一种融入常识知识的生成式对话摘要方法与流程
本发明涉及自然语言处理领域,具体涉及一种融入常识知识的生成式对话摘要方法。
背景技术:
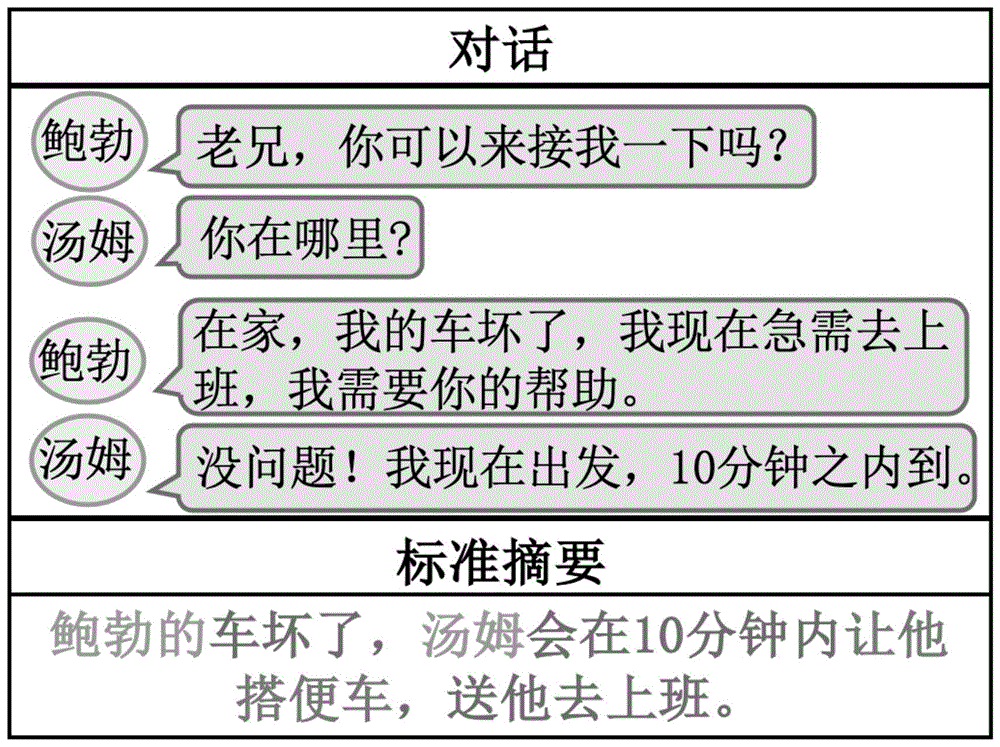
基于自然语言处理—自动文本摘要(automaticsummarization)[1](题目:constructingliteratureabstractsbycomputer:techniquesandprospects,作者:chrisdpaice,年份:1990年,文献引自informationprocessing&management)领域下的生成式对话摘要(abstractivedialoguesummarization),即给定一段多人对话的文字记录,生成一段简短的、包含对话关键信息的文本描述,如图1,展示了一个多人对话及其对应的标准摘要。
对于对话摘要,现有工作大多集中于生成式(abstractive)方法,即允许最终摘要包含原文没有的新颖的词汇和短语。例如liu等人[2][题目:automaticdialoguesummarygenerationforcustomerservice,作者:chunyiliu,年份:2019年,文献引自proceedingsofthe25thacmsigkddinternationalconferenceonknowledgediscovery&datamining]针对客服对话摘要任务,采用多步生成方式生成对话摘要,liu等人[3][题目:topic-awarepointer-generatornetworksforsummarizingspokenconversations,作者:zhengyuanliu,年份:2019年,文献引自arxivpreprint]针对医患对话摘要任务,融入主题信息建模对话,生成最终摘要。ganesh等人[4][题目:abstractivesummarizationofspokenandwrittenconversation,作者:prakharganesh,年份:2019年,文献引自arxivpreprint]利用对话篇章结构作为规则去除对话中的无用句子,然后生成对话摘要。近期,在对话回复生成[5][题目:commonsenseknowledgeawareconversationgenerationwithgraphattention.,作者:haozhou,年份:2018年,文献引自ijcai,]和对话上下文建模[6][题目:maskingorchestration:multi-taskpretrainingformulti-roledialoguerepresentationlearning,作者:tianyiwang,年份:2020年,文献引自aaai]等任务中显示,尽管目前基于神经网络的摘要模型已经有很强的学习能力,但是现有方法忽略了常识知识的利用,一方面会导致模型无法更好的理解对话文本,生成质量低的摘要;另一方面缺少常识知识,会导致生成摘要抽象性较低。通过融入显式的常识知识可以帮助模型更好的完成任务,融入常识知识的对话摘要可以帮助模型理解对话背后的高层含义;还可以作为不连贯句子之间的桥梁,帮助更好的理解对话。然而,现有的对话摘要系统却忽视了常识知识的利用。
常识知识可以帮助对话摘要系统生成更高质量的摘要。如图1,通过“接”和“车坏了”可以知道鲍勃希望汤姆让他“搭便车”,引入显式的常识知识“搭便车”,可以帮助更好的生成对话摘要。在融入常识知识之后,为了更好的建模说话人,句子和常识知识三类数据,可利用异构图神经网络建模三类数据,并生成最终摘要。
技术实现要素:
本发明是为了解决现有生成式对话摘要方法未利用常识知识而导致生成的对话摘要不准确,抽象性低的问题。现提出一种融入常识知识的生成式对话摘要方法。
一种融入常识知识的生成式对话摘要方法,包括:
步骤一、获取常识知识库conceptnet与对话摘要数据集samsum;包含的常识知识以元组的形式存在,即元组知识,表示为:
r=(h,r,t,w),
其中,r表示一个元组知识;表示头实体;r表示关系;t表示尾实体;w表示权重,表示关系的置信度;知识r表示了头实体和尾实体t拥有关系r,并且权重为w;
所述对话摘要数据集samsum分为训练、开发和测试三部分;
步骤二、利用获取的常识知识库conceptnet为对话摘要数据集samsum引入元组知识,构建异构对话图;具体过程为:
步骤三、构建对话异构神经网络模型;所述对话异构神经网络模型包括节点编码器、图编码器和解码器;
步骤三一、构造节点编码器,利用双向长短时神经网络获取节点初始化表示
步骤三二、构造图编码器,利用异构图神经网络更新节点表示,并添加节点位置编码信息和更新词语表示
步骤三三、构造解码器;
步骤四、训练步骤三中构造的对话异构神经网络模型,通过训练的对话异构神经网络模型从一段对话中生成最终对话摘要。
有益效果
融入常识知识的对话摘要可以帮助模型理解对话背后的高层含义;
融入常识知识的对话摘要可以作为不连贯句子之间的桥梁,帮助更好的理解对话;
通过引入常识知识,可以帮助模型生成更加抽象和具有概括性的摘要;
本发明在对话摘要任务中引入常识知识,将对话中的说话人,句子和常识知识三类数据建模为异构对话图,利用异构图神经网络建模整个异构对话图。
整个模型采用图到序列框架,生成最终对话摘要。解决了现有生成式对话摘要忽略常识知识利用的问题。在本发明方法进行实验后生成的摘要中,生成了更加抽象和正确的摘要,更好的概括了对话内容,显示了本发明方法的有效性,在评价指标rouge上本发明方法比现有的方法取得了更好的结果。
rouge是一种基于召回率的相似性度量方法,是评估自动文摘以及机器翻译的一组指标,考察翻译的充分性和忠实性,值越高越好。rouge-1、rouge-2、rouge-l的计算分别涉及一元语法、二元语法和最长公共子序列。
附图说明
图1为一个多人对话及其对应的标准摘要示意图;
图2为samsum对话摘要数据集对话摘要对示例;
图3为samsum数据集中对话-摘要对示例;
图4为从conceptnet中获取的相关知识三元组;
图5为本发明所构建的句子-知识图;
图6为本发明所构建的说话人-句子图;
图7为本发明所构建的异构对话图;
图8为本发明模型示意图,其中(a)异构对话图构建,(b)节点编码器,(c)图编码器,(d)解码器。
具体实施方式
具体实施方式一:本实施方式一种融入常识知识的生成式对话摘要方法,包括:
步骤一:获取大规模常识知识库conceptnet与对话摘要数据集samsum。
步骤一一、获取大规模常识知识库conceptnet:
从http://conceptnet.io/获取大规模常识知识库conceptnet;其中包含的常识知识以元组的形式存在,即元组知识,可以表示为:
r=(h,r,t,w),
其中,r表示一个元组知识;h表示头实体;r表示关系;t表示尾实体;w表示权重,表示关系的置信度;知识r表示了头实体h和尾实体t拥有关系r,并且权重为w;例如r=(打电话,相关,联系,10),表示了“打电话”与“联系”的关系是“相关”,并且权重是10;通过网址http://conceptnet.io/可以获得大规模以元组形式存在的常识知识。
步骤一二、获取对话摘要数据集samsum:
从https://arxiv.org/abs/1911.12237可以获得对话摘要数据集samsum,该数据集分为训练、开发和测试三个部分,训练、开发和测试三个部分的数量分别为14732,818,819,该划分为统一标准的固定划分;该数据集主要描述了参与者之间的闲聊等主题,且每一个对话都有对应的标准摘要;图2给出了该数据集的一个示例;
步骤二、利用获取到的大规模常识知识库conceptnet为对话摘要数据集samsum引入元组知识,并构建异构对话图;
步骤三、构造对话异构神经网络模型;该模型主要包括三个部分:节点编码器,图编码器和解码器三个部分;
步骤三一、构造节点编码器,利用双向长短时神经网络(bi-lstm)获取节点初始化表示
步骤三二、构造图编码器,利用异构图神经网络更新节点表示,并添加节点位置编码信息和更新词语表示
步骤三三、构造解码器,利用单向长短时记忆网络(lstm)解码器来生成摘要;
步骤四:训练步骤三中构造的对话异构神经网络模型,通过训练的对话异构神经网络模型从一段对话中生成最终对话摘要。
具体实施方式二:本实施方式与具体实施方式一不同的是,所述步骤二利用获取到的大规模常识知识库conceptnet为对话摘要数据集samsum引入元组知识,并构建异构对话图;具体过程为:
步骤二一、获取对话相关知识;对于一段对话,本发明首先根据对话中的词语从conceptnet中获取一系列相关元组知识,排除噪音知识,最终可以得到与给定对话相关的元组知识集合,如图4;
步骤二二、构建句子—知识图:
对于步骤二一获取到的相关元组知识中,假设存在句子a和句子b,词语a属于句子a,词语b属于句子b,如果a和b的相关知识的尾实体h一致,那么将句子a和句子b连接到尾实体h;得到句子—知识图;例如图5,句子a为“你有贝蒂的号码吗”,句子b为“劳拉上次呼叫了她”;词语a和b分别为“号码”和“呼叫”;存在相关知识元组(号码,位于,电话本)和(呼叫,相关,电话本),那么将句子a和b连接到实体“电话本”;
通过上述方式获得到的常识知识会存在多余和重复的问题,因此本发明还需要简化元组知识,通过简化知识,可以引入更加干净和质量更高的常识知识;
(1)如果句子a和b连接多个实体,那么选择边关系平均权重最高的一个,例如5所示,“电话本”的平均权重大于“日期”的平均权重,那么选择“电话本”;
(2)如果不同对句子分别连接到同一个实体,那么将该实体合并成为一个实体,例如图5所示,两个“联系”实体合并为一个“联系”实体;
步骤二三、构建说话人-句子图:
根据“说话人说的一句话”建立说话人与句子之间的边关系,得到说话人-句子图,如图6所示;
步骤二四、融合句子-知识图与说话人-句子图:
在句子-知识图与说话人-句子图中,句子部分相同,因此将句子部分合并,融合句子-知识图和说话人-句子图为最终的异构对话图;构造出的异构对话图均在说话人和句子之间存在两种边,从说话人到句子的“speak-by”边,从句子到说话人的“rev-speak-by”边;在句子和知识之间存在两种边,从知识到句子的“know-by”边,从构造出的异构对话图均存在三类节点:说话人,句子,常识知识。
其它步骤及参数与具体实施方式一相同。
具体实施方式三:本实施方式与具体实施方式一或二不同的是,所述步骤三一、构造节点编码器,利用双向长短时神经网络(bi-lstm)获取节点初始化表示
对于步骤二本发明提出的异构对话图,其中每一个节点vi包含|vi|个单词,单词序列为
其它步骤及参数与具体实施方式一或二相同。
具体实施方式四:本实施方式与具体实施方式一至三之一不同的是,所述步骤三二构造图编码器,利用异构图神经网络更新节点表示,并添加节点位置编码信息和更新词语表示
给定一个目标节点t,可以得到其邻居节点s∈n(t),其中,n(t)表示t的邻居节点集合,s表示其中一个邻居节点;给定一个边e=(s,t),表示从邻居节点s指向目标节点t的一条边,定义:(1)节点类型映射函数为:
其中,τ表示节点类型映射函数;v表示给定节点;v表示节点集合;
(2)边关系类型映射函数为:
其中,
在步骤二构造的异构对话图中,一共包含四种类型的边:speak-by,rev-speak-by,know-by,rev-know-by;对于给定边e=(s,t),s和t分别拥有来自上一层的表示
然后计算
其中,
在得到每一个邻居节点s与目标节点t之间的权重后,对所有权重进行归一化:
其中,softmax为归一化函数,att(l)(s,e,t)为最终归一化之后的分数;
将每一个邻居节点s表示
其中,
在得到
其中,
当目标节点t类型不是句子节点时,本发明利用归一化分数att(l)(s,e,t)作为权重来加权求和消息向量msg(l)(s,e,t)得到
其中,
当目标节点t类型是句子节点时,本发明区分邻居节点s的类型进行信息融合得到
其中,τ(s)表示邻居邻居节点的类型,sk表示类型为知识的邻居节点,ss表示类型为说话人的邻居节点;
针对上述两种情况分别映射得到
其中,sigmoid表示激活函数,
接着,在更新后的节点表示
最后,将更新之后的节点表示
其中,f_linear()表示映射函数,;表示向量拼接。
其它步骤及参数与具体实施方式一至三之一相同。
具体实施方式五:本实施方式与具体实施方式一至四之一不同的是,所述步骤三三构造解码器:
在得到更新后的词语表示
at=softmax(et)(12)
其中,wa表示可学习的参数,
根据上下文向量ct和解码器t时刻状态st计算词表中生成每一个词语的概率pvocab:
pvocab(w)=softmax(v′(v[st;ct]+b)+b′)(14)
其中,v′,v,b,b′为可学习的参数;[st;ct]表示st和ct的拼接;softmax为归一化函数;pvocab(w)表示生成词语w的概率;
除了从词表中生成词语,本发明模型还允许从原文中拷贝词语;首先计算生成词语的概率pgen:
其中,wc,ws,wx和bptr为可学习的参数;sigmoid为激活函数;pgen表示生成词语的概率;1-pgen表示了从原文中拷贝的概率;
因此对于一个词语w,综合考虑从词表中生成的概率和从原文中拷贝的概率,最终概率如式(16):
其中,
根据式(16),即可利用该解码器在解码每一步选择概率最大的词语作为输出。
其它步骤及参数与具体实施方式一至四之一相同。
具体实施方式六:本实施方式与具体实施方式一至五之一不同的是,所述训练步骤三中构造的对话异构神经网络模型,通过训练的对话异构神经网络模型从一段对话中生成最终对话摘要;具体过程为:
使用极大似然估计,利用samsum数据集的训练部分训练对话异构神经网络模型,在解码器解码的每一步,根据式(16)预测的词语概率和标准词语计算交叉熵损失;
对于一个对话d,给定标准摘要
其中,
根据公式(17)训练对话异构神经网络模型,利用samsum数据集的开发部分选择最好的模型,最终利用训练好的对话异构神经网络模型根据式(16)针对samsum数据集的测试部分来生成最终对话摘要。
其它步骤及参数与具体实施方式一至五之一相同。
具体实施方式七:本实施方式与具体实施方式一至六之一不同的是,所述排除噪音知识方法包括:
(1)如果元组知识中的权重w低于1,那么排除此知识;
(2)如果元组知识的关系r属于:反义词、语源上相关、语源上发源于、不同于,不期望,那么排除此知识。
其它步骤及参数与具体实施方式一至六之一相同。
具体实施方式八:本实施方式与具体实施方式一至七之一不同的是,所述简化元组知识的过程包括:
(1)如果句子a和b连接多个实体,那么选择边关系平均权重最高的一个,例如图5所示,“电话本”的平均权重大于“日期”的平均权重,那么选择“电话本”;
(2)如果不同对句子分别连接到同一个实体,那么将该实体合并成为一个实体,例如图5所示,两个“联系”实体合并为一个“联系”实体。
其它步骤及参数与具体实施方式一至七之一相同。
实施例
实施例一:
本发明对提出的模型进行了实现,同时和目前的基线模型和标准摘要进行了对比。
(1)基线模型生成的摘要:
garyandlarawillmeetat5pmfortom'sbdayparty.
(2)本发明模型生成的摘要:
garyandlaraaregoingtotom'sbirthdaypartyat5pm.larawillpickupthecake.
(3)标准摘要:
it’stom'sbirthday.laraandgarywillcometotom'splaceabout5pmtoprepareeverything.garyhasalreadypaidforthecakelarawillpickit.
根据以上实施例可以看出,本发明的模型可以生成与标准摘要更加相似的结果,通过引入常识知识,可以更好的理解对话信息。
本发明还可有其它多种实施例,在不背离本发明精神及其实质的情况下,本领域技术人员当可根据本发明作出各种相应的改变和变形,但这些相应的改变和变形都应属于本发明所附的权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!