基于最优劣距的部分多标记学习方法与流程
1.本发明是涉及部分多标记学习的消歧方法,特别针对一个示例对应一个候选标记集合,并且该集合中不止一个真实标记,还包含着噪声标记的情况。
背景技术:
2.传统的强监督学习假定训练集中的样本是被充分标记的,且每个对象的标记都是单一、无歧义的。但随着互联网的发展,获得的数据在不断增加,对数据进行分类组织的任务也变的越来越重要,在现代分类问题中,传统的强监督信息已不能满足分类的需求,我们常遇到一个对象不仅与一个类别有关,还关联着其他的类别,因此多标记学习(multi
‑
label learning,mll)得到了发展,但多标记学习常常需要为每个训练示例都精确地标注所有相关的标记,实际中由于数据资源的限制,真实标记往往难以获得,以及精确标注的成本昂贵等因素,很难获得明确标注的对象,更多遇到一种弱监督学习场景。如zhi
‑
hua zhou在文献《a brief introduction to weakly supervised learning》所述,目前弱监督学习大致分三大类:不完全监督(incomplete supervision)、不确切监督(inexact supervision)、不准确监督(inaccurate supervision)。部分多标记(partial multi
‑
label learning,pml)学习是属于弱监督学习中不准确监督的一类,pml是近几年刚提出的框架,已在如众包图像标注(crowdsourcing image tagging)、音乐情感识别、文本分类等一些很难从收集的数据中获得准确的监督信息的场景得到应用。据不完全统计,近三年以来(2018年
‑
2020年),标题中出现“部分多标记(partial multi
‑
label)”关键词在kdd、aaai、ijcai、icdm等一流的机器学习会议上出现超过10篇以上。pml与目前流行的mll和偏标记学习(partial label learning,pll)的学习框架有紧密的联系。其中mll处理允许一个示例可以同时与多个具有正确语义标记(类)相关联,学习系统的目标是从训练集中归纳出预测模型,用得来的模型为未见示例预测相关标记集合。pll也是一种弱监督学习框架,它处理一个示例与一个候选标记集合关联,但这个候选标记集合中只有一个这个示例的真实标记的情况。而在pml学习框架下,我们为每个示例分配了一个粗略的候选标记集,这个候选标记集有以下特点:a)候选标记集合至少有一个标记为这个示例的真实(相关)标记,其余标记为噪声(伪)标记;b)不在候选标记集合中的标记均为不相关标记;c)候选标记集合中的真实标记数量未知。
3.综上所述我们可以看出,pml是mll和pll的两个结合,当把示例对应的候选标记集都视为真实标记时,pml则退化为了mll;若候选标记集合中只有一个标记为真实标记,其他都是噪声标记,pml就退化为了pll。
4.目前存在的问题
5.pml学习虽然获取部分多标记数据降低了标注的成本,但也让候选标记集合不仅包含着真实标记,也掺杂了一些噪音标记。若是直接用mll学习方法来处理pml问题,即将候选标记集合中所有的标记都作为真实的标记,这样在训练阶段将会受到候选标记集合中的噪声标记的影响。由于pml任务是需要从训练示例中得到多个标记的示例,而不是单标记示
例,而且候选标记集合中真实标记的数量未知,因此pll的方法不能直接使用于pml问题中。如何识别候选标记集合中的真实标记,减轻噪声标记污染的影响,成为了我们要解决的问题。
6.本发明与现有技术相比具有的优点
7.本发明就目前部分多标记学习中,利用距离方式来计算相似度,主要从示例特征值上的差异来体现示例的相似性,但没有考虑两示例特征向量方向上的相似性,首次引入一个修正的余弦相似度计算方法来估计示例之间的相似程度。此方法不仅继承了原本余弦相似度的优点,从特征方向上的差异来度量示例的相似性;同时也通过对示例特征去中心化的方式,即对示例的每个特征值都减去一个均值,改进了余弦相似度对特征值不敏感的缺点。
8.本发明为训练集中每个训练示例的每个标记设置一个置信度,即该标记成为该示例真实标记的可能性。虽然置信度的概念不是本发明所提出,但现有关于置信度的方法并没有很好地对得到的置信矩阵进一步分析。本发明将置信度应用到pml学习中,并用topsis法进一步分析置信矩阵的信息。首先从置信度矩阵中构造出最优置信向量和最劣置信向量。然后定义一个贴合度函数,根据此函数计算示例中每个标记的贴合度,即该标记与最优标记的贴合程度、与最劣标记的差距。最后利用贴合度函数从候选标记集合中提取可信标记集合,实现对候选标记集合的去噪。
技术实现要素:
9.基于背景中提到的训练阶段易受到噪声标记的影响,mll的方法不能直接应用到pml学习中的情况,本发明假设数据具有平滑性,即特征空间相似的示例,其真实标记也应具有相似性。先基于示例特征空间的相似性定义一个相似度矩阵来衡量示例的相似度,传统相似性的度量方法如欧氏距离度量、余弦相似度(cosine similarity)等度量存在着不足。如欧氏距离主要从示例特征值上的差异来体现示例的相似性,但没有考虑两示例特征向量方向上的相似性,余弦相似度更多的是从特征方向上的差异来度量示例的相似性,但却对特征值不敏感。针对以上问题,在部分多标记学习中,本发明采用修正后的夹角余弦值作为相似度,构造出相似度矩阵。利用候选标记集合的信息初始化置信度矩阵,通过迭代传播的方式不断更新置信度矩阵。应用逼近理想解排序法(technique for order preference by similarity to an ideal solution,topsis),根据最优劣贴合的方式提取可信标记集合。至此去除了候选标记集合中噪声标记的影响,解决mll方法不能直接运用到pml的情况。
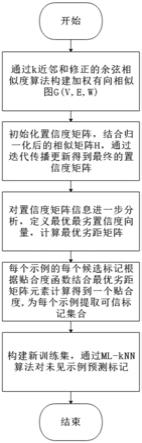
10.参考图1,一种基于最优劣距提取可信标记的部分多标记学习主要步骤如下:
11.步骤s1:利用修正后的余弦相似度式(1)计算示例与其k近邻的相似度,以此初始化加权相似图g(v,e,w)。
12.步骤s2:根据示例候选标记信息初始化置信度矩阵f
(0)
,对步骤s1得来的相似矩阵归一化得到h,利用迭代更新公式(5)来迭代更新得到最终的置信度矩阵f
*
。
13.步骤s3:对步骤s2得到的最终置信度矩阵f
*
进一步分析,根据topsis思想定义(7)、(8)两式。根据(7)、(8)两式从置信度矩阵中提取最优和最劣置信度向量f
+
、f
‑
,将各示例与f
+
、f
‑
作比较,通过(9)、(10)两式计算出最优距和最劣距矩阵
14.步骤s4:利用步骤s3得来的最优最劣距矩阵根据topsis思想定义一个贴合度函数如式(11),为每一示例的每一标记计算一个贴合度,根据贴合度为每一示例提取一个可信标记集合。
15.步骤s5:利用步骤s4得到的可信标记集合,建立新的训练集d
*
,通过ml
‑
knn算法对未见示例预测标记。
附图说明
16.图1为本发明基于最优劣距的部分多标记学习的主要流程图
17.图2步骤s2迭代传播更新标记置信矩阵的流程图
具体实施方式
18.我们主要任务是基于图的标记迭代传播算法来为每个标记确定一个置信度,得到一个置信度矩阵,利用置信度矩阵的信息来定义一个贴合度函数,为每个示例的候选标记计算贴合度,用贴合度从候选标记集合中提取可信标记集合,达到消除噪声标记的影响,使得mll方法能够应用到部分多标记学习。
19.步骤s1:利用修正后的余弦相似度式(1)计算示例与其k近邻的相似度,以此初始化加权相似图g(v,e,w)。具体实施步骤如下:
20.步骤s1.1:根据给定的训练集初始化一个加权有向图。
21.给对于给定的pml训练集其中x
i
=(x
i,1
x
i,2
,
…
,x
i,d
)
t
∈x是d维特征向量示例,是示例x
i
对应的候选标记集合,基于knn算法实例化一个加权有向图g=(v,e,w),其中v={x
i
|1≤i≤m}对应训练集中的示例,为边的集合,表示示例x
i
的k个最近邻示例组成的集合,w
m
×
m
为权重矩阵,各元素初始化为0。
22.步骤s1.2:为权重矩阵w
m
×
m
赋值。
23.通过只考虑x
i
和其近邻示例修正后的夹角余弦值作为相似度赋予权重矩阵每一元素,如下式(1):
[0024][0025]
从(1)式可以看出,对于的示例我们令其和示例x
i
的相似度为0,(1)式中sim<x
i
,x
j
>定义如下式(2):
[0026][0027]
步骤s2:根据示例候选标记信息初始化置信度矩阵f
(0)
,对步骤s1得来的相似矩阵归一化得到h,利用迭代更新公式(5)来迭代更新得到最终的置信度矩阵f
*
。参考图2,步骤s2的具体实施步骤如下:
[0028]
步骤s2.1:对相似度矩阵w
m
×
m
归一化。
[0029]
为了便于后续的迭代标签传播过程,在迭代前先将相似度矩阵w
m
×
m
按列归一化为矩阵h,它的每一元素定义如下式(3):
[0030][0031]
步骤s2.2:初始化置信度矩阵。
[0032]
定义置信矩阵f=[f
i,c
]
m
×
q
,它的每一项f
i,c
≥0代表标记y
c
作为示例x
i
的真实标记的置信度。在迭代传播之前初始化置信度矩阵,记初始的置信度矩阵为;f
(0)
。为使初始标记置信度均匀分布在候选标记集上,令候选标记集合中每个标记的置信度置为候选标记集合以外的标记置信度置为0,每项具体定义如下式(4):
[0033][0034]
步骤s2.3:迭代传播更新置信度矩阵,直至迭代终止。
[0035]
利用当前置信度矩阵f
(t)
和初始的置信度矩阵f
(0)
,通过下式(5)不断迭代更新得到下一个置信度矩阵
[0036][0037]
每一次标记传播过程中当前标记置信度矩阵信息f
(t)
和标记初始化的置信度信息f
(0)
对更新后的置信的矩阵的影响用α∈[0,1]来控制,若每一轮迭代传播过程中更多考虑示例自身的初始化置信度信息,则α越小;若每次迭代中考虑更多的是其近邻示例的标记信息,则α取值越大。每个示例的标记通过其与近邻的相似度来影响相邻示例,每个示例根据其k个近邻示例的标记置信度来更新自身的标记置信度。
[0038]
步骤s2.4:每轮迭代后归一化步骤s2.3得到的新置信度矩阵。
[0039]
每一轮迭代传播后,将得到的置信度矩阵归一化为f
(t+1)
:
[0040][0041]
步骤s2.5:判断是否满足迭代终止条件,即达到预设迭代轮数或连续两轮标记置信度矩阵之间没有显著差异时,迭代标记传播过程结束。
[0042]
步骤s3:对步骤s2得到的最终置信度矩阵f
*
进一步分析,根据topsis思想定义(7)、(8)两式,根据(7)、(8)两式从置信度矩阵中提取最优和最劣置信度向量f
+
、f
‑
,将各示例与f
+
、f
‑
作比较,通过(9)、(10)两式计算出最优距和最劣距矩阵具体实施步骤如下:
[0043]
步骤s3.1:根据迭代结束后得到的最终置信度矩阵f
*
,定义最优置信度向量f
+
和最劣置信度向量f
‑
,具体定义如下(7)(8)两式:
[0044][0045][0046]
其中f
+
的分量表示示例x
i
在置信度矩阵第i行的最优置信度,即示例x
i
在候选标记集合中的最优置信度,f
‑
的分量表示示例x
i
在置信度矩阵第i行的最差置信度,即示例x
i
在候选标记集合中的最差置信度。
[0047]
步骤s3.2:根据最优和最劣置信度向量和示例自身的标记置信度向量定义最优距矩阵和最劣距矩阵其第i行第j列元素分别定义如下:
[0048][0049][0050]
最优距矩阵的元素表示示例x
i
的标记y
c
的置信度与示例x
i
的候选标记集合中标记的最优置信度的差距,值越小越好,表明标记y
c
离理想的置信度的差距越小,即成为真实标记的可能性越大。同理最劣距矩阵的元素表示示例x
i
的标记y
c
的置信度与示例x
i
的候选标记集合中标记的最差置信度的差距,值越大越好,表明标记y
c
离最不理想的置信度的差距越大,即成为真实标记的可能性越大。
[0051]
步骤s4:利用步骤s3.2得来的最优最劣距矩阵根据topsis思想定义一个贴合度函数如式(11),为每一示例的每一标记计算一个贴合值,根据贴合值为每一示例提取一个可信标记集合,具体实施步骤如下:
[0052]
步骤s4.1:计算示例对应的贴合向量。
[0053]
利用步骤s3.2得到的最优距矩阵和最劣距矩阵,定义一个贴合度函数用此函数为训练集中示例x
i
的候选集合中的标记y
c
∈y
i
计算出一个贴合值
[0054][0055]
贴合值的取值范围为[0,1],值越大越好,值越接近于1,说明示例x
i
的标记y
c
越贴合示例x
i
的真实标记,则x
i
对应的标记贴合向量可记为:
[0056]
步骤s4.2:根据贴合向量提取可信标记集合。
[0057]
x
i
的可信标记集合可由步骤s4.1的贴合向量λ
i
和阈值θ确定,如下式(12):
[0058][0059]
x
i
可信标记集合由贴合度大于阈值θ的标记组成,为避免可信标记集合为空的情况,公式后一项取贴合度最大的那个标记也加入可信标记集合中。
[0060]
步骤s5:步骤s4的完成,我们实现了对候选标记集合的去噪,至此我们就可以使用现有的多标记算法为未见示例预测标记。本发明利用步骤s4得到的可信标记集合,建立新的训练集s,通过ml
‑
knn算法对未见示例预测标记,具体实施步骤如下:
[0061]
步骤s5.1:构建新的训练集。
[0062]
利用步骤s4.2得到的可信标记集合,构造新的训练集
[0063]
步骤s5.2:在新训练集中,用ml
‑
knn为每个示例确定k个近邻和统计量
[0064]
步骤s4.2完成后,我们基本实现了对候选标记集合去噪的工作,此时再在新训练集合中运用mll算法是可行的,选用一个成熟的ml
‑
knn算法利用新训练集的完成对未见示例的预测工作。假设表示新训练集d
*
中示例x
i
的k个最近邻示例。定义统计量:
[0065][0066]
其中是指示函数,当π=true时,取值为1,否则为0。表示新训练集中示例x
i
的k个近邻示例对应的标记集合中包含标记y
j
的近邻示例个数。
[0067]
步骤s5.3:ml
‑
knn算法如式(14)利用最大后验概率对未见示例x
i
进行预测:
[0068][0069]
其中表示示例是否x
i
具有标记y
j
的事件。当b=1表示具有,反之不具有。表示示例x
i
的k个近邻中有个示例具有标记y
j
的事件。
[0070]
其中上式(14)中的先验概率和条件概率都可在新的训练集中事先估计预测得到。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1