基于生成式对抗网络的人脸素描图像转换为RGB图像方法与流程
基于生成式对抗网络的人脸素描图像转换为rgb图像方法
技术领域
[0001]
本发明涉及深度学习技术领域,具体为基于生成式对抗网络的人脸素描图像转换为rgb图像的方法。
背景技术:
[0002]
随机深度学习的迅速发展,计算机图形学和计算机视觉已经成为人工智能领域最重要的技术之一。基于生成式对抗网络的图像转换是计算机视觉领域的一个新的研究热点,它的基本原理是利用生成式对抗网络将一张输入图像转换为相对应的输出图像的过程。目的是在图像转换问题上,输入一张图像能够得到相应的输出图像。
[0003]
phillip等人在2017年的cvpr(国际计算机视觉与模式识别大会上)发表了文章“image-to-image translation with conditional adversarial networks”证实了生成式对抗网络(gan)在图像转换方面的巨大优势:通过将场景的一个可能转换成另一个图像,一种通用的gan模型能够对各种结构的图像进行转换。从那以后,从那以后,在学术研究和产业应用对生成式对抗网络图像转换产生了极大的兴趣,基于生成式对抗网络的图像转换已成为学术界和工业界的研究热点之一。包括清华大学,北京大学,stanford大学和uc berkeley大学等国内外世界知名大学、研究院(所)和实验室在内的团队,对图像转换进行了广泛且深入的研究。
[0004]
现有的图像到图像的转换方法存在的问题主要有:图像到图像的转换具有很大的随意性,因此很多情况下,效果不理想,有时候还会产生一些错误,比如说眼睛处有重影,背景颜色缺失,清晰度不高等,转换效果不理想。
技术实现要素:
[0005]
本发明的目的在于提供基于边缘增强和生成式对抗网络的人脸素描图像转换为rgb图像的方法,以解决上述背景技术中提出的问题。
[0006]
为实现上述目的,本发明提供如下技术方案:基于生成式对抗网络的人脸素描图像转换为rgb图像方法,包括以下步骤:
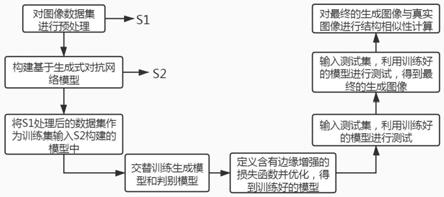
[0007]
步骤1,使用celebfaces属性数据集(celeba)作为真实的彩色人脸图像数据来源,并对图像数据进行预处理,得到训练集a;
[0008]
步骤2,构建基于生成式对抗网络的人脸素描图像转换为rgb图像的模型,包括生成模型g和判别模型d;
[0009]
步骤3,将训练集a输入到基于生成式对抗网络的人脸素描图像转换为rgb图像的模型中,并采用单独交替训练方法训练生成模型g与判别模型d,采用监督性学习方式对生成式对抗网络模型进行训练,得到训练输出集b;
[0010]
步骤4,利用条件生成式对抗网络模型的损失函数、生成模型g损失函数、判别模型d损失函数计算生成式对抗网络模型的损失函数,得到基于生成式对抗网络的模型最终的损失函数;
[0011]
步骤5,重复步骤1,得到测试集c;
[0012]
步骤6,将测试集c输入训练好的基于生成式对抗网络的模型进行测试,得到测试输出集e;
[0013]
步骤7,重复步骤3,4,将训练集a进行600次迭代,用于训练模型,在重复步骤6,将测试集c进行5次迭代,得到最终的测试输出集e;
[0014]
优选的,所述步骤1中,对celebfaces属性数据集(celeba)中的图像进行预处理,首先利用基于深层神经网络的openface人脸检测方法,截取数据集中每张图像的人脸部分,得到彩色人脸图像数据集,再利用opencv方法对彩色人脸图像数据集进行归一化,得到大小为256*256的目标数据集即真实的彩色人脸图像集target,最后利用pillow库把真实的彩色人脸图像集target转化为素描图像,作为输入图像即人脸素描图像input,与真实的彩色人脸图像集target一一配对,并将input和target作为训练集a。
[0015]
优选的,所述步骤2中,构建基于生成式对抗网络的人脸素描图像转换为rgb图像的模型,包括生成模型g和判别模型d。生成模型g使用u-net架构,由编码器和解码器组成,编码器中的第i层与解码器中第n-i层之间连通,使得解码器中的通道数变为原来的2倍。其中编码器进行下采样操作,包括8个卷积层,第一层为卷积层,卷积核为4*4,步长为2,第二层至第八层均为卷积核为4*4、步长为2的convolution-batchnorm-relu层;解码器包括8个反卷积层,进行上采样操作,8个标准化层,使反卷积后的值处于[0,1]之间,8个拼接层,用于拼接图像第3维的特征通道,最后返回tanh函数。判别模型使用patchgan架构,包含3个卷积核为4*4、步长为2的1个convolution-lrelu层,3个convolution-batchnorm-dropout-lrelu层和1个全连接层,其中dropout的概率为0.5。
[0016]
优选的,所述步骤3中,将训练集a输入到模型中,开始交替训练模型,将训练集a输入到模型中,开始交替训练模型,
[0017]
(1)固定判别模型d,训练生成模型g,首先训练生成模型g即u-net结构中的编码器和解码器:
[0018]
①
编码器训练
[0019]
a1.将1张3维256*256的人脸素描图像input输入到编码器的第1层卷积层中,得到64维128*128像素大小的编码器卷积层输出特征图;
[0020]
b1.将编码器第1层卷积层的输出特征图输入到编码器的第2层卷积层中,依次进行非线性lrelu变换、卷积和批标准化,得到128个64*64像素大小的编码器卷积层输出特征图;
[0021]
c1.将编码器第2层卷积层的输出特征图输入到生成模型的第3层卷积层中,依次进行非线性lrelu变换、卷积和批标准化,得到256个32*32像素大小的编码器卷积层输出特征图;
[0022]
d1.将编码器第3层卷积层的输出特征图输入到生成模型的第4层卷积层中,依次进行非线性lrelu变换、卷积和批标准化,得到512个16*16像素大小的编码器卷积层输出特征图;
[0023]
e1.以此类推,将编码器的第4层卷积层输出的特征图输入到第5层,将第5层卷积层的输出特征图输入到第6层,将第层6卷积层的输出特征图输入到第7层,将第7层卷积层的输出特征图输入到第8层,依次进行非线性lrelu变换、卷积、下采样和批标准化操作,分
别得到512个8*8像素大小的特征图、512个4*4像素大小的特征图、512个2*2像素大小的特征图、512个1*1像素大小的特征图;
[0024]
②
解码器训练
[0025]
a2.将512个1*1像素大小的特征图输入解码器的第1层反卷积层中,依次对其进行非线性的relu变换、反卷积、批标准化、dropout操作以及第3通道的concat操作,得到1024个2*2像素大小的解码器卷积层输出特征图;
[0026]
b2.将解码器第1层卷积层输出的特征图输入到解码器的第2层中,依次对其进行非线性的relu变换、反卷积、上采样、批标准化、dropout操作以及第3通道的concat操作,得到1024个4*4像素大小的解码器卷积层输出特征图;
[0027]
c2.将解码器第2层卷积层输出的特征图输入到解码器的第3层中,依次对其进行非线性的relu变换、反卷积、上采样、批标准化、dropout操作以及第3通道的concat操作,得到1024个8*8像素大小的解码器卷积层输出特征图;
[0028]
d2.将解码器第3层卷积层输出的特征图输入到解码器的第4层中,依次对其进行非线性的relu变换、反卷积、上采样、批标准化、dropout操作以及第3通道的concat操作,得到1024个16*16像素大小的解码器卷积层输出特征图;
[0029]
e2.以此类推,将解码器的第4层卷积层输出的特征图输入到第5层,将第5层卷积层的输出特征图输入到第6层,将第层6卷积层的输出特征图输入到第7层,将第7层卷积层的输出特征图输入到第8层,依次进行非线性relu变换、反卷积、批标准化以及第3通道的concat操作,第5层到第7层分别得到512个32*32像素大小的特征图、256个64*64像素大小的特征图、128个128*128像素大小的特征图,第8层得到的是1张3维的256*256像素大小的特征图,最后返回tanh函数。
[0030]
(2)固定生成模型g,训练判别模型d:
[0031]
a3.将一张6维256*256像素大小的彩色人脸图像输入到判别模型d的第1层卷积层中,依次对其进行卷积和非线性lrelu变换操作,得到64个128*128像素大小的判别模型d第1层卷积层输出特征图;
[0032]
b3.将判别模型d第1层卷积层输出的特征图输入第2层卷积层中,依次对其进行卷积、批标准化和非线性lrelu变换操作,得到128个64*64像素大小的判别模型d第2层卷积层输出特征图;
[0033]
c3.将判别模型d第2层卷积层输出的特征图输入第3层卷积层中,依次对其进行卷积、批标准化和非线性lrelu变换操作,得到256个32*32像素大小的判别模型d第3层卷积层输出特征图;
[0034]
d3.将判别模型d第3层卷积层输出的特征图输入第4层全连接层中,依次对其进行卷积、批标准化和非线性lrelu变换操作,得到512个32*32像素大小的判别模型d第4层卷积层输出特征图;
[0035]
e3.将判别模型d第4层卷积层输出的特征图输入第5层全连接层中,对其进行reshape操作,调整特征图的维度,输出3维的256*256的彩色人脸图像,最后返回sigmoid函数。
[0036]
优选的,所述步骤4中,交替训练生成模型g和判别模型d的损失函数,训练生成模型g使得目标函数最小化,而判别模型d使得目标函数最大化,即:
[0037][0038]
其中表示训练判别模型d时,保证生成模型g部分保持不变,使得判别模型g可以准确地判别生成的彩色人脸图像output,即使得1-d(x,g(x,z))的值接近于1,最大化e
x,y
[logd(x,y)]的值。
[0039]
表示训练生成模型g时保证判别模型d部分保持不变,使得生成的彩色人脸图像output可以通过判别模型d的判断,即使得d(x,g(x,z))的值接近于1,并且最小化e
x,z
[log(1-d(x,g(x,z)))]的值。
[0040]
式中λ1为权重系数,用来调节生成模型g的损失函数l
l1
(g)的比重,从而得到更好地输出图像,l
l1
(g)表示真实的彩色人脸图像target与生成的彩色人脸图像output之间的距离,定义为:
[0041]
l
l1
(g)=e
x,y,z
[||y-g(x,z)||1],
[0042]
其中y-g(x,z)表示真实的彩色人脸图像target与生成的彩色人脸图像output之间的差异。
[0043]
与现有技术相比,本发明的有益效果是:
[0044]
(1)本发明基于生成式对抗网络模型,实现了对人脸素描图像转换为rgb图像的方法,首次将人脸图像的转换运用在生成式对抗网络模型中,填补了生成式对抗网络在人脸图像运用上的空缺,同时网络的泛化能力和鲁棒性更强,少量的数据集也可以作为训练样本,节省了人工搜集图像的时间;
[0045]
(2)本发明定义了一个新的损失函数,与传统的生成式对抗网络模型损失函数相比,在生成模型g中加入了边缘增强对生成图像的约束,能够生成与真实的彩色人脸图像更相似的图像,提高了模型的性能和图像转换的精度。
附图说明
[0046]
图1是本发明的系统流程图;
[0047]
图2是本发明的模型架构图;
[0048]
图3是本发明实施例中的部分转换结果对比图;
[0049]
其中a为原图,b为我们的方法输出的图像,c为gatys方法输出的图像,d为cnnmrf方法输出的图像;
[0050]
图4是本发明实施例中的部分转换结果对比图;
[0051]
其中e为原图,f为我们的方法输出的图像,g为gatys方法输出的图像,h为cnnmrf方法输出的图像。
具体实施方式
[0052]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清除、完整地描述,显然,说书的实施例仅仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术上人员在没有做出创造性劳动的前提下所获得的其他实施例,都属于本发明保护的范围。
[0053]
请参阅图1-3,本发明提供一种技术方案:基于生成式对抗网络的人脸素描图像转
换为rgb图像方法,包括以下步骤:
[0054]
步骤1,使用celebfaces属性数据集(celeba)作为真实的彩色人脸图像数据来源,并对图像数据进行预处理,得到训练集a;
[0055]
步骤2,构建基于生成式对抗网络的人脸素描图像转换为rgb图像的模型,包括生成模型g和判别模型d;
[0056]
步骤3,将训练集a输入到基于生成式对抗网络的人脸素描图像转换为rgb图像的模型中,并采用单独交替训练方法训练生成模型g与判别模型d,采用监督性学习方式对生成式对抗网络模型进行训练,得到训练输出集b;
[0057]
步骤4,利用条件生成式对抗网络模型的损失函数、生成模型g损失函数、判别模型d损失函数计算生成式对抗网络模型的损失函数,得到基于生成式对抗网络的模型最终的损失函数;
[0058]
步骤5,重复步骤1,得到测试集c;
[0059]
步骤6,将测试集c输入训练好的基于生成式对抗网络的模型进行测试,得到测试输出集e;
[0060]
步骤7,重复步骤3,4,将训练集a进行600次迭代,用于训练模型,在重复步骤6,将测试集c进行5次迭代,得到最终的测试输出集e;
[0061]
本发明中,步骤1中,对celebfaces属性数据集(celeba)中的图像进行预处理,首先利用基于深层神经网络的openface人脸检测方法,截取数据集中每张图像的人脸部分,得到彩色人脸图像数据集,再利用opencv方法对彩色人脸图像数据集进行归一化,得到大小为256*256的目标数据集即真实的彩色人脸图像集target,最后利用pillow库把真实的彩色人脸图像集target转化为素描图像,作为输入图像即人脸素描图像input,与真实的彩色人脸图像集target一一配对,并将input和target作为训练集a。
[0062]
本发明中,步骤2中,构建基于生成式对抗网络的人脸素描图像转换为rgb图像的模型,包括生成模型g和判别模型d。生成模型g使用u-net架构,由编码器和解码器组成,编码器中的第i层与解码器中第n-i层之间连通,使得解码器中的通道数变为原来的2倍。其中编码器进行下采样操作,包括8个卷积层,第一层为卷积层,卷积核为4*4,步长为2,第二层至第八层均为卷积核为4*4、步长为2的convolution-batchnorm-relu层;解码器包括8个反卷积层,进行上采样操作,8个标准化层,使反卷积后的值处于[0,1]之间,8个拼接层,用于拼接图像第3维的特征通道,最后返回tanh函数。判别模型使用patchgan架构,包含3个卷积核为4*4、步长为2的1个convolution-lrelu层,3个convolution-batchnorm-dropout-lrelu层和1个全连接层,其中dropout的概率为0.5。
[0063]
本发明中,步骤3中,将训练集a输入到模型中,开始交替训练模型,将训练集a输入到模型中,开始交替训练模型,
[0064]
(1)固定判别模型d,训练生成模型g,首先训练生成模型g即u-net结构中的编码器和解码器:
[0065]
①
编码器训练
[0066]
a1.将1张3维256*256的人脸素描图像input输入到编码器的第1层卷积层中,得到64维128*128像素大小的编码器卷积层输出特征图;
[0067]
b1.将编码器第1层卷积层的输出特征图输入到编码器的第2层卷积层中,依次进
行非线性lrelu变换、卷积和批标准化,得到128个64*64像素大小的编码器卷积层输出特征图;
[0068]
c1.将编码器第2层卷积层的输出特征图输入到生成模型的第3层卷积层中,依次进行非线性lrelu变换、卷积和批标准化,得到256个32*32像素大小的编码器卷积层输出特征图;
[0069]
d1.将编码器第3层卷积层的输出特征图输入到生成模型的第4层卷积层中,依次进行非线性lrelu变换、卷积和批标准化,得到512个16*16像素大小的编码器卷积层输出特征图;
[0070]
e1.以此类推,将编码器的第4层卷积层输出的特征图输入到第5层,将第5层卷积层的输出特征图输入到第6层,将第层6卷积层的输出特征图输入到第7层,将第7层卷积层的输出特征图输入到第8层,依次进行非线性lrelu变换、卷积、下采样和批标准化操作,分别得到512个8*8像素大小的特征图、512个4*4像素大小的特征图、512个2*2像素大小的特征图、512个1*1像素大小的特征图;
[0071]
②
解码器训练
[0072]
a2.将512个1*1像素大小的特征图输入解码器的第1层反卷积层中,依次对其进行非线性的relu变换、反卷积、批标准化、dropout操作以及第3通道的concat操作,得到1024个2*2像素大小的解码器卷积层输出特征图;
[0073]
b2.将解码器第1层卷积层输出的特征图输入到解码器的第2层中,依次对其进行非线性的relu变换、反卷积、上采样、批标准化、dropout操作以及第3通道的concat操作,得到1024个4*4像素大小的解码器卷积层输出特征图;
[0074]
c2.将解码器第2层卷积层输出的特征图输入到解码器的第3层中,依次对其进行非线性的relu变换、反卷积、上采样、批标准化、dropout操作以及第3通道的concat操作,得到1024个8*8像素大小的解码器卷积层输出特征图;
[0075]
d2.将解码器第3层卷积层输出的特征图输入到解码器的第4层中,依次对其进行非线性的relu变换、反卷积、上采样、批标准化、dropout操作以及第3通道的concat操作,得到1024个16*16像素大小的解码器卷积层输出特征图;
[0076]
e2.以此类推,将解码器的第4层卷积层输出的特征图输入到第5层,将第5层卷积层的输出特征图输入到第6层,将第层6卷积层的输出特征图输入到第7层,将第7层卷积层的输出特征图输入到第8层,依次进行非线性relu变换、反卷积、批标准化以及第3通道的concat操作,第5层到第7层分别得到512个32*32像素大小的特征图、256个64*64像素大小的特征图、128个128*128像素大小的特征图,第8层得到的是1张3维的256*256像素大小的特征图,最后返回tanh函数。
[0077]
(2)固定生成模型g,训练判别模型d:
[0078]
a3.将一张6维256*256像素大小的彩色人脸图像输入到判别模型d的第1层卷积层中,依次对其进行卷积和非线性lrelu变换操作,得到64个128*128像素大小的判别模型d第1层卷积层输出特征图;
[0079]
b3.将判别模型d第1层卷积层输出的特征图输入第2层卷积层中,依次对其进行卷积、批标准化和非线性lrelu变换操作,得到128个64*64像素大小的判别模型d第2层卷积层输出特征图;
[0080]
c3.将判别模型d第2层卷积层输出的特征图输入第3层卷积层中,依次对其进行卷积、批标准化和非线性lrelu变换操作,得到256个32*32像素大小的判别模型d第3层卷积层输出特征图;
[0081]
d3.将判别模型d第3层卷积层输出的特征图输入第4层全连接层中,依次对其进行卷积、批标准化和非线性lrelu变换操作,得到512个32*32像素大小的判别模型d第4层卷积层输出特征图;
[0082]
e3.将判别模型d第4层卷积层输出的特征图输入第5层全连接层中,对其进行reshape操作,调整特征图的维度,输出3维的256*256的彩色人脸图像,最后返回sigmoid函数。
[0083]
本发明中,步骤3中,交替训练生成模型g和判别模型d的损失函数,训练生成模型g使得目标函数最小化,而判别模型d使得目标函数最大化,即:
[0084][0085]
其中表示训练判别模型d时,保证生成模型g部分保持不变,使得判别模型g可以准确地判别生成的彩色人脸图像output,即使得1-d(x,g(x,z))的值接近于1,最大化e
x,y
[logd(x,y)]的值。
[0086]
表示训练生成模型g时保证判别模型d部分保持不变,使得生成的彩色人脸图像output可以通过判别模型d的判断,即使得d(x,g(x,z))的值接近于1,并且最小化e
x,z
[log(1-d(x,g(x,z)))]的值。
[0087]
式中λ1为权重系数,用来调节生成模型g的损失函数l
l1
(g)的比重,从而得到更好地输出图像,l
l1
(g)表示真实的彩色人脸图像target与生成的彩色人脸图像output之间的距离,定义为:
[0088]
l
l1
(g)=e
x,y,z
[||y-g(x,z)||1],
[0089]
其中y-g(x,z)表示真实的彩色人脸图像target与生成的彩色人脸图像output之间的差异。
[0090]
下面结合仿真实验对本发明的效果做进一步描述。
[0091]
1.仿真实验条件:
[0092]
本发明仿真的硬件环境是:intel(r)core(tm)i5-5200u cpu@2.2ghz 2.2ghz,gpunvidiageforce gtx titan x,12gb内存;软件环境:ubuntu 16.04,ipython2.7;windows 10,matlabr2014b。
[0093]
2.仿真内容和结果:
[0094]
本发明首先将celebfaces属性数据集(celeba)作为真实的彩色人脸图像数据来源,并对图像数据进行预处理,得到600张一一配对的真实的彩色人脸图像和素描人脸图像,作为训练集a,再构建生成式对抗网络模型,将训练集a输入到模型中,交替训练模型,首先固定判别模型,训练生成模型,其次固定生成模型,固定判别模型,设定batch_size为1,经过600次迭代,得到生成的600张彩色人脸图像。将测试集c输入到训练好的模型中,迭代5次之后,输出生成的200张彩色人脸图像,对其结构相似度即ssim值进行了计算,表1统计了2张图像的相似度,并与gatys方法和cnnmrf方法进行了比较。图3,图4分别是输出图像和真
实图像。
[0095][0096]
从表1中可知,对比其他两种方法,我们的方法生成的彩色人脸图像与真实的彩色人脸图像的结构相似度是比较高的,证明基于生成式对抗网络的人脸素描图像转换为rgb图像方法是可行的。
[0097]
本发明基于生成式对抗网络建立人脸素描图像转换为rgb图像的模型,然后输入训练集,交替训练其生成模型g和判别模型d,从而生成与真实的彩色人脸图像相似度高的彩色人脸图像,实现对人脸图像的转换。
[0098]
综上所述,本发明通过对celebfaces属性数据集(celeba)中的图像进行预处理,得到训练集a,把训练集a输入到生成式对抗网络模型中,交替训练生成模型g和判别模型d,得到训练输集b,同时在训练过程中不断调整参数,从而使得生成的图像与真实的彩色人脸图像更加相似;本文定义了一个新的损失函数,与传统的图像转换损失函数相比,增加了边缘增强对生成图像的约束,提高了模型的性能和图像转换的精度。
[0099]
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1