一种基于日志挖掘的微服务故障预测方法与流程
1.本发明涉及一种基于日志挖掘的微服务故障预测方法,属于软件技术领域。
背景技术:
2.微服务应用通常有多个微服务运行在数量众多的服务器上,生产环境中的基础设施或应用错误经常会引起微服务故障,因此在测试环境中诊断微服务应用故障具有挑战性。在云基础设施层,可以通过故障预测、虚拟机分配和迁移等技术手段处理故障(jawwad ahmed, et al. online approach to performance fault localization for cloud and datacenter services. in proc. ifip/ieee symposium on integrated network and service management. 873
–
874.)。在软件应用层,故障依赖于开发者通过代码审查、测试和调试的方式修复故障(elton alves, et al. 2011. fault localization using dynamic slicing and change impact analysis. in proc. 26
th ieee/acm international conference on automated software engineering. 520
–
523.)。已有方法匹配使用故障注入产生的相似故障,仅具有一定泛化能力且不支持故障识别(daniel joseph dean, et al. 2016. perfcompass: online performance anomaly fault localization and inference in infrastructure-as-a-service clouds. ieee trans. parallel distrib. syst. 27, 6 (2016), 1742
–
1755.)。然而,微服务应用由于具有复杂的交互和动态的运行时环境,难以检查并处理故障。微服务应用根据资源和性能需求,动态创造或销毁众多微服务实例,实例间交互复杂,且每个实例都涉及数十个微服务调用链。环境配置不当、微服务实例错误、异步交互问题都可能导致运行时故障的出现。因而,在生产环境中,使用微服务的日志信息检测并定位故障问题具有可行性。日志通过开发者在应用中写下的记录语句产生,在应用程序执行时记录其内部执行的时间和状态。但应用程序日志通常以任意的临时方式记录,对错误诊断的作用有限。已有方法使用日志方式检测异常或预测基于云系统产生的故障,这些日志由操作系统、分布式文件系统和容器编排系统等基础软件产生,因而只能检测发生在计算或存储节点的云基础设施中的异常或故障。
技术实现要素:
3.本发明的目的:通过挖掘系统追踪日志对微服务应用进行潜在错误预测和故障定位。
4.本发明的原理:本发明挖掘系统日志,预测多实例故障、配置故障和异步交互故障等与微服务交互和运行时环境具体相关的常见故障。与分析内部运行状态和逻辑产生的故障不同,这些故障与外部追踪日志的特征相关,比如微服务实例的数量、全局变量或本地缓存的权限、资源消耗和执行命令等特征。本发明从追踪日志中提取反映微服务动态环境和交互的特征并训练了基于该特征的预测模型,预测潜在错误可能导致的故障。该方法基于相关分析提取的追踪日志,结合了系统和微服务层的预测。系统层预测,利用在其特征向量中特定于应用程序的上下文,并在训练预测过程中把追踪实例作为整体来对待。微服务层
预测,以无上下文的方式使用微服务功能,基于模型预测目标服务的故障类型。
5.本发明技术解决方案:一种基于日志挖掘的微服务故障预测方法,其特点在于实现步骤如下:第一步,错误注入:将不同类型的错误注入到应用的不同部分以产生存在故障的目标应用。对于每个错误版本,以半自动化的方式注入一种类型的错误到一个特定的微服务,并为每种类型的故障设计一种故障注入策略。每个故障注入策略具有以下参数:指定微服务错误注入位置的前提条件;指定如何生成一个补丁以转化微服务为故障微服务的代码转化方法;指定是否注入错误引起故障的预期症状。为了将特定类型的故障注入目标应用程序,首先确定应用程序中错误注入的位置,并且在该位置加入错误代码以引入故障,检测故障微服务是否能够成功编译,如果不能则将人工修复编译问题。通过多次执行测试用例以验证故障注入结果,如果在其中一种执行中观察到预期的故障症状,该故障注入即被认为是成功的,每个成功注入的故障都会合并到目标应用程序中以产生故障版本。
6.第二步,执行控制:自动部署原始和注入错误的目标应用,使用现有的测试案例执行应用并收集追踪日志。对于错误版本,改变应用的运行环境以使应用在不同的设置下执行,包括不同的微服务实例数量、环境配置参数和异步交互序列。对于每种设置,随机次数执行涉及故障微服务的测试案例,以得到多个在同等设置下的追踪实例。在应用和其错误版本执行期间,持续收集追踪日志,包括每个追踪实例的微服务调用序列、环境配置、资源消耗、微服务实例数量等,为预测模型提供所需的特征。
7.第三步,构建训练数据集:对于每个追踪实例,通过提取追踪层特征并标出其错误状态、故障类型和故障定位,生成系统追踪层的训练样本。对于每个在追踪实例中的微服务,提取微服务层特征并标注其错误状态,生成微服务层的训练样本。然后,进行特征提取,在追踪实例中提取微服务层特征,汇总这些微服务层特征至系统追踪层特征。追踪实例的错误状态可以是0或1,0表示追踪实例有一个潜在错误,而1表示其他情况,包括追踪实例没有错误或者有其他未知错误的情况。如果追踪错误状态是1,标注该相应追踪层训练样本的错误状态为1并标注每个微服务层训练样本的错误状态为“无错误”。如果追踪错误状态为0,标注相应追踪层训练样本为0,它的故障类型标注为注入故障类型,并将它的故障位置标注为故障微服务,并标注其故障类型。
8.第四步,模型训练:运行原始应用和注入不同种类故障的错误版本,并使用相应的测试案例。在这个过程中,应用使用不同的设置执行,如实例数目,环境配置和异步调用执行顺序等。在训练预测模型之前,使用标准化的预处理训练数据方法,包括清洗、类别编码、离散化和特征缩放。清洗将训练样本中丢失的数据置换为典型的值,即连续值的表示和最频繁出现的值;类别编码过程将分类值转换为从0到n-1的整数值,其中n是特征的编码数字;离散化过程通过将值的范围划分为k个分区使连续值,转化为从0到k-1的整数值;特征伸缩则将特征值范围归一化至[0,1]。使用贝叶斯分类器、knn、神经网络等机器学习技术以训练预测模型。贝叶斯分类器是一种针对在训练时间构造众多决定树并且输出个别树的的类别模式的分类整体学习技术;knn是一种通过多个邻居的投票决定对象类的无参分类技术神经网络是一种将一组输入数据映射到一组适当输出的前馈人工神经网络模型。使用网格搜索技术优化这些分类模型,从由一些初始参数指定的参数网格值中详尽地生成候选对象,然后扫描所有可能的组合以寻找最好的交叉验证分数。
[0009]
第五步,特征提取和预测:从追踪日志提取微服务层和系统追踪层特征,使用预测模型预测潜在错误、故障定位和类型。使用了模型以预测追踪实例是否有潜在错误,并决定追踪层预测是否具有所需的置信度。如果置信度高于预定义的阈值,则使用模型预测故障微服务和故障类型。
[0010]
本发明与现有技术相比具有如下优点:已有方法使用日志方式检测异常或预测基于云系统产生的故障,这些日志由操作系统、分布式文件系统和容器编排系统等基础软件产生,因而只能检测发生在计算或存储节点的云基础设施中的异常或故障。本发明从追踪日志中提取了反映微服务动态环境和交互的特征,训练了基于该特征的预测模型,这些预测模型不仅能应用于定位故障也能通过预测由故障导致的潜在错误识别这些故障,定位故障位置,分析故障原因。
附图说明
[0011]
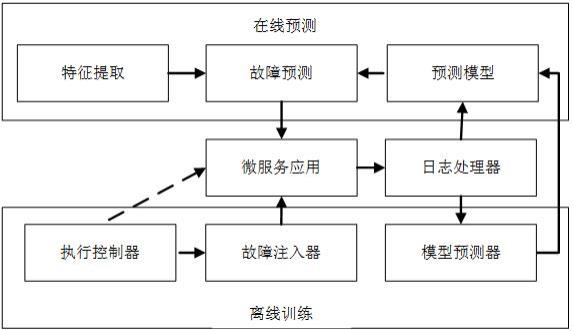
图1为基于日志挖掘的微服务故障预测技术架构图。
具体实施方式
[0012]
以下结合具体实施例和附图对本发明进行详细说明,如图1所示,本发明实施例方法流程:方法包括离线训练阶段和在线预测阶段。离线训练阶段,在测试环境下执行目标应用,根据收集的追踪日志训练预测模型,需要成功执行下和错误执行下的追踪日志。使用故障注入策略以获得应用的错误版本,使用自动化测试案例执行应用及其错误版本以产生追踪日志。测试案例模拟来自客户的用户请求并产生微服务调用链,测试过程在受控部署环境下运行,使得应用在不同的配置下执行。然后,收集并分析执行产生的追踪日志为预测模型训练建立数据实例库。对于每个追踪实例,通过特征提取和故障标记构造追踪层训练样本和微服务层训练样本,同时使用机器学习技术训练是故障发生、故障位置和故障类型的预测模型。在线故障预测阶段,监测应用在生产环境的执行,持续收集并分析运行中应用的追踪日志,对于每个追踪实例,以类似于准备训练数据集时使用的方式提取特征,然后使用预测模型预测是否发生潜在错误,错误驻留于哪个微服务和故障的类型。方法实现包括四个主要组件:故障注入器、执行控制器、日志处理器和模型预测器。
[0013]
错误注入器:使用javaparser(https://javaparser.org/)解析微服务应用和操作微服务的源代码,以实现错误注入,同时也可以使用其他解析器以支持用其他语言实现的微服务应用的错误注入。
[0014]
执行控制器:使用testng(https://testng.org/doc/index.html)实现了测试用例的自动调度和执行。在基础设施层,集成了kubernetes(https://kubernetes.io/)和istio(https://istio.io/)以实现离线培训中的自动微服务应用程序部署、配置和运行时操作。使用kubernetes rest api动态部署微服务应用程序并管理微服务实例及其环境配置。使用istio实现网络通信的智能代理,以控制同步微服务调用的执行/返回序列。
[0015]
日志处理器:使用kubernetes和istio来捕获跟踪日志,为了捕获所需的变量访问信息,使用jdk捕获运行时jvm线程转储和堆转储,并分析调用堆栈和转储中的变量值。包括一个收集和处理跟踪日志的管道,管道运行基于spring boot(http://
projects.spring.io/spring-boot/)的restful服务来收集istio生成的分布式日志数据,并使用kafka (http://kafka.apache.org/)流处理日志数据,然后使用spark (http://spark.apache.org/)对数据进行处理,生成训练样本,并使用hdfs (http://hadoop.apache.org/)存储处理后的数据。
[0016]
模型预测器:使用用于python的机器学习库scikit-learn(https://scikit-learn.org/)进行模型训练,并基于得到的模型预测故障及其位置和类型。。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1