一种基于强化时空图神经网络的交通预测方法与流程
[0001]
本发明属于交通预测技术领域,具体涉及一种基于强化时空图神经网络的交通预测方法。
背景技术:
[0002]
现有随着智能交通系统的迅速发展,交通预测越来越受到人们的关注,它是交通管理系统的重要组成部分,是实现交通规划、交通管理和交通控制的重要组成部分。交通预测不仅可以为交通管理者提前感知交通拥堵、限制车辆提供科学依据,还可以帮助出行者选择合适的出行路线,从而提高出行效率。然而道路网络中复杂的时空相关性使交通预测变得复杂。
[0003]
现有的交通预测方法有很多,所用到的道路上的传感器包括环形线圈车辆检测器、视频车辆检测器、红外传感器等,经典的自回归综合移动平均模型、卡尔曼滤波模型、支持向量机模型等方法繎取得了一定的效果,但它们都只考虑了交通状况随时间的动态变化,而忽略了路网中的空间相关性,使预测的交通状况不受路网拓扑结构的影响。为了在预测过程中加入空间特征的影响,研究人员开始引入卷积神经网络来对空间相关性进行建模。然而卷积神经网络通常用于图像、规则网格等欧式数据,无法捕获复杂的路网拓扑结构,因此在本质上无法描述空间相关性。随着图神经网络的发展,时空图建模也引起了研究人员的关注。交通数据由路网中固定位置的传感器记录下来,将这些传感器构建成一个图网络,边缘由两个节点之间的距离确定,同一节点不同时间的交通数据不仅受到其历史数据的影响,还受邻近节点的影响。因此有效提取数据的时空相关性是解决这一问题的关键。
[0004]
虽然现有的基于深度模型的交通预测模型已经取得了较高的预测精度,但仍存在一些待解决的问题。大多数现有的方法依赖于经典的序列到序列架构(seq2seq),将历史时间序列输入至编码器并使用其最终状态初始化解码器来进行预测。然而经典的seq2seq模型在训练过程中的训练损失由传感器采集的真实样本来监督,然而在测试时没有真实样本,解码器完全依赖模型自身的生成的输出来预测下一个输出,这会导致模型在训练和测试过程中产生的下一个动作存在差异,而在这个过程中产生的误差会不断累积,这种差异又称为曝光误差(exposure bias)。虽然也出现了计划采样、对抗生成网络等方法用于避免曝光误差,但这些方法都存在一些弊端,因此有效地避免曝光误差对提高预测精度来说是十分必要的。
技术实现要素:
[0005]
本发明的目的是提供一种基于强化时空图神经网络的交通预测方法,提高预测精度。
[0006]
本发明解决其技术问题的技术方案为:一种基于强化时空图神经网络的交通预测方法,包括以下步骤,
[0007]
s1:对某一时间段内传感器采集到的原始交通数据进行预处理;
[0008]
s2:将预处理后的数据集分为用于训练模型的训练集、用于验证模型的训练结果的验证集、用于对训练完成的模型进行测试的测试集;
[0009]
s3:根据传感器之间的邻接关系构建有向加权道路网络结构拓扑图g=(v,e,a),其中v为所有传感器节点的集合,e为边的集合,即相邻传感器节点之间的连接关系,a为路网拓扑图的邻接矩阵,将预处理后的数据集中的交通信息(即交通速度信息)作为节点的属性特征,用x表示g中节点的特征矩阵;
[0010]
s4:通过路网拓扑图的邻接矩阵a和有向加权道路网络结构拓扑图g中节点的特征矩阵x构建序列到序列的图神经网络模型,通过序列到序列的图神经网络模型:
[0011]
s4.1:通过路网拓扑图的邻接矩阵a和有向加权道路网络结构拓扑图g中节点的特征矩阵x建立k阶扩散图卷积dgc,在路网上用k阶扩散图卷积dgc来建模路网的空间相关性,通过随机游走捕获路网中各传感器节点上下游交通状况对该传感器节点的影响,也即路网的空间相关性;
[0012]
s4.2:通过嵌入扩散图卷积和门控递归单元gru构建时空数据编码器,将带有空间特征的时间序列输入到门控递归单元gru来提取交通数据之间的时间相关性,从而得到路网的时空相关性;
[0013]
s4.3:计算编码器内各历史时间步长的时空隐藏状态,然后将编码器的最后一个隐藏状态作为解码器的输入;
[0014]
s4.4:在编码器中加入注意力机制,计算编码器的上下文向量c;
[0015]
s4.5:在解码器中使用actor-critic算法对模型的策略参数进行优化;
[0016]
s5:训练模型,用平均相对误差mre作为损失函数;并在验证集和测试集中对模型进行验证、测试。
[0017]
s6:在测试集中,将特征矩阵x及路网拓扑图输入到训练好的模型中来预测未来的交通状况,并评估图神经网络模型的性能。
[0018]
所述步骤s1中预处理的过程为以5分钟为间隔通过道路周围的传感器来采集交通数据,提取交通数据样本的特征,通过滤波、归一化对原始数据进行处理,剔除无效的数据,得到时间序列数据;获得传感器的位置信息(经度、纬度),并对所有传感器节点进行编号,通过传感器的位置信息计算相邻传感器节点之间的距离。
[0019]
所述步骤s2中训练集中的数据占总数据的70%,验证集中的数据占总数据的10%,测试集中的数据占总数据的20%。
[0020]
所述步骤s2中的邻接矩阵a∈r
n
×
n
,其中a
ij
为邻接矩阵a中第i行,第j列的元素,若传感器节点i与传感器节点j相邻,则a
ij
=1,否则a
ij
=0;
[0021]
g中节点的特征矩阵x∈r
n
×
p
,p表示节点属性特征的数量,n表示传感器节点的个数。
[0022]
所述的步骤s4.1中的k阶扩散图卷积为:其中do-1
a,d
i-1
a
t
分别表示转移矩阵及其逆矩阵,θ∈r
k
×
2
为滤波器的参数,x为x中的一个元素,是单个时间片对应的特征矩阵,根据扩散图卷积构建扩散卷积层来捕获空间相关性。
[0023]
所述的步骤s4.4中在序列到序列模型中加入注意力机制,注意力机制的具体计算
过程为:计算第i个输入对第j个输出的影响权重,即注意力分值:e
ij
=tanh(h
i-1
,h
j
),为了便于比较不同输入对同一输出的权重系数,通过softmax函数对所有输入的注意力分值进行归一化;
[0024]
所述的步骤s4.5中将整个预测过程看作一个连续的马尔可夫决策过程mdp,一个智能体在离散时间步长t'时与环境进行交互,令m=(s,a,p,r,s
o
,γ,t),将所有传感器组成的路网拓扑结构作为智能体,门控递归单元gru作为智能体选择下一个动作(输出)的随机策略,则s为解码器隐藏状态的集合,a为智能体选择的动作集合,p为状态转移概率矩阵,r为奖励函数,s
o
为初始状态,γ为折扣因子,t为时间步;
[0025]
所述的智能体与环境交互的目标是最大化优势函数,即
[0026]
所述的优势函数a
π
(s
t
,y
t
)=q
π
(s
t
,y
t
)-v
π
(s
t
)≈r
t
+γv
π
(s
t+1
)-v
π
(s
t
),其中q
π
(s
t
,y
t
)为t时刻策略π下的状态-动作对对应的奖励函数,值函数v
π
(s
t
)为t时刻策略π下选择状态s的奖励值,r
t
为奖励函数r中的元素,表示t时刻的奖励函数;
[0027]
所述的值函数v
π
(s
t
),通过拟合一个参数为ψ的神经网络来估计值函数v
ψ
(s
t
),采用均方根误差对v
ψ
(s
t
)进行训练,即损失函数其中代表t时刻的真实奖励值。
[0028]
所述的步骤s4.5中优化策略参数是预测过程中,在t+1时刻,actor通过策略π生成预测结果critic通过计算优势函数来判别预测结果的准确性并将其反馈给actor,actor根据critic反馈的优势函数来更新策略π的参数θ以达到更准确的预测结果:actor根据critic反馈的优势函数来更新策略π的参数θ以达到更准确的预测结果:表示t时刻的预测结果,表示t-1时刻的预测结果,s
t
表示t时刻的隐藏状态,c
t-1
表示t-1时刻的上下文向量,l
θ
表示参数θ的损失函数,π
θ
表示智能体选择下一个动作的随机策略。
[0029]
所述步骤s5具体为在训练阶段,通过得到模型的预测输出和传感器节点采用的真实样本,采用梯度下降法对模型进行训练,用平均相对误差(mre)作为损失函数:并在验证集上验证模型的训练结果。迭代以上步骤,待训练次数达到预设值时停止训练,用训练好的模型在测试集上进行测试。
[0030]
所述步骤s6用平均绝对误差(mae)、均方根误差(rmse)、平均绝对百分比误差(mape)函数来评估模型的测试结果:
[0031][0032][0033]
[0034]
其中y表示t时刻传感器监测到的真实数据,表示t时刻通过模型预测得到的交通数据,y
i
代表t时刻节点i的真实值,代表t时刻节点i的预测值。
[0035]
本发明的有益效果为:本发明基于序列到序列模型的交通预测框架,它可以对道路网络的时间相关性、空间相关性进行建模,根据道路网络上下游关系将整个路网构建成一个有向加权图,通过扩散图卷积网络来捕获路网的空间相关性,提取路网的空间相关性特征,再将带有空间相关性特征的时间序列输入到递归神经网络中捕获路网的时间相关性。然后通过强化学习中的actor-critic算法在解码的过程中对预测结果进行优化。将每个时间片捕获的路网关系拓扑图看作智能体中的actor,将递归神经网络看作actor选择下一个动作(输出)的随机策略,并用critic对它选择的动作进行评判,并反馈一个优势函数,actor根据反馈的优势函数来更新策略参数,相比传统方法大大提高了预测精度。
附图说明
[0036]
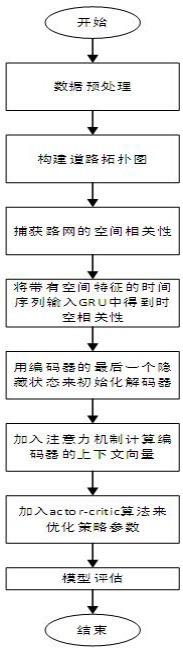
图1是本发明的流程图。
[0037]
图2为本发明的模型结构示意图。
[0038]
图3是本发明的扩散卷积门控递归网络的结构示意图。
[0039]
图4是本发明的actor-critic算法的模型结构示意图。
具体实施方式
[0040]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0041]
如图1所示,本发明包括以下步骤,
[0042]
s1:对某一时间段内传感器采集到的原始交通数据进行预处理;
[0043]
所述步骤s1中预处理的过程为以5分钟为间隔通过道路周围的传感器来采集交通数据,提取交通数据样本的特征,通过滤波、归一化对原始数据进行处理,剔除无效的数据,得到时间序列数据;获得传感器的位置信息(经度、纬度),并对所有传感器节点进行编号,通过传感器的位置信息计算相邻传感器节点之间的距离。
[0044]
s2:将预处理后的数据集分为用于训练模型的训练集、用于验证模型的训练结果的验证集、用于对训练完成的模型进行测试的测试集;
[0045]
所述步骤s2中训练集中的数据占总数据的70%,验证集中的数据占总数据的10%,测试集中的数据占总数据的20%。
[0046]
所述步骤s2中的邻接矩阵a∈r
n
×
n
,其中a
ij
为邻接矩阵a中第i行,第j列的元素,若传感器节点i与传感器节点j相邻,则a
ij
=1,否则a
ij
=0;
[0047]
g中节点的特征矩阵x∈r
n
×
p
,p表示节点属性特征的数量,n表示传感器节点的个数。
[0048]
s3:根据传感器之间的邻接关系构建有向加权道路网络结构拓扑图g=(v,e,a),其中v为所有传感器节点的集合,e为边的集合,即相邻传感器节点之间的连接关系,a为路网拓扑图的邻接矩阵,将预处理后的数据集中的交通信息(即交通速度信息)作为节点的属性特征,用x表示g中节点的特征矩阵;
[0049]
s4:通过路网拓扑图的邻接矩阵a和有向加权道路网络结构拓扑图g中节点的特征矩阵x构建序列到序列的图神经网络模型,通过序列到序列的图神经网络模型:
[0050]
s4.1:通过路网拓扑图的邻接矩阵a和有向加权道路网络结构拓扑图g中节点的特征矩阵x建立k阶扩散图卷积dgc,在路网上用k阶扩散图卷积dgc来建模路网的空间相关性,通过随机游走捕获路网中各传感器节点上下游交通状况对该传感器节点的影响,也即路网的空间相关性;
[0051]
所述的步骤s4.1中的k阶扩散图卷积为:其中do-1
a,d
i-1
a
t
分别表示转移矩阵及其逆矩阵,θ∈r
k
×
2
为滤波器的参数,x为x中的一个元素,是单个时间片对应的特征矩阵,根据扩散图卷积构建扩散卷积层来捕获空间相关性。
[0052]
s4.2:通过嵌入扩散图卷积和门控递归单元gru构建时空数据编码器,将带有空间特征的时间序列输入到门控递归单元gru来提取交通数据之间的时间相关性,从而得到路网的时空相关性;
[0053]
s4.3:计算编码器内各历史时间步长的时空隐藏状态,然后将编码器的最后一个隐藏状态作为解码器的输入;
[0054]
s4.4:在编码器中加入注意力机制,计算编码器的上下文向量c;
[0055]
所述的步骤s4.4中在序列到序列模型中加入注意力机制,注意力机制的具体计算过程为:计算第i个输入对第j个输出的影响权重,即注意力分值:e
ij
=tanh(h
i-1
,h
j
),为了便于比较不同输入对同一输出的权重系数,通过softmax函数对所有输入的注意力分值进行归一化;
[0056]
s4.5:在解码器中使用actor-critic算法对模型的策略参数进行优化;
[0057]
所述的步骤s4.5中将整个预测过程看作一个连续的马尔可夫决策过程mdp,一个智能体在离散时间步长t'时与环境进行交互,令m=(s,a,p,r,s
o
,γ,t),将所有传感器组成的路网拓扑结构作为智能体,门控递归单元gru作为智能体选择下一个动作(输出)的随机策略,则s为解码器隐藏状态的集合,a为智能体选择的动作集合,p为状态转移概率矩阵,r为奖励函数,s
o
为初始状态,γ为折扣因子,t为时间步;
[0058]
所述的智能体与环境交互的目标是最大化优势函数,即
[0059]
所述的优势函数a
π
(s
t
,y
t
)=q
π
(s
t
,y
t
)-v
π
(s
t
)≈r
t
+γv
π
(s
t+1
)-v
π
(s
t
),其中q
π
(s
t
,y
t
)为t时刻策略π下的状态-动作对对应的奖励函数,值函数v
π
(s
t
)为t时刻策略π下选择状态s的奖励值,r
t
为奖励函数r中的元素,表示t时刻的奖励函数;
[0060]
所述的值函数v
π
(s
t
),通过拟合一个参数为ψ的神经网络来估计值函数v
ψ
(s
t
),采用均方根误差对v
ψ
(s
t
)进行训练,即损失函数其中代表t时刻的真实奖励值。
[0061]
所述的步骤s4.5中优化策略参数是预测过程中,在t+1时刻,actor通过策略π生成预测结果critic通过计算优势函数来判别预测结果的准确性并将其反馈给actor,
actor根据critic反馈的优势函数来更新策略π的参数θ以达到更准确的预测结果:actor根据critic反馈的优势函数来更新策略π的参数θ以达到更准确的预测结果:表示t时刻的预测结果,表示t-1时刻的预测结果,s
t
表示t时刻的隐藏状态,c
t-1
表示t-1时刻的上下文向量,l
θ
表示参数θ的损失函数,π
θ
表示智能体选择下一个动作的随机策略。
[0062]
s5:训练模型,用平均相对误差mre作为损失函数;并在验证集和测试集中对模型进行验证、测试。
[0063]
所述步骤s5具体为在训练阶段,通过得到模型的预测输出和传感器节点采用的真实样本,采用梯度下降法对模型进行训练,用平均相对误差(mre)作为损失函数:并在验证集上验证模型的训练结果。迭代以上步骤,待训练次数达到预设值时停止训练,用训练好的模型在测试集上进行测试。
[0064]
s6:在测试集中,将特征矩阵x及路网拓扑图输入到训练好的模型中来预测未来的交通状况,并评估图神经网络模型的性能。
[0065]
所述步骤s6用平均绝对误差(mae)、均方根误差(rmse)、平均绝对百分比误差(mape)函数来评估模型的测试结果:
[0066][0067][0068][0069]
其中y表示t时刻传感器监测到的真实数据,表示t时刻通过模型预测得到的交通数据,y
i
代表t时刻节点i的真实值,代表t时刻节点i的预测值。
[0070]
交通预测问题的本质是学习一个映射函数f(
·
)通过给定的道路结构和历史t个时间步长的交通状态映射出未来t'个时间步长的交通状态,即[x
t+1
,
…
,x
t+t'
]=f([x
1
,
…
,x
t
],g);
[0071]
如图2所示为本发明的模型结构示意图,所述的步骤s4.1中的k阶扩散图卷积,即图2中的dgc为:其中do-1
a,d
i-1
a
t
分别表示转移矩阵及转移逆矩阵,θ∈r
k
×
2
为滤波器的参数。构建扩散卷积层为:其中为相关的卷积核函数,f
o
为输出特性的数量。
[0072]
将历史时间序列即历史t个时间片对应特征矩阵x
1
,
…
,x
t
输入编码器中的扩散卷积层,通过双向扩散卷积在图g上的随机游走过程从而捕获到路网上下游交通状况对该传感器节点的影响;
[0073]
如图3所示为本发明的模型中的扩散图卷积门控递归单元,可以看出历史时间序列通过dgc中的扩散卷积运算得到路网的空间相关性,然后将带有空间特征的时间序列输入到gru来提取路网的时空相关性。gru包括两个门结构:更新门和重置门,其中更新门z
t
用来控制在t时刻输入t-1时刻的交通状态信息的程度,重置门r
t
用来控制在t时刻忽略t-1时刻的交通状态信息的程度。通过gru的内部运算得到编码器的隐藏状态h
1
,
…
,h
t
,输出隐藏状态的计算过程为:
[0074]
z
t
=σ(w
z
·
[h
t-1
,x
t
]+b
z
)
[0075]
r
t
=σ(w
r
·
[h
t-1
,x
t
]+b
r
)
[0076]
c
t
=tanh(w
c
·
[(r
t
*h
t-1
),x
t
]+b
c
)
[0077]
h
t
=z
t
*h
t-1
+(1-z
t
)*c
t
[0078]
其中h
t-1
为t-1时刻交通信息的隐藏状态,x
t
表示t时刻输入的交通信息,w
z
、w
r
、w
c
和b
z
、b
r
、b
c
分别表示更新门、重置门、和记忆单元在训练过程中的权重和偏差,σ(
·
)、tanh表示激活函数。
[0079]
所述的步骤s4.4中在序列到序列模型中加入注意力机制,注意力机制的具体计算过程为:计算第i个输入对第j个输出的影响权重,即注意力分值:e
ij
=tanh(h
i-1
,h
j
),为了便于比较不同输入对同一输出的权重系数,通过softmax函数对所有输入的注意力分值进行归一化:其中softmax为激活函数,用来对相关隐藏特征进行非线性变换,然后通过注意力分值和编码器的隐藏状态的加权求和得到编码器中的上下文向量:
[0080]
将编码器中的最后一个隐藏状态h
t
=gru(x
t
,h
t-1
)来初始化解码器,解码器将当前时刻t的特征矩阵和编码器中的上下文向量c
t
作为输入,在给定隐藏状态h
t
(h
t
是编码器的最后一个隐藏状态,也就是在t时刻的隐藏状态)的条件下预测出下一个时间步即t+1时刻的输出在解码器中,将t+1时刻的预测结果作为t+2时刻的输入,让模型可以依据自身的预测结果来对下一个时间步进行预测;
[0081]
如图4所示为本发明中采用的强化学习中actor-critic算法的模型架构示意图,actor将生成的预测结果及状态s
t'
传递给critic,critic对其生成的结果进行评价(这里由于是代入真实数据,所以用这里是用t'代替t+t'),并反馈给actor一个优势函数所述的智能体与环境交互的目标是最大化优势函数,即
[0082]
所述的优势函数a
π
(s
t'
,y
t'
)=q
π
(s
t'
,y
t'
)-v
π
(s
t'
)≈r
t'
+γv
π
(s
t'+1
)-v
π
(s
t'
),其中q
π
(s
t'
,y
t'
)为t'时刻策略π下的状态-动作对对应的奖励函数,值函数v
π
(s
t'
)为t'时刻策略π下选择状态s对应的奖励值。
[0083]
所述的值函数v
π
(s
t'
),通过拟合一个参数为ψ的神经网络作为函数逼近器来估计值函数v
ψ
(s
t'
),采用均方根误差对v
ψ
(s
t'
)进行训练:其中
为t'时刻的真实奖励值。
[0084]
解码器在预测过程中,在t+1时刻,actor通过策略π生成预测结果critic通过计算优势函数来判别预测结果的准确性并将其反馈给actor,actor根据critic反馈的优势函数来更新策略π的参数θ以达到更准确的预测结果:
[0085]
本发明基于序列到序列模型的交通预测框架,它可以对道路网络的时间相关性、空间相关性进行建模,根据道路网络上下游关系将整个路网构建成一个有向加权图,通过扩散图卷积网络来捕获路网的空间相关性,提取路网的空间相关性特征,再将带有空间相关性特征的时间序列输入到递归神经网络中捕获路网的时间相关性。然后通过强化学习中的actor-critic算法在解码的过程中对预测结果进行优化。将每个时间片捕获的路网关系拓扑图看作智能体中的actor,将递归神经网络看作actor选择下一个动作(输出)的随机策略,并用critic对它选择的动作进行评判,并反馈一个优势函数,actor根据反馈的优势函数来更新策略参数,相比传统方法大大提高了预测精度。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1