一种分词处理方法及系统、分词搜索方法与流程
本发明涉及大数据处理技术领域,特别涉及一种分词处理方法及系统、分词搜索方法。
背景技术:
随着大数据技术的发展,关键词数量数以亿计,并且会定时定量更新相关内容。各企业单位会面对大量关键词,要保证各企业单位所搜集采集的大数据为最新的数据,才能开展有效的业务需求,那么就需要及时对大数据进行搜索和采集的管理。
由于关键词的数量非常庞大,传统对关键词的管理方案存在反复搜索、无效搜索等问题,则会导致搜索不及时、搜索遗漏,从而降低了对关键词的搜索或使用效率,申请号为2020110246836的专利文件公开了提高关键词的处理、搜索效率的方法,从而提高对关键词的管理效率。然而分词在关键词的基础上可以进行模糊搜索,即使用一个分词可得到多个搜索结果,因此,如何提高分词的处理、搜索效率的问题是本研究的重点。
技术实现要素:
本发明的目的在于更加有效的运用大数据,对关键词进行分词处理,并提高分词的处理、搜索效率,提供一种分词处理方法及系统、分词搜索方法。
为了实现上述发明目的,本发明实施例提供了以下技术方案:
一种分词处理方法,包括以下步骤:
对关键词库中的关键词进行分词处理,并将分词处理后的分词输入分词库;
按照标记字段对分词库中的分词进行扫描,从扫描的分词中提取部分发送至消息队列;所述分词库中的分词被赋予标记字段,并形成了更新状态;
将消息队列中的分词发送至业务端进行搜索,得到状态结果,并将状态结果返回分词库,以更新分词的更新状态,同时更新对应关键词的更新状态。
本方案对分词赋予标记字段,形成分词的更新状态,便于后期使用者能够按照标记字段对分词的相关内容进行搜索和使用;按照分词的标记字段对分词进行扫描,比如将标记字段中的更新时间作为优先级时,则可以根据更新时间的先后,对分词进行扫描,这样可以保证对分词进行扫描时,不出现搜索遗漏的问题,同时也可以提高搜索效率,也可以使用其他的标记字段作为优先级对分词进行扫描;对分词进行搜索后,将得到的状态结果返回分词库进行状态的更新,同时更新对应关键词的更新状态,相当于进行了标记处理,可以避免对关键词的完全管理和跟踪,避免搜索遗漏和反复搜索,提高了数据资源的利用效率,减少服务器运作负载,节省成本,提高了经济效益。
所述对关键词库中的关键词进行分词处理的步骤,包括:
对关键词库中的关键词进行分词拆分、清洗、过滤,得到分词处理后的分词;进行了分词处理后的分词与对应的关键词形成一对多的关系。
对多个关键词同时进行分词处理后会统计合并得到一个对应的分词,因此形成了分词与关键词一对多的关系,当更新该分词的更新状态,同时也更新了该分词对应的这些关键词的更新状态,从而弥补对应关键词的内容缺陷。
被赋予了标记字段的分词转换为结构数据,所述结构数据包括分词字段名、数据类型、描述、备注;形成的所述更新状态包括分词的入库时间、更新时间、更新失败时间。
本方案对分词赋予的标记字段,以及形成的更新状态可以为后续使用者进行搜索或使用时提供便利,并且更新状态中的入库时间、更新时间、更新失败时间还可以作为一种对分词更新状态的标记处理,根据分词的更新状态,就可以知道该分词是否进行过搜索,以保证分词搜索不反复进行。
所述将消息队列中的分词发送至业务端进行搜索,得到状态结果的步骤,包括:
按照分词的标记字段对消息队列中的分词在业务端进行搜索,得到搜索正常的状态结果、搜索异常的状态结果以及超时未返回的状态结果;所述搜索正常的状态结果包括分词内容已更新或分词内容未更新。
所述将状态结果返回分词库,以更新分词的更新状态,同时更新对应关键词的更新状态的步骤,包括:
若状态结果为搜索正常,则对该分词在分词库中的更新状态进行更新,包括该分词的更新时间,同时更新对应关键词的更新状态,包括该关键词的更新时间;
若状态结果为搜索异常,则将搜索异常的状态结果返回分词库进行异常排查,并对该分词在分词库中的更新状态进行更新,包括该分词的更新失败时间,同时更新对应关键词的更新状态,包括该关键词的更新失败时间;
若状态结果为超时未返回,则提高超时未返回的状态结果的分词优先级,对该分词进行再次搜索,若仍然为超时未返回的状态结果,则返回分词库进行异常排查,并对该分词在分词库中的更新状态进行更新,包括该分词的更新失败时间,不再对该分词进行搜索,同时更新对应关键词的更新状态,包括该关键词的更新失败时间。
一种分词搜索方法,按照分词的标记字段对消息队列中的分词在业务端进行搜索,得到搜索正常的状态结果、搜索异常的状态结果以及超时未返回的状态结果,并将状态结果返回分词库。
一种分词处理系统,包括:
分词库,用于存储分词,以及分词对应的标记字段和更新状态;
分词服务器,用于对关键词库中的关键词进行分词处理后输入分词库,并对分词库中的分词赋予标记字段且形成分词的更新状态,以及按照分词的标记字段对分词库中的分词进行扫描,从扫描的分词中提取部分发送至消息队列;
消息队列,用于存放分词服务器扫描的分词;
业务端,用于对消息列表中的分词进行搜索,并将得到的状态结果返回分词库,以更新分词的更新状态。
所述分词服务器用于对分词赋予标记字段,将分词转换为结构数据,所述结构数据包括分词字段名、数据类型、描述、备注;以及形成的更新状态包括分词的入库时间、更新时间、更新失败时间。
所述业务端根据分词的标记字段对消息列表中的分词进行搜索后得到的状态结果包括:搜索正常的状态结果、搜索异常的状态结果以及超时未返回的状态结果,所述搜索正常的状态结果包括分词内容已更新或分词内容未更新。
与现有技术相比,本发明的有益效果:
本发明对关键词进行分词处理得到分词库,可以在关键词的基础上进行模糊搜索,即使用一个分词可得到多个搜索结果,对分词的处理、搜索方法形成分词的闭环更新,实现在大数据搜索领域对分词的完全管理和跟踪,避免搜索遗漏和反复搜索,提高了数据资源的利用效率,减少服务器运作负载,节省成本,提高了经济效益。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。
图1为本发明分词处理方法流程图。
具体实施方式
下面将结合本发明实施例中附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本发明实施例的组件可以以各种不同的配置来布置和设计。因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施例。基于本发明的实施例,本领域技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步定义和解释。
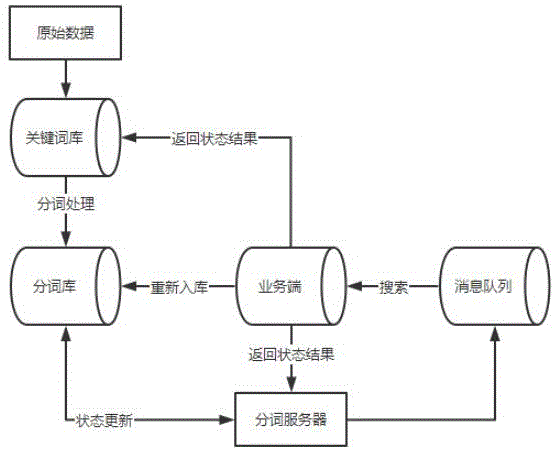
本发明通过下述技术方案实现,如图1所示,一种分词处理方法,包括以下步骤:
步骤s1:对关键词库中的关键词进行分词处理,并将分词处理后的分词输入分词库。
关键词库中已有大量的关键词,对这些关键词进行分词拆分、清洗、过滤等分词处理,得到分词处理后的分词,将得到的分词输入分词库。
所述对关键词进行分词处理的步骤包括:
s11:对关键词进行分词拆分处理,如表1所示:
表1
s12:对拆分后的分词进行清洗;
预先建立敏感词库,用于清洗拆分后的分词中的敏感词,敏感词指包含范围很大的词,比如地域名称、专有名称等,专有名称比如“科技”、“股份”等,敏感词库可以即时扩充。
s13:对拆分后的分词进行过滤,过滤后的分词如表2所示:
表2
s14:对过滤后的分词进行非法字符去除,比如单个字符、符号、乱码等,非法字符去除后的分词如表3所示:
表3
s15:对剩余分词进行统计,计算各个分词出现的次数,统计次数后的分词如表4所示;
表4
s16:由于关键词数量庞大,需要去除出现频次较高的分词,每个关键词选择频次在一定区间(自由定义)的一个分词输入分词库,并记录该分词的来源关键词供后续的查询统计,表4的分词选择合并后,四个关键词共用一个分词,如表5所示形成一对多的关系:
表5
步骤s2:按照标记字段对分词库中的分词进行扫描,从扫描的分词中提取部分发送至消息队列;所述分词库中的分词被赋予标记字段,并形成了更新状态。
对关键词库中大量的关键词进行分词处理后作为分词输入分词库中,然后对分词赋予标记字段,将分词转换为结构数据,所述结构数据包括分词字段名、数据类型、描述、备注,如表6所示:
表6
根据形成的结构数据可以进一步形成该分词的更新状态,比如该分词的更新状态可以包括该分词的入库时间、更新时间、更新失败时间。那么使用者根据分词的标记字段或更新状态,即可对分词的内容进行搜索或使用。
由于分词库中的分词数量非常的庞大,业务端无法做到一次就完成所有分词的搜索,因此可以对分词设置优先级,按照分词的优先级进行搜索,可以将分词的某一标记字段作为优先级,比如将更新时间作为优先级时,则可以按照分词的更新时间依次对分词库中的所有分词进行扫描,这样就不会遗漏分词。
假设按照分词的优先级依次可以扫描一万个分词,但一万个分词数量还是比较庞大,因此又从扫描的这一万个分词中提起部分发送至消息队列。消息对也属于业务端的一个功能模块,由于其容量有限,所以按照设定可以提取容量范围内的关键词放入消息队列进行后续的搜索。
步骤s3:将消息队列中的分词发送至业务端进行搜索,得到状态结果,并将状态结果返回分词库,以更新分词的更新状态,同时更新关键词的更新状态。
根据分词的标记字段优先级对消息队列中的分词依次或同时在业务端进行搜索,比如以机构代码作为优先级进行搜索,若该标记字段缺失,则会用公司名称在百度百科或工商行政网等网站上进行搜索。搜索的目的是为了经过搜索后得知该分词在分词库中的信息是否是最新的,以弥补该分词对应关键词的内容缺陷。并且可以对更新了的分词打一个标记,这个标记就是该分词的更新状态,比如该分词的更新时间等。
需要说明的是,关键词库中的关键词也具有与分词类似的标记字段和更新状态,可参见申请号为2020110246836的文件。所述关键词库中的关键词被赋予标记字段后,将关键词转换为结构数据,所述结构数据包括关键词字段名、数据类型、描述、备注,形成的所述更新状态包括关键词的入库时间、更新时间、更新失败时间。
进行分词的搜索后,会存在搜索正常、搜索异常以及超时未返回三种状态结果,其中搜索正常的状态结果是该分词从网站返回结果,无论结果和历史结果对比有无更新。比如某企业a的名称作为分词进行搜索时,业务端得到有无搜索结果,词库服务器获取反馈后相应地对该分词的更新状态进行更新,比如对该分词的搜索发生在2020年6月21日15点21分,则将该分词的更新时间改为2020年6月21日15点21分,以达到对更新的分词打一个标记的目的,同时更新对应关键词的更新状态,包括该关键词的更新时间。
但并不是对所有的分词进行搜索时都能返回该分词的相应内容,比如返回的结果为“error”时,则为搜索异常的状态结果,得不到任何的相应内容。此时则需要将搜索异常的状态结果返回分词进行异常排查,并对该分词在分词库中的更新状态进行更新,比如本次搜索发生在2020年8月21日16点40分,则将该分词的更新失败时间记录为2020年8月21日16点40分,以达到对更新的分词打一个标记的目的,同时更新对应关键词的更新状态,包括该关键词的更新失败时间。
如果搜索后的状态结果为超时未返回,则提高该分词的优先级,对该分词进行再次搜索,若仍然为超时未返回的状态结果,则返回分词库进行异常排查,并对该分词在分词库中的更新状态进行更新,包括该分词的更新失败时间,不再对该分词进行搜索,同时更新对应关键词的更新状态,包括该关键词的更新失败时间,关键词库联系的词库服务器也不再对该关键词进行搜索。
本方案不对状态结果为搜索异常的分词进行怎样的异常排查进行具体限定和保护,依据各使用者所属的技术可以进行不同的异常排查方式。
基于上述处理方法,本方案还提出一种分词搜索方法,包括:按照分词的标记字段对消息队列中的分词在业务端进行搜索,得到搜索正常的状态结果、搜索异常的状态结果以及超时未返回的状态结果,并将状态结果返回分词库。
基于上述处理、搜索方法,本方案还提出一种分词处理系统,包括:
分词库,用于存储分词,以及分词对应的标记字段和更新状态;
分词服务器,用于对关键词库中的关键词进行分词处理后输入分词库,并对分词库中的分词赋予标记字段且形成分词的更新状态,以及按照分词的标记字段对分词库中的分词进行扫描,从扫描的分词中提取部分发送至消息队列;
消息队列,用于存放分词服务器扫描的分词;
业务端,用于对消息列表中的分词进行搜索,并将得到的状态结果返回分词库,以更新分词的更新状态。
更进一步地,所述分词服务器用于对分词赋予标记字段,将分词转换为结构数据,所述结构数据包括分词字段名、数据类型、描述、备注;以及形成的更新状态包括分词的入库时间、更新时间、更新失败时间。
所述业务端根据分词的标记字段对消息列表中的分词进行搜索后得到的状态结果包括:搜索正常的状态结果、搜索异常的状态结果以及超时未返回的状态结果,所述搜索正常的状态结果包括分词内容已更新或分词内容未更新。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应所述以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!