基于高并发环境的缓存一致性问题解决方法与流程
[0001]
本发明涉及spring框架下的应用软件编程技术领域,特别是一种基于高并发环境的缓存一致性问题解决方法。
背景技术:
[0002]
在现代互联网应用程序中,由于庞大的用户基数,常常需要应对较高的任务并发,而数据存取往往需要大量的外存io操作,过长的处理时延,大大限制了应用的并发数。缓存技术便应运而生,即在数据层和接入层之间引入缓存层,由于是直接对内存的操作,极大降低了对外存的io频次,特别是对应读多写少的应用,甚至能将处理时延降低几倍乃至数百倍,如图1所示。但随着缓存的引入,又不得不面对新的问题,数据一致性问题。
[0003]
业界常见的处理方法有删除缓存后更新数据源,或者更新数据源后删除缓存。在低并发系统中,这两种处理方法均能较好的工作,随着并发数的提高,问题就逐渐暴露了出来。就拿前者来说,假设有两个线程并发进入,a线程更新,b线程读取,a删除缓存成功后但更新数据源成功前b线程开始读取缓存,此时读取到的缓存为空,于是从数据源查询出数据并将结果放入缓存,此时a线程更新数据源成功,不一致的“脏”数据由此产生,只能靠缓存的键值过期,或者下次更新才能恢复。而后者相较于前者则是一个更优的解决方案,数据源更新前不论读取并发有多高,都不会穿透到数据层造成大量的io阻塞,且因为缓存还没有删除数据也还未更新,不会取到不一致的“脏”数据。但是依然存在异常情况,即数据源的更新事务提交前,删除了缓存,或者更新事务提交后但缓存删除却失败了,在高并发环境下依然会很容易出现一致性问题,如图2所示。
[0004]
这时就需要引入额外的方法,进行补偿或者施加限制,尽最大可能在最短的时间内实现缓存的最终一致性,甚至是个别特殊系统下的强一致性。
技术实现要素:
[0005]
为解决现有技术中存在的问题,本发明的目的是提供一种基于高并发环境的缓存一致性问题解决方法,可灵活解决项目开发中的缓存一致性问题。
[0006]
为实现上述目的,本发明采用的技术方案是:一种基于高并发环境的缓存一致性问题解决方法,包括以下步骤:
[0007]
步骤1、配置事务和缓存的执行顺序;
[0008]
步骤2、捕获缓存执行失败事件;
[0009]
步骤3、获取缓存执行的相关参数;
[0010]
步骤4、对捕获到的事件进行处理:首先维护一个队列,其次对补偿事件进行wrap,植入失败时刻、重读次数属性,然后维护一个持久化线程池,对所有入队的事件进行异步持久化处理,补偿成功后则异步删除持久化的数据,每次队列初始化的时候从已持久化的数据源读取未补偿成功的数据;
[0011]
步骤5、结合需要删除缓存的缓存名和key集合再通过相应的摘要算法,计算出特
征值并赋值到补偿数据中,在删除缓存失败时被入队到补偿队列,等待时间唤醒后再次执行补偿,如果删除操作执行成功,则把补偿队列中的相同特征值的数据清除,当新增入队数据的时候,判断队列里面是否已经有相同特征值的数据;
[0012]
步骤6、对可配置项进行配置,包括对缓存进行强一致性或最终一致性的配置、对队列进行配置以及对补偿唤醒的延迟算法进行配置;
[0013]
步骤7、对关键节点进行抽象归纳,并expose出精炼易懂的接口。
[0014]
作为本发明的进一步改进,在步骤1中,配置事务和缓存的执行顺序具体包括:通过观察开关注解import的configuration,找出order属性最终被赋值的bean,然后通过autowire的方式获得reference,进而对其相应的存储字段进行设定。
[0015]
作为本发明的进一步改进,在步骤2中,通过spring-cache框架的原生模块cacheerrorhandler来捕获缓存执行失败事件。
[0016]
作为本发明的进一步改进,在步骤5中,所述的摘要算法包括hash算法、sha算法或md5算法。
[0017]
本发明的有益效果是:
[0018]
本发明封装完善,配置灵活,集成简单,极大提高了缓存数据和数据源数据保持一致性的概率,配合无限制的补偿机制,最终一致性理论上达到100%。
附图说明
[0019]
图1为引入缓存原因分析示意图;
[0020]
图2为现有缓存处理的现状及问题所在示意图;
[0021]
图3为本发明实施例1中补偿事件的整体处理设计图;
[0022]
图4为本发明实施例1中补偿数据的特征值计算示意图;
[0023]
图5为本发明实施例1中补偿队列出入队时特征值作用示意图;
[0024]
图6为本发明实施例1的框架配置流程示意图;
[0025]
图7为本发明实施例1中补偿唤醒算法的次数与时长关系示意图;
[0026]
图8为本发明实施例1的框架核心的uml类图。
具体实施方式
[0027]
下面结合附图对本发明的实施例进行详细说明。
[0028]
实施例1
[0029]
一种基于高并发环境的缓存一致性问题解决方法,本实施例采用可配置的方式,配置是强一致性还是最终一致性,配置补偿点的持久化介质等等,使用编程式或声明式的编码方式,灵活解决项目开发中的缓存一致性问题。
[0030]
本实施例是基于spring环境,封装同时兼容声明式和编程式编码方式来优化处理缓存一致性问题的框架。其中声明式的方式有两个要点,一是声明式缓存注解和声明式事务注解的执行顺序调整,二是缓存注解执行失败的事件捕获以及相应参数的获取;声明式和编程式的方式均有一个共同的要点,就是被标记的补偿点,要有一个特征值,即同样的缓存操作,再次被调用并且成功后,需要把原同样操作的补偿数据从补偿队列中剔除,避免重复补偿。
[0031]
接下来针对声明式方式进行展开,第一个就是要配置事务和缓存的执行顺序,首先如果采用默认的aop顺序,则事务和缓存的顺序依赖于多种因素,是不可控的,所以必须显式的对其排序值进行设定。通过查阅spring-framework源码,不难发现这两个aop advisor的排序是来自开关注解配置的order属性,通过传递metadata的方式进行获取。所以可以推出若干种设定方式,最直观的就是在使用开关注解enabletransactionmanagement、enablecaching中直接配置order属性,为其赋予合适的顺序值;其次就是通过观察开关注解import的configuration,找出order属性最终被赋值的bean,然后通过autowire的方式获得reference,进而对其相应的存储字段进行设定;最后就是通过反射、aop等方式hook相应的调用句柄,中途实施拦截并修改。综上,除了第二种,其他的方式对使用者的侵入性都比较高,以及稳定性偏低(比如通过反射的方式,后续版本升级了,field或method定义变了,则可能导致hook失效)等问题,故本实施例采用第二种方式对事物和缓存的顺序进行设定。第二个就是缓存执行失败的事件捕获,这个有两种实现方式,一种是通过try-catch语句块,捕获缓存执行代码抛出的异常,并筛选出与之对应的异常,进而加以标记;另外一种则是通过spring-cache框架的原生模块cacheerrorhandler来进行处理。显然,第一种方式需要甄别异常类型,写法繁琐且容易遗漏,稳定性也差(各版本所抛异常可能有差异),所以本实施例采用第二种方式进行事件捕获。第三个就是获取缓存执行的相关参数,这一点在采用cacheerrorhandler捕获事件的前提下变得非常容易,直接获取回调方法里的入参即可。
[0032]
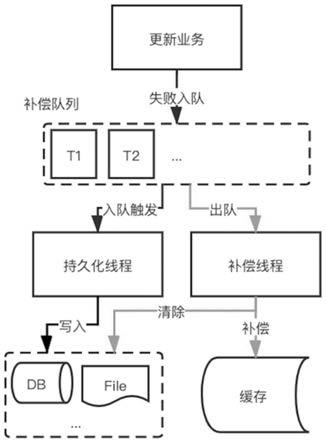
然后是对捕获到的事件进行处理。首先需要维护一个队列,这里的队列可以采用常用中间件如rabbitmq,也可以自定义一个简单的单机queue,因为这里的业务对队列属于轻量级依赖,只需要用到简单的入队/出队即可,本实施例按自定义单机queue的方式进行说明。其次对补偿事件进行wrap,将失败时刻、重试次数等属性进行植入,以便消费队列时取用。然后是维护一个持久化线程池,对所有入队的事件进行异步持久化处理,补偿成功后则异步删除持久化的数据,每次队列初始化的时候都会从已持久化的数据源读取未补偿成功的数据,尽可能保证所有未补偿数据最终都能补偿成功,如图3所示。
[0033]
其次是对事件特征值做说明,假设有个缓存a的删除操作,删除key为key1,结合缓存名和key集合再通过相应的摘要算法,如hash、sha、md5等,计算出特征值α并赋值到补偿数据中,如图4所示,在删除缓存失败时被入队到补偿队列,补偿多次后仍不成功,此时队列里面和持久化数据里面均保存了该补偿数据,只是根据唤醒算法,仍在等待中,等待时间唤醒后将再次执行补偿。此时缓存a的删除操作再次被执行,删除key仍为key1,所以他们的特征值必定是一样的,而这次删除操作又执行成功了。这时应该尝试把补偿队列中的相同特征值的数据给清除,避免下次唤醒时的重复补偿。同理新增入队数据的时候,也应当判断队列里面是否已经有相同特征值的数据,如图5所示。
[0034]
再次是对可配置项进行说明,如图6所示,比如可配置缓存的解决方案是强一致性还是最终一致性,上述方法都是针对最终一致性为目标的,如果是配置的强一致性,则需要对相同的缓存,相同的key施加分布式锁,保证有写锁时读锁应该等待,多个读锁可重入,来强制规避该问题。显然,该方案会带来严重的性能问题,所以如果不是对一致性有强烈要求的业务一般不采用该方案。然后是对队列实现进行配置,可配置队列中间件和自定义简单队列等,可配置持久化数据源如db、file等。最后是配置补偿唤醒的延迟算法,如相等间隔
算法,线性间隔算法,指数间隔算法等,如图7所示。
[0035]
最后是对整个方案进行封装,对关键节点进行抽象归纳,并expose出精炼易懂的接口。例如实施例对调用层,抽象出标记失败、标记成功两个方法;对入队层抽象入队、出队两个方法;对持久层抽象出新增、更新、删除、读取方法;对声明式封装集成调用工具和自动配置类。框架核心的架构设计如图8所示。
[0036]
实施例2
[0037]
一种基于高并发环境的缓存一致性问题解决方法,包括以下步骤:
[0038]
s1:创建配置类用于接入框架时配置相应的补偿策略,以及注入必要的工具bean;
[0039]
s1-1:配置类设置非必要方式注入beanfactorycacheoperationsourceadvisor以及beanfactorytransactionattributesourceadvisor,并在注入成功后设置order属性;
[0040]
s2:创建注解@safetycache用于支持本发明框架的声明式使用;
[0041]
s2-1:创建注解解析类用于读取并保存配置了注解的方法和注解中的metadata;
[0042]
s2-2:实现cacheerrorhandler接口处理相应类型的error并加入到补偿队列;
[0043]
s2-3:实现methodinterceptor接口在缓存操作执行成功时进行出队操作;
[0044]
s3:封装cache类用于存储缓存名、缓存key集合、特征值、重试次数、等待时长等字段;
[0045]
s4:创建入口函数用于支持本发明框架的编程式使用,提供标记失败和标记成功两个方法;
[0046]
s4-1:获得调用句柄后首先计算特征值,然后根据失败或成功状态执行入队或出队操作;
[0047]
s4-2:实现计算特征值算法,本发明采用md5摘要算法来进行计算;
[0048]
s5:创建队列并实现基本的入队出队方法,入队方法加入根据特征值排重的判断逻辑;
[0049]
s5-1:队列的出入队操作均配置乐观锁实现和悲观锁实现,以满足不同场景的业务需求;
[0050]
s5-1-1:本实施例只实现了悲观锁实现,即在出入队时加入细粒度的分段锁,有效防止数据冲突,对性能的影响也控制在可接受范围内;
[0051]
s6:维护持久化线程持续异步地从队列中读取数据并调用相应的持久化实现进行持久化操作;
[0052]
s7:至少实现并注入一种持久化接口的实现类,本框架仅实现filepersistant,并采用filechannel进行io操作,大幅提高文件的存取性能;
[0053]
s8:维护补偿线程,同样采用类似filechannel的aio方式监测队列情况,一旦唤醒则立即执行补偿操作;
[0054]
s9:至少实现并注入一种唤醒接口的实现类,本框架采用线性间隔算法的实现,因为在目前的应用中3次内几乎能达到100%的补偿率,该算法处理耗时较为平稳。
[0055]
以上所述实施例仅表达了本发明的具体实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1