一种基于深度学习的变电站人员检测方法及装置与流程
本发明属于电力工程技术领域,具体涉及变电站安全监控技术。
背景技术:
近些年,变电站的自动化系统正随着电力信息技术、人工智能技术、深度学习算法的快速发展而得到普遍应用。当前该系统的值守模式是将变电站的各类实时数据传送到调度中心,减少了人为因素的影响,但对变电站是否发生非法人员入侵、操作行为是否违规等现象仍需要人为分析监控视频进行判断。这种依赖工作人员昼夜査看视频的值守模式需要消耗大量的人力,且变电站24小时不停运转,必定会产生海量的视频数据,在需查阅或统计某些信息时,不能依赖人力来完成任务。可见,对现有的变电站无人值守模式进行改造,实现更加智能化的管理模式己经成为变电站运行管理发展的必然趋势。
技术实现要素:
针对现有采用人工值守进行监控的局限性,本发明所要解决的技术问题就是提供一种基于深度学习的变电站人员检测方法,减少了人力劳动,提高了变电站的检测效率。
为解决上述技术问题,本发明采用如下技术方案:一种基于深度学习的变电站人员检测方法,包括训练基于深度学习的变电站人员轨迹及行为检测模型,以及应用基于深度学习的变电站人员轨迹及行为检测模型进行变电站人员检测的步骤;
其中,模型训练包括如下步骤:
s11,采集变电站内相关人员的图像数据,获得大样本数据集;
s12,对采集的图像数据进行预处理,采用mosaic和自对抗训练方法对图像数据进行增强,在进行核验后,作为训练数据集;
s13,采用cspdarknet53为基础网络,提取特征,接着对特征提取器进行训练训练,获得基于深度学习的变电站人员轨迹及行为检测模型;
模型应用包括如下步骤:
步骤s21:实时获取摄像机所拍摄的视频数据,对视频进行抽帧处理,提取视频数据中的实时图像数据;
步骤s22:利用基于深度学习的变电站人员轨迹及行为检测模型对提取到的关键帧图片进行检测;
步骤s23:根据检测结果判断变电站内的人员身份及操作行为有无异常。
优选的,步骤s11中,首先在变电站场所下,利用摄像机从不同角度对现场进行拍摄,获取图像样例数据;然后对收集到的图像数据进行标注,本模型的识别类型设置为人、安全帽、工作服和工作证4个物体类别;最后将制作好的图像保存为模型训练所需的图像数据集;接下来利用python脚本文件将数据集拆分成训练集和测试集,并生成对应的train.txt和test.txt文件,其中分别存放训练图片和测试图片的图片路径及名称。
优选的,cspdarknet53中的csp模块将基础层的特征映射划分为两个部分,然后通过跨阶段层次结构将两个部分合并;将spp模型加入了cspdarknet53中增大多尺度的感受野;cspdarknet53中使用panet作为不同层的参数聚合。
优选的,步骤s21中间隔10s对视频样本进行一次抽帧处理,利用opencv算法库从视频裸流中提取关键帧,获得视频数据中的实时图像数据。
优选的,步骤s23中,通过是否戴有工作证和穿戴工作服判断变电站内的人员身份,是否是外来人员;根据有无正确佩戴头盔,判断变电站内的人员是否违规操作;并且对外来人员以及违规操作的行为发出报警信息。
本发明还提供了一种基于深度学习的变电站人员检测装置,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述法的步骤。
深度学习以人工神经网络为架构,模拟人脑进行分析学习,实现对图像、声音、文本等数据的自主学习。本发明提出的基于深度学习的变电站人员检测模型yolo-se,不再依赖人工专家进行特征的选择,能够高效、准确的完成对安全服、安全帽、工作证等物体的识别,这种能力非常契合当前变电站无人值守模式的要求。将该算法集成到嵌入式硬件设备中,借助于识别结果,可以实现对非法入侵、没有佩戴安全帽等物品、没有在规定的时间、地点内进行操作等问题进行分析和警报。相较于传统的人工设计的模型,智能监控分析可以更加及时的发现可疑人员、监控工作人员的操作并防范风险,减轻了基层人员的设备维护保养工作负荷,节省了人力成本,提高了变电站的效率,并保障了变电站的安全。
本发明的具体技术方案及其有益效果将会在下面的具体实施方式中进行详细的说明。
附图说明
下面结合附图和具体实施方式对本发明作进一步描述:
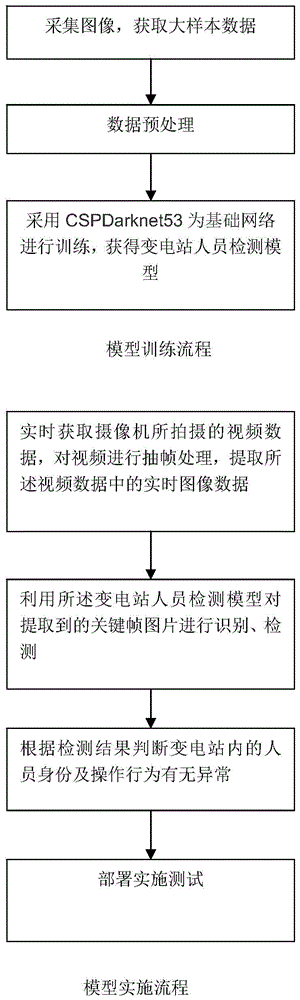
图1为本发明的整体流程框图;
图2为本发明的模型框架图;
图3为cspdarknet53中的残差块结构图。
具体实施方式
下面将结合本发明实施例对本发明技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。以下对至少一个示例性实施例的描述实际上仅仅是说明性的,决不作为对本发明及其应用或使用的任何限制。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示,一种基于深度学习的变电站人员检测方法,包括训练基于深度学习的变电站人员轨迹及行为检测模型,以及应用基于深度学习的变电站人员轨迹及行为检测模型进行变电站人员检测的步骤;
其中,模型训练包括如下步骤:
s11,采集变电站内相关人员的图像数据,获得大样本数据集;
s12,对采集的图像数据进行预处理,采用mosaic和自对抗训练方法对图像数据进行增强,在进行核验后,作为训练数据集;
s13,采用cspdarknet53为基础网络,提取特征,接着对特征提取器进行训练训练,获得基于深度学习的变电站人员轨迹及行为检测模型;
模型应用包括如下步骤:
步骤s21:实时获取摄像机所拍摄的视频数据,对视频进行抽帧处理,提取视频数据中的实时图像数据;
步骤s22:利用基于深度学习的变电站人员轨迹及行为检测模型对提取到的关键帧图片进行检测;
步骤s23:根据检测结果判断变电站内的人员身份及操作行为有无异常。
具体步骤如下:
(一)模型训练流程
步骤1,采集数据,获取数据集,具体为:
在变电站场所下,工作人员利用摄像机从不同角度对现场进行拍摄,获取大量图像样例数据,然后对收集到的图像数据进行标注,本模型的识别类型设置为people(人)、helmat(安全帽)、suit(工作服)、card(工作证)等4个物体类别,最后将制作好的图像保存为模型训练所需的图像数据集。接下来利用python脚本文件将数据集拆分成训练集和测试集,并生成对应的train.txt和test.txt文件,里面分别存放训练图片和测试图片的图片路径及名称。
步骤2,数据预处理,具体为:
为了提高模型检测精度,降低图像受到的某种程度的破坏和各种噪声污染的影响,需要对步骤1采集到的图像数据进行预处理。因为无论是在视频样本中采样的过程还是极端恶劣天气造成的视频图像不清晰等,都将对图像数据集造成影响,导致图片丧失了本质或者偏高了人们的需求,这就需要一系列的预处理操作来消除图像受到的影响。本发明提出的yolo-se模型采用新型的mosaic和自对抗训练(sat,self-adversarialtraining)方法进行数据增强,mosaic方法是融合四张训练图像,也就是把四张具有不同语义信息的图片拼接为一张图片,这样就可以让检测器检测出超出常规语境的目标,增强模型的鲁棒性。具体操作是每次读取四张图片,然后分别对这四张图片进行翻转、缩放、色域变化等操作,并且按照四个方向位置摆好,最后进行图片的组合和boundingbox的组合。除此之外,在bn(batchnormalization)层计算每一层激活数据的时候是包含这四幅不同的图像,这就极大的减小了估计均值和方差时对大mini-batch的要求,模型在单个gpu上训练就变得更加轻松。
自对抗训练(sat,self-adversarialtraining)方法,可以在一定程度上抵抗对抗攻击,作用于两个前向、反向传播阶段。第一阶段,cnn通过反向传播改变原始图像信息而非网络模型的权重,通过这种方式,改变了原始图像,创建了一个针对当前模型的对抗性攻击,造成图像上没有目标的假象;第二阶段,cnn使用这个带有原始bbox和类标签的新图像对模型进行训练,有助于减少过拟合。
步骤3,采用cspdarknet53为基础网络,提取特征,接着对所述特征提取器进行训练,获得变电站人员检测模型,具体为:
本发明是在yolov3的模型结构基础上,将原先的darknet53换成了感受野、参数量和速度都比较好的cspdarknet53(crossstagepartialdarknet53)作为主干特征提取网络,并且添加了sppblock(spatialpyramidpooling,空间金字塔池化)结构,增加了多尺度的感受野,但也不会降低运行速度,另外还将fpn替换成了panet作为不同层的参数整合方法。模型的主要框架图如图2所示。
cspdarknet53包含29个卷积层,725*725的感受野,27.6m参数,在该网络中存在一系列改进的残差网络resblock_body模块结构。darknet53中的残差卷积就是进行一次3x3、步长为2的卷积,然后保存该卷积layer,再进行一次1x1的卷积和一次3x3的卷积,并把这个结果加上layer作为最后的结果,残差网络的特点是容易优化,并且能够通过增加相当的深度来提高准确率。而cspdarknet53是将resblock_body的结构进行了修改,使用了cspnet结构,这个结构就是将原来的残差块的堆叠进行了一个拆分,拆成左右两部分:主干部分继续进行原来的残差块的堆叠,但去除了bottleneck层;另一部分则像一个残差边一样,经过少量处理直接连接到最后,如图3所示。cspdarknet53的每一个卷积部分使用了特有的darknetconv2d结构,每一次卷积的时候进行l2正则化,完成卷积后进行batchnormalization标准化与mish激活函数。图2中的cbm指的就是这个过程,conv2d+bn+mish。
其中,mish函数的公式如下:
mish=x×tanh(ln(1+ex))
整个过程可以描述为:输入一张图像,首先将图像输入darknet特有的二维卷积层darknetconv2d中,在这一层中进行l2正则化(bn)操作,并且激活函数采用mish函数,此时特征尺寸变小,通道数(filter)也会随着num_filter的改变而改变。接下来将新产生的特征图输入五大残差块单元中,每个大残差块所包含的小残差单元个数为1、2、8、8、4,在每个残差块中进行双卷积(1*1和3*3)操作,每组均含有一次步长为2的卷积操作,因此一共降维5次32倍,即32=2^5,则输出的特征图维度就等于输入图像尺寸/32。本发明提出的yolo-se模型提取多特征层进行目标检测,一共提取三个特征层,分别位于主干网络cspdarknet的中层、中下层和底层。三个特征层一部分通过五次卷积操作和多个矩阵的拼接操作,用于输出该特征层对应的预测结果;一部分先进入spp网络进行池化操作,然后再通过卷积操作和矩阵的拼接操作后,进行反卷积和upsampling与其它特征层进行结合,输出预测结果。
为了增大感受野,分离出最显著的上下文特征,yolo-se模型使用spp和panet(pathaggregationnet,路径聚合网络)作为特征金字塔的结构。spp结构掺杂在对cspdarknet53的最后一个特征层的卷积里,在对cspdarknet53的最后一个特征层进行三次卷积操作后,分别利用三个不同尺度的最大池化进行处理,最大池化的池化核大小分别为13x13、9x9、5x5,完成池化后,将池化后的layer进行卷积和concat操作,拼接成一个特征图layer并通过1*1卷积降维到512个通道。panet结构的一大重要特点就是特征的反复提取,特征层进入panet后,既有像原先fpn一样的自上向下的特征路径,又增加了一条自下而上的下采样增强路径,这样每个特征层通过自适应特征池化与其它特征层做融合操作后,用于后续预测。
在预测过程中采用的是head结构,这个结构利用上一步获取的特征进行预测,获得我们需要的变电站人员检测模型。经过上述过程提取到3个不同shape的特征层,而提出的模型yolo-se针对每一个特征层存在3个先验框,所以,获得的三个特征层分别对应每个图上不同尺寸的网格上3个预测框的位置。
(二)模型实施流程
步骤1,实时获取视频数据,对视频进行抽帧处理,提取所述视频数据中的实时图像数据,具体为:
工作人员利用球机从不同角度对现场进行拍摄,实时获取摄像机所拍摄的视频数据样本,根据视频样本的时间长度决定采样时间,为使训练出的模型精确度更高,需要采集尽可能多的样本。本发明选取的是间隔10s对视频样本进行一次抽帧处理,利用的是opencv算法库,从视频裸流中提取关键帧,获得所述视频数据中的实时图像数据。
步骤2,利用所述训练好的变电站人员检测模型对提取到的关键帧图片进行识别、检测。
步骤3,根据检测结果判断变电站内的人员身份及操作行为有无异常,具体为:
根据模型的检测结果,通过是否戴有工作证和穿戴工作服判断变电站内的人员身份,是否是外来人员;根据有无正确佩戴头盔,判断变电站内的人员是否违规操作,对外来人员以及违规操作的行为发出报警信息。
步骤4,部署实施测试,具体为:将训练好的模型集成到一些基于深度学习的硬件设备上,如移动计算板卡等,并配置好相关的环境,部署完成后,对其进行实地测试。
本发明还提供了一种基于深度学习的变电站人员检测装置,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述法的步骤。
综上,本发明采用上述技术方案,具有如下有益效果:
(1)本发明创造性的将基于深度学习的目标检测模型应用到了变电站场景下的人员检测中,同时将该模型集成到移动板卡中,实现了边缘计算的应用,系统可以实现实时检测和发出报警信息,极大的减少了人力劳动,提高了变电站的检测效率。
(2)本发明采用了全新的数据增强方法--mosaic和自对抗训练(sat)方法,mosaic方法同时融合四张具有不同语义信息的图片,让检测器检测出超出常规语境的目标,增强了模型的鲁棒性,减少了对mini-batch的依赖。sat是进行两个阶段的前向和后向传播,可以在一定程度上抵抗对抗攻击。使用这两种方法对数据进行处理,可以使模型更加适合在单张gpu上训练。
(3)本发明的网络模型是一种全新的yolo-se模型,该模型将cspdarknet53作为模型的主干网络,csp模块是将基础层的特征映射划分为两个部分,然后通过跨阶段层次结构将它们合并,这样在减小了计算量的同时,保证了准确率,降低了内存成本。同时,本模型将spp模型加入了cspdarknet53中,增大了多尺度的感受野而且没有降低运行速度,本模型还使用panet替代fpn作为不同层的参数聚合的方法,增强了低层和高层的语义信息,有效避免了有用特征信息的丢失。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,熟悉该本领域的技术人员应该明白本发明包括但不限于上面具体实施方式中描述的内容。任何不偏离本发明的功能和结构原理的修改都将包括在权利要求书的范围中。
- 还没有人留言评论。精彩留言会获得点赞!