基于高级持续性威胁攻击的信息处理方法及系统与流程
[0001]
本发明涉及网络技术领域,特别是涉及一种基于高级持续性威胁攻击的信息处理方法及系统。
背景技术:
[0002]
在进行apt(advanced persistent threat,高级持续性威胁攻击)的追踪和研究过程中,基于网络安全监测的实时数据、各种多源异构的威胁情报平台及论坛数据,往往会积累海量关于apt攻击组织及相关ttp(tactic technique process,攻击技战术)的信息,如果能够有效抽取、存储和利用这些信息,将会为apt攻击追踪和发现提供重要的信息帮助,因此,如何获得高级持续性威胁攻击的有效信息已经成为目前的研究重点。
技术实现要素:
[0003]
针对于上述问题,本发明提供一种基于高级持续性威胁攻击的信息处理方法及系统,实现了能够有效获得高级持续性威胁攻击的相关信息,便于对信息的更有效地利用。
[0004]
为了实现上述目的,本发明提供了如下技术方案:
[0005]
一种基于高级持续性威胁攻击的信息处理方法,所述方法包括:
[0006]
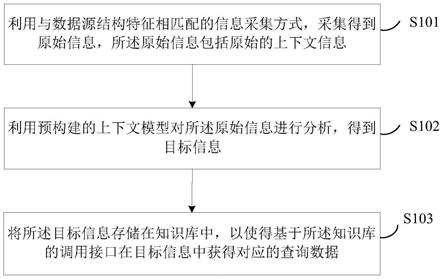
利用与数据源结构特征相匹配的信息采集方式,采集得到原始信息,所述原始信息包括原始的上下文信息;
[0007]
利用预构建的上下文模型对所述原始信息进行分析,得到目标信息,所述上下文模型用于对所述原始信息进行过滤、推断和融合处理,所述目标信息表征具有统一描述格式的高层上下文;
[0008]
将所述目标信息存储在知识库中,以使得基于所述知识库的调用接口在目标信息中获得对应的查询数据。
[0009]
可选地,所述利用与数据源结构特征相匹配的信息采集方式,采集得到原始信息,包括:
[0010]
针对于非实时的半结构化的高级持续威胁攻击情报信息,利用预设的爬虫引擎进行信息采集,获得原始信息;
[0011]
针对大数据平台实时生成的数据,利用预设的大数据框架进行信息采集,获得原始信息。
[0012]
可选地,所述爬虫引擎包括引擎、调度器、下载器、爬虫单元、管道、下载中间件和爬虫中间件构成,所述利用预设的爬虫引擎进行信息采集,获得原始信息,包括:
[0013]
通过所述引擎从所述调度器读取用于进行信息抓取的链接;
[0014]
利用所述引擎将所述链接封装成请求,并将所述请求发送给所述下载器;
[0015]
通过所述下载器将与所述请求对应的资源进行下载,并生成应答包;
[0016]
通过爬取单元对所述应答包进行解析,得到实体信息,将所述实体信息发送给所述管道,使得所述管道对所述实体信息进行即系得到所述链接,将所述链接发送给调度器,
使得所述调度器进行信息抓取,得到原始信息。
[0017]
可选地,所述利用预设的大数据框架进行信息采集,获得原始信息,包括:
[0018]
通过所述预设的大数据框架的流式计算,对大数据平台实时生成的数据进行处理和规范,得到原始数据。
[0019]
可选地,所述方法还包括:
[0020]
创建上下文模型,包括:
[0021]
构建高级持续性威胁攻击的威胁本体结构,所述威胁本体结构包括各个实体概念类的定义以及实体概念类之间关系的定义;
[0022]
对上下文语义存储格式进行统一,得到目标上下文语义;
[0023]
基于所述威胁本体结构,对所述目标上下文语义进行表示,得到上下文模型。
[0024]
可选地,所述利用预构建的上下文模型对所述原始信息进行分析,得到目标信息,包括:
[0025]
对所述原始信息进行上下文过滤,得到过滤够的信息;
[0026]
利用预构建的上下文模型得到实体和关系抽取规则,并利用所述规则在过滤后的信息中进行信息抽取,得到抽取后的信息;
[0027]
将抽取后的信息进行上下文语义融合,得到目标信息,其中,所述上下文语义融合包括实体链接的处理方式,所述实体链接为将上下文中提到的实体与知识库中对应的实体进行链接的处理方式。
[0028]
一种基于高级持续性威胁攻击的信息处理系统,所述系统包括:
[0029]
采集单元,用于利用与数据源结构特征相匹配的信息采集方式,采集得到原始信息,所述原始信息包括原始的上下文信息;
[0030]
分析单元,用于利用预构建的上下文模型对所述原始信息进行分析,得到目标信息,所述上下文模型用于对所述原始信息进行过滤、推断和融合处理,所述目标信息表征具有统一描述格式的高层上下文;
[0031]
存储单元,用于将所述目标信息存储在知识库中,以使得基于所述知识库的调用接口在目标信息中获得对应的查询数据。
[0032]
可选地,所述采集单元包括:
[0033]
第一采集子单元,用于针对于非实时的半结构化的高级持续威胁攻击情报信息,利用预设的爬虫引擎进行信息采集,获得原始信息;
[0034]
第二采集子单元,用于针对大数据平台实时生成的数据,利用预设的大数据框架进行信息采集,获得原始信息。
[0035]
可选地,所述爬虫引擎包括引擎、调度器、下载器、爬虫单元、管道、下载中间件和爬虫中间件构成,所述第一采集子单元具体用于:
[0036]
通过所述引擎从所述调度器读取用于进行信息抓取的链接;
[0037]
利用所述引擎将所述链接封装成请求,并将所述请求发送给所述下载器;
[0038]
通过所述下载器将与所述请求对应的资源进行下载,并生成应答包;
[0039]
通过爬取单元对所述应答包进行解析,得到实体信息,将所述实体信息发送给所述管道,使得所述管道对所述实体信息进行即系得到所述链接,将所述链接发送给调度器,使得所述调度器进行信息抓取,得到原始信息。
[0040]
可选地,所述第二采集子单元具体用于:
[0041]
通过所述预设的大数据框架的流式计算,对大数据平台实时生成的数据进行处理和规范,得到原始数据。
[0042]
可选地,所述系统还包括:
[0043]
创建单元,用于创建上下文模型,所述创建单元具体用于包括:
[0044]
构建高级持续性威胁攻击的威胁本体结构,所述威胁本体结构包括各个实体概念类的定义以及实体概念类之间关系的定义;
[0045]
对上下文语义存储格式进行统一,得到目标上下文语义;
[0046]
基于所述威胁本体结构,对所述目标上下文语义进行表示,得到上下文模型。
[0047]
可选地,所述分析单元包括:
[0048]
过滤子单元,用于对所述原始信息进行上下文过滤,得到过滤够的信息;
[0049]
抽取子单元,用于利用预构建的上下文模型得到实体和关系抽取规则,并利用所述规则在过滤后的信息中进行信息抽取,得到抽取后的信息;
[0050]
融合子单元,用于将抽取后的信息进行上下文语义融合,得到目标信息,其中,所述上下文语义融合包括实体链接的处理方式,所述实体链接为将上下文中提到的实体与知识库中对应的实体进行链接的处理方式。
[0051]
相较于现有技术,本发明提供了一种基于高级持续性威胁攻击的信息处理方法及系统,利用与数据源结构特征相匹配的信息采集方式,采集得到原始信息,所述原始信息包括原始的上下文信息;利用预构建的上下文模型对所述原始信息进行分析,得到目标信息,所述上下文模型用于对所述原始信息进行过滤、推断和融合处理,所述目标信息表征具有统一描述格式的高层上下文;将所述目标信息存储在知识库中,以使得基于所述知识库的调用接口在目标信息中获得对应的查询数据。实现了能够有效获得高级持续性威胁攻击的相关信息,便于对信息的更有效地利用。
附图说明
[0052]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
[0053]
图1为本发明实施例提供的一种基于高级持续性威胁攻击的信息处理方法的流程示意图;
[0054]
图2为本发明实施例提供的一种apt上下文感知计算框架总体结构图;
[0055]
图3为本发明实施例提供的一种大数据框架的结构示意图;
[0056]
图4为本发明实施例提供的一种各个实体概念之间的关系图;
[0057]
图5为本发明实施例提供的一种基于高级持续性威胁攻击的信息处理系统的结构示意图。
具体实施方式
[0058]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完
整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0059]
本发明的说明书和权利要求书及上述附图中的术语“第一”和“第二”等是用于区别不同的对象,而不是用于描述特定的顺序。此外术语“包括”和“具有”以及他们任何变形,意图在于覆盖不排他的包含。例如包含了一系列步骤或单元的过程、方法、系统、产品或设备没有设定于已列出的步骤或单元,而是可包括没有列出的步骤或单元。
[0060]
在本发明实施例中提供了一种基于高级持续性威胁攻击的信息处理方法,基于本体论定义高级持续性威胁攻击(apt)本体模型,基于该本体模型设计一个专门针对apt上下文语义计算的框架,实现对多源异构apt上下文信息的采集,推理和存储,并提供查询api支撑基于知识库存储的上下文信息进行利用。
[0061]
参见图1,所述方法可以包括以下步骤:
[0062]
s101、利用与数据源结构特征相匹配的信息采集方式,采集得到原始信息,所述原始信息包括原始的上下文信息。
[0063]
在本发明实施例中根据不同的数据源利用对应的数据采集方式实现原始数据的获得。即针对于非实时的半结构化的高级持续威胁攻击情报信息,利用预设的爬虫引擎进行信息采集,获得原始信息;针对大数据平台实时生成的数据,利用预设的大数据框架进行信息采集,获得原始信息。
[0064]
参见图2,其示出了本发明实施例提供的一种apt上下文感知计算框架总体结构图,该上下文感知计算框架包含上下文采集模块、上下文推理模块和apt知识库三个主要部分,在apt知识库之上提供apt查询接口用于支撑基于知识库存储的上下文信息的利用。其中,上下文采集模块用于执行本发明实施例中的步骤s101的处理过程,以及该步骤对应的子步骤的处理过程。该上下文采集模块的主要功能时从异构、复杂多样的而信息源获取信息,这其中包括非实时的半结构化的开源apt威胁情报信息,比如,各种apt相关的论坛、博客和网站信息,也包括网络威胁检测设备和恶意样本沙箱实时的结构化日志告警信息。
[0065]
针对非实时的半结构化的apt威胁情报信息,设计基于爬虫引擎的apt网页爬虫系统,结合定义的apt本体结构,实现对apt上下文语义的采集,具体的爬虫引擎包括引擎、调度器、下载器、爬虫单元、管道、下载中间件和爬虫中间件构成,所述利用预设的爬虫引擎进行信息采集,获得原始信息,包括:
[0066]
通过所述引擎从所述调度器器读取用于进行信息抓取的链接;
[0067]
利用所述引擎将所述链接封装成请求,并将所述请求发送给所述下载器;
[0068]
通过所述下载器将与所述请求对应的资源进行下载,并生成应答包;
[0069]
通过爬取单元对所述应答包进行解析,得到实体信息,将所述实体信息发送给所述管道,使得所述管道对所述实体信息进行即系得到所述链接,将所述链接发送给调度器,使得所述调度器进行信息抓取,得到原始信息。
[0070]
举例说明,整个爬虫系统的核心框架是基于scrapy来设计的,框架主要包含以下几个核心模块:
[0071]
engine(引擎):爬虫的引擎是整合爬虫系统框架的核心,控制所有部件间的数据流。
[0072]
scheduler(调度器):接受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回。相当于一个url(抓取网页的网址或者说是链接)的优先队列。调度器决定下一个要抓取的网址是什么,同时负责去除重复的网址。
[0073]
下载器(downloader):用于下载引擎发送的所有requests(请求),并将获取到的responses发给引擎,再由引擎交给爬虫(spider)处理。
[0074]
爬虫(spider):它负责处理所有的responses,从中分析提取数据,获取item字段需要的数据,并将需要跟进的url提交给引擎,由引擎提交给scheduler(调度器)。
[0075]
itempipeline(管道):它负责处理spider中获取到的item,并进行进行后期处理(详细分析、过滤、存储等)。
[0076]
downloader middlewares(下载中间件):位于引擎和下载器之间的框架,主要是处理引擎与下载器之间的请求及响应。可以自定义扩展下载功能的组件(代理、cokies等)。
[0077]
爬虫中间件(spider middlewares):可以自定扩展和操作引擎和spider中间通信的功能组件。
[0078]
爬虫系统运行的流程如下:
[0079]
(1)引擎从调度器中取出一个链接(url)用于接下来的抓取;
[0080]
(2)引擎把url封装成一个请求(request)传给下载器;
[0081]
(3)下载器把资源下载下来,并封装成应答包(response);
[0082]
(4)爬虫解析response,解析出实体(item),则交给实体管道进行进一步的处理;
[0083]
(5)如果解析出的是链接(url),则把url交给调度器等待抓取;
[0084]
(6)重复步骤(1)直到调度器队列中不再有任何链接(url)。
[0085]
在本发明实施例中还可以基于大数据框架实现实时上下文采集。针对网络威胁检测设备和恶意样本检测沙箱等设备输出的实时的结构化或班结构化的数据,由于这一类数据通常是实时产生的、数量巨大,并且不同厂商不同类型的设备的输出数据格式也差异较大,因此设计基于大数据计算架构的海量日志处理模块,通过流式计算,实现对海量异构数据的快速处理和规范化。参见图3,其示出了本发明实施例的大数据框架的结构示意图。
[0086]
海量异构的网络设备告警日志通过多种方式接入到系统后,这些原始数据会首先被放到原始topic当中,之后sparkstreaming的job作为原始topic的consumer实现日志的范式化解析,之后将解析完成的日志又重新写入到新的topic当中;最后通过jdbc或rest的将解析完成的上下文语义数据分别写入到hive或者elasticsearch中。
[0087]
s102、利用预构建的上下文模型对所述原始信息进行分析,得到目标信息。
[0088]
所述上下文模型用于对所述原始信息进行过滤、推断和融合处理,所述目标信息表征具有统一描述格式的高层上下文。
[0089]
对应的,在本发明实施例中还提供了一种创建上下文模型的方法,包括:
[0090]
构建高级持续性威胁攻击的威胁本体结构,所述威胁本体结构包括各个实体概念类的定义以及实体概念类之间关系的定义;
[0091]
对上下文语义存储格式进行统一,得到目标上下文语义;
[0092]
基于所述威胁本体结构,对所述目标上下文语义进行表示,得到上下文模型。
[0093]
其中,所述利用预构建的上下文模型对所述原始信息进行分析,得到目标信息,包括:
[0094]
对所述原始信息进行上下文过滤,得到过滤够的信息;
[0095]
利用预构建的上下文模型得到实体和关系抽取规则,并利用所述规则在过滤后的信息中进行信息抽取,得到抽取后的信息;
[0096]
将抽取后的信息进行上下文语义融合,得到目标信息,其中,所述上下文语义融合包括实体链接的处理方式,所述实体链接为将上下文中提到的实体与知识库中对应的实体进行链接的处理方式。
[0097]
该过程可以由图2中的上下文推理模块实现。经过上下文采集模块获得的上下文语义信息往往有明显的异构性,其表示的方式不一致,具有单一、低层、不精确不稳定的特点。上下文推理模块的主要目标就是通过构建统一的上下文模型将采集模块收集到的原始的上下文利用过滤、推断和融合的方式将原始的低层上下文转换成具有统一描述格式的高层上下文,并存储在只是库当中。
[0098]
具体的,上下文感知计算的一个基础要求是能够处理各种各样的上下文数据,这就需要建立统一的上下文标识模型。本发明通过自上而下的方式定义apt威胁本体模型,基于该本体模型进行上下文建模和表示。主要目标是构建统一的语义表示模型,一方面构建apt威胁本体结构,包括本体下各个实体概念类的定义以及实体概念类之间关系的定义;另一方面是上下文语义存储格式的统一,比如统一用key-value键值对或者是json格式等。
[0099]
基于apt攻击所涉及的领域知识范围,定义apt威胁知识图谱的本体结构,该本体包含12个实体概念:威胁主体、目标客体、案例、意图危害、攻击模式、恶意代码模式、隐患、事件、威胁指示器、风险策略、合规和防御手段,各个实体概念之间的关系如图4所示。其示出了apt知识图谱本体结构的示意图。
[0100]
其中,各个实体概念类的详细描述如下:
[0101]
攻击模式:攻击发起者使用的策略、技术和程序。
[0102]
恶意代码:进行恶意活动的软件或代码片段,包含恶意代码的静态和动态信息。
[0103]
隐患:黑客可利用的不安全配置和软件漏洞。
[0104]
目标客体:攻击的目标对象详细信息。
[0105]
威胁主体:攻击发起者的详细信息,可以是个人、团体和组织。
[0106]
案例:针对具体目标的一系列恶意行为或攻击。
[0107]
意图危害:针对特定目标的攻击意图以及相关危害描述。
[0108]
风险策略:威胁、隐患、事件映射而成的原子级的安全指标。
[0109]
合规:安全指标映射的外部安全标准。
[0110]
防御手段:针对攻击的防护和响应手段。
[0111]
事件:当前安全状态描述,重点关注的网络安全事件。
[0112]
威胁指示器:网络中可获取的单一实体,包括文件、网络连接、ip地址等。
[0113]
上下文推理模块的主要功能一方面在于构建同一上下文表达模型及结构,另一方面就在于如何识别有效的上下文语义信息,实现语义的筛选过滤、相同语义的融合,以及基于利用多个上下文语义信息进行推理,从而将经过上下文采集模块获取的模糊、重复、矛盾和不精确的原始语义转化为统一的、更加准确高层上下文。
[0114]
上下文过滤主要用于解决从原始上下文中甄选需要存储和支撑语义推理的语义内容,并且提出一部分格式内容错误的语义。在实际进行上下文语义过滤的过程中,首先基
于构建的上下文表示模型,即apt本体结构,构建对应的实体和关系抽取规则,将规则与文本字符串进行匹配,识别命名实体。此外,基于实体抽取规则获取的内容可能会出现格式错误不合要求的情况,此时需要构建格式匹配规则,针对所有抽取的上下文语义内容,进行格式匹配,剔除掉不符合要求语义内容。
[0115]
上下文抽取完成之后,由于其复杂性、多异性和模糊性的特点,导致同一实体概念可能对应多种的同义的语义内容,因此需要进行上下文语义融合,实现对同义语义内容的融合与消歧。在实际进行上下文融合的过程中,主要采取实体链接的方法来进行。实体链接将上下文中提到的实体与知识库中对应的实体进行链接的任务,可以有效解决实体间的歧义性问题。通常情况下,实体的歧义性主要表现在两个方面,首先是称之为多词同义的情况(md,mention detection),即多个不同词语指代同一个实体,比如美国和usa实际上是指同一个实体;另外就是称之为一词多义的情况(ed,entity disambiguation),即同一词语可能表示为多个实体,比如苹果既可以指代水果也可以指代apple公司。实体链接通常需要通过实体指称(mention)的方式将具体的词语连接到知识库正确的实体上。
[0116]
实体链接包括以下流程:
[0117]
第一,候选实体生成,主要采用基于实体词典的方法,通过定义各个实体的标准化词典,再通过trie树(前缀树)等方法进行匹配,将自由文本中的实体指称(entity mention)链接到知识库中对应的实体。通过字符匹配的方式链接到的实体可能会包含多个,这些实体共同组成候选实体列表。
[0118]
第二,候选实体排序,候选实体的排序方法是目前实体链接算法研究的重点和难点,但是针对apt领域的知识库来说,通常不会出现多个候选实体,即便出现,数量也不会太多,因此从处理效率的角度来考虑,一般直接采用抽取实体上下文信息进行相似度计算来实现候选实体的排序。比如在进行apt组织实体链接时,可能会出现同一个apt组织具有多个名称的情况,此时只需要额外多抽取描述文档中提及的该组织的别名逐个与候选实体进行匹配,选取相似度最高的一个实体进行链接即可。
[0119]
第三,上下文的推理。通过添加一系列用户定制的上下文推理规则,知识库推理机读取知识库中上下文知识与规则进行匹配,从而构建生成新的类间关系。比如下面就是一条描述某apt组织关联上新的c&c地址的新的关联关系生成规则:
[0120]
[rulecc:(?group:use?mal)(?mal:hasaction?action)(?action:connectto?ip)(?ip:type
‘
c&c’)->(?ip:belongsto?group)]
[0121]
该规则描述如果某一个组织使用过某个样本,该样本具有某一个特定动作,该特定动作包含connectto关连边,并且关连上c&c类型的ip,那么则建立一条belongsto的边将该ip和组织关联起来,可以通过一个摩柯草攻击组织c&c关连边生成。
[0122]
s103、将所述目标信息存储在知识库中,以使得基于所述知识库的调用接口在目标信息中获得对应的查询数据。
[0123]
经过上下文采集和上下文推理两个模块的处理,源自多源情报平台和实时网络威胁设备的告警日志被整合归并到按照apt本体结构的知识库当中。知识库统一了上下文表达的模型和形式,从而有助于解决上下文高效存储和查询的问题,并且统一的上下文形式也是进行上下文语义推理,以知识产生知识的基础。
[0124]
尽管知识库中已经基于apt威胁本体将apt相关的知识及知识之间的关联进行了
有效的保存,但是为了能够有效利用知识库中存储的知识及知识关系,上下文感知计算框架需要设计应用程序编程接口(api)以支撑按照需求导出多种格式的知识,并且一定程度上实现外部系统和计算框架的数据交互。
[0125]
本框架的api主要包含一系列的函数和接口,基于这些接口和函数可以对知识库进行操作。这些api需要封装能够基于rdql(rdf data query language)进行包括知识库中上下文信息的查询、添加、修改以及导出。
[0126]
本发明基于该本体结构本文设计了完整的apt上下文感知计算框架,该框架实现了对多源异构的实时和非实时的apt上下文信息的采集、甄选、存储和推理,将低层异构的上下文转变成为统一格式的高层上下文,从而使上下文的利用达到一个更高的水平。
[0127]
本发明实施例提供了一种基于高级持续性威胁攻击的信息处理系统,参见图5,所述系统包括:
[0128]
采集单元10,用于利用与数据源结构特征相匹配的信息采集方式,采集得到原始信息,所述原始信息包括原始的上下文信息;
[0129]
分析单元20,用于利用预构建的上下文模型对所述原始信息进行分析,得到目标信息,所述上下文模型用于对所述原始信息进行过滤、推断和融合处理,所述目标信息表征具有统一描述格式的高层上下文;
[0130]
存储单元30,用于将所述目标信息存储在知识库中,以使得基于所述知识库的调用接口在目标信息中获得对应的查询数据。
[0131]
可选地,所述采集单元包括:
[0132]
第一采集子单元,用于针对于非实时的半结构化的高级持续威胁攻击情报信息,利用预设的爬虫引擎进行信息采集,获得原始信息;
[0133]
第二采集子单元,用于针对大数据平台实时生成的数据,利用预设的大数据框架进行信息采集,获得原始信息。
[0134]
可选地,所述爬虫引擎包括引擎、调度器、下载器、爬虫单元、管道、下载中间件和爬虫中间件构成,所述第一采集子单元具体用于:
[0135]
通过所述引擎从所述调度器器读取用于进行信息抓取的链接;
[0136]
利用所述引擎将所述链接封装成请求,并将所述请求发送给所述下载器;
[0137]
通过所述下载器将与所述请求对应的资源进行下载,并生成应答包;
[0138]
通过爬取单元对所述应答包进行解析,得到实体信息,将所述实体信息发送给所述管道,使得所述管道对所述实体信息进行即系得到所述链接,将所述链接发送给调度器,使得所述调度器进行信息抓取,得到原始信息。
[0139]
可选地,所述第二采集子单元具体用于:
[0140]
通过所述预设的大数据框架的流式计算,对大数据平台实时生成的数据进行处理和规范,得到原始数据。
[0141]
可选地,所述系统还包括:
[0142]
创建单元,用于创建上下文模型,所述创建单元具体用于包括:
[0143]
构建高级持续性威胁攻击的威胁本体结构,所述威胁本体结构包括各个实体概念类的定义以及实体概念类之间关系的定义;
[0144]
对上下文语义存储格式进行统一,得到目标上下文语义;
[0145]
基于所述威胁本体结构,对所述目标上下文语义进行表示,得到上下文模型。
[0146]
可选地,所述分析单元包括:
[0147]
过滤子单元,用于对所述原始信息进行上下文过滤,得到过滤够的信息;
[0148]
抽取子单元,用于利用预构建的上下文模型得到实体和关系抽取规则,并利用所述规则在过滤后的信息中进行信息抽取,得到抽取后的信息;
[0149]
融合子单元,用于将抽取后的信息进行上下文语义融合,得到目标信息,其中,所述上下文语义融合包括实体链接的处理方式,所述实体链接为将上下文中提到的实体与知识库中对应的实体进行链接的处理方式。
[0150]
本发明提供了一种基于高级持续性威胁攻击的信息处理系统,采集单元利用与数据源结构特征相匹配的信息采集方式,采集得到原始信息,所述原始信息包括原始的上下文信息;分析单元利用预构建的上下文模型对所述原始信息进行分析,得到目标信息,所述上下文模型用于对所述原始信息进行过滤、推断和融合处理,所述目标信息表征具有统一描述格式的高层上下文;存储单元将所述目标信息存储在知识库中,以使得基于所述知识库的调用接口在目标信息中获得对应的查询数据。实现了能够有效获得高级持续性威胁攻击的相关信息,便于对信息的更有效地利用。
[0151]
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
[0152]
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1