面向警情笔录数据的实体关系联合抽取方法与流程
本发明涉及自然语言处理和深度学习领域,尤其涉及一种面向警情笔录数据的实体关系联合抽取方法。
背景技术:
面向警情笔录数据的实体关系抽取(relationextraction)是警情笔录信息抽取技术的重要环节,是警情笔录信息抽取领域重要的基础任务和难点问题之一。其任务是从非结构化文本中识别出一对实体以及这对实体具有的语义关系,并构成关系三元组。从理论价值层面看,实体关系抽取涉及到机器学习、语言学、数据挖掘等多个学科的理论和方法。从应用层面看,实体关系抽取可用于大规模知识库的自动构建。实体关系抽取还能为信息检索和自动问答系统的构建提供数据支持。近年来,研究人员已经在关系抽取方面做出了诸多工作,尤其是基于神经网络的有监督的关系抽取方法。
目前进行面向警情笔录数据的实体关系抽取的方法主要是基于流水线的抽取方法,即把实体和关系的抽取分为两个子任务:先采用命名实体识别模型抽取出所有实体,再采用关系分类器得到实体对之间的关系。然而,流水线方法存在着以下几个缺点:
1、误差累计,实体识别模块的错误会影响到接下来的关系分类性能;
2、忽视了两个子任务之间存在的关系,丢失相互信息,影响抽取效果;
3、产生冗余信息,由于对识别出来的实体进行两两配对,然后再进行关系分类,那些没有关系的实体对就会带来多余信息,提升错误率。
相比于流水线方法,联合学习方法能够利用警情笔录数据中实体和关系间紧密的交互信息,同时抽取实体并分类实体对的关系,很好地解决了流水线方法所存在的问题。然而,目前存在的联合抽取方法虽然消除了流水线方法中两个子任务相互独立的问题,但现有的方法大都孤立的预测每一个关系而未考虑关系标签相互之间的丰富语义关联。
技术实现要素:
针对目前警情笔录领域下实体关系抽取方法存在误差传导、不能充分利用各子任务之间的交互信息和未考虑关系标签之间语义关联的问题,本发明提出了一种面向警情笔录数据的实体关系联合抽取方法。该方法不仅能解决目前警情笔录关系抽取中误差传导、不能充分利用各子任务之间的交互信息问题,而且还能利用警情笔录数据中关系标签的重要依赖知识。实际应用中本发明显著提高了警情笔录关系抽取的性能。
为实现上述技术目的,本发明采用的具体技术方案如下:
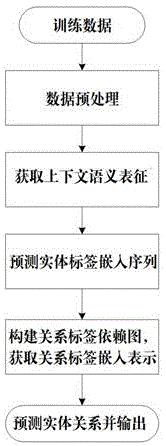
面向警情笔录数据的实体关系联合抽取方法,包括:
s1.收集大量警情笔录数据作为训练数据,预定义m个实体标签以及q个关系标签,针对收集的警情笔录数据以句子为单位,对各句子中存在的实体标签和关系标签进行人工标注,以及获得训练数据中关系标签的先验共现信息。
s2.对警情笔录数据中的每个句子进行上下文编码得到每个句子的上下文语义表征。
s3.对警情笔录数据中的每个句子的上下文语义表征进行命名实体识别。
s4.根据训练数据的先验共现信息构建标签依赖图的邻接矩阵,使用多层图卷积网络进行关系标签依赖编码后,得到一组相互依赖的关系标签嵌入表示。
s5.对于待预测的警情笔录数据的每个句子,综合其上下文语义表征和命名实体识别结果以及s4中得到的关系标签嵌入表示,预测每个句子中所有的实体关系。
本发明的s2中将警情笔录数据中的任意句子用x={x1,x2,…xn}表示,其中x1,x2,…xn表示句子中的字符,n是句子的长度;将每个句子对应的
本发明的s1中预定义的m个实体标签为
本发明的s4中针对收集的警情笔录数据,使用一个邻接矩阵
对于预定义的q种关系标签,将每个关系标签映射为一个待更新的p维向量,得到一组关系标签节点嵌入
本发明的s5中对于待预测的警情笔录数据的每个句子,获取其语义向量序列和实体标签嵌入序列并进行拼接,得到目标向量集合,综合目标向量集合中的任意两个目标向量,与s4中得到的关系标签嵌入表示中每一种可能的关系标签进行关系预测,得到对应的预测实体关系。
与现有技术相比,本发明具有以下优点:
1、采用预训练语言模型bert,bert能对不同层次信息之间的复杂交互进行建模,学习深层语境化的词汇表征。
2、实体关系联合抽取,联合学习能够利用警情笔录数据中实体和关系间紧密的交互信息,并解决流水线方法的弊端。
3、与现有方法相比,不再孤立的预测每一个关系并利用图卷积网络学习关系标签相互之间的丰富语义关联信息。
附图说明
图1为本发明的流程图。
图2为本发明的系统框图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚明白,下面将以附图及详细叙述清楚说明本发明所揭示内容的精神,任何所属技术领域技术人员在了解本发明内容的实施例后,当可由本发明内容所教示的技术,加以改变及修饰,其并不脱离本发明内容的精神与范围。本发明的示意性实施例及其说明用于解释本发明,但并不作为对本发明的限定。
参照图1和图2,本实施例提供一种面向警情笔录数据的实体关系联合抽取方法,包括:
s1.收集大量警情笔录数据作为训练数据。每条警情笔录数据都由专业人员进行实体标签和关系标签的标注。具体地,预定义m个实体标签
与某市公安系统合作,收集了真实案件受理过程中产生的警情文本作为训练数据。由专家组紧密贴合业务,设计出科学合理的标签体系。在本方案具体实施中,根据办案需求和警情数据特点,共设计和预定义了m种实体标签
s2.对警情笔录数据中的每个句子进行上下文编码得到每个句子的上下文语义表征。
将警情笔录数据中的每个句子分别用x={x1,x2,…xn}表示,其中x1,x2,…xn表示句子中的字符,n是句子的长度。
将每个句子对应的x分别输入到
将每个句子对应的预处理后的数据w={w1,w2,…wk}输入至预训练语言模型bert,通过预训练语言模型bert将划分出的每个词单元映射为对应的上下文语义表征
s3.对警情笔录数据中的每个句子的上下文语义表征进行命名实体识别,得到对应的预测实体标签序列。
将命名实体识别任务描述为一个序列标注问题,使用bio(开始、内部、外部)编码方案对句子进行序列标注。即为句子中的每个标记分配一个bio中的某一种标签。由于实体由句子中的多个连续标记组成,这种做法可以识别实体的起始位置和结束位置及其类型(例如机构)。具体来说,就是将b-type(开始)分配给实体的第一个标记,将i-type(内部)分配给实体内的每个其他标记,如果标记不是实体的一部分,则分配o标签(外部)。比如输入文本为“市公安局干警张三”,目标是预测“b-机构i-机构i-机构i-机构oob-人物i-人物”的实体标签序列。
本实施例中将警情笔录数据中的每个句子的上下文语义表征通过线性crf(条件随机场)计算进行命名实体识别,得到对应的预测实体标签序列。
具体地,对于警情笔录数据中的每个句子的上下文语义表征
其中,
经公式运算后得到一个向量
由于bio标注编码方案存在着若干限制,如“b-机构”后面不能跟“i-人物”,“o”后面不能跟“i-type”等。本发明根据实体标签得分来计算线性crf得分,通过学习得到的标签转移概率考虑实体边界。给定一组实体标签序列
其中,
通过
其中,
最后,将预测实体标签序列向量化映射为对应的实体标签嵌入序列
s4.根据训练数据的先验共现信息构建标签依赖图的邻接矩阵,使用多层图卷积网络进行关系标签依赖图编码后,得到一组相互依赖的关系标签嵌入表示。
针对收集的警情笔录数据,使用一个邻接矩阵
构建了关系标签依赖图的邻接矩阵后,使用图卷积网络来建立关系标签依赖的模型。对于预定义的q种关系标签,首先将每个关系标签映射为一个待更新的p维向量,得到一组关系标签节点嵌入
其中
本实施例使用一个三层图卷积网络来学习多个关系标签节点嵌入之间的相关性:
通过多层图卷积网络学习多个关系标签节点嵌入之间的相关性,完成关系标签依赖编码后,得到最终的一组相互依赖的关系标签嵌入表示
s5.对于待预测的警情笔录数据的每个句子,综合其上下文语义表征和命名实体识别结果以及s4中得到的关系标签嵌入表示,预测每个句子中所有的实体关系。
对于待预测的警情笔录数据的每个句子,获取其语义向量序列
每次给定两个词单元的目标向量和一种关系标签嵌入表示,则计算词单元
其中,
在三维表填充过程中,评估词单元
通过本发明不仅能解决目前警情笔录事件抽取中误差传导、不能充分利用各子任务之间的交互信息的问题,而且还能利用警情笔录数据中关系标签的重要依赖知识。总体来说,本发明通过提高了警情笔录实体关系抽取的
综上所述,虽然本发明已以较佳实施例揭露如上,然其并非用以限定本发明,任何本领域普通技术人员,在不脱离本发明的精神和范围内,当可作各种更动与润饰,因此本发明的保护范围当视权利要求书界定的范围为准。
- 还没有人留言评论。精彩留言会获得点赞!