一种基于矩阵分解的访问策略智能化生成方法与流程
[0001]
本发明涉及属性加密技术领域,尤其涉及一种基于矩阵分解的访问策略智能化生成方法。
背景技术:
[0002]
属性加密(attribute-based encryption,abe)机制是以属性为公钥,将密文和用户私钥与属性关联。密文-策略abe(cp-abe)是abe中常用的一类方案。在cp-abe中,访问权限能够灵活的用访问策略表示,能够实现细粒度的访问控制。故cp-abe在细粒度访问控制领域具有广阔的应用前景。
[0003]
现有的基于abe的细粒度的访问控制机制要求数据拥有者针对每个数据单元人工制定相应的访问策略。但是,在如云存储等海量数据存储系统中,为每个数据单元制定访问策略会花费极大的人工开销,不利于abe密文访问控制机制在大规模网络场景中的推广应用。
技术实现要素:
[0004]
本发明的目的在于提供一种基于矩阵分解的访问策略智能化生成方法,有利于abe密文访问控制机制在大规模网络场景中的推广应用。
[0005]
为实现上述目的,本发明提供了一种基于矩阵分解的访问策略智能化生成方法,包括以下步骤:
[0006]
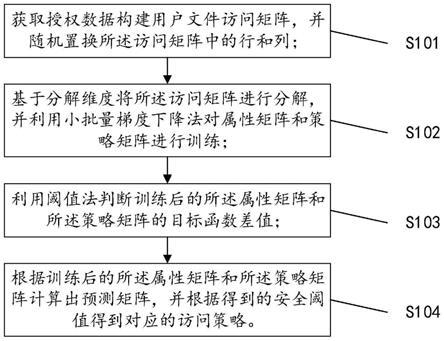
获取授权数据构建用户文件访问矩阵,并随机置换所述访问矩阵中的行和列;
[0007]
基于分解维度将所述访问矩阵进行分解,并利用小批量梯度下降法对属性矩阵和策略矩阵进行训练;
[0008]
利用阈值法判断训练后的所述属性矩阵和所述策略矩阵的目标函数差值;
[0009]
根据训练后的所述属性矩阵和所述策略矩阵计算出预测矩阵,并根据得到的安全阈值得到对应的访问策略。
[0010]
其中,获取授权数据构建用户文件访问矩阵,并随机置换所述访问矩阵中的行和列,包括:
[0011]
根据获取的授权数据构建用户文件访问矩阵,并设置对应的矩阵值,同时对所述访问矩阵中的列进行随机置换π后,再对置换后的矩阵中的行进行随机置换π。
[0012]
其中,基于分解维度将所述访问矩阵进行分解,并利用小批量梯度下降法对属性矩阵和策略矩阵进行训练,包括:
[0013]
基于分解维度,将行列置换后的所述访问矩阵随机分解为属性矩阵和策略矩阵,同时构建目标函数,并设置缺失值权重、正则项系数、学习率、梯度下降阈值和批量大小。
[0014]
其中,基于分解维度将所述访问矩阵进行分解,并利用小批量梯度下降法对属性矩阵和策略矩阵进行训练,还包括:
[0015]
利用小批量梯度下降法对所述属性矩阵进行训练,然后计算所述属性矩阵阈值,
并根据属性阈值将所述属性矩阵二值化。
[0016]
其中,利用阈值法判断训练后的所述属性矩阵和所述策略矩阵的目标函数差值,包括:
[0017]
计算出训练后的所述属性矩阵和所述策略矩阵的所述目标函数之差的绝对值,若所述绝对值大于设定的阈值,则继续训练所述属性矩阵和所述策略矩阵。
[0018]
其中,根据训练后的所述属性矩阵和所述策略矩阵计算出预测矩阵,并根据得到的安全阈值得到对应的访问策略,包括:
[0019]
根据训练后的所述属性矩阵和所述策略矩阵计算出对应的预测矩阵,并将所述预测矩阵任一列元素按降序排列后,计算对应列所有的潜在阈值。
[0020]
其中,根据训练后的所述属性矩阵和所述策略矩阵计算出预测矩阵,并根据得到的安全阈值得到对应的访问策略,还包括:
[0021]
利用所述潜在阈值将对应列所述元素二值化后,计算出对应的均方误差值和安全阈值,直至所述预测矩阵所有列完成计算。
[0022]
本发明的一种基于矩阵分解的访问策略智能化生成方法,通过已有的授权数据集构建用户-文件访问矩阵;随机置换访问矩阵的行和列;随机生成属性矩阵和策略矩阵;设置目标函数、缺失值权重、正则项系数、学习率、梯度下降阈值和批量大小;利用小批量梯度下降法训练属性矩阵,计算属性矩阵阈值并将其二值化,利用小批量梯度下降法训练策略矩阵,计算前后两次训练后目标函数之差的绝对值,若绝对值大于给定阈值则继续训练属性矩阵、计算属性矩阵阈值和训练策略矩阵,否则停止训练;根据属性矩阵和策略矩阵计算预测矩阵;为预测矩阵的每一个文件向量计算一个阈值,该阈值即为安全阈值;最后根据策略矩阵和安全阈值制定相应的访问策略。本发明通过对已有授权数据集的学习,构建智能化的访问策略生成方法,大大减少了制定访问策略所需的人工开销,有利于abe密文访问控制机制在大规模网络场景中的推广应用。
附图说明
[0023]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0024]
图1是本发明提供的一种基于矩阵分解的访问策略智能化生成方法的步骤示意图。
[0025]
图2是本发明提供的基于矩阵分解的访问策略智能化生成方法的流程示意图。
[0026]
图3是本发明提供的用户-文件矩阵举例图。
[0027]
图4是本发明提供的将用户-文件访问矩阵分解成属性矩阵和策略矩阵的示意图。
[0028]
图5是本发明提供的训练属性矩阵的流程图。
[0029]
图6是本发明提供的计算属性矩阵阈值的流程图。
[0030]
图7是本发明提供的训练策略矩阵的流程图。
[0031]
图8是本发明提供的计算安全阈值的流程图。
[0032]
图9是本发明提供的根据策略向量和安全阈值生成访问树示例图。
[0033]
图10是本发明提供的查全率随学习率变化的折线图。
[0034]
图11是本发明提供的查全率随分解维度变化的折线图。
[0035]
图12是本发明提供的查全率随批量大小变化的折线图。
[0036]
图13是本发明提供的查全率随正则项系数变化的折线图。
[0037]
图14是本发明提供的训练时间随分解维度变化的折线图。
[0038]
图15是本发明提供的均方误差随训练样本占比变化的折线图。
具体实施方式
[0039]
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。
[0040]
在本发明的描述中,“多个”的含义是两个或两个以上,除非另有明确具体的限定。
[0041]
请参阅图1和图2,本发明提供一种基于矩阵分解的访问策略智能化生成方法,包括以下步骤:
[0042]
s101、获取授权数据构建用户文件访问矩阵,并随机置换所述访问矩阵中的行和列。
[0043]
具体的,如图3所示,根据授权数据集构建用户-文件访问矩阵r=(r
ui
)
m
×
n
,矩阵r的行表示用户,列表示文件。然后设置对应的矩阵值:用户成功访问某个文件则将矩阵对应位置为1;用户不能访问则置为0;没有访问记录则置为null。
[0044]
随机置换访问矩阵r的行和列。
[0045]
1.1对1,
…
,n进行随机置换π(1,2,..,n)=(x1,x2,...,x
n
)。
[0046]
1.2令r
′
=(r
x1
,r
x2
,...,r
xn
),其中r
xi
(1≤i≤n)为矩阵r的第x
i
列。
[0047]
1.3对1,
…
,m进行随机置换π(1,2,..,m)=(y1,y2...,y
m
)。
[0048]
1.4令
[0049][0050]
其中,r
′
yi
(1≤i≤m)为矩阵r
′
的第y
i
行。
[0051]
1.5令r=r
″
[0052]
s102、基于分解维度将所述访问矩阵进行分解,并利用小批量梯度下降法对属性矩阵和策略矩阵进行训练。
[0053]
具体的,如图4所示,确定矩阵分解所需要的维度f,并随机生成属性矩阵p=(p
uj
)
m
×
f
(0≤p
uj
≤1)和策略矩阵q=(q
ji
)
f
×
n
(0≤q
ji
≤1)。属性矩阵p的行表示用户,列表示属性;策略矩阵q的行表示属性,列表示文件。
[0054]
设置目标函数:
[0055][0056]
其中,w
ui
为r
ui
的权重,λ为正则项系数,r
ui
为访问矩阵r的第u行第i列元素,p
uj
为属性矩阵p的第u行第j列元素,q
ji
为策略矩阵q的第j行第i列元素,f表示分解维度。
[0057]
设置正则项系数λ,学习率γ,梯度下降阈值θ,批量大小b,缺失值权重w
ui
,若r
″
ui
=1或r
″
ui
=0则令w
ui
=1,否则设置一个较小的权重值。
[0058]
对访问矩阵的行和列分组:
[0059]
set
l
={i|i=l
′
modn,(l-1)b+1≤l
′
≤lb}
[0060]
set
′
l
={i|i=l
′
modm,(l-1)b+1≤l
′
≤lb}
[0061]
其中,set
l
为行分组,set
′
l
为列分组,l为迭代次数,b为批量大小,m和n分别为访问矩阵的行数和列数。
[0062]
令l=1。
[0063]
如图5所示,输入属性矩阵、策略矩阵、访问矩阵、权重w
ui
,学习率、正则项系数和行分组,并初始化k=1,u=1。
[0064]
训练属性矩阵p:
[0065][0066]
其中,γ为学习率,w
ui
为r
ui
的权重,λ为正则项系数,r
ui
为访问矩阵r的第u行第i列元素,p
uk
为属性矩阵p的第u行第k列元素,q
ki
为策略矩阵q的第k行第i列元素,f表示分解维度。
[0067]
若k<f,则令k=k+1,并继续训练属性矩阵p,否则进入下一步。
[0068]
若u<m,则u=u+1,k=k+1,并继续训练属性矩阵p,否则进入下一步。
[0069]
输出属性矩阵p。
[0070]
如图6所示,训练属性矩阵阈值v=(v1,v2,...,v
f
),其中,v
i
(1≤i≤f)表示属性矩阵p第i列的属性阈值。
[0071]
令k=1。
[0072]
将属性矩阵p的第k列p
k
从大到小排列得到a
k
=(a
k1
,a
k2
,...,a
km
)。
[0073]
计算p
k
所有潜在阈值v
kt
:
[0074][0075]
根据不同的v
kt
(1≤t≤m-1)将p
k
二值化得到
[0076][0077]
其中,
[0078][0079]
计算目标函数值:
[0080][0081]
1≤t≤m-1
[0082]
其中,v
kt
表示p
k
的第t个潜在阈值,w
ui
为r
ui
的权重,λ为正则项系数,r
ui
为访问矩阵r的第u行第i列元素,p
uj
为属性矩阵p的第u行第j列元素,q
ji
为策略矩阵q的第j行第i列元素,表示p
k(t)
的第u个元素,f表示分解维度。
[0083]
选取阈值使得
[0084]
若k<f,则令k=k+1,并将属性矩阵p的第k+1列p
k+1
从大到小排列;否则进入下一步。
[0085]
根据阈值v=(v1,v2,...,v
f
),对属性矩阵p的进行二值化得p
′
=(p
′
uj
)
m
×
f
。
[0086][0087]
令p=p
′
[0088]
如图7所示,输入属性矩阵、策略矩阵、访问矩阵、权重w
ui
,学习率、正则项系数和批量分组,并初始化k=1,i=1。
[0089]
训练策略矩阵q:
[0090][0091]
其中,γ为学习率,w
ui
为r
ui
的权重,λ为正则项系数,r
ui
为访问矩阵r的第u行第i列元素,p
uk
为属性矩阵p的第u行第k列元素,q
ki
为策略矩阵q的第k行第i列元素,f表示分解维度。
[0092]
若k<f,则令k=k+1,并继续训练策略矩阵q,否则进入下一步。
[0093]
若i<n,则i=i+1,k=k+1,并继续训练策略矩阵q,否则进入下一步。
[0094]
输出矩阵q。
[0095]
s103、利用阈值法判断训练后的所述属性矩阵和所述策略矩阵的目标函数差值。
[0096]
具体的,计算目标函数值l2。若l=1,则令l1=l2,继续训练属性矩阵p;否则进入下一步。
[0097][0098]
其中,w
ui
为r
ui
的权重,λ为正则项系数,r
ui
为访问矩阵r的第u行第i列元素,p
uj
为属性矩阵p的第u行第j列元素,q
ji
为策略矩阵q的第j行第i列元素,f表示分解维度。
[0099]
计算训练后的所述属性矩阵和所述策略矩阵的所述目标函数之差的绝对值,若所
述绝对值大于设定的阈值,则继续训练所述属性矩阵和所述策略矩阵;即计算|l
1-l2|,若|l
1-l2|>θ,则继续训练属性矩阵p,否则停止训练。
[0100]
s104、根据训练后的所述属性矩阵和所述策略矩阵计算出预测矩阵,并根据得到的安全阈值得到对应的访问策略。
[0101]
具体的,根据属性矩阵p和策略矩阵q计算预测矩阵
[0102][0103]
其中,为预测矩阵的第u行第i列元素,r
ui
为访问矩阵r的第u行第i列元素,p
uj
为属性矩阵p的第u行第j列元素,q
ji
为策略矩阵q的第j行第i列元素,f表示分解维度。
[0104]
如图8所示,计算安全参数s=(s1,s2,...,s
n
),其中,s1(1≤i≤n)表示预测矩阵第i列的阈值,即文件i的安全阈值。
[0105]
令k=1。
[0106]
将矩阵的第k列从大到小排列得到a
k
=(a
k1
,a
k2
,...,a
km
)。
[0107]
计算所有潜在阈值s
kt
:
[0108][0109]
根据不同的s
kt
(1≤t≤m-1)将二值化得到
[0110][0111]
计算均方误差值:
[0112][0113]
其中,s
kt
表示的第t个潜在阈值,w
ui
为r
ui
的权重,r
ui
为访问矩阵r的第u行第i列元素,表示的第u个元素。
[0114]
选取安全阈值使得
[0115]
若k<n,则令k=k+1,则将矩阵的第k+1列从大到小排列;否则进入下一步。
[0116]
根据策略矩阵q和安全阈值s=(s1,s2,...,s
n
)制定访问策略。根据文件的策略向量和安全阈值生成授权访问集合,进一步可生成访问树。如用户u的属性向量为p
u
,文件i的策略向量和安全阈值分别为q
i
和s
i
,若p
u
q
i
>s
i
,则用户u可以访问文件i,否则不可访问。
[0117]
根据文件的属性向量和安全阈值可以生成文件的授权属性集和访问树,如图9所示,假设系统有a、b、c三个属性,属性向量p1=(0,1,0)表示用户1的属性集为{b}。根据文件1的策略向量q1=(0.3,0.7,0.5),安全阈值s1=0.5,可得到文件1的所有授权访问集合为
{{b},{a,c},{a,b},{b,c},{a,b,c}},进一步可生成访问树。
[0118]
如图10所示,横坐标为学习率,纵坐标为查全率。当学习率0.007≤γ≤0.009时,三个数据集的查全率都超过90%。当学习率为0.007时数据集2的查全率能达到最大值为96.5%。
[0119]
如图11所示,横坐标为矩阵分解维度,纵坐标为查全率。当分解维度为3时三个数据集的查全率都超过90%,且数据集1的查全率能达到最大值为95.8%。
[0120]
如图12所示,横坐标为批量大小,纵坐标为查全率。当批量大小5≤b≤25时,三个数据集的查全率都能超过90%。当批量大小为10时数据集1的查全率能达到最大值为97.3%。
[0121]
如图13所示,横坐标为正则项系数,纵坐标为查全率。当正则项系0.01≤γ≤0.02时,三个数据集的查全率都在90%以上。当正则项系数为0.01时数据集3能达到最大值为96.8%。
[0122]
如图14所示,横坐标为分解维度,纵坐标为训练时间。由图可知训练时间随分解维度增加而增加。
[0123]
如图15所示,横坐标为训练样本在数据集中所占比例,纵坐标为均方误差。由图可知训练样本在数据集中所占比例增大时均方误差减小。当训练样本在数据集中的占比为95%时数据集1的均方误差达到最小值0.017。
[0124]
本发明的一种基于矩阵分解的访问策略智能化生成方法,通过已有的授权数据集构建用户-文件访问矩阵;随机置换访问矩阵的行和列;随机生成属性矩阵和策略矩阵;设置目标函数、缺失值权重、正则项系数、学习率、梯度下降阈值和批量大小;利用小批量梯度下降法训练属性矩阵,计算属性矩阵阈值并将其二值化,利用小批量梯度下降法训练策略矩阵,计算前后两次训练后目标函数之差的绝对值,若绝对值大于给定阈值则继续训练属性矩阵、计算属性矩阵阈值和训练策略矩阵,否则停止训练;根据属性矩阵和策略矩阵计算预测矩阵;为预测矩阵的每一个文件向量计算一个阈值,该阈值即为安全阈值;最后根据策略矩阵和安全阈值制定相应的访问策略。本发明通过对已有授权数据集的学习,构建智能化的访问策略生成方法,大大减少了制定访问策略所需的人工开销,有利于abe密文访问控制机制在大规模网络场景中的推广应用。
[0125]
以上所揭露的仅为本发明一种较佳实施例而已,当然不能以此来限定本发明之权利范围,本领域普通技术人员可以理解实现上述实施例的全部或部分流程,并依本发明权利要求所作的等同变化,仍属于发明所涵盖的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1