一种可控情感与风格的古诗生成方法与流程
[0001]
本发明属于人工智能技术领域,涉及古诗文本生成技术,特别涉及一种可控情感与风格的古诗生成技术。
背景技术:
[0002]
古诗生成系统旨在根据用户需求,生成用户满意的押韵诗歌,这首先需要写诗系统要能根据用户提供的文本信息分析、抽取、概括出适合古诗的关键词,通过关键词与用户的其他需求进行古诗生成与校正。在古诗生成之后,写诗系统还要能进行自动评分与交互,继续修改与润色生成的古诗。
[0003]
目前,古诗生成领域已有许多可以生成押韵且满足用户需求诗歌的模型,但这些模型都仅仅只能根据单个关键词生成诗句,导致生成的古诗通常前言不搭后语,语意连贯度不高。并且这些模型没有同时考虑到风格、情感对于古诗的影响,因此,这些模型生成的诗句缺乏多样性,且大多数是和用户意图不匹配的。能根据用户给定的多个关键词、情感、风格自动生成押韵古诗的系统,具有很高的应用价值且可以更好地实现生成古诗的适配性与多样性。
技术实现要素:
[0004]
为解决上述问题,本发明根据解码器预训练模型和带掩膜的自注意力机制,提出了一种可控情感与风格的古诗生成方法。本方法首先利用人工本方法人工检索与机器自动计算相似度相结合的方法,对训练古诗语料库按情感标签、风格标签、主关键词标签细粒度分类,预处理后利用解码器模型进行预训练。本方法其次可以根据用户的文本信息筛选、校正、分配出主关键词标签与副关键词标签,并将前者与给定的格式标签、风格标签、情感标签进行组合形成标签集,与副关键词标签共同作用实现古诗生成。本方法最后还支持用户对生成古诗进行评分与交互,实现修改与润色的功能。本方法生成的押韵古诗可以同时满足风格、情感的限制且具有更多的关键词标签,更好地理解了用户需求,同时也进一步增强了古诗的多样性,本发明提供了一种可控情感与风格的古诗生成方法,包括如下模块:
[0005]
1)古诗分类:对收集的海量古诗依据风格标签、情感标签、主关键词标签进行分类,根据预先人工精确分类的有标签古诗,采用诗词向量的余弦距离判断相似度的方法对无标签古诗进行风格、情感分类,采用检索同义词的方法对对无标签古诗进行主关键词分类,
[0006]
将每首语料库古诗预处理成统一格式,输入解码器模型进行预训练;
[0007]
2)古诗生成:采用带掩膜的自注意力机制屏蔽到后续信息,增强对标签的关注并实现古诗生成,首先对输入的文本进行关键词筛选、关键词校正和关键词分配,将文本分词后筛选出概括性关键词,并根据古诗语料进行校正,分配出主关键词标签与副关键词标签,之后,将用户给定的格式标签、风格标签、情感标签和主关键词标签包装成标签集,解码器预训练模型再根据模块1)分类的训练语料库、标签集与副关键词标签自动生成关联诗句,
且进行格式和韵律的检查;
[0008]
3)古诗评分和交互:本方法对传统文本生成的评价指标进行微调,令其适用于古诗生成评价,并将训练语料中的名诗名篇标记为优秀集,对模块2)生成的古诗质量进行自动评分,同时也支持人工对其情感标签、风格标签的契合度进行评分;用户还可以对生成诗歌不满意的位置进行修改与润色,并且本方法会对指定修改位置提供替换词,以达到人机交互、共同润色的作用。
[0009]
作为本发明进一步改进,步骤1)中对收集的海量古诗依据风格标签、情感标签、主关键词标签进行分类,采用人工检索与机器自动计算相似度相结合的方法,构建按情感标签、风格标签、主关键词标签细粒度分类的训练古诗语料库和由名诗名篇组成的优秀集,本方法能依据前者进行自关联训练,依据后者和微调后的评价指标进行自动评分。
[0010]
作为本发明进一步改进,步骤2)中对输入预处理增设关键词分配环节,根据筛选、校正后的概括性关键词和预先设置的标准主关键词来确定唯一的主关键词标签,其余均作为副关键词标签,以此达到多个关键词标签同时限制生成古诗的效果。
[0011]
作为本发明进一步改进,步骤2)中依据用户给定的格式标签、情感标签、风格标签和主关键词标签包装成标签集,自动生成古诗,并在生成诗句时自动关联副关键词标签,以此达到情感、风格、多关键词可控的效果,最后本方法还对古诗进行筛选,剔除不满足格式、押韵需求的古诗。
[0012]
与现有技术相比,本发明具有如下优点和有益效果:
[0013]
本方法采用诗词向量的余弦距离的方法半监督地进行风格、情感分类,利用检索同义词的方法进行主关键词分类,构建了细粒度分类的训练古诗语料库。本发明能有效地将用户的文本需求通过关键词筛选、关键词校正和关键词分配形成概括性的主关键词标签与副关键词标签,通过多个关键词可以更好地表达用户需求。本发明还添加了用户给定的风格标签与情感标签,与传统的写诗系统相比,本方法可以生成风格多元、情感多元的诗歌,在加强古诗多元性的同时也能更加贴合用户需求。本方法还提出了一种适用于古诗生成的评价指标,能够实现机器自动评分,并能与用户进行交互实现指定位置的修改与润色,达到人机交互、共同润色的效果。现有的大多数模型缺乏语意连贯度与丰富度,而本方法因为考虑到了多个关键词和诗歌整体的情感、风格,所以生成的古诗具有更好的连贯度与丰富度,可以更好地满足用户需求。
附图说明
[0014]
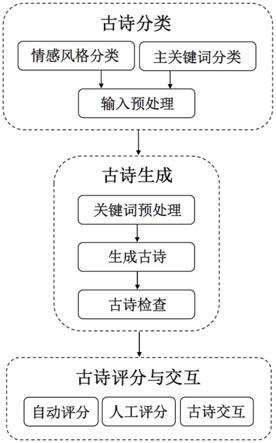
图1为本发明提供的可控情感与风格的古诗生成方法的逻辑流程图。
[0015]
图2为古诗生成模块中关键词预处理的逻辑流程图。
[0016]
图3为古诗生成模块中生成古诗的逻辑流程图。
[0017]
图4为古诗分类模块的示例。
[0018]
图5为由给定文本信息生成古诗的示例。
具体实施方式
[0019]
下面结合附图与具体实施方式对本发明作进一步详细描述:
[0020]
本发明提供一种可控情感与风格的古诗生成方法。本方法生成的押韵古诗可以同
时满足风格、情感的限制且具有更多的关键词标签,更好地理解了用户需求,同时也进一步增强了古诗的多样性。
[0021]
本发明提供的可控情感与风格的古诗生成方法,其中逻辑流程图如图1所示,古诗生成模块中关键词预处理的逻辑流程图如图2所示,古诗生成模块中生成古诗的逻辑流程图如图3所示,古诗分类模块的示例如图4所示,具体包括如下模块:
[0022]
1)古诗分类:对收集的海量古诗依据风格标签、情感标签、主关键词标签进行分类,将每首语料库古诗预处理成统一格式,输入解码器模型进行预训练。包括以下环节:
[0023]
a)风格情感分类,本方法首先根据收集的海量古诗,人为确定若干个标准风格标签与标准情感风格,并筛选出有标签的古诗作为参照。其次,采用诗词向量的余弦距离度量,因为诗词向量糅合了整句诗歌的词,忽略了字词具体意义而具有整体性,可以用来判断风格与情感。通过分类,每首古诗语料会具有唯一的风格标签与情感标签,同时本方法也支持人为对其中不符合分类目标的古诗语料进行再分类。
[0024]
b)主关键词分类,与环节a)类似,根据收集的海量古诗,人为确定若干个标准主关键词标签,例如“春”、“秋”、“酒”、“月”等,通过人工检索同义词的方式为每首古诗语料确定唯一的主关键词标签,保证每个标准主关键词标签有相近的语料数目,同时本方法也支持人为对其中不符合分类目标的古诗语料进行再分类。
[0025]
c)输入预处理,对收集来的海量古诗语料进行统一的规格化预处理,将环节a)和环节b)确定的风格标签、情感标签、主关键词标签以及自身的格式标签包装成标签集,即“格式标签【tag1】主关键词标签【tag2】风格标签【tag3】情感标签”,而古诗语料的输入预处理操作为“【cls】标签集【body】古诗语料【eos】”。海量古诗语料经过输入预处理后,统一作为输入通过解码器模型进行预训练。例如对孟浩然的《春晓》,“春眠不觉晓,处处闻啼鸟。夜来风雨声,花落知多少。”,确定其格式标签为五言绝句,主关键词标签为“春”,风格标签为写景诗,情感标签为积极,随后将以上标签包装成标签集,即“五言绝句【tag1】春【tag2】写景诗【tag3】积极”。
[0026]
2)古诗生成。本方法首先对输入的文本进行关键词预处理,即关键词筛选、关键词校正和关键词分配,再将给定的格式标签、情感标签、风格标签、主关键词标签,并统一包装成标签集供解码器预训练训练,同时实时关联副关键词标签以达到多标签生成的效果,具体做法是:
[0027]
a)关键词筛选,本方法首先对文本进行分词,对分词后的字词w,按如下方法计算其权重:weight(w)=a*tf(w)+(1-a)*tr(w),其中tf(w)和tr(w)分别代表w的td-idf值和textrank分数,a代表用来平衡二者的权重的超参数,筛选出weight分值较高的k个关键词。例如,在朱自清的散文《春》中,本方法可以筛选出“春天”、“小草”、“花”、“短笛”。为了避免自注意力的分散与实现诗歌多样化展现,本方法将从这weight分值较高的k个关键词中随机取样k个概括性关键词,例如“春天”和“小草”。这些筛选后的概括性关键词将通过校正,映射为古诗语料库中可用的关键词。
[0028]
关键词校正,考虑到许多现代词汇无法直接出现在古诗中,本方法还对筛选出来的k个概括性关键词进行校正。本方法预先准备了两个语料库,分别代表字语料库与词语料库,是对数十万首诗歌进行分词并按照词频排序产生的。之后,通过判断概括性关键词与语料库的相似程度,确定一一校正后的关键词。例如,当输入k个概括性关键词分别为“月亮”、
“
梅花”、“长安”时,一一校正后的关键词分别为“月”、“梅”、“长安”。
[0029]
关键词分配,本方法将k个校正后的关键词分配成主关键词标签和副关键词标签,其中主关键词标签将在训练时作为标签集使用,副关键词标签则在生成古诗时实时关联。分配时,通过判断标准主关键词标签与校正后的概括性关键词的相似程度,确定唯一的主关键词标签,其余均作为副关键词标签。
[0030]
b)生成古诗,本方法利用解码器预训练模型,其带掩膜的自注意力机制能更好地捕捉前续标签的信息,即加强对古诗标签集的注意力,保证了本方法的可实施性。首先将用户给定的格式标签、风格标签、情感标签和环节a)分配的主关键词标签包装成标签集,即“格式标签【tag1】主关键词标签【tag2】风格标签【tag3】情感标签”,作为输入通过解码器模型生成古诗。
[0031]
在生成古诗时,本方法除了要考虑标签集的限制,还需要利用副关键词标签进行控制。因此,本方法在生成古诗时将从模型原始预测的候选词中选择与副关键词关联度更高的词作为输出。为了增加诗歌的丰富性与多样性,在选择原始预测的候选词时采用top-k stochastic sampling策略,选取权重较高的词作为候选词,从其中选取与副关键词标签相似程度更高的值作为最终输出。
[0032]
c)古诗检查,为了进一步提高生成古诗的质量,本方法还需要对生成的古诗进行格式与押韵的检查,对格式、韵律严重不满足要求的古诗进行自动修改。因此,本方法也预先准备了韵律表以校正韵律。即在押韵位置除了要进行输出词语的筛选外,还要进行韵律的检查,保证生成的古诗满足通用的押韵要求。
[0033]
3)古诗评分与交互。在生成古诗之后,本方法还可以根据预先整理的优秀集自动为古诗评分,同时也允许用户对不满意的位置进行字句修改与润色,在修改的同时本方法也会为用户提供替换词给用户选择,达到人机交互、共同润色的效果,具体做法是:
[0034]
a)古诗评分,本方法支持机器自动评判,依据传统文本生成任务中的评分函数bleu和rouge进行微调,使其适应于古诗生成的评分。本方法预先根据古诗语料库收集了古代名诗名篇作为优秀集,并根据微调后的评分函数与优秀集评分,衡量生成古诗与优秀集的相似程度。
[0035]
除了针对古诗质量的评分函数之外,本方法还支持人工评分,主要针对与风格与情感分类的契合度。同一组主副关键词标签,搭配不同的情感标签、风格标签可以产生多首互不相同的诗歌,人工针对生成古诗的风格、情感分类的契合度可以用作判断本方法是否做到风格可控、情感可控的标准。
[0036]
b)古诗交互,本方法支持用户对生成古诗中的不满意语句进行修改。用户指定位置后,本方法可以重新获取标签集、副关键词标签、该位置前的生成诗句作为解码器预训练模型输入,生成若干替换词给用户进行参考,用户可以选择替换词或自定义从而对生成古诗进行修改与润色。例如,用户对“秋声长安城”中的“声”不满意,可以对其进行修改与润色,系统会自动给出若干替换词“来”、“风”、“入”、“深”为用户进行选择,用户可以选择其中之一或自定义替换词,最终达到人机交互、共同润色的效果。
[0037]
作为本发明可控情感与风格的古诗生成方法,本发明提供了一种可控情感与风格的古诗生成方法,下面通过给定文本信息生成古诗的示例,实施案例介绍本发明的实施过程。相应的图示参见图5。
[0038]
用户输入文本信息为朱自清的散文《春》,格式标签为七言绝句,情感标签为消极,风格标签为婉约诗。
[0039]
1)编码器预训练模型:
[0040]
本实施案例采用gpt-2模型进行预训练,其相比于传统的rnn模型与lstm模型可以捕捉到更长范围的信息,且并行效率更高。gpt-2模型的核心思想是用无监督训练模型做有监督任务,主要由以下模块组成:输入模块,由能表征单词并捕获其意义的嵌入向量与位置编码组成;masking self-attention模块,屏蔽后续信息,利用query向量、key向量、value向量计算注意力得分并加权求和获得输出;前馈神经网络模块,通过两层权重矩阵进行训练;残差网络模块,优化网络并解决网络退化问题。
[0041]
为了增加诗歌的语意丰富性与语意连贯性,在选择候选词时采用的top-k stochastic sampling策略中k通常设置成15,即选取15个权重较高的词作为候选词,随后从其中选取与副关键词标签相似程度更高的值作为最终输出。同时,为了避免生成古诗的冗余问题,本方法还使用惩罚因子避免单词的重复。
[0042]
2)古诗生成:
[0043]
本方法根据自清的散文《春》提取出k=4个weight分值较高的关键词,分别为“春天”,“小草”,“花”,“短笛”,筛选出其中k=2个关键词作为概括性关键词,例如“春天”和“小草”,经过关键词校正后将其分别校正为“春”和“草”。因为“春”在预先设置的标准主关键词中,因此选定“春”为主关键词标签,而“草”作为副关键词标签。
[0044]
关键词预处理环节后,本方法将用户给定的格式标签、主关键词标签、风格标签和情感标签包装为标签集,即“七言绝句【tag1】春【tag2】婉约诗【tag3】消极”,输入gpt2模型生成诗句并经过机器自动的格式检查、韵律检查后,得到古诗“春阴寒食草青时,花落莺啼杨柳枝。游子去来人不见,今年折尽别离诗。”[0045]
3)古诗评分与交互:
[0046]
对bleu和rouge中n-gram对应的权重进行如下调整:考虑到n=1时,评分函数衡量的是生成字在优秀集出现的频率,均为100%且无参考意义,因此权重设置为0;考虑到n>4时,出现频率很低且不利于诗歌的多样性,同样无参考意义,权重设置为0;对n=2和n=3的n-gram附以更高的权重,因为这两者可以更好的衡量古诗与优秀集的相似程度从而进行评分,在保证连贯度优先的情况下又保证了古诗的多样性。
[0047]
根据微调后的古诗生成评分函数,生成诗句具有0.647的分数,代表与名诗名篇组成的优秀集有64.7%的相似度,且人工评分也证实其诗带有强烈的婉约风格与消极情感,例如“杨柳枝”、“游子”、“别离诗”等均有强烈的隐喻意,婉约地暗示离愁别绪。针对生成诗句,用户如果想修改其中的“年”,系统会自动给出4个替换词“朝”、“日”、“夜”、“昔”为用户进行选择。
[0048]
为比较不同风格标签、不同情感标签、不同主副关键词标签的区别,以下实施案例可进一步展示本发明的效果:
[0049]
如果仅仅修改风格标签,将“婉约诗”改为“豪放诗”后,解码器预训练模型将生成诗句“江草连天春欲暮,绿杨千里花无主。杜鹃啼处不知归,门掩青山芳意苦。”其中“江草连天”、“绿杨千里”、“杜鹃”等带有明显的豪放、雄浑的风格,说明本方法可以较好地实现风格可控的效果。
[0050]
如果仅仅修改情感标签,将“消极”改为“积极”后,解码器预训练模型将生成诗句“东风吹鬓蝉声里,西窗草阁闲庭砌。今朝小病无人来,春暖花香一炷起。”其中“闲庭砌”、“春暖花香”等词汇不同于消极,体现着慵懒、惬意的积极情感,说明本方法可以较好地实现情感可控的效果。
[0051]
因为“草”本身不在预先设置的标准主关键词中,我们以下实施案例考虑关键词“春”与“月”,格式、风格、情感标签均不变动。
[0052]
如果将“春”作为主关键词标签,“月”作为副关键词标签,解码器预训练模型将生成诗句“春水无边客思家,夜来风月隔江花。不知身处烟霞色,那识流年鬓上华。”其中“春水”、“江花”、“流年”等意象均常见于描写春天的诗歌,而“月”作为副关键词只在前文“风月”中点缀般提到,之后因为惩罚因子的存在而权重骤减。
[0053]
如果将“月”作为主关键词标签,“春”作为副关键词标签,解码器预训练模型将生成诗句“春风吹梦婵娟影,遗恨如丝展画屏。多情无复怀旧约,正道何处问新亭。”其中“梦”、“婵娟影”、“遗恨”、“画屏”等意象均常见于描写月亮和夜晚的诗歌,而“春”作为副关键词只在前文“春风”中点缀般提到,之后因为惩罚因子的存在而权重骤减。
[0054]
以上两个实施案例共同说明主关键词能整体控制生成古诗,使生成古诗有更强的凝聚力与语意连贯性,而副关键词只能点缀般控制前文部分词句,增加生成古诗的多元性与语意丰富度。
[0055]
以上所述,仅是本发明的较佳实施例而已,并非是对本发明作任何其他形式的限制,而依据本发明的技术实质所作的任何修改或等同变化,仍属于本发明所要求保护的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1