一种基于风机运行数据的风电项目发电量评估方法与流程
本发明属于风力发电技术领域,更具体地,涉及一种基于风机运行数据的风电项目发电量评估方法。
背景技术:
风电项目发电量的准确评估对于项目投资决策与运维管理而言至关重要。
目前行业中针对已投运风电项目的发电量评估,主要采用以下方法,一是直接采用设计阶段的前期测风数据、地图、机组实际布置与功率曲线等对项目发电量进行重新复核,将重新复核结果作为项目的投资决策与运维管理依据;二是基于项目投运后的完整年实际运行数据与运维信息,对发电量进行复核,将复核的发电量结果作为项目的投资决策与运维管理依据。
实际中经常存在项目全部风电机组尚未稳定投产一年,不具备完整年投运数据,且项目前期测风塔不具备代表性或已被拆除,在这种复杂情况下仍需有效评估项目实际年发电量的情况,这种情况如果仅采用对设计的重新复核,将可能造成设计复核的发电量结果与项目实际发电量存在较大偏差的风险。
技术实现要素:
本发明目的在于提供一种基于风机运行数据的风电项目发电量评估方法,其能够针对投产未满一年的风电项目,充分利用已运行的机组与机组间数据,对项目所处年发电量与代表年发电量进行评估,从而提高对项目发电量评估的准确度。
本发明采用如下技术方案来实现的:
一种基于风机运行数据的风电项目发电量评估方法,包括以下步骤:
1)调取项目每台风电机组稳定并网运行以来的scada数据,以及风电场运行维护记录,拟合出每台风电机组功率曲线,即scada平均风速-有功功率曲线;
2)利用同期相关性数据源以及邻近风电机组间同期scada风速相关性,将所有风电机组插补出一套同期完整日历年的scada平均风速时序数据;
3)利用长期相关性数据源,将以上步骤2)中的每台机组完整日历年scada平均风速时序数据订正成代表年scada平均风速时序数据;
4)结合每台机组拟合的功率曲线与同期完整日历年scada平均风速时序数据,计算出每台风电机组运行同期完整日历年发电量;
5)结合每台机组拟合的功率曲线与代表年scada平均风速时序数据,计算出每台风电机组代表年发电量。
本发明进一步的改进在于,步骤1)中,所述调取的风电机组稳定并网运行以来的scada数据包括10min平均风速、10min平均有功功率、风电机组状态码时序、风电机组限电码与结冰状态码时序。
本发明进一步的改进在于,步骤1)中,所述风电场运行维护记录包括风电机组故障记录与检修台账、电站工作票与操作票、电网调度记录、电网停电纪录。
本发明进一步的改进在于,步骤1)中,所述拟合出每台风电机组功率曲线中,剔除风电机组非正常并网状态、风电机组限功率、叶片结冰、风电机组定检与故障检修、电网停电或限电的数据点。
本发明进一步的改进在于,步骤1)中,所述风电机组功率曲线拟合采用“区间法”。
本发明进一步的改进在于,步骤2)中,所述利用同期相关性数据源包括同期气象站数据源或同期中尺度数据源,具体采用哪种数据源根据数据源的可获得性、数据源同机组scada平均风速的相关性程度r的大小进行决定。
本发明进一步的改进在于,步骤2)中,所述利用同期相关性数据源以及邻近风电机组间同期scada风速相关性,插补出同期完整日历年的风电机组scada平均风速时序数据的步骤包括:首先选择项目投运时间最长的机组,将该风电机组scada风速时序数据与同期相关性数据源的风速数据进行相关性分析,当相关性r大于0.6时,则判定相关性较好,进而利用同期相关性数据源将该风电机组插补成完整日历年的scada平均风速时序数据;第二、对其他风电机组,先利用其机组同临近相关性r大于0.8且运行时段长的风电机组进行风速数据相关性分析与插补,然后对风电机组统一缺少的不足完整日历年时段,则采用同期相关性数据源与该风电机组已通过临近机组插补完后的数据进行相关性分析,当相关性r大于0.6时,则判定相关性较好,进而利用同期相关性数据源将该其他机组插补成完整日历年的scada平均风速时序数据。
本发明进一步的改进在于,步骤2)中,所述利用长期相关性数据源包括长期气象站数据源或长期中尺度数据源,根据同期相关性数据源遴选中确定的相关性程度较高的那个数据源作为长期数据源。
本发明进一步的改进在于,步骤5)中,所述风电机组同期完整日历年与代表年发电量计算采用以下公示计算:
本发明与现有技术相比,具有如下有益的技术效果:
本发明为投产未满一年项目发电量的准确评估,提供了有益的解决方法;评估过程中对风电机组已投运实际数据进行了充分利用,该数据源自各机位点风电机组实际运行现场,能够更加准确的代表各机位点的实际风能资源水平与风电场及风电机组运行状况,使风电项目发电量评估结果更加精准与可靠。
附图说明
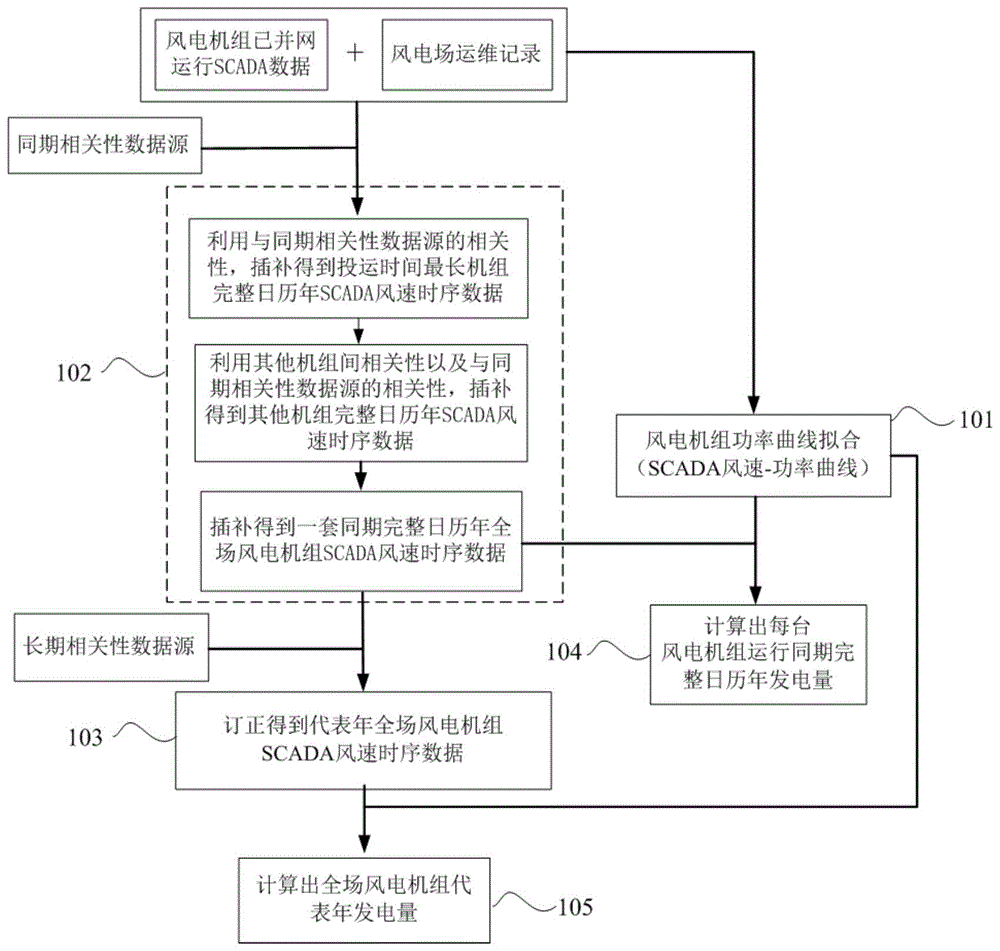
图1为根据本发明的实施例的基于风机运行数据的风电项目发电量评估方法流程图。
图2为根据本发明的实施例的风电机组功率曲线拟合流程图。
具体实施方式
下面结合附图和具体实施例对本发明作进一步说明。
如图1所示,本实施例所提供的一种基于风机运行数据的风电项目发电量评估方法,其具体实施过程如下:
步骤101,调取项目每台风电机组稳定并网运行以来的scada数据,数据包括10min平均风速、10min平均机舱位置与风向角偏差、10min平均有功功率、风电机组状态码时序、风电机组限电(功率)码与结冰状态码时序;收集风电场运行维护记录,包括风电机组故障记录与检修台账、电站工作票与操作票、电网调度记录、电网停电纪录;根据调取的scada数据和收集的运维记录,针对每台机组筛选出正常并网发电状态下的数据;基于筛选出的每台正常并网发电状态下的数据,拟合出每台风电机组功率曲线,即scada平均风速-有功功率曲线。
如图2所示,每台风电机组正常并网发电状态下的数据提取方法与步骤如下:
步骤201,首先根据风电机组状态码时序,筛选出代表风电机组处于并网状态的时间段序列t1,这里的并网状态包含了正常并网状态和非正常并网状态。scada系统通常采用不同数字表示风电机组的不同状态,例如“0”代表机组维护,“1”代表机组启动,“2”代表待机,“3”代表故障停机,“4代表正常停机”,“5”代表手动停机,“6”代表机组并网,“7”代表机组通讯中断。因此风电机组在运行过程中,其状态是根据实际情况实时变化的,对应其状态码也在随时间实时变动。根据以上举例的状态码指代的风电机组状态为例,此步工作相当于在风电机组运行的时间序列中,筛选出风电机组状态码保持为“6”的时间段序列t1。
步骤202,根据风电机组限电(功率)码时序,在a)筛选出的代表风电机组处于并网状态的时间段序列t1中,进一步筛选出代表风电机组未被限电(限功率)的时间段序列。例如“0”代表机组未被被限电(限功率)运行,“1”代表机组被限电(限功率)运行,相当于筛选出风电机组限电(功率)码保持为“0”的时间段序列t2。
步骤203,对存在明显冰冻环境的风电场项目,还应根据风电机组叶片结冰状态码时序,在a)和b)筛选出的时间段序列t2中,进一步筛选出代表风电机组叶片未结冰运行的时间段序列t3。例如“0”代表机组叶片未结冰,“1”代表机组叶片结冰,相当于筛选出风电机组叶片结冰状态码保持为“0”的时间段序列t3。
步骤204,利用风电场运行维护记录,包括风电机组故障记录与检修台账、电站工作票与操作票、电网调度记录、电网停电纪录,对a)或b)提取出来的时间段序列t2或t3再次进行筛选,剔除风电场运行维护记录的非正常并网运行状态时间段序列,得到经风电场运行维护记录核对后的风电机组正常并网运行的时间段序列t4。
步骤205,根据筛选出的时间段序列t4,调取与t4时间段序列对应的10min平均风速、10min平均有功功率数据,至此完成每台风电机组正常并网发电状态下的数据提取。
如图2所示,风电机组功率曲线,即scada平均风速-有功功率曲线,拟合方法如下:
步骤206,将0-25m/s风速划分成间隔为0.5m/s的区间,然后采用“区间法”,将经提取的风电机组正常并网发电状态下的每个10min平均风速、10min平均有功功率数据,划分至对应的风速区间组中;
步骤207,计算出每个风速区间组对应的风速平均值与功率平均功率,依据下式进行计算:
式中:
vi第i个区间平均风速;
vn,i,j第i个区间数组j的风速;
pi第i个区间平均输出功率;
pn,i,j第i个区间数组j输出功率;
ni第i个区间内10min数组的数目。
步骤208,经计算得出每台风电机组拟合功率曲线,即scada平均风速-有功功率曲线。
步骤102,利用同期相关性数据源以及邻近风电机组间同期scada风速相关性,将所有风电机组插补出一套同期完整日历年的scada平均风速时序数据。步骤包括:
a)对风电机组投运期间scada平均风速的缺失与异常数据进行剔除与插补。不同于风电机组功率曲线拟合时的数据提取方法,无论风电机组是处于维护、待机、启机、停机、并网中的哪种状态,只要风电机组测风仪能够正常准确测风并能将数据传输至scada系统进行记录,那么风速数据就可被认为是有效的。因此这里仅需剔除与插补风电机组因通讯中断、机组全系统断电、电网停电、风速仪故障或结冰等因素导致的风速仪数据记录缺失或异常的数据。
b)选择项目投运时间最长的风电机组,将该风电机组scada风速时序数据与同期相关性数据源的风速数据进行相关性分析,当相关性r大于0.6时,则判定相关性较好,进而利用同期相关性数据源对该风电机组不足完整年的时段风速数据进行插补,从而得到插补成完整日历年的scada平均风速时序数据。例如某风电项目,1#风电机组投运时间最长,投运时间为2020年1月至8月,投入运行不足完整年,缺失9月至12月共4个月的运行时间和数据,为此可选择同期相关性数据源,先利用同期相关性数据源中2020年1月至8月的数据与1#风电机组2020年1月至8月的scada风速时序数据进行相关性分析,如果2020年1月至8月同期相关性数据源与1#风电机组2020年1月至8月的scada风速时序数据的相关性r大于0.6时,则判定同期相关性数据源与1#风电机组2020年1月至8月的scada风速时序数据相关性较高;则利用该相关性关系,以同期相关性数据源中2019年9月至12月的数据对1#风电机组10月至12月的scada风速时序数据进行插补,从而就得到了1#风电机组2019年10月至2020年9月完整年的scada风速时序数据。
优选的,所述利用的同期相关性数据源可包括同期气象站数据源或同期中尺度数据源,具体采用哪种数据源可根据数据源的可获得性、数据源同风电机组scada平均风速的相关性程度r的大小进行决定。如果同期气象站数据源与同期中尺度数据源均可获取,则分别计算同期气象站数据源、同期中尺度数据源与风电机组scada平均风速的相关性程度r,选择相关性程度r最高的数据源作为同期相关性数据源。
c)对其他风电机组的数据插补,先以周边投运时间长的风电机组风速数据作为同期数据插补源,同运行时间短的临近风电机组风速数据开展相关性分析,当相关性r大于0.8时,则判定为临近风电机组间的数据相关性较好,进而将运行时间短的风电机组插补成同投运时间长的风电机组运行时段相同的长时间数据;然后对风电机组统一缺少的不足完整日历年时段,则采用同期相关性数据源与该风电机组已通过临近机组插补完后的数据进行相关性分析,当相关性r大于0.6时,则判定相关性较好,进而利用同期相关性数据源将其他风电机组插补成完整日历年的scada平均风速时序数据。
步骤103,利用长期相关性数据源,将以上步骤102中的每台机组完整日历年scada平均风速时序数据订正成代表年scada平均风速时序数据。步骤包括:
a)分析相关性数据源近30年或近20年的年际平均风速变化趋势,并同风电项目投运期对应的等效完整年份的年平均风速进行比较,分析出风电项目投运期对应的等效完整年在长周期中是处于平风年、小风年还是大风年。
b)如果风电项目投运期对应的等效完整年风速被判定为平风年,则不对插补出的风电机组等效完整年scada平均风速进行订正;如果风电项目投运期对应的等效完整年风速被判定为大风年,则应对插补出的风电机组等效完整年scada平均风速向下订正;如果风电项目投运期对应的等效完整年风速被判定为小风年,则需经过进一步谨慎论证和分析,判断是否需要对插补出的风电机组等效完整年scada平均风速向上订正。
优选的,所述利用长期相关性数据源也可包括长期气象站数据源或长期中尺度数据源。具体采用何种长期相关性数据源,根据步骤102中同期相关性数据源遴选中确定的相关性最高的那个数据源作为长期数据源。
步骤104,结合每台机组拟合的功率曲线与同期完整日历年scada平均风速时序数据,计算出每台风电机组运行同期完整日历年发电量。步骤包括:
a)同期完整日历年scada平均风速的风频分布统计
以0.5m/s为间隔,统计出项目所有风电机组运行同期完整日历年scada风速时序数据的风频分布,拟合求解出威布尔分布中的c和k参数。
其中威布尔分布的概率密度函数和累计概率分布函数分别见下式(3)和(4):
式中:c为威布尔分布的尺度参数;k为威布尔分布的形状参数。
b)同期完整日历年的风电机组发电量测算
基于运行同期完整日历年风频分布结果,采用以下方法分别计算出项目运行当年应发电量。
式中:
aep为年发电量
η为风电机组可利用率
n为区间个数
f(vi)为风速的威布尔累计概率分布函数。
vi第i个区间平均风速;
pi第i个区间平均输出功率。
步骤105,结合每台机组拟合的功率曲线与代表年scada平均风速时序数据,计算出每台风电机组代表年发电量。步骤包括:
a)代表年scada平均风速的风频分布统计
以0.5m/s为间隔,统计出项目所有风电机组运行同期完整日历年scada风速时序数据的风频分布,拟合求解出代表年的风速威布尔分布中的c和k参数。
b)代表年的风电机组发电量测算
基于代表年风频分布结果,采用公式(5)计算出所有风电机组代表年应发电量。
- 还没有人留言评论。精彩留言会获得点赞!