对象的识别方法、装置、存储介质和处理器与流程
1.本发明涉及数据处理领域,具体而言,涉及一种对象的识别方法、装置、存储介质和处理器。
背景技术:
2.目前,在对对象进行重识别时,可以将对象的图像直接分为固定的水平条纹,以通过水平条纹来获得更丰富的细粒度局部特征。但是,固定的水平条纹无法处理图像之间的严重错位,并且不能消除背景或遮挡的影响,从而存在对对象进行重识别的效率低的技术问题。
3.针对上述的对对象进行重识别的效率低的技术问题,目前尚未提出有效的解决方案。
技术实现要素:
4.本发明实施例提供了一种对象的识别方法、装置、存储介质和处理器,以至少解决对对象进行重识别的效率低的技术问题。
5.根据本发明实施例的一个方面,提供了一种对象的识别方法。该方法可以包括:获取包括待识别的对象的目标图像;通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息,其中,目标网络模型包括区域生成模型和区域感知模型,区域生成模型用于确定目标图像中多个子图像分别对应的子区域的位置信息,子图像包括对象的至少一个子对象,区域感知模型用于确定子区域的目标权重,目标权重用于表示子区域对目标区域的重要程度;基于目标位置信息对目标图像中的对象进行重识别,得到重识别结果。
6.根据本发明实施例的另一方面,还提供了另一种对象的识别方法。该方法可以包括:获取包括待识别的行人的目标图像;通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息,其中,目标网络模型包括区域生成模型和区域感知模型,区域生成模型用于确定目标图像中多个子图像分别对应的子区域的位置信息,子图像包括行人的至少一个子部位,区域感知模型用于确定子区域的目标权重,目标权重用于表示子区域对目标区域的重要程度;基于目标位置信息对目标图像中的行人进行重识别,得到重识别结果。
7.根据本发明实施例的另一方面,还提供了另一种对象的识别方法。该方法可以包括:在目标界面显示包括待识别的对象的目标图像;在目标界面显示重识别结果,其中,重识别结果为基于目标区域的目标位置信息对目标图像中的对象进行重识别得到,目标位置信息为通过目标网络模型对目标图像进行识别得到,目标网络模型包括区域生成模型和区域感知模型,区域生成模型用于确定目标图像中多个子图像分别对应的子区域的位置信息,子图像包括对象的至少一个子对象,区域感知模型用于确定子区域的目标权重,目标权重用于表示子区域对目标区域的重要程度。
8.根据本发明实施例的另一方面,还提供了另一种对象的识别方法。该方法可以包括:前端客户端向后台服务器上传包括待识别的对象的目标图像;前端客户端接收后台服务器返回的重识别结果,其中,重识别结果为后台服务器基于目标区域的目标位置信息对目标图像中的对象进行重识别得到,目标位置信息为通过目标网络模型对目标图像进行识别得到,目标网络模型包括区域生成模型和区域感知模型,区域生成模型用于确定目标图像中多个子图像分别对应的子区域的位置信息,子图像包括对象的至少一个子对象,区域感知模型用于确定子区域的目标权重,目标权重用于表示子区域对目标区域的重要程度。
9.根据本发明实施例的另一方面,还提供了另一种对象的识别方法。该方法可以包括:在目标界面的录入界面中录入包括待识别的对象的目标图像;在目标界面内感应到位置生成指令,显示目标图像对应的目标区域的目标位置信息,其中,目标位置信息为通过目标图像中多个子图像分别对应的子区域的位置信息和子区域的目标权重得到,子图像包括对象的至少一个子对象,目标权重用于表示子区域对目标区域的重要程度;在目标界面内感应到识别指令,显示重识别结果,其中,重识别结果通过基于目标位置信息对目标图像中的对象进行重识别得到。
10.根据本发明实施例的另一方面,还提供了另一种对象的识别装置。该装置可以包括:第一获取单元,用于获取包括待识别的对象的目标图像;第一识别单元,用于通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息,其中,目标网络模型包括区域生成模型和区域感知模型,区域生成模型用于确定目标图像中多个子图像分别对应的子区域的位置信息,子图像包括对象的至少一个子对象,区域感知模型用于确定子区域的目标权重,目标权重用于表示子区域对目标区域的重要程度;第二识别单元,用于基于目标位置信息对目标图像中的对象进行重识别,得到重识别结果。
11.根据本发明实施例的另一方面,还提供了另一种对象的识别装置。该装置可以包括:第二获取单元,用于获取包括待识别的行人的目标图像;第三识别单元,用于通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息,其中,目标网络模型包括区域生成模型和区域感知模型,区域生成模型用于确定目标图像中多个子图像分别对应的子区域的位置信息,子图像包括行人的至少一个子部位,区域感知模型用于确定子区域的目标权重,目标权重用于表示子区域对目标区域的重要程度;第四识别单元,用于基于目标位置信息对目标图像中的行人进行重识别,得到重识别结果。
12.根据本发明实施例的另一方面,还提供了另一种对象的识别装置。该装置可以包括:第一显示单元,用于在目标界面显示包括待识别的对象的目标图像;第二显示单元,用于在目标界面显示重识别结果,其中,重识别结果为基于目标区域的目标位置信息对目标图像中的对象进行重识别得到,目标位置信息为通过目标网络模型对目标图像进行识别得到,目标网络模型包括区域生成模型和区域感知模型,区域生成模型用于确定目标图像中多个子图像分别对应的子区域的位置信息,子图像包括对象的至少一个子对象,区域感知模型用于确定子区域的目标权重,目标权重用于表示子区域对目标区域的重要程度。
13.根据本发明实施例的另一方面,还提供了另一种对象的识别装置。该装置可以包括:上传单元,用于使前端客户端向后台服务器上传包括待识别的对象的目标图像;接收单元,用于使前端客户端接收后台服务器返回的重识别结果,其中,重识别结果为后台服务器基于目标区域的目标位置信息对目标图像中的对象进行重识别得到,目标位置信息为通过
目标网络模型对目标图像进行识别得到,目标网络模型包括区域生成模型和区域感知模型,区域生成模型用于确定目标图像中多个子图像分别对应的子区域的位置信息,子图像包括对象的至少一个子对象,区域感知模型用于确定子区域的目标权重,目标权重用于表示子区域对目标区域的重要程度。
14.根据本发明实施例的另一方面,还提供了一种计算机可读存储介质。计算机可读存储介质包括存储的程序,其中,在程序被处理器运行时控制计算机可读存储介质所在设备执行本发明实施例的对象的识别方法。
15.根据本发明实施例的另一方面,还提供了一种处理器。该处理器用于运行程序,其中,程序运行时执行本发明实施例的对象的识别方法。
16.根据本发明实施例的另一方面,还提供了一种对象的识别系统。该系统可以包括:处理器;存储器,与处理器相连接,用于为处理器提供处理以下处理步骤的指令:获取包括待识别的对象的目标图像;通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息,其中,目标网络模型包括区域生成模型和区域感知模型,区域生成模型用于确定目标图像中多个子图像分别对应的子区域的位置信息,子图像包括对象的至少一个子对象,区域感知模型用于确定子区域的目标权重,目标权重用于表示子区域对目标区域的重要程度;基于目标位置信息对目标图像中的对象进行重识别,得到重识别结果。
17.在本发明实施例中,提供了一种目标网络模型,其包括区域生成模型和区域感知模型,通过其对目标图像进行识别,得到目标区域的位置信息,进而通过位置信息对目标图像中的对象进行重识别,从而该实施例无需额外使用其它语义信息,因此计算量较小,检索效率较高,通过区域生成模型可以自动计算出具有鉴别力并且对齐的区域的坐标,可以避免遮挡区域的产生,对于每个生成区域,生成式区域感知网络给每个子区域赋予不同的权重,避免了无意义的子区域对网络造成的影响,解决了对对象进行重识别的效率低的技术问题,从而提高了对对象进行重识别的效率的技术效果。
附图说明
18.此处所说明的附图用来提供对本发明的进一步理解,构成本技术的一部分,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
19.图1是根据本发明实施例的一种用于实现对象的识别方法的计算机终端(或移动设备)的硬件结构框图;
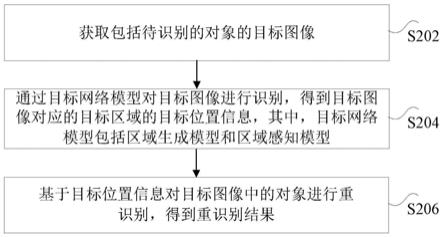
20.图2是根据本发明实施例的一种对象的识别方法的流程图;
21.图3是根据本发明实施例的另一种对象的识别方法的流程图;
22.图4是根据本发明实施例的另一种对象的识别方法的流程图;
23.图5是根据本发明实施例的另一种对象的识别方法的流程图;
24.图6(a)是根据相关技术中的一种基于区域的方法实现行人重识别的示意图;
25.图6(b)是根据相关技术中的另一种基于区域的方法实现行人重识别的示意图;
26.图7是根据本发明实施例的一种用于实现行人重识别的生成式区域感知网络的示意图;
27.图8(a)是根据本发明实施例的一种子区域的数量与行人重识别、区域等级的平均
精度的关系的示意图;
28.图8(b)是根据本发明实施例的一种区域比率与行人重识别的平均精度、区域等级的关系的示意图;
29.图9(a)是根据本发明实施例的一种存储库的长度与行人重识别的平均精度、区域等级的关系的示意图;
30.图9(b)是根据本发明实施例的一种不变性感知指示器的总损失与行人重识别的平均精度、区域等级的关系的示意图;
31.图10(a)是根据本发明实施例的一种通过生成式区域感知网络对行人进行重识别的结果的示意图;
32.图10(b)是根据本发明实施例的另一种通过生成式区域感知网络对行人进行重识别的结果的示意图;
33.图11是根据本发明实施例的一种对象的识别装置的示意图;
34.图12是根据本发明实施例的另一种对象的识别装置的示意图;
35.图13是根据本发明实施例的另一种对象的识别装置的示意图;
36.图14是根据本发明实施例的另一种对象的识别装置的示意图;以及
37.图15是根据本发明实施例的一种计算机终端的结构框图。
具体实施方式
38.为了使本技术领域的人员更好地理解本发明方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分的实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明保护的范围。
39.需要说明的是,本发明的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本发明的实施例能够以除了在这里图示或描述的那些以外的顺序实施。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
40.首先,在对本技术实施例进行描述的过程中出现的部分名词或术语适用于如下解释:
41.生成式区域感知网络(generative region-aware network,简称为g-ran),可以利用图像之间的固有关系生成自适应区域;
42.区域生成模型(region generation module,简称为rgm),用于通过两个级联的全连接层自适应地预测区域的坐标;
43.区域感知模块(region aware module,简称为ram),为了进一步分析通过rgm生成的区域,提出了ram,其通过鉴别力感知指示器和不变性感知指示器为每个区域分配权重;
44.卷积神经网络(convolutional neural network,简称为cnn),是一种前馈神经网
络,人工神经元可以响应周围单元,进行大型图像的处理,其包括卷积层和池化层。
45.实施例1
46.根据本发明实施例,还提供了一种对象的识别方法的实施例,需要说明的是,在附图的流程图示出的步骤可以在诸如一组计算机可执行指令的计算机系统中执行,并且,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
47.本技术实施例一所提供的方法实施例可以在移动终端、计算机终端或者类似的运算装置中执行。图1是根据本发明实施例的一种用于实现对象的识别方法的计算机终端(或移动设备)的硬件结构框图。如图1所示,计算机终端10(或移动设备10)可以包括一个或多个(图中采用102a、102b,
……
,102n来示出)处理器102(处理器102可以包括但不限于微处理器mcu或可编程逻辑器件fpga等的处理装置)、用于存储数据的存储器104、以及用于通信功能的传输装置106。除此以外,还可以包括:显示器、输入/输出接口(i/o接口)、通用串行总线(usb)端口(可以作为i/o接口的端口中的一个端口被包括)、网络接口、电源和/或相机。本领域普通技术人员可以理解,图1所示的结构仅为示意,其并不对上述电子装置的结构造成限定。例如,计算机终端10还可包括比图1中所示更多或者更少的组件,或者具有与图1所示不同的配置。
48.应当注意到的是上述一个或多个处理器102和/或其他数据处理电路在本文中通常可以被称为“数据处理电路”。该数据处理电路可以全部或部分的体现为软件、硬件、固件或其他任意组合。此外,数据处理电路可为单个独立的处理模块,或全部或部分的结合到计算机终端10(或移动设备)中的其他元件中的任意一个内。如本技术实施例中所涉及到的,该数据处理电路作为一种处理器控制(例如与接口连接的可变电阻终端路径的选择)。
49.存储器104可用于存储应用软件的软件程序以及模块,如本发明实施例中的对象的识别方法对应的程序指令/数据存储装置,处理器102通过运行存储在存储器104内的软件程序以及模块,从而执行各种功能应用以及数据处理,即实现上述的对象的识别方法。存储器104可包括高速随机存储器,还可包括非易失性存储器,如一个或者多个磁性存储装置、闪存、或者其他非易失性固态存储器。在一些实例中,存储器104可进一步包括相对于处理器102远程设置的存储器,这些远程存储器可以通过网络连接至计算机终端10。上述网络的实例包括但不限于互联网、企业内部网、局域网、移动通信网及其组合。
50.传输装置106用于经由一个网络接收或者发送数据。上述的网络具体实例可包括计算机终端10的通信供应商提供的无线网络。在一个实例中,传输装置106包括一个网络适配器(network interface controller,nic),其可通过基站与其他网络设备相连从而可与互联网进行通讯。在一个实例中,传输装置106可以为射频(radio frequency,rf)模块,其用于通过无线方式与互联网进行通讯。
51.显示器可以例如触摸屏式的液晶显示器(lcd),该液晶显示器可使得用户能够与计算机终端10(或移动设备)的用户界面进行交互。
52.此处需要说明的是,在一些可选实施例中,上述图1所示的计算机设备(或移动设备)可以包括硬件元件(包括电路)、软件元件(包括存储在计算机可读介质上的计算机代码)、或硬件元件和软件元件两者的结合。应当指出的是,图1仅为特定具体实例的一个实例,并且旨在示出可存在于上述计算机设备(或移动设备)中的部件的类型。
53.在图1所示的运行环境下,本技术提供了如图2所示的对象的识别方法。需要说明的是,该实施例的对象的识别方法以由图1所示实施例的移动终端执行。
54.图2是根据本发明实施例的一种对象的识别方法的流程图。如图2所示,该方法可以包括以下步骤:
55.步骤s202,获取包括待识别的对象的目标图像。
56.在本发明上述步骤s202提供的技术方案中,对象为需要进行识别的特定对象(感兴趣对象),获取该对象的目标图像,可以是通过图像采集设备获取目标图像,比如,通过摄像头获取目标图像,该目标图像可以为图片,也可以为视频序列,此处不做具体限制。
57.步骤s204,通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息,其中,目标网络模型包括区域生成模型和区域感知模型。
58.在本发明上述步骤s204提供的技术方案中,在获取包括待识别的对象的目标图像之后,可以通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息,其中,目标网络模型中的区域生成模型用于确定目标图像中多个子图像分别对应的子区域的位置信息,子图像包括对象的至少一个子对象,目标网络模型中的区域感知模型用于确定子区域的目标权重,目标权重用于表示子区域对目标区域的重要程度。
59.在该实施例中,目标网络模型为预先训练好的用于对输入的图像对应的区域进行识别,得到该区别的位置信息,可以为生成式区域感知网络。该实施例的目标网络模型可以进一步包括区域生成模型(rgm)和区域感知模型(ram)。
60.可选地,该实施例的目标图像包括多个子图像,该多个子图像组成目标图像,每个子图像可以包括待识别的对象的至少一个子对象。该实施例的区域生成模型可以用于自适应地预测目标图像中的多个子图像分别对应的子区域的位置信息,其中,子区域也可以称为生成区域,位置信息可以为具有鉴别力且对齐的子区域的坐标。可选地,该实施例的区域生成模型可以通过有效的弱监督预测目标图像中的多个子图像分别对应的子区域的位置信息,对应的区域分类损失可以用于很好地对齐区域。为了进一步对子区域的位置信息进行分析,该实施例的目标网络模型还可以包括区域感知模型,该区域感知模型可以用于确定每个子区域的目标权重,该目标权重可以用于表示子区域对目标区域的重要程度,也即,对于每个子区域,区域感知模型可以给每个子区域赋予不同的目标权重,以确定子区域向目标区域的合理贡献,进而避免无意义的子区域对目标网络模型造成影响。
61.该实施例将获取到的目标图像输入至目标网络模型中进行识别,从而得到目标图像对应的目标区域的目标位置信息,该目标位置信息可以为目标区域的坐标。
62.步骤s206,基于目标位置信息对目标图像中的对象进行重识别,得到重识别结果。
63.在本发明上述步骤s206提供的技术方案中,在通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息之后,可以基于目标位置信息对目标图像中的对象进行重识别,得到重识别结果。
64.在该实施例中,在对目标图像中的对象进行重识别时,可以是基于目标区域的目标位置信息来对目标图像中的对象进行重识别,从而确定目标图像中是否存在特定的对象。
65.通过本技术上述步骤s202至步骤s206,本技术提供了一种目标网络模型,其包括区域生成模型和区域感知模型,通过其对目标图像进行识别,得到目标区域的位置信息,进
而通过位置信息对目标图像中的对象进行重识别,从而该实施例无需额外使用其它语义信息,因此计算量较小,检索效率较高,通过区域生成模型可以自动计算出具有鉴别力并且对齐的区域的坐标,可以避免遮挡区域的产生,对于每个生成区域,生成式区域感知网络给每个子区域赋予不同的权重,避免了无意义的子区域对网络造成的影响,解决了对对象进行重识别的效率低的技术问题,从而提高了对对象进行重识别的效率的技术效果。
66.下面对该实施例的上述方法进行进一步介绍。
67.作为一种可选的实施方式,目标区域为未遮挡的区域。
68.在该实施例中,通过目标网络模型可以自动计算出具有鉴别力并且对齐的目标区域的坐标,该目标区域为未遮挡的区域,从而有效避免了遮挡区域的产生。
69.作为一种可选的实施方式,在步骤s204,通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息之前,该方法还包括:提取目标图像的特征图;通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息,包括:通过目标网络模型对特征图对应的目标区域进行识别,得到目标位置信息。
70.在该实施例中,在通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息之前,可以先提取目标图像的特征图,可选地,该实施例可以通过卷积神经网络模型从目标图像中提取出特征图其中,c可以用于表示特征图的通道数值,h可以用于表示特征图的高度,w可以用于表示特征图的宽度。在提取出目标图像的特征图之后,该实施例可以通过目标网络模型对特征图对应的目标区域进行识别,从而得到目标区域的目标位置信息。
71.作为一种可选的实施方式,步骤s204,通过目标网络模型对特征图对应的目标区域进行识别,得到目标位置信息,包括:基于区域生成模型中的全连接层对特征图进行预测,得到多个子图像分别对应的子区域的位置信息;基于区域感知模型中的子感知模型确定目标权重;基于子区域的位置信息和目标权重确定目标位置信息。
72.在该实施例中,区域生成模型可以包括两个全连接层(fully-connected,简称为fc),该区域生成模型可以通过全连接层来自适应预测子区域的位置信息,比如,通过全连接层自适应地预测子区域的坐标。可选地,该实施例的区域感知模型可以进一步包括子感知模型,该子感知模型可以是鉴别力感知指示器(discrimination-aware indicator)和不变性感知指示器(invariance-aware indicator),该实施例可以基于子感知模型确定各个子区域的目标权重,进而基于各个子区域的位置信息和对应的目标权重共同来确定最终的目标区域的目标位置信息。
73.作为一种可选的实施方式,基于区域生成模型中的全连接层对特征图进行预测,得到多个子图像分别对应的子区域的位置信息,包括:对特征图进行最大池化操作,得到池化结果;基于第一全连接层和第二全连接层对池化结果进行分类,得到子区域的位置信息,其中,第一全连接层和第二全连接层级联。
74.在该实施例中,在实现基于区域生成模型中的全连接层对特征图进行预测,得到多个子图像分别对应的子区域的位置信息时,可以是先将特征图输入至卷积层,以降低特征图的通道的宽度,然后对卷积层的输出结果进行最大池化操作(max-pooling operation),得到池化结果,进而将池化结果输入至第一全连接层和第二全连接层进行分类,来预测出子区域的位置信息。可选地,该实施例的子区域的位置信息可以通过以下公式
来表示:
75.θ=θj(j=1,
…
,p)=φ(f,δ,α)
[0076][0077]
其中,θ可以用于表示子区域的坐标,φ可以用于表示区域生成模型,δ,α可以分别用于表示卷积层和全连接层的参数,θj可以用于表示子区域的坐标,并且包括四个坐标参数其分别用于表示顶部、左、底部、右侧的坐标。
[0078]
作为一种可选的实施方式,基于区域感知模型中的子感知模型确定目标权重,包括:通过第一子感知模型通过自注意力机制对子区域的特征进行分析,得到子区域的第一权重,其中,第一子感知模型包括第三全连接层和激活函数;通过第二子感知模型将子区域和与目标图像具有同一标识的其它图像对应的区域进行比较,得到比较结果,并基于比较结果确定子区域的第二权重;将第一权重和第二权重之和,确定为目标权重。
[0079]
在该实施例中,第一子感知模型可以为鉴别力感知指示器,第二子模型可以为不变性感知指示器。该实施例通过第一子感知模型通过自注意力机制(f)来对子区域的特征进行分析,得到子区域的第一权重(鉴别力权重,discriminative weight),其中,子区域的特征可以通过以下公式进行表示:
[0080][0081]
其中,fr可以用于表示子区域的特征,c1可以用于表示特征图在通过卷积层处理后的通道数,p可以用于表示子区域的数量,fj可以用于表示第j个特征图。该实施例将子区域的特征作为第一子感知模型的输入,将每个子区域的目标权重作为第一子感知模型的输出。可选地,该实施例的第一子感知模型包括一个第三全连接层和一个激活函数,其中,第三全连接层可以为线性全连接层,激活函数可以为sigmoid激活函数。
[0082]
可选地,该实施例的第j个子区域的鉴别力权重可以通过以下公式进行表示:
[0083][0084]
其中,αj可以用于表示第j个子区域的鉴别力权重,wa可以用于表示第一全连接层和第二全连接层的参数,σ可以用于表示激活函数。
[0085]
该实施例的上述第一子感知模型可以增强用于学习目标图像的多个子图像之间的固有关系的特征,并且用于衡量每个子区域的特征。
[0086]
为了学习每个子区域对应的目标权重,该实施例可以通过第二子感知模型将子区域和与目标图像具有同一标识的其它图像对应的区域进行比较,得到比较结果,其中,标识可以为身份表示(identification,简称为id),进而基于比较结果确定子区域的第二权重(不变性权重,invariance weight)。该实施例的第二子感知模型为对第一子感知模型的进一步补充,用于学习子多个子区域和对齐区域之间的关系,其中,多个子区域和对齐区域对应相同的标识。
[0087]
可选地,该实施例创建一个目标存储库,子区域的特征存储在目标存储库中,该目标存储库包括用于训练第二子感知模型的图像的区域特征,可以使用第二子感知模型对具有相同标识的对齐区域进行比较。
[0088]
可选地,该实施例通过以下公式来表示目标存储库:
[0089][0090]
其中,t可以用于表示训练代数,m可以用于表示更新率,可以设为0.7,可以为通过的正则化所表示的结果。
[0091]
可选地,在该实施例中,可以计算fj和gj之间的相似度sj:
[0092][0093]
其中,rj用于表示第j个子区域。
[0094]
第j个子区域的不变性权重(invariance weight)可以通过下述公式进行表示:
[0095][0096]
其中,为包括l的相似度分数的矩阵,l为目标存储库的其中一个尺寸。
[0097]
可选地,该实施例可以使用全连接层对进行调整,可以通过如下公式进行实现:
[0098][0099]
其中,并且为全连接层的参数,r为衰减率,可以为2。
[0100]
在该实施例中,可以使用softmax函数对进行正则化处理,以获取对应的子区域的第二权重,进而将第一权重和第二权重之间的和,确定为目标区域的目标权重。
[0101]
作为一种可选的实施方式,在步骤s204,通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息之后,该方法还包括:在子区域的尺寸未处于目标尺寸范围的情况下,基于子区域的面积和目标图像的特征图的尺寸将子区域的尺寸调整至目标尺寸范围内。
[0102]
在通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息之后,可以判断子区域的尺寸是否处于目标尺寸范围内,该目标尺寸范围为用于对子区域的尺寸进行限定的合适范围,太大或太小的子区域的尺寸都需要进行进一步调整。如果子区域的尺寸未处于目标尺寸范围,则可以基于子区域的面积和目标图像的特征图的尺寸将子区域的尺寸调整至目标尺寸范围内。可选地,该实施例可以通过以下公式来实现目标尺寸范围的调整,得到调整后的子区域的尺寸
[0103][0104]
其中,ξ用于表示子区域的尺寸占全部图的尺寸的比率(区域比率,area ratio),s用于表示全部特征图的尺寸,且s=w
×
h。
[0105]
作为一种可选的实施方式,在步骤s204,通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息之后,该方法还包括:在子区域的高宽比未处于目标高宽比范围的情况下,基于子区域的高宽比的临界值将子区域的高宽比调整至目标高宽比范围内。
[0106]
在该实施例中,在通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息之后,还可以对子区域的高宽比进行进一步调整。在该实施例中,可以判断子区域的高宽比是否处于目标高宽比范围,如果判断出子区域的高宽比未处于目标高宽比范围,则可以基于子区域的高宽比的临界值将子区域的高宽比调整至目标高宽比范围内,可以通过以下公式来实现,得到调整后的子区域的宽高比
[0107][0108]
其中,可以用于表示宽高比,α1,α2可以用于表示宽高比的比值,可以分别为0.5和2。
[0109]
作为一种可选的实施方式,在通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息之后,该方法还包括:在子区域与其它子区域重叠的情况下,基于子区域与其它子区域之间的重叠度调整子区域,以使调整后的子区域与其它子区域之间的重叠度低于调整前的子区域与其它子区域之间的重叠度。
[0110]
在该实施例中,为了使得子区域包括不同的特征,在通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息之后,还可以对子区域与其它子区域之间的重叠度进行调整,可以是基于子区域与其它子区域之间的重叠度来调整子区域,可以通过以下公式进行实现,得到调整后的重叠度
[0111][0112]
其中,可以用于计算θj与θk之间的重叠度,j≠k,可以用于分别表示上述子区域和其它子区域。
[0113]
作为一种可选的实施方式,在步骤s204,通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息之后,该方法还包括:基于子区域的区域分类损失,将子区域的特征与其它子区域的特征进行对齐。
[0114]
在该实施例中,在通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息之后,为了进一步对子区域进行限制,以及更好地对齐子区域的特征,该实施例可以获取子区域的区域分类损失,该区域分类损失可以很好地将子区域的特征与其它子区域的特征进行对齐。
[0115]
可选地,该实施例可以使用参数共用分类器(parameters-shared classifier)来确保每个子区域与其伪标签(pseudo label)对齐,可以通过区域分类损失对参数共用分类
器进行优化,其中,区域分类损失也可以称为分类交叉熵损失,可以通过进行表示。可选地,该实施例的第二子感知模型的总损失可以通过以下公式得到:
[0116][0117]
其中,λa,λo,λ
align
可以用于表示比率,λa可以默认为0.1,λo可以默认为0.1,λ
align
可以默认为0.5。
[0118]
作为一种可选的实施方式,在步骤s204,通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息之前,该方法还包括:基于训练样本的全局特征的损失、区域特征的损失和区域生成模型对应的损失训练目标网络模型。
[0119]
在该实施例中,在通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息之前,需要训练出目标网络模型。在训练阶段,可以使用训练样本的全局特征的损失、区域特征的损失和区域生成模型对应的损失训练目标网络模型,其中,全局特征的损失可以通过进行表示,区域特征的损失可以通过进行表示,区域生成模型对应的损失可以上述第二子感知模型的总损失
[0120]
可选地,该实施例在得到上述目标网络模型之后,可以对目标网络模型进行进一步测试。在测试阶段通过子区域的目标权重来表示子区域的重要程度。
[0121]
下面对本发明实施例的对象的识别方法的行人识别场景进行进一步介绍。
[0122]
图3是根据本发明实施例的另一种对象的识别方法的流程图。如图3所示,该方法可以包括以下步骤:
[0123]
步骤s302,获取包括待识别的行人的目标图像。
[0124]
在本发明上述步骤s302提供的技术方案中,行人为需要进行识别的特定行人(感兴趣行人,获取该行人的目标图像,可以是通过图像采集设备获取该行人的目标图像,该目标图像可以为图片,也可以为视频序列,此处不做具体限制。
[0125]
步骤s304,通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息,其中,目标网络模型包括区域生成模型和区域感知模型。
[0126]
在本发明上述步骤s304提供的技术方案中,在获取包括待识别的行人的目标图像之后,通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息,其中,目标网络模型中的区域生成模型可以用于确定目标图像中多个子图像分别对应的子区域的位置信息,子图像可以包括行人的至少一个子部位,目标网络模型中的区域感知模型用于确定子区域的目标权重,目标权重用于表示子区域对目标区域的重要程度。
[0127]
在该实施例中,目标图像包括多个子图像,每个子图像可以包括待识别的行人的至少一个子对象。该实施例的区域生成模型可以用于自适应地预测目标图像中的多个子图像分别对应的子区域的位置信息,该位置信息可以为具有鉴别力且对齐的子区域的坐标。可选地,该实施例的区域生成模型可以通过有效的弱监督预测目标图像中的多个子图像分别对应的子区域的位置信息,对应的区域分类损失可以用于很好地对齐区域。为了进一步对子区域的位置信息进行分析,该实施例的目标网络模型还可以包括区域感知模型,该区域感知模型可以用于确定每个子区域的目标权重,以确定子区域向目标区域的合理贡献,进而避免无意义的子区域对目标网络模型造成影响。
[0128]
该实施例将获取到的目标图像输入至目标网络模型中进行识别,从而得到目标图
像对应的目标区域的目标位置信息,该目标位置信息可以为目标区域的坐标。其中,该目标区域为未遮挡的区域。
[0129]
步骤s306,基于目标位置信息对目标图像中的行人进行重识别,得到重识别结果。
[0130]
在本发明上述步骤s306提供的技术方案中,在通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息之后,可以基于目标位置信息对目标图像中的行人进行重识别,得到重识别结果。
[0131]
在该实施例中,在对目标图像中的行人进行重识别时,可以是基于目标区域的目标位置信息来对目标图像中的行人进行重识别,得到重识别结果,从而确定目标图像中是否存在特定的行人。其中,行人重识别也称为行人再识别,是利用计算机视觉技术判断图像或者视频序列中是否存在特定行人的方法。
[0132]
作为一种可选的实施方式,在通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息之前,该方法还包括:提取目标图像的特征图;通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息,包括:通过目标网络模型对特征图对应的目标区域进行识别,得到目标位置信息。
[0133]
在该实施例中,在通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息之前,可以先提取目标图像的特征图,可选地,该实施例可以通过卷积神经网络模型从目标图像中提取出特征图在提取出目标图像的特征图之后,该实施例可以通过目标网络模型对特征图对应的目标区域进行识别,从而得到目标区域的目标位置信息。
[0134]
下面从人机交互角度对本发明实施例的对象的识别方法进行介绍。
[0135]
图4是根据本发明实施例的另一种对象的识别方法的流程图。如图4所示,该方法可以包括以下步骤:
[0136]
步骤s402,在目标界面显示包括待识别的对象的目标图像。
[0137]
在本发明上述步骤s402提供的技术方案中,获取对象的目标图像,可以是通过图像采集设备获取目标图像,进而将该目标图像显示在目标界面上,该目标图像可以为图片,也可以为视频序列,此处不做具体限制。
[0138]
步骤s404,在目标界面显示重识别结果,其中,重识别结果为基于目标区域的目标位置信息对目标图像中的对象进行重识别得到,目标位置信息为通过目标网络模型对目标图像进行识别得到,目标网络模型包括区域生成模型和区域感知模型。
[0139]
在本发明上述步骤s402提供的技术方案中,区域生成模型用于确定目标图像中多个子图像分别对应的子区域的位置信息,子图像包括对象的至少一个子对象,区域感知模型用于确定子区域的目标权重,目标权重用于表示子区域对目标区域的重要程度。
[0140]
在该实施例中,在目标界面显示包括待识别的对象的目标图像之后,可以在目标界面上显示重识别结果。可选地,该实施例的目标图像包括多个子图像,每个子图像可以包括待识别的对象的至少一个子对象。该实施例的区域生成模型可以用于自适应地预测目标图像中的多个子图像分别对应的子区域的位置信息,其中,位置信息可以为具有鉴别力且对齐的子区域的坐标。可选地,该实施例的区域生成模型可以通过有效的弱监督预测目标图像中的多个子图像分别对应的子区域的位置信息,对应的区域分类损失可以用于很好地对齐区域。为了进一步对子区域的位置信息进行分析,该实施例的目标网络模型还可以包
括区域感知模型,该区域感知模型可以用于确定每个子区域的目标权重,该目标权重可以用于表示子区域对目标区域的重要程度,也即,对于每个子区域,区域感知模型可以给每个子区域赋予不同的目标权重,以确定子区域向目标区域的合理贡献,进而避免无意义的子区域对目标网络模型造成影响。
[0141]
该实施例将获取到的目标图像输入至目标网络模型中进行识别,从而得到目标图像对应的目标区域的目标位置信息,该目标位置信息可以为目标区域的坐标,进而基于目标区域的坐标来对目标图像中的对象进行重识别,得到重识别结果,进而在目标界面上显示该重识别结果,以确定目标图像中是否存在特定的对象。
[0142]
下面从前端客户端一侧对本发明实施例的对象的识别方法进行进一步介绍。
[0143]
图5是根据本发明实施例的另一种对象的识别方法的流程图。如图5所示,该方法可以包括以下步骤:
[0144]
步骤s502,前端客户端向后台服务器上传包括待识别的对象的目标图像。
[0145]
在本发明上述步骤s502提供的技术方案中,前端客户端可以先获取对象的目标图像,然后将该目标图像上传至后台服务器中,其中,目标图像可以为图片,也可以为视频序列,此处不做具体限制。
[0146]
步骤s504,前端客户端接收后台服务器返回的重识别结果,其中,重识别结果为后台服务器基于目标区域的目标位置信息对目标图像中的对象进行重识别得到,目标位置信息为通过目标网络模型对目标图像进行识别得到,目标网络模型包括区域生成模型和区域感知模型。
[0147]
在本发明上述步骤s504提供的技术方案中,区域生成模型用于确定目标图像中多个子图像分别对应的子区域的位置信息,子图像包括对象的至少一个子对象,区域感知模型用于确定子区域的目标权重,目标权重用于表示子区域对目标区域的重要程度。
[0148]
在该实施例中,在前端客户端向后台服务器上传包括待识别的对象的目标图像之后,后台服务器可以基于目标区域的目标位置信息对目标图像中的对象进行重识别,得到重识别结果,进而将重识别结果发送至前端客户端,使得前端客户端接收该重识别结果,进而可以在前端客户端的显示界面上显示该重识别结果。
[0149]
可选地,该实施例的目标图像包括多个子图像,每个子图像可以包括待识别的对象的至少一个子对象。该实施例的上述区域生成模型可以用于自适应地预测目标图像中的多个子图像分别对应的子区域的位置信息,其中,位置信息可以为具有鉴别力且对齐的子区域的坐标。可选地,该实施例的区域生成模型可以通过有效的弱监督预测目标图像中的多个子图像分别对应的子区域的位置信息,对应的区域分类损失可以用于很好地对齐区域。为了进一步对子区域的位置信息进行分析,该实施例的目标网络模型还可以包括区域感知模型,该区域感知模型可以用于确定每个子区域的目标权重,该目标权重可以用于表示子区域对目标区域的重要程度,也即,对于每个子区域,区域感知模型可以给每个子区域赋予不同的目标权重,以确定子区域向目标区域的合理贡献,进而避免无意义的子区域对目标网络模型造成影响。
[0150]
该实施例的后台服务器可以将接收到的目标图像输入至目标网络模型中进行识别,从而得到目标图像对应的目标区域的目标位置信息,该目标位置信息可以为目标区域的坐标,进而基于目标区域的坐标来对目标图像中的对象进行重识别,得到重识别结果,将
该重识别结果发送至前端客户端,进而在前端客户端的目标界面上显示该重识别结果,以确定目标图像中是否存在特定的对象。
[0151]
下面从人机交互角度对本发明实施例的另一种对象的识别方法进行介绍。
[0152]
作为一种可选的示例,该实施例的对象的识别方法可以包括:在目标界面的录入界面中录入包括待识别的对象的目标图像;在目标界面内感应到位置生成指令,显示目标图像对应的目标区域的目标位置信息,其中,目标位置信息为通过目标图像中多个子图像分别对应的子区域的位置信息和子区域的目标权重得到,子图像包括对象的至少一个子对象,目标权重用于表示子区域对目标区域的重要程度;在目标界面内感应到识别指令,显示重识别结果,其中,重识别结果通过基于目标位置信息对目标图像中的对象进行重识别得到。
[0153]
在该实施例中,目标界面中包括录入界面,该实施例可以在该录入界面中录入包括待识别的对象的目标图像,该对象为需要进行识别的特定对象,可以是在录入界面中录入通过图像采集设备获取目标图像,比如,录入通过摄像头获取到的目标图像,该目标图像可以为图片,也可以为视频序列,此处不做具体限制。需要说明的是,该实施例的录入界面可以位于目标界面的任意位置,此处不做具体限制。
[0154]
可选地,该实施例在目标界面内感应到用户触发的位置生成指令,该位置生成指令用于指示显示目标位置信息,进而响应该位置生成指令,在目标界面中显示目标图像对应的目标区域的目标位置信息。可选地,该实施例的目标图像包括多个子图像,该多个子图像组成目标图像,每个子图像可以包括待识别的对象的至少一个子对象。该实施例自适应地预测目标图像中的多个子图像分别对应的子区域的位置信息,其中,子区域也可以称为生成区域,位置信息可以为具有鉴别力且对齐的子区域的坐标。可选地,该实施例可以通过有效的弱监督预测目标图像中的多个子图像分别对应的子区域的位置信息,对应的区域分类损失可以用于很好地对齐区域。为了进一步对子区域的位置信息进行分析,该实施例还可以确定每个子区域的目标权重,该目标权重可以用于表示子区域对目标区域的重要程度。
[0155]
在获取到目标图像中多个子图像分别对应的子区域的位置信息以及子区域的目标权重之后,该实施例可以利用多个子图像分别对应的子区域的位置信息以及子区域的目标权重综合确定上述目标位置信息,可以是基于多个子图像分别对应的子区域的位置信息以及子区域的目标权重之间的积来确定上述目标位置信息。
[0156]
在利用多个子图像分别对应的子区域的位置信息以及子区域的目标权重确定上述目标位置信息之后,该实施例的目标界面可以接收用户触发的识别指令,该识别指令用于指示对目标图像中的对象进行重识别,进而响应该识别指令,基于已经确定的目标位置信息对目标图像中的对象进行重识别,得到重识别结果,进而在目标界面上显示该重识别结果。
[0157]
在该实施例中,在对目标图像中的对象进行重识别时,可以是基于目标区域的目标位置信息来对目标图像中的对象进行重识别,从而确定目标图像中是否存在特定的对象,进而达到确定目标图像中是否存在特定的对象的目的。
[0158]
在相关技术中,对象的识别可以为基于区域的方法,可以将对象的图像直接分为固定的水平条纹,以获得更丰富的细粒度局部特征,但是固定的水平条纹可能无法处理图
像之间的严重错位,并且不能消除背景或遮挡的影响。另外,还可以可学习的网格自动生成区域。但是,并未很地研究不同生成区域的重要性,使得难以处理遮挡区域或区域未对准问题。进一步地,本领域的基于注意力的方法,是以自我监督的方式学习注意力权重以获得代表特征,而权重是基于每个单个图像生成的,并且图像之间的固有关系会被忽略。因此,如何利用图像之间的固有关系生成自适应区域并挖掘更强大的功能,是实现对对象有效识别的重要问题。
[0159]
然而,该实施例提供了一种目标网络模型,其包括区域生成模型和区域感知模型,通过其对目标图像进行识别,得到目标区域的位置信息,进而通过位置信息对目标图像中的对象进行重识别,从而该实施例无需额外使用其它语义信息,因此计算量较小,检索效率较高,通过区域生成模型可以自动计算出具有鉴别力并且对齐的区域的坐标,可以避免遮挡区域的产生,对于每个生成区域,生成式区域感知网络给每个子区域赋予不同的权重,避免了无意义的子区域对网络造成的影响,解决了对对象进行重识别的效率低的技术问题,从而提高了对对象进行重识别的效率的技术效果。
[0160]
实施例2
[0161]
下面对该实施例的上述方法的优选实施方式进行进一步介绍,具体以对象识别为行人重识别进行举例介绍。
[0162]
在实现行人重识别时,由于难以对于部分遮挡区域进行检测,对行人进行准确检测,以及由于人类姿势的变化和相机视角的变化所提取的具有鉴别性和鲁棒性的区域,使得行人重识别仍然具有挑战性。
[0163]
在一种相关技术中,可以采用基于区域的方法来实现行人重识别,图6(a)是根据相关技术中的一种基于区域的方法实现行人重识别的示意图,图6(b)是根据相关技术中的另一种基于区域的方法实现行人重识别的示意图,如图6(a)和6(b)所示,可以将行人的图像直接分为固定的水平条纹,并且每部分具有相同的权重(0.167),以获得更丰富的细粒度局部特征。但是,该固定的水平条纹可能无法处理图像之间的严重错位,并且不能消除背景或遮挡区域的影响。
[0164]
在另一种相关技术中,可以通过可学习的网格来自动生成区域。但是,该方法还尚未很好地研究不同生成区域的重要性,这在处理遮挡区域或未对准问题时是致命的。
[0165]
在另一种相关技术中,可以基于注意力的方法以自我监督的方式可以学习注意力权重,从而获得代表特征,而权重是基于每个单个图像生成的,并且图像之间的固有关系常常被忽略。因此,如何利用图像之间的固有关系生成自适应区域并挖掘更强大的功能是至关重要的问题。
[0166]
下面针对上述问题,对本技术的技术方案进行介绍。
[0167]
图7是根据本发明实施例的一种用于实现行人重识别的生成式区域感知网络的示意图。如图7所示,生成式区域感知网络(g-ran)可以包括区域生成模型(rgm)和区域感知模型(ram),rgm通过两个级联的全连接层(fc)自适应地预测区域的坐标。
[0168]
该实施例可以先提取待识别的目标图像(标识为id:1)的特征图,可选地,该实施例可以通过卷积神经网络模型(conv)从目标图像中提取出特征图其中,c可以用于表示特征图的通道数值,h可以用于表示特征图的高度,w可以用于表示特征图的宽度。在提取出目标图像的特征图之后,该实施例可以基于区域生成模型中的全连接层对
特征图进行预测,得到多个子图像分别对应的子区域的位置信息。可选地,该实施例可以将特征图输入至卷积层(conv),以降低特征图的通道的宽度,然后对卷积层的输出结果进行最大池化操作(max-pooling operation),得到池化结果,进而将池化结果输入至第一全连接层(fc)和第二全连接层(fc)进行分类,来预测出子区域的位置信息。可选地,该实施例的子区域的位置信息可以通过以下公式来表示:
[0169]
θ=θj(j=1,
…
,p)=φ(f,δ,α)
[0170][0171]
其中,θ可以用于表示子区域的坐标,φ可以用于表示区域生成模型,δ,α分别用于表示卷积层和全连接层的参数,θj用于表示子区域的坐标,并且包括四个坐标参数其分别用于表示顶部、左、底部、右侧的坐标。
[0172]
可选地,在该实施例中,ram可以进一步包括两个区域感知模块,即,鉴别力感知指示器和不变性感知指示器。鉴别力感知指示器可以使用符号f代表自注意力机制,来计算每个区域的区别特征,可以用于确定鉴别力权重(discriminative weight)α。存储库可以存储所生成区域的特征。为了学习不变权重,不变性感知指示器可以通过存储库将给定图像的区域与来自属于同一id的其他图像的对应区域进行比较,其可以用于确定不变性权重(invariance weight)
[0173]
可选地,该实施例通过鉴别力感知指示器通过自注意力机制(f)来对子区域的特征进行分析,得到子区域的鉴别力权重,其中,子区域的特征可以通过以下公式进行表示:
[0174][0175]
其中,fr可以用于表示子区域的特征,c1可以用于表示特征图在通过卷积层处理后的通道数,p可以用于表示子区域的数量,比如,为6个,fj可以用于表示第j个特征图。该实施例将子区域的特征作为第一子感知模型的输入,将每个子区域的目标权重作为第一子感知模型的输出。fg用于表示全局特征,是通过全局平均池化操作(global average pooling,简称为gap)来获得的。
[0176]
该实施例的子区域的鉴别力权重可以通过以下公式进行实现:
[0177][0178]
其中,αj用于表示第j个子区域的权重(鉴别力权重,discriminative weight),wa用于表示第一全连接层和第二全连接层的参数,σ用于表示激活函数。
[0179]
可选地,该实施例创建一个目标存储库,子区域的特征存储在目标存储库中,该目标存储库包括用于训练第二子感知模型的图像的区域特征,可以使用第二子感知模型对具有相同标识的对齐区域进行比较。可选地,该实施例的目标存储库的长度可以设置为经验值20。
[0180]
可选地,该实施例通过以下公式来表示存储库:
[0181][0182]
其中,t可以用于表示训练代数,m可以用于表示更新率,可以设为0.7,可以为通过的正则化表示结果。
[0183]
可选地,在该实施例中,可以计算fj和gj之间的相似度sj:
[0184][0185]
其中,rj用于表示第j个子区域。
[0186]
平均权重可以通过下述公式进行表示:
[0187][0188]
其中,为包括l的相似度分数的矩阵,l为目标存储库的其中一个尺寸。
[0189]
可选地,该实施例可以使用全连接层对进行调整,可以通过如下公式进行实现:
[0190][0191]
其中,并且为全连接层的参数,r为衰减率,可以为2。
[0192]
在该实施例中,可以使用softmax函数对进行正则化处理,以获取对应的子区域的不变性权重,进而将鉴别力权重和不变性权重之间的和,确定为目标区域的目标权重。
[0193]
图8(a)是根据本发明实施例的一种子区域的数量与行人重识别、区域等级的平均精度的关系的示意图。如图8(a)所示,当子区域的数量超过6,行人重识别的平均精度(meanaverage precision,简称为map)和区域等级(rank)会降低;而当子区域的数量未超过6时,行人重识别的平均精度和区域等级会增加。
[0194]
图8(b)是根据本发明实施例的一种区域比率与行人重识别的平均精度、区域等级的关系的示意图。如图8(b)所示,当区域比率超过0.125,行人重识别的平均精度或区域等级会降低;而当区域比率未超过0.125时,行人重识别的平均精度或区域等级会增加。其中,区域比率为子区域的尺寸占全部图的尺寸的比率。
[0195]
图9(a)是根据本发明实施例的一种存储库的长度与行人重识别的平均精度、区域等级的关系的示意图。如图9(a)所示,当存储库的长度超过20,行人重识别的平均精度和区域等级会降低;而当存储库的长度未超过20时,行人重识别的平均精度和区域等级会增加。
[0196]
该实施例在训练阶段,可以通过不变性感知指示器的总损失训练样本对应的区域特征的损失(lr)和全局特征的损失(lg)共同优化g-ran以学习判别和不变特征。
[0197]
图9(b)是根据本发明实施例的一种不变性感知指示器的总损失与行人重识别的平均精度、区域等级的关系的示意图。如图9(b)所示,当在0.5至1.0之间时,行人重识别的平均精度、区域等级不会明显地变化。
[0198]
图10(a)是根据本发明实施例的一种通过生成式区域感知网络对行人进行重识别的结果的示意图。图10(b)是根据本发明实施例的另一种通过生成式区域感知网络对行人进行重识别的结果的示意图。如图10(a)和10(b)所示,通过该实施例的生成式区域感知网络对行人进行重识别可以自适应地避开背景和遮挡区域的影响,并且每个部分的区域的权
重不同,且每个部分的区域的权重用于表示该区域的重要性。
[0199]
该实施例提出了一种简单而有效的针对行人重识别的生成生成式区域感知网络(g-ran),其中设计了区域生成模块(rgm)以通过有效的弱监督范式为行人重识别生成区域,而区域分类损失可以用于很好地对齐区域;在g-ran中,为了进一步分析生成的区域,该实施例还提出了一个区域感知模块(ram),可以通过其中的鉴别力感知指示器和不变性感知指示器为每个区域分配权重,从而学习给定区域的合理贡献值;该实施例的g-ran在包括数据集market-1501,数据集dukemtmc-reid和数据集cuhk03-np在内的多个基准数据集上,可以实现最先进的性能,除了正常的行人重识别问题之外,g-ran还对被遮挡的行人重识别任务进行了显着改进,并且在被遮挡的数据集dukemtmc上,其最新技术在rank-1的性能超过了6.8%。
[0200]
该实施例通过上述方法无需额外使用人体语义信息,因此计算量较小,检索效率较高;通过网络自动计算出具有鉴别力并且对齐的区域的坐标,避免了遮挡区域的产生;对于每个生成区域,生成式区域感知网络可以为每个区域赋予不同的权重,从而避免无意义的区域对网络所造成的影响。
[0201]
需要说明的是,对于前述的各方法实施例,为了简单描述,故将其都表述为一系列的动作组合,但是本领域技术人员应该知悉,本发明并不受所描述的动作顺序的限制,因为依据本发明,某些步骤可以采用其他顺序或者同时进行。其次,本领域技术人员也应该知悉,说明书中所描述的实施例均属于优选实施例,所涉及的动作和模块并不一定是本发明所必须的。
[0202]
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到根据上述实施例的方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质(如rom/ram、磁碟、光盘)中,包括若干指令用以使得一台终端设备(可以是手机,计算机,服务器,或者网络设备等)执行本发明各个实施例所述的方法。
[0203]
实施例3
[0204]
根据本发明实施例,还提供了一种用于实施上述图2所示实施例的对象的识别方法的对象的识别装置。
[0205]
图11是根据本发明实施例的一种对象的识别装置的示意图。如图11所示,该对象的识别装置110可以包括:第一获取单元111、第一识别单元112和第二识别单元113。
[0206]
第一获取单元111,用于获取包括待识别的对象的目标图像。
[0207]
第一识别单元112,用于通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息,其中,目标网络模型包括区域生成模型和区域感知模型,区域生成模型用于确定目标图像中多个子图像分别对应的子区域的位置信息,子图像包括对象的至少一个子对象,区域感知模型用于确定子区域的目标权重,目标权重用于表示子区域对目标区域的重要程度。
[0208]
第二识别单元113,用于基于目标位置信息对目标图像中的对象进行重识别,得到重识别结果。
[0209]
此处需要说明的是,上述第一获取单元111、第一识别单元112和第二识别单元113
对应于实施例1中的步骤s202至步骤s206,三个单元与对应的步骤所实现的实例和应用场景相同,但不限于上述实施例一所公开的内容。需要说明的是,上述单元作为装置的一部分可以运行在实施例一提供的计算机终端10中。
[0210]
根据本发明实施例,还提供了另一种用于实施上述图3所示实施例的对象的识别方法的对象的识别装置。
[0211]
图12是根据本发明实施例的另一种对象的识别装置的示意图。如图12所示,该对象的识别装置120可以包括:第二获取单元121、第三识别单元122和第四识别单元123。
[0212]
第二获取单元121,用于获取包括待识别的行人的目标图像。
[0213]
第三识别单元122,用于通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息,其中,目标网络模型包括区域生成模型和区域感知模型,区域生成模型用于确定目标图像中多个子图像分别对应的子区域的位置信息,子图像包括行人的至少一个子部位,区域感知模型用于确定子区域的目标权重,目标权重用于表示子区域对目标区域的重要程度。
[0214]
第四识别单元123,用于基于目标位置信息对目标图像中的行人进行重识别,得到重识别结果。
[0215]
此处需要说明的是,上述第二获取单元121、第三识别单元122和第四识别单元123对应于实施例1中的步骤s302至步骤s306,三个单元与对应的步骤所实现的实例和应用场景相同,但不限于上述实施例一所公开的内容。需要说明的是,上述单元作为装置的一部分可以运行在实施例一提供的计算机终端10中。
[0216]
根据本发明实施例,还提供了另一种用于实施上述图4所示实施例的对象的识别方法的对象的识别装置。
[0217]
图13是根据本发明实施例的另一种对象的识别装置的示意图。如图13所示,该对象的识别装置130可以包括:第一显示单元131和第二显示单元132。
[0218]
第一显示单元131,用于在目标界面显示包括待识别的对象的目标图像。
[0219]
第二显示单元132,用于在目标界面显示重识别结果,其中,重识别结果为基于目标区域的目标位置信息对目标图像中的对象进行重识别得到,目标位置信息为通过目标网络模型对目标图像进行识别得到,目标网络模型包括区域生成模型和区域感知模型,区域生成模型用于确定目标图像中多个子图像分别对应的子区域的位置信息,子图像包括对象的至少一个子对象,区域感知模型用于确定子区域的目标权重,目标权重用于表示子区域对目标区域的重要程度。
[0220]
此处需要说明的是,上述第一显示单元131和第二显示单元132对应于实施例1中的步骤s402至步骤s404,两个单元与对应的步骤所实现的实例和应用场景相同,但不限于上述实施例一所公开的内容。需要说明的是,上述单元作为装置的一部分可以运行在实施例一提供的计算机终端10中。
[0221]
根据本发明实施例,还提供了另一种用于实施上述图5所示实施例的对象的识别方法的对象的识别装置。
[0222]
图14是根据本发明实施例的另一种对象的识别装置的示意图。如图14所示,该对象的识别装置140可以包括:上传单元141和接收单元142。
[0223]
上传单元141,用于使前端客户端向后台服务器上传包括待识别的对象的目标图
像。
[0224]
接收单元142,用于使前端客户端接收后台服务器返回的重识别结果,其中,重识别结果为后台服务器基于目标区域的目标位置信息对目标图像中的对象进行重识别得到,目标位置信息为通过目标网络模型对目标图像进行识别得到,目标网络模型包括区域生成模型和区域感知模型,区域生成模型用于确定目标图像中多个子图像分别对应的子区域的位置信息,子图像包括对象的至少一个子对象,区域感知模型用于确定子区域的目标权重,目标权重用于表示子区域对目标区域的重要程度。
[0225]
此处需要说明的是,上述上传单元141和接收单元142对应于实施例1中的步骤s502至步骤s504,两个单元与对应的步骤所实现的实例和应用场景相同,但不限于上述实施例一所公开的内容。需要说明的是,上述单元作为装置的一部分可以运行在实施例一提供的计算机终端10中。
[0226]
在该实施例的对象的识别装置中,提供了一种目标网络模型,其包括区域生成模型和区域感知模型,通过其对目标图像进行识别,得到目标区域的位置信息,进而通过位置信息对目标图像中的对象进行重识别,从而该实施例无需额外使用其它语义信息,因此计算量较小,检索效率较高,通过区域生成模型可以自动计算出具有鉴别力并且对齐的区域的坐标,可以避免遮挡区域的产生,对于每个生成区域,生成式区域感知网络给每个子区域赋予不同的权重,避免了无意义的子区域对网络造成的影响,解决了对对象进行重识别的效率低的技术问题,从而提高了对对象进行重识别的效率的技术效果。
[0227]
实施例4
[0228]
本发明的实施例可以提供一种对象的识别系统,该对象的识别系统可以包括一种计算机终端,该计算机终端可以是计算机终端群中的任意一个计算机终端设备。可选地,在本实施例中,上述计算机终端也可以替换为移动终端等终端设备。
[0229]
可选地,在本实施例中,上述计算机终端可以位于计算机网络的多个网络设备中的至少一个网络设备。
[0230]
在本实施例中,上述计算机终端可以执行对象的识别方法中以下步骤的程序代码:获取包括待识别的对象的目标图像;通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息,其中,目标网络模型包括区域生成模型和区域感知模型,区域生成模型用于确定目标图像中多个子图像分别对应的子区域的位置信息,子图像包括对象的至少一个子对象,区域感知模型用于确定子区域的目标权重,目标权重用于表示子区域对目标区域的重要程度;基于目标位置信息对目标图像中的对象进行重识别,得到重识别结果。
[0231]
可选地,图15是根据本发明实施例的一种计算机终端的结构框图。如图15所示,该计算机终端a可以包括:一个或多个(图中仅示出一个)处理器1502、存储器1504、以及传输装置1506。
[0232]
其中,存储器可用于存储软件程序以及模块,如本发明实施例中的对象的识别方法和装置对应的程序指令/模块,处理器通过运行存储在存储器内的软件程序以及模块,从而执行各种功能应用以及数据处理,即实现上述的对象的识别方法。存储器可包括高速随机存储器,还可以包括非易失性存储器,如一个或者多个磁性存储装置、闪存、或者其他非易失性固态存储器。在一些实例中,存储器可进一步包括相对于处理器远程设置的存储器,
这些远程存储器可以通过网络连接至计算机终端a。上述网络的实例包括但不限于互联网、企业内部网、局域网、移动通信网及其组合。
[0233]
处理器可以通过传输装置调用存储器存储的信息及应用程序,以执行下述步骤:获取包括待识别的对象的目标图像;通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息,其中,目标网络模型包括区域生成模型和区域感知模型,区域生成模型用于确定目标图像中多个子图像分别对应的子区域的位置信息,子图像包括对象的至少一个子对象,区域感知模型用于确定子区域的目标权重,目标权重用于表示子区域对目标区域的重要程度;基于目标位置信息对目标图像中的对象进行重识别,得到重识别结果。
[0234]
可选地,上述处理器还可以执行如下步骤的程序代码:在通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息之前,提取目标图像的特征图;通过目标网络模型对特征图对应的目标区域进行识别,得到目标位置信息。
[0235]
可选地,上述处理器还可以执行如下步骤的程序代码:基于区域生成模型中的全连接层对特征图进行预测,得到多个子图像分别对应的子区域的位置信息;基于区域感知模型中的子感知模型确定目标权重;基于子区域的位置信息和目标权重确定目标位置信息。
[0236]
可选地,上述处理器还可以执行如下步骤的程序代码:对特征图进行最大池化操作,得到池化结果;基于第一全连接层和第二全连接层对池化结果进行分类,得到子区域的位置信息,其中,第一全连接层和第二全连接层级联。
[0237]
可选地,上述处理器还可以执行如下步骤的程序代码:通过第一子感知模型通过自注意力机制对子区域的特征进行分析,得到子区域的第一权重,其中,第一子感知模型包括第三全连接层和激活函数;通过第二子感知模型将子区域和与目标图像具有同一标识的其它图像对应的区域进行比较,得到比较结果,并基于比较结果确定子区域的第二权重;将第一权重和第二权重之和,确定为目标权重。
[0238]
可选地,上述处理器还可以执行如下步骤的程序代码:在通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息之后,在子区域的尺寸未处于目标尺寸范围的情况下,基于子区域的面积和目标图像的特征图的尺寸将子区域的尺寸调整至目标尺寸范围内。
[0239]
可选地,上述处理器还可以执行如下步骤的程序代码:在通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息之后,在子区域的高宽比未处于目标高宽比范围的情况下,基于子区域的高宽比的临界值将子区域的高宽比调整至目标高宽比范围内。
[0240]
可选地,上述处理器还可以执行如下步骤的程序代码:在通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息之后,在子区域与其它子区域重叠的情况下,基于子区域与其它子区域之间的重叠度调整子区域,以使调整后的子区域与其它子区域之间的重叠度低于调整前的子区域与其它子区域之间的重叠度。
[0241]
可选地,上述处理器还可以执行如下步骤的程序代码:在通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息之后,基于子区域的区域分类损失,将子区域的特征与其它子区域的特征进行对齐。
[0242]
可选地,上述处理器还可以执行如下步骤的程序代码:在通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息之前,基于训练样本的全局特征的损失、区域特征的损失和区域生成模型对应的损失训练目标网络模型。
[0243]
作为一种可选的实施方式,处理器可以通过传输装置调用存储器存储的信息及应用程序,以执行下述步骤:获取包括待识别的行人的目标图像;通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息,其中,目标网络模型包括区域生成模型和区域感知模型,区域生成模型用于确定目标图像中多个子图像分别对应的子区域的位置信息,子图像包括行人的至少一个子部位,区域感知模型用于确定子区域的目标权重,目标权重用于表示子区域对目标区域的重要程度;基于目标位置信息对目标图像中的行人进行重识别,得到重识别结果。
[0244]
可选地,上述处理器还可以执行如下步骤的程序代码:在通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息之前,提取目标图像的特征图;通过目标网络模型对特征图对应的目标区域进行识别,得到目标位置信息。
[0245]
作为一种可选的实施方式,处理器可以通过传输装置调用存储器存储的信息及应用程序,以执行下述步骤:在目标界面显示包括待识别的对象的目标图像;在目标界面显示重识别结果,其中,重识别结果为基于目标区域的目标位置信息对目标图像中的对象进行重识别得到,目标位置信息为通过目标网络模型对目标图像进行识别得到,目标网络模型包括区域生成模型和区域感知模型,区域生成模型用于确定目标图像中多个子图像分别对应的子区域的位置信息,子图像包括对象的至少一个子对象,区域感知模型用于确定子区域的目标权重,目标权重用于表示子区域对目标区域的重要程度。
[0246]
作为一种可选的实施方式,处理器可以通过传输装置调用存储器存储的信息及应用程序,以执行下述步骤:前端客户端向后台服务器上传包括待识别的对象的目标图像;前端客户端接收后台服务器返回的重识别结果,其中,重识别结果为后台服务器基于目标区域的目标位置信息对目标图像中的对象进行重识别得到,目标位置信息为通过目标网络模型对目标图像进行识别得到,目标网络模型包括区域生成模型和区域感知模型,区域生成模型用于确定目标图像中多个子图像分别对应的子区域的位置信息,子图像包括对象的至少一个子对象,区域感知模型用于确定子区域的目标权重,目标权重用于表示子区域对目标区域的重要程度。
[0247]
作为一种可选的实施方式,处理器可以通过传输装置调用存储器存储的信息及应用程序,以执行下述步骤:在目标界面的录入界面中录入包括待识别的对象的目标图像;在目标界面内感应到位置生成指令,显示目标图像对应的目标区域的目标位置信息,其中,目标位置信息为通过目标图像中多个子图像分别对应的子区域的位置信息和子区域的目标权重得到,子图像包括对象的至少一个子对象,目标权重用于表示子区域对目标区域的重要程度;在目标界面内感应到识别指令,显示重识别结果,其中,重识别结果通过基于目标位置信息对目标图像中的对象进行重识别得到。
[0248]
采用本发明实施例,提供了一种对象的识别方法。该方法可以包括:获取包括待识别的对象的目标图像;通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息,其中,目标网络模型包括区域生成模型和区域感知模型,区域生成模型用于确定目标图像中多个子图像分别对应的子区域的位置信息,子图像包括对象的至少
一个子对象,区域感知模型用于确定子区域的目标权重,目标权重用于表示子区域对目标区域的重要程度;基于目标位置信息对目标图像中的对象进行重识别,得到重识别结果。也就是说,本技术提供了一种目标网络模型,其包括区域生成模型和区域感知模型,通过其对目标图像进行识别,得到目标区域的位置信息,进而通过位置信息对目标图像中的对象进行重识别,从而该实施例无需额外使用其它语义信息,因此计算量较小,检索效率较高,通过区域生成模型可以自动计算出具有鉴别力并且对齐的区域的坐标,可以避免遮挡区域的产生,对于每个生成区域,生成式区域感知网络给每个子区域赋予不同的权重,避免了无意义的子区域对网络造成的影响,解决了对对象进行重识别的效率低的技术问题,从而提高了对对象进行重识别的效率的技术效果。
[0249]
本领域普通技术人员可以理解,图15所示的结构仅为示意,计算机终端a也可以是智能手机(如android手机、ios手机等)、平板电脑、掌声电脑以及移动互联网设备(mobile internet devices,mid)、pad等终端设备。图15其并不对上述计算机终端a的结构造成限定。例如,计算机终端a还可包括比图15中所示更多或者更少的组件(如网络接口、显示装置等),或者具有与图15所示不同的配置。
[0250]
本领域普通技术人员可以理解上述实施例的各种方法中的全部或部分步骤是可以通过程序来指令终端设备相关的硬件来完成,该程序可以存储于一计算机可读存储介质中,存储介质可以包括:闪存盘、只读存储器(read-only memory,rom)、随机存取器(random access memory,ram)、磁盘或光盘等。
[0251]
实施例5
[0252]
本发明的实施例还提供了一种计算机可读存储介质。可选地,在本实施例中,上述计算机可读存储介质可以用于保存上述实施例一所提供的对象的识别方法所执行的程序代码。
[0253]
可选地,在本实施例中,上述计算机存储介质可以位于计算机网络中计算机终端群中的任意一个计算机终端中,或者位于移动终端群中的任意一个移动终端中。
[0254]
可选地,在本实施例中,计算机可读存储介质被设置为存储用于执行以下步骤的程序代码:获取包括待识别的对象的目标图像;通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息,其中,目标网络模型包括区域生成模型和区域感知模型,区域生成模型用于确定目标图像中多个子图像分别对应的子区域的位置信息,子图像包括对象的至少一个子对象,区域感知模型用于确定子区域的目标权重,目标权重用于表示子区域对目标区域的重要程度;基于目标位置信息对目标图像中的对象进行重识别,得到重识别结果。
[0255]
可选地,在本实施例中,计算机可读存储介质被设置为存储用于执行以下步骤的程序代码:在通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息之前,提取目标图像的特征图;通过目标网络模型对特征图对应的目标区域进行识别,得到目标位置信息。
[0256]
可选地,在本实施例中,计算机可读存储介质被设置为存储用于执行以下步骤的程序代码:基于区域生成模型中的全连接层对特征图进行预测,得到多个子图像分别对应的子区域的位置信息;基于区域感知模型中的子感知模型确定目标权重;基于子区域的位置信息和目标权重确定目标位置信息。
[0257]
可选地,在本实施例中,计算机可读存储介质被设置为存储用于执行以下步骤的程序代码:对特征图进行最大池化操作,得到池化结果;基于第一全连接层和第二全连接层对池化结果进行分类,得到子区域的位置信息,其中,第一全连接层和第二全连接层级联。
[0258]
可选地,在本实施例中,计算机可读存储介质被设置为存储用于执行以下步骤的程序代码:通过第一子感知模型通过自注意力机制对子区域的特征进行分析,得到子区域的第一权重,其中,第一子感知模型包括第三全连接层和激活函数;通过第二子感知模型将子区域和与目标图像具有同一标识的其它图像对应的区域进行比较,得到比较结果,并基于比较结果确定子区域的第二权重;将第一权重和第二权重之和,确定为目标权重。
[0259]
可选地,在本实施例中,计算机可读存储介质被设置为存储用于执行以下步骤的程序代码:在通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息之后,在子区域的尺寸未处于目标尺寸范围的情况下,基于子区域的面积和目标图像的特征图的尺寸将子区域的尺寸调整至目标尺寸范围内。
[0260]
可选地,在本实施例中,计算机可读存储介质被设置为存储用于执行以下步骤的程序代码:在通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息之后,在子区域的高宽比未处于目标高宽比范围的情况下,基于子区域的高宽比的临界值将子区域的高宽比调整至目标高宽比范围内。
[0261]
可选地,在本实施例中,计算机可读存储介质被设置为存储用于执行以下步骤的程序代码:在通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息之后,在子区域与其它子区域重叠的情况下,基于子区域与其它子区域之间的重叠度调整子区域,以使调整后的子区域与其它子区域之间的重叠度低于调整前的子区域与其它子区域之间的重叠度。
[0262]
可选地,在本实施例中,计算机可读存储介质被设置为存储用于执行以下步骤的程序代码:在通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息之后,基于子区域的区域分类损失,将子区域的特征与其它子区域的特征进行对齐。
[0263]
可选地,在本实施例中,计算机可读存储介质被设置为存储用于执行以下步骤的程序代码:在通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息之前,基于训练样本的全局特征的损失、区域特征的损失和区域生成模型对应的损失训练目标网络模型。
[0264]
作为一种可选的实施方式,计算机可读存储介质被设置为存储用于执行以下步骤的程序代码:获取包括待识别的行人的目标图像;通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息,其中,目标网络模型包括区域生成模型和区域感知模型,区域生成模型用于确定目标图像中多个子图像分别对应的子区域的位置信息,子图像包括行人的至少一个子部位,区域感知模型用于确定子区域的目标权重,目标权重用于表示子区域对目标区域的重要程度;基于目标位置信息对目标图像中的行人进行重识别,得到重识别结果。
[0265]
可选地,在本实施例中,计算机可读存储介质被设置为存储用于执行以下步骤的程序代码:在通过目标网络模型对目标图像进行识别,得到目标图像对应的目标区域的目标位置信息之前,提取目标图像的特征图;通过目标网络模型对特征图对应的目标区域进
行识别,得到目标位置信息。
[0266]
作为一种可选的实施方式,计算机可读存储介质被设置为存储用于执行以下步骤的程序代码:在目标界面显示包括待识别的对象的目标图像;在目标界面显示重识别结果,其中,重识别结果为基于目标区域的目标位置信息对目标图像中的对象进行重识别得到,目标位置信息为通过目标网络模型对目标图像进行识别得到,目标网络模型包括区域生成模型和区域感知模型,区域生成模型用于确定目标图像中多个子图像分别对应的子区域的位置信息,子图像包括对象的至少一个子对象,区域感知模型用于确定子区域的目标权重,目标权重用于表示子区域对目标区域的重要程度。
[0267]
作为一种可选的实施方式,计算机可读存储介质被设置为存储用于执行以下步骤的程序代码:前端客户端向后台服务器上传包括待识别的对象的目标图像;前端客户端接收后台服务器返回的重识别结果,其中,重识别结果为后台服务器基于目标区域的目标位置信息对目标图像中的对象进行重识别得到,目标位置信息为通过目标网络模型对目标图像进行识别得到,目标网络模型包括区域生成模型和区域感知模型,区域生成模型用于确定目标图像中多个子图像分别对应的子区域的位置信息,子图像包括对象的至少一个子对象,区域感知模型用于确定子区域的目标权重,目标权重用于表示子区域对目标区域的重要程度。
[0268]
作为一种可选的实施方式,计算机可读存储介质被设置为存储用于执行以下步骤的程序代码:在目标界面的录入界面中录入包括待识别的对象的目标图像;在目标界面内感应到位置生成指令,显示目标图像对应的目标区域的目标位置信息,其中,目标位置信息为通过目标图像中多个子图像分别对应的子区域的位置信息和子区域的目标权重得到,子图像包括对象的至少一个子对象,目标权重用于表示子区域对目标区域的重要程度;在目标界面内感应到识别指令,显示重识别结果,其中,重识别结果通过基于目标位置信息对目标图像中的对象进行重识别得到。
[0269]
上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
[0270]
在本发明的上述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详述的部分,可以参见其他实施例的相关描述。
[0271]
在本技术所提供的几个实施例中,应该理解到,所揭露的技术内容,可通过其它的方式实现。其中,以上所描述的装置实施例仅仅是示意性的,例如所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,单元或模块的间接耦合或通信连接,可以是电性或其它的形式。
[0272]
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
[0273]
另外,在本发明各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
[0274]
所述集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可为个人计算机、服务器或者网络设备等)执行本发明各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:u盘、只读存储器(rom,read-only memory)、随机存取存储器(ram,random access memory)、移动硬盘、磁碟或者光盘等各种可以存储程序代码的介质。
[0275]
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1