基于倒排索引的大规模数据相似特征检测方法与流程
[0001]
本发明属于机器学习及数据挖掘领域,涉及大数据特征工程中特征相似性检测的方法,尤其涉及一种基于倒排索引的大规模数据相似特征检测方法。
背景技术:
[0002]
特征相似性检测(feature similarity detection)是数据挖掘过程中至关重要的一个环节,也是机器学习模型训练的必要过程。原始的数据集中往往存在大量的相似特征,在模型训练过程中会分散特征的重要度,影响特征的筛选,影响模型性能;且增加了不必要的计算开销,浪费大量的资源。
[0003]
目前主要的特征相似性检测方法,大多需要遍历并两两组合所有的特征进行分析,当原始特征集的规模很大时,组合后得到的特征对集合规模也会非常大,这使得该方法在大规模数据集上表现不佳;或者通过局部敏感哈希(locality sensitive hash)方法先进行降维再分析相似性,该方法的不足之处在于:虽然降低了数据集的维度,但该方法目前只能应用于类别型(包括数值型经过独热编码后)的特征,无法应用于数值型特征。
技术实现要素:
[0004]
本发明的目的是针对现有技术的不足,提供一种基于倒排索引的大规模数据相似特征检测方法。本发明方法可以做到降低特征集的维度,进而大幅度减少计算时间,且可以同时应用于类别型和数值型的特征,并保证极高的准确率和召回率。
[0005]
本发明的目的是通过以下技术方案来实现的:
[0006]
一种基于倒排索引的大规模数据相似特征检测方法,包括:
[0007]
1.对于关系型数据库中的表格型数据集,数据集的特征即为表格的字段。数据集的所有特征构成了原始特征集,对于原始特征集中的每一个特征:首先将它所对应的数据进行列采样,并构建倒排索引,再将倒排索引-特征作为哈希表的键-值对;
[0008]
2.遍历哈希表,将哈希表中所有属于同一个键的不同特征提取出来,作为特征子集。对每一个特征子集,将其中包含的特征两两组合成为特征对,由于每一个特征对中的两个特征都具有相同的倒排索引,因此二者具有较高的概率是一对相似特征。所有的特征对构成了候选特征集;
[0009]
3.候选特征集中的每一个特征对,应用对应的相似度度量函数,设定阈值,得到相似性度量结果并加入结果集。
[0010]
特征按其数据属性,可分为数值型特征和类别型特征两类。因此对于一个给定的数据集,我们先对原始特征分类,构建数值型原始特征集和类别性原始特征集,并分别执行上述1~3,分别得到数值型特征集的结果集和类别型特征集的结果集。
[0011]
上述技术方案中,1中所述的列采样并构建倒排索引方法,其具体方法如下:
[0012]
1)将特征所对应数据进行随机的列采样,得到采样后数据列;
[0013]
2)倒排索引构建方法:对于数值型特征,先计算采样后数据列的均值,然后将采样
后数据列中大于均值的值映射为1,小于均值的值映射为-1,其余的值映射为0,映射后的采样后数据列即为对应数值型特征的倒排索引;对于类别型特征,顺序遍历采样后数据列,将第一个类别取值映射为1,第二个类别取值映射为2
…
依次递增,映射后的采样后数据列即为对应类别型特征的倒排索引。
[0014]
进一步的,3中对每个特征对采用相应的相似性度量函数、阈值设定,加入结果集,其具体方法如下:
[0015]
1)对于数值型的特征对,对全列数据应用皮尔森相关系数(pearson correlation coefficient)方法来度量相似性,当特征对中两个特征对应的数据列之间的皮尔森相关系数绝对值大于设定的阈值时,将该特征对标记为相似特征对,并加入结果集当中;
[0016]
2)对于类别型的特征对,对全列数据应用非重复计数方法来度量相似性,即统计原始数据列中去除重复值后的取值的数目;假设待测的特征对中两个特征f1和f2的非重复计数分别为c1、c2;f1和f2的联合非重复计数为c3;当c1=c2=c3时,将该特征对标记为相似特征对,并加入结果集当中。
[0017]
本发明与现有技术相比具有的有益效果:
[0018]
1)本发明提出了通过倒排索引建立特征子集的方法,将可能具有相似性的特征放入同一个子集中,大大降低了需要度量和分析的特征对组合的规模;
[0019]
2)本发明通过分析特征分布和相似性度量函数的关系,提出了全新的倒排索引设计方法,该方法将百万级别的数据分布映射到极小规模的倒排索引上,既将数据维度降低了许多个数量级,也能保证映射关系的唯一性和准确性;
[0020]
3)本发明针对数值型和类别型的特征,分别采用了相应的相似性度量函数皮尔森相关系数算法和非重复计数方法,并在工程化过程中进行了算法的优化,大大提升了算法计算效率。
附图说明
[0021]
图1是基于倒排索引的大规模数据相似特征检测方法总体方案设计示意图;
[0022]
图2是基于倒排索引的大规模数据相似特征检测方法中候选特征集的生成方法举例示意图。
具体实施方式
[0023]
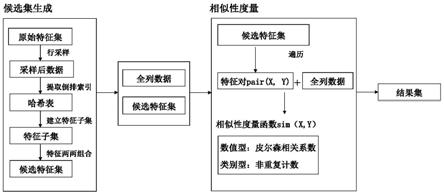
如图1所示,基于倒排索引的大规模数据相似特征检测方法,包括:候选集生成、相似性度量和结果集整合过程。
[0024]
首先对原始特征集中所有的特征对应的数据进行列采样,并构建倒排索引。将具有相同倒排索引的特征放入同一个特征子集中,每一个特征子集中的所有特征两两组合形成特征对后,加入候选特征集。本发明通过分析特征分布和相似性度量函数的关系,提出了全新的倒排索引设计方法:
[0025]
对于数值型的特征对(令特征为x,y),采用皮尔森相关系数来度量特征x和y的相似性,皮尔森相关系数公式如下:
[0026]
[0027]
皮尔森相关系数衡量的是两个特征线性关联性的程度,特征x,y之间的皮尔森相关系数ρ
x,y
和它们之间的协方差cov(x,y)正相关。观察cov(x,y)的公式e((x-μ
x
)(y-μ
y
)),可知x和y同向或反向变化时,协方差的绝对值趋向最大化,归一化后得到皮尔森相关系数趋向1或者-1,此时表明x和y高度正相关或负相关。而x,y的变化趋势可以通过其样本点和期望值μ的关系推导。
[0028]
因此本发明的数值型特征数据列倒排索引设计方法如下:
[0029]
1)对原始特征随机列采样,采样的长度默认为20个样本点,得到采样后序列;
[0030]
2)计算采样后序列的均值μ
sampled
;
[0031]
3)对采样后序列中的所有样本点s,作如下映射:
[0032][0033]
4)映射后的序列即为倒排索引。
[0034]
对于类别型的特征对,采用类别取值重映射的方法来提取倒排索引。
[0035]
本发明的类别型特征数据列倒排索引设计方法如下:
[0036]
1)对原始特征随机列采样,采样的长度默认为20个样本点,得到采样后序列;
[0037]
2)顺序遍历采样后序列中的所有样本点s,作如下映射:
[0038]
若s为采样后序列中的第1种类别取值,则映射为1;
[0039]
若s为采样后序列中的第2种类别取值,则映射为2;
[0040]
……
[0041]
若s为采样后序列中的第n种类别取值,则映射为n;
[0042]
3)映射后的序列即为倒排索引。
[0043]
将倒排索引-特征作为哈希表的键-值对;遍历哈希表,将哈希表中所有属于同一个键的不同特征提取出来,作为特征子集。对每一个特征子集,将其中包含的特征两两组合成为特征对,所有的特征对构成了候选特征集;此时得到的候选特征集中的特征对数目远远小于对原始特征集进行两两组合的数目。具体的理论推导如下:
[0044]
令原始特征集的维度为d,经采样和倒排索引筛选后,得到了m个子集d1d2…
d
m
。注意:
[0045][0046]
若对原始特征集中特征进行两两组合,得到的特征对数目为
[0047]
若所有子集中的特征进行两两组合,得到的特征对数目为
[0048]
计算的时间复杂度大小为:
[0049][0050]
通过倒排索引分解子集后的特征对数目和最大子集相关,而往往子集的规模远小于原始特征集,因此max(o(di2))<<o(d2)。
[0051]
接着对于候选特征集中的所有待测特征对x和y,应用相应的相似性度量函数sim
(x,y)。对于数值型的特征对,采用皮尔森相关系数来度量特征x和y的相似性,设定阈值threshold(默认为0,95),当|sim(x,y)|>threshold,认为相应的特征对属于一对相似特征对并加入结果集;对于类别型特征对,采用非重复计数(即确定去除原始数据中重复值后的取值的数目,比如:对一组数据[a,a,a,b,b,c,d],去除重复值后就成了[a,b,c,d],非重复计数就是4)来度量特征x和y的相似性,具体理论如下:
[0052]
令distinct(x)和distinct(y)分别表示特征x和y的非重复计数的数量;
[0053]
令distinct(x,y)表示特征x和y的联合非重复计数(即将特征x和y对应的字段合并后再进行对应数据列的非重复计数)的数量。
[0054]
当distinct(x)=distinct(y)=distinct(x,y)时,即可推导出特征x和y的取值具有一一对应的映射关系,即待测特征对属于类别型的相似特征对。加入结果集。
[0055]
应用上述理论原理,本发明提供了一种基于倒排索引的大规模数据相似特征检测方法。
[0056]
该方法中的候选特征集生成方法具体实例如图2所示:
[0057]
假设有一个关系型数据库表格,共有100万条记录和5个字段(f1~f5)。以数值型特征为例,该数据集的特征名即为对应表格的字段名,每个特征对应的数据列都具有100万个值。先对数据列进行采样(假设采样长度为8)和倒排索引的构建,得到对应的哈希表。遍历哈希表,得到两组特征子集s1:{f1,f2,f3}以及s2:{f4,f5};对每一个候选子集:将其中的所有特征两两组合,表示成特征对的形式。s1
→
{(f1,f2),(f1,f3),(f2,f3)},s2
→
{(f4,f5)}。合并后得到了候选特征集s:{(f1,f2),(f1,f3),(f2,f3),(f4,f5)},最终得到4组不同的特征对。作为对比,若我们一开始就对原始的特征集进行两两组合,则最终会有组不同的特征对。
[0058]
而实际上在验证该发明的过程中,我们一共在10份不同的数据集上做了实验,平均每份数据集的规模都是250万条左右的记录数和300个左右的特征数。经实验得到以下结果:在采用了本发明中的方法后,相似特征的检测时间可以缩短为使用其他现有方法的十分之一左右,进而极大幅度地节约了时间和资源。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1