故和致命事故三种,训练集和测试集不重复存在;2)缺失值筛除对于已有的数据先进行统计,根据统计结果首先筛除缺失值超过一半的特征,即不再考虑此特征对于所有数据最后分类结果的影响。在未知前提下猜测结果正确率有二分之一,缺失值超过了一半的特征对于数据的分类准确率可能造成干扰;3)单一特征筛除对于现有的特征及数据,筛除掉特征值单一的数据特征。因为只有一个值,所以对于全部数据的分类准确率没有影响,而且会加大后续算法的计算量,因此将单一特征值的特征筛除;4)信息熵筛除对于现有的特征和数据,计算所有特征的信息熵。信息熵h(x)的计算公式如公式(1):式中,p(xi)代表了第x个特征的n种不同取值情况对应的不同概率。信息熵表示了信息的不确定度,信息熵越大,信息的不确定度越高。因此筛除掉信息熵由大到小排名后3位的特征,因为该特征没有很多的有用信息,筛除后可以在基本不影响结果准确率的前提下减少特征选择工作量;所述的步骤二中,将数据特征筛选结果作为一种遗传算法和蜻蜓算法相结合的多维数据特征选择方法的输入,输出结果为算法选择出的数据特征,其中另一种遗传算法和蜻蜓算法相结合的多维数据特征选择方法是指:1)遗传算法遗传算法是近年来发展的基于生物遗传学的观点的全新的全局优化算法,在数据进行处理的过程中,通过不断地进化,种群中的整体适应度不断提高,最终达到全局寻优的目标。遗传算法具有自适应性,随机生成初始种群后,经过迭代选择、交叉、变异等操作,最终寻得最优解;2)遗传算法步骤第一步骤:进行种群初始化,将要解决的问题表示成遗传空间的染色体个体,通常采用二进制编码方式,经过编码后随机生成初始种群p(0),设置迭代计数器t=0,设置最大迭代次数t;第二步骤:根据适应度函数来计算种群个体p(t)适应度值,其中适应度函数是用来判断种群个体的优劣程度的指标,表示了种群个体对于环境的适应能力;第三步骤:将结束条件设置为“达到第t代”,当t<t时进行选择、交叉、变异操作,当t=t时结束迭代,输出第t代中最优个体,即最优解。例如求解函数最大值问题,假设函数如公式(2),采用遗传算法求出x取值范围在[0,10]时,该函数的最大值。f(x)=x*sin(10x)+2(2)应用第一步骤,假定求解的精度为小数点后两位,则可以将解空间分为1000个等份,如果采用二进制编码则要使用10位二进制数码表示。一个二进制数代表一条染色体chromosome,初始染色体是随机生成的,对于求解最大值问题,可以初始化生成10条染色体,即初始种群p(0)。对于染色体可以采用如公式(3)的解码公式将其转换为十进制数。最大迭代次数t初始值通常设置为100代到200代。应用第二步骤,对种群个体p(t)计算适应度函数值,即f(x)的值。将染色体解码后对应的十进制数带入到f(x)中计算,f(x)值越大表明个体适应度越好。应用第三步骤,将最大迭代次数t设置为100代。当t<t,即未达到结束条件时,进行选择、交叉和变异操作,说明如下:(1)选择操作是将染色体个体根据适应度函数f(x)的值从大到小排序,在本问题中可知适应度函数f(x)的最大值不会超过12,因此每个染色体个体被选为父代的概率为f(x)/12,保证适应度函数f(x)的值大的染色体个体有更大的概率被选取。(2)然后对于两个父代染色体进行交叉操作,通常采用单点交叉法。如图7所示,假设选出的染色体个体a为1010101010,染色体个体b为1111100000。若以左数第3位为交叉点,交叉生成的一个新个体c是“a”的前3位与“b”的后7位的组合,为1011100000,另一个新个体d是“b”的前3位与“a”的后7位的组合,为1110101010。(3)变异操作是指染色体个体中的基因有概率突变,即染色体个体中的10位二进制数码均可能发生变异,生成新的染色体个体,通常遗传算法中变异的概率一般设置为0.1。当t=t,即达到结束条件时,输出适应度函数值最大的个体。3)蜻蜓算法蜻蜓算法是根据自然界中蜻蜓寻找食物的行为而模拟提出的一种新兴群智能优化算法,该算法原理简单,易于理解且便于实现,具有较强的搜索能力,可以应用于图像分割、变压器故障诊断等多个领域。蜻蜓算法的主要思想是通过模拟蜻蜓群体分离、列队、聚集、捕食及避敌五种飞行行为进行寻优操作。蜻蜓个体在分离行为中产生的位移如公式(4):其中,si表示第i只蜻蜓个体在分离行为中产生的位移,xi表示该蜻蜓个体当前位置,xj表示蜻蜓种群中与第i只蜻蜓个体相邻的第j只蜻蜓在当前迭代的位置,n表示蜻蜓种群数量。蜻蜓个体在列队行为中产生的位移如公式(5):其中,ai表示第i只蜻蜓个体在列队行为中产生的位移,xj表示蜻蜓种群中与第i只蜻蜓个体相邻的第j只蜻蜓在当前迭代的位置,n表示蜻蜓种群数量。蜻蜓个体在聚集行为中产生的位移如公式(6):其中,ci表示第i只蜻蜓个体在聚集行为中产生的位移,xi表示第i只蜻蜓个体当前位置,xj表示蜻蜓种群中与第i只蜻蜓个体相邻的第j只蜻蜓在当前迭代的位置,n表示蜻蜓种群数量。蜻蜓个体在捕食行为中产生的位移如公式(7):fi=xfood-xi(7)其中,fi表示第i只蜻蜓个体在聚集行为中产生的位移,xi表示第i只蜻蜓个体当前位置,xfood表示在当前迭代次数下,蜻蜓种群所需要寻找的食物的具体位置。蜻蜓个体在避敌行为中产生的位移如公式(8):ei=xe+xi(8)其中,ei表示第i只蜻蜓个体在避敌行为中产生的位移,xi表示第i只蜻蜓个体当前位置,xe表示在当前迭代次数下,蜻蜓种群所发现的天敌所在的具体位置。为了模拟蜻蜓五种飞行模式的移动过程,算法又引入了步长向量(δx)和位置向量(x),用于更新蜻蜓个体在下一次迭代的位置。第i只蜻蜓在第t+1次迭代时步长向量如公式(9):其中表示第i只蜻蜓在第t+1次迭代时d维步长向量,s表示分离行为对蜻蜓位置权重影响,表示第i只蜻蜓个体在第t次迭代时d维步长向量因为分离行为而产生的位移,α表示列队行为对蜻蜓位置权重影响,表示第i只蜻蜓个体在第t次迭代时d维步长向量因为列队行为而产生的位移,c表示聚集行为对蜻蜓位置权重影响,表示第i只蜻蜓个体在第t次迭代时d维步长向量因为聚集行为而产生的位移,f表示捕食行为对蜻蜓位置权重影响,表示第i只蜻蜓个体在第t次迭代时d维步长向量因为捕食行为而产生的位移,e表示避敌行为对蜻蜓位置权重影响,表示第i只蜻蜓个体在第t次迭代时d维步长向量因为避敌行为而产生的位移,ω为惯性权重,表示第i只蜻蜓在第t次迭代时d维步长向量。第i只蜻蜓在第t+1次迭代时位置向量如公式(10):当蜻蜓没有临近个体作为参考时,引入莱维飞行随机游走,此时第i只蜻蜓的位置更新如公式(11):其中,表示第i只蜻蜓个体在第t次迭代时d维步长向量,levy(d)表示d维的莱维飞行步长;莱维飞行指的是步长的概率分布为重尾分布的随机行走,在随机行走的过程中有相对较高的概率出现大跨步。其中重尾分布是一种概率分布模型。莱维飞行的计算公式如公式(12):其中,r1和r2为[0,1]之间的随机数,σ的计算公式如公式(13)所示:其中,β为一个常数,γ(x)为(x-1)的阶乘;4)遗传算法和蜻蜓算法结合遗传算法中,种群的更新是通过对个体的选择、交叉和变异来完成的,其中的交叉和变异过程均具有随机性。蜻蜓算法可以标记食物和天敌的位置,即可以选出最优和最差的两个基因位置。使用蜻蜓算法计算的食物和天敌基因位置来干预遗传算法的交叉和变异过程,使遗传算法的染色体进化成更优个体的过程加速,优化遗传算法求解的过程。步骤1:进行种群初始化,将要解决的问题表示成遗传空间的染色体个体,通常采用二进制编码方式,经过编码后随机生成初始种群p(0),设置迭代计数器t=0,设置最大迭代次数t;步骤2:根据适应度函数来计算种群个体p(t)适应度值f(x),其中适应度函数f(x)是用来判断种群个体的优劣程度的指标,表示了种群个体对于环境的适应能力;步骤3:将结束条件设置为“达到第t代”,当t<t时,选择种群个体p(t)中适应度值最大的两个染色体个体作为父代;步骤4:将蜻蜓算法作用于遗传算法的交叉过程中。步骤3输出的两个父代染色体个体交叉生成新个体前,使用蜻蜓算法遍历这两个父代染色体并确定交叉位置后,遗传算法再实施交叉操作。(1)利用蜻蜓算法,将两条父代染色体中标记为1(选取)的基因位依次改为0(不选取),其中使适应度函数值降低最多的那个基因位,标记为“食物”(最优特征位置);(2)利用蜻蜓算法,将两条父代染色体中标记为0(不选取)的基因位依次改为1(选取),其中使适应度函数值降低最多的那个基因位,标记为“天敌”(最差特征位置);(3)如果通过(1)和(2)对染色体标记的“食物”在“天敌”的左侧,则将“食物”选做交叉点;如果“食物”在“天敌”的右侧,则将“天敌”选做交叉点。(4)根据(3)中蜻蜓算法选定的交叉点位置进行交叉操作,生成两条新染色体,如图8。(5)将(4)中生成的两条新染色体和步骤3中未被选择为父代的染色体作为步骤4第t代的输出结果。步骤5:将蜻蜓算法作用于步骤4输出的染色体上,进行变异操作。(1)每一轮迭代开始时,将基因变异概率p设置为0.2,即种群中每条染色体个体中的每一位基因均有0.2的概率发生突变,从1(选取)变到0(不选取)或从0(不选取)变到1(选取),目的是增加“变异”对染色体的影响。(2)根据步骤4中标记的“食物”和“天敌”位置,将全部染色体个体中的“食物”和“天敌”标记出来,调整(1)中设定的基因变异概率,从而增加“变异”对不同基因位的影响。(3)设置食物位基因变异的概率如公式(14)。经历过蜻蜓算法标记后,如果染色体中被标记为“食物”的那位基因未被选取,即该基因位数码为0,则“食物”位置的变异概率pfood为其他位置变异概率p的二倍,即选0.4,增大“食物”位置变异的概率;如果染色体中被标记为“食物”的那位基因已被选取,即该基因位数码为1,则“食物”位置的变异概率pfood为其他位置变异概率p的一半,即选0.1,降低“食物”位置变异的概率;(4)设置天敌位基因变异的概率如公式(15)。经历过蜻蜓算法标记后,如果染色体中被标记为“天敌”的那位基因未被选取,即该基因位数码为0,则“天敌”位的变异概率penemy为其他位置变异概率p的一半,即选0.1,降低“天敌”位置变异的概率;如果染色体中被标记为“天敌”的那位基因已被选取,即该基因位数码为1,则“天敌”位的变异概率penemy为其他位置变异概率p的二倍,即选0.4,增大“天敌”位置变异的概率;(5)输出第t代全部染色体变异操作后的结果。步骤6:当t=t时,结束迭代,输出适应度值最大的个体,即最优特征组合。与现有技术相比,本发明的有益效果是:1.对比遗传算法,本发明在遗传算法的交叉操作过程中优先考虑蜻蜓算法标记为“食物”的父代部分,避开蜻蜓算法标记为“天敌”的父代部分,加快遗传算法寻得最优个体的速度;2.对比遗传算法,本发明在遗传算法的变异操作过程中,如果被蜻蜓算法标记为“食物”的基因值并没有被取到,则将该基因值变异的概率设置为最大;如果被蜻蜓算法标记为“食物”的基因值已经取到,则将该基因值变异的概率设置为最小。如果被蜻蜓算法标记为“天敌”的基因值并没有被取到,则将该基因值变异的概率设置为最小;如果被蜻蜓算法标记为“天敌”的基因值已经取到,则将该基因值变异的概率设置为最大。经过这种操作可以减少寻优时间,优化寻优结果。附图说明图1为本发明的流程框图。图2为本发明的数据特征筛除清理流程框图。图3为本发明的遗传算法流程框图。图4为本发明的蜻蜓算法流程框图。图5为本发明的遗传算法和蜻蜓算法相结合的流程框图。图6是使用决策树分类器对三种算法输出的数据特征进行数据识别的准确率迭代曲线,其中折线为本发明的遗传算法和蜻蜓算法相结合算法da-ga的曲线、点线为蜻蜓算法da曲线、点折线为遗传算法ga曲线。图7为遗传算法交叉操作过程说明图。图8为遗传算法和蜻蜓算法相结合算法交叉操作过程说明图。具体实施方式参阅图1所示,一种遗传算法和蜻蜓算法相结合的多维数据特征选择方法的步骤如下:1)对于交通事故数据进行简单清洗;2)将步骤1)中的数据特征筛选结果作为一种遗传算法和蜻蜓算法相结合的多维数据特征选择方法的输入,输出结果为本发明方法选择出的数据特征;参阅图2所示,对于交通事故数据进行简单清洗,根据数据的每一维特征,将本维度特征中仅有单一值、数据缺失超过一半的特征筛除和信息熵值由大到小排名后三位的特征筛除,即所有数据进行模型训练时均不选取此特征,其余特征留用,数据筛选步骤如下:1)制作交通事故数据集交通事故数据集由各种渠道获得,共计570011条车祸数据,每条数据特征有32维,各维数据特征的名称如表1的第2列“特征”所示。根据车祸事故的严重程度,分为致命、严重和轻微三个程度。其中致命程度数据共8533条,严重程度数据共74297条,轻微程度数据共487161条。随机选取各个严重程度的百分之五十作为训练集,其余作为测试集;2)缺失值筛除表2是从真实的交通事故数据集中抽取了部分数据,包括特征编号是3、4、……、29等的6列特征的少量数据。表2中,编号为3、4的两个特征数据缺失超过一半,按照数据清洗规则“筛除缺失值超过一半的特征”,这两列数据特征将被去掉。在表1的第4列,使用“×”表示“去缺失值”的操作,“经度”、“纬度”两个特征不被选用。此时数据剩余30维特征。3)单一特征筛选表2中的编号16和25的两列特征数据都是“0”,按照数据清洗规则“筛除掉特征值单一的数据特征”,这两列数据特征将被去掉。在表1的第5列,使用“×”表示“去单一值”的操作,“路口信息细节”、“特殊控制”两个特征不被选用。此时数据剩余28维特征。4)信息熵筛选如表1所示,对于现有28维的特征数据,计算其信息熵,其熵值列于表1的第3列。按照数据清洗规则“筛除掉信息熵由大到小排名后3位的特征”,分别是编号为1、11、30的“城市”、“地方政府”和“年份”特征,如表1的第6列所示。此时数据剩余25维特征,用“√”表示“简单清洗”后被留用的这25维特征,如表1第7列所示;经过上述数据筛选步骤后,将剩余25维特征数据分别送入遗传算法、蜻蜓算法、遗传算法蜻蜓算法相结合的算法中进行数据特征选择;参阅图3所示的遗传算法流程框图,遗传算法用于特征选择的具体步骤如下:步骤1:进行种群初始化操作,将25维特征的取舍问题表示成遗传空间的染色体个体,采用二进制编码方式,标记为1的特征选用,标记为0的特征不选用,生成初始种群p(0),设置迭代计数器t=0,设置最大进化代数t=100,初始种群个体数为10条染色体;步骤2:采用决策树分类器来计算种群个体的适应度值,将决策树的准确率作为适应度值,适应度值越高表明种群个体越优秀;步骤3:当t<t时,对种群进行选择、交叉、变异操作。(1)采用决策树分类器来计算种群个体的适应度值,将决策树的准确率作为适应度值,选择种群个体中适应度值高的两个个体作为父代染色体。(2)将两个父代染色体进行交叉操作,通常遗传算法交叉操作选取中间基因位作为交叉点,因此在本专利中选取第12维特征处作为交叉点,将父代a的前12维特征取值与父代b的后13维特征取值相结合、父代b的前12维特征取值与父代a的后13维特征取值相结合,生成两个新的个体c、d。(3)将(2)中交叉生成的新个体和未被选为父代的其余染色体的基因位的变异概率设置为0.2,即每位基因从0变到1或从1变到0的概率为0.2。这里相比通常的遗传算法的变异操作的概率值0.1,提高到0.2,从而促进10个染色体产生变异,加速进化。步骤4:当t=t时,终止计算,输出适应度函数值最大的个体“1010110110101101010111011”,即最优特征组合,解码后对应16维特征,如表1第8列标出的“ga”最优特征组合。通过遗传算法获得数据特征的寻优时间是41秒,如表3所示。步骤5:将这16维特征(过滤+遗传)分别输入到randomforest、决策树、gradientboost、adaboost、xgboost分类器,通过仿真得到了它们的识别准确率,如表4的第3列数据所示;参阅图4所示的蜻蜓算法流程框图,蜻蜓算法用于特征选择的具体步骤如下:步骤1:初始化蜻蜓种群,将十只蜻蜓均匀的分布在特征空间中,并根据蜻蜓位置初始化步长向量,随机生成0到1之间的权重ω、α、s、c、f、e,规定迭代20代;步骤2:在未遍历所有蜻蜓个体时,比较更新食物和天敌的位置,更新权重和位置,并判断是否达到第20代,未达到最终代数时根据蜻蜓周围是否存在其他蜻蜓选择公式(10)或者公式(11)更新蜻蜓位置;步骤3:遍历完全部蜻蜓个体后判断是否达到第20代,达到则输出判别的食物和天敌,食物即应该选择的特征,共15个食物,对应15维特征,如表1第9列标出的“da”最优特征组合。蜻蜓算法选择出最优特征子集的时间是14秒,如表3所示。步骤4:将这15维特征(过滤+蜻蜓)输入到随机森林、决策树、gradientboost、adaboost、xgboost分类器,仿真得到它们的识别准确率,如表4的第4列数据所示;参阅图5所示的遗传算法和蜻蜓算法相结合的流程框图,遗传算法和蜻蜓算法相结合并应用的具体步骤如下:步骤1:进行遗传算法种群初始化,将特征选择问题表示成遗传空间的染色体个体,根据实验经验,本专利设置初始染色体个体数为10条,采用二进制编码方式将选择的特征标记为1,不选择的特征标记为0,设置迭代次数为10代;步骤2:采用决策树分类器来计算种群个体的适应度值,将结束条件设置为“达到第10代”,当未达到时,选择种群中适应度值最大的两个染色体个体作为父代;步骤3:将蜻蜓算法作用于遗传算法的交叉过程中,使用蜻蜓算法遍历父代染色体,标记食物位置和天敌位置,从而确定交叉位置,完成遗传交叉操作;步骤4:将蜻蜓算法作用于遗传算法的变异过程中,根据步骤3中的食物位置和天敌位置,调整基因变异概率,食物位置基因变异概率如公式(14)所示,天敌位置基因变异概率如公式(15)所示,完成遗传变异操作;步骤5:当t=10时,结束迭代,输出适应度值最大的个体“1010111010001111011110111”,即最优特征组合,解码后对应17维特征,如表1第10列标出的“ga+da”最优特征组合。遗传算法和蜻蜓算法相结合的算法选择出最优特征子集的寻优时间是11秒,如表3所示;步骤6:将这17维特征输入到randomforest、决策树、gradientboost、adaboost、xgboost分类器,仿真得到它们的识别准确率,如表4的第5列数据;参阅图6所示,利用决策树分类器对三种算法输出的数据特征进行数据识别的准确率与迭代次数的曲线,遗传算法和蜻蜓算法相结合的算法得到的数据特征有如下优势:(1)遗传算法与蜻蜓算法相结合的特征选择算法准确率高于单独的遗传算法和单独的蜻蜓算法;(2)遗传算法与蜻蜓算法相结合的特征选择算法在第7代达到最优解位置,遗传算法要在第80代左右,蜻蜓算法要在第14代左右,显然,遗传算法与蜻蜓算法相结合的特征选择算法具有更快的收敛性;(3)参阅表3,遗传算法与蜻蜓算法相结合的算法的特征选择过程需要11秒,遗传算法要41秒,蜻蜓算法要14秒。综上所述,本发明在准确率、收敛速度和运行时间三个方面均优于遗传算法和蜻蜓算法。表1数据集特征编号及筛选情况注:“×”表示不被选用的特征;“√”表示被选用的特征;“o”表示不计算熵值。表2部分数据特征举例编号3416252729a0010b0011c0010d51.5170000e-2.9710011f0010g0001表3三种算法寻得最优特征的运行时间表4不同特征选择算法应用到不同分类器上的准确率当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1