一种序列化多线程数据处理系统的制作方法
本发明涉及数据处理技术领域,尤其具体涉及一种序列化多线程数据处理系统。
背景技术:
以大数据应用中的机器学习为例,计算机需要识别一幅图片中的苹果,则就需要学习多张图片中的苹果,并分析和提炼出共同的相似特征以确实是否是苹果。这样学习的越多,识别越精准,但是其对数据的处理要求也就越高。
由上可知,机器学习的过程是需要以处理大量的数据为前提的,面对海量的庞大数据资源,如何快速有效地管理数据加载处理就是我们需要面临的问题。传统的方法是采用多线程方式进行数据加载,即多线程数据处理方法允许同时执行多个线程,通常在允许进行调试操作的软件开发期间使用调试指令。然而传统的多线程数据加载方法虽然在一定方面有利于数据加载,提高了数据处理速度,但是其对将要加载的数据没有进行有效分析,对进行多线程加载的服务器的各个通道处理能力也没有进行区分调度管理不够,经常就会造成某些通道处理的快,有些通道处理的能力慢,造成数据加载时间长,等待时间过多,甚至造成某些通道的加载死机,内存溢出等诸多服务器错误。
现有技术中的多线程加载数据经常出现每个线程都在给客户端返回数据,用户所看到的数据类似洗牌后数据,数据非序列化排列;每个线程都在读取数据,数据在过程中发生变化,则会造成服务器数据为1~5、10~20,中间由于无同步化的数据加载造成用户展示的数据为1~20。
现有技术中的顺序加载数据在面临数据量过大导致死机、内存溢出、蓝屏等死机情况。现有数据中的分段加载数据需要用户点击“下一页”的此类操作才能完成对于后续数据的加载,其操作繁琐。
现有技术中以大数据应用中语音识别为例,在机器学习过程中需要大量的语言、发音的数据样本,学习计算机和数据源计算机一般不会是同一台计算机,数据样本需要通过加载的方式供学习计算机学习。学习过程计算机会对数据进行读取、分析、保存数据,而这个过程漫长。由于数据读取会对数据源计算机cpu、内存、硬盘产生性能消耗,时间越久次数越多,计算机本身就会越热,可能会造成性能占用高、蓝屏、死机等诸多电器元器件错误现象。学习计算机由于一般不会由一台计算机完成,会由一个学习计算机集群进行,如果采用传统数据记载,势必会造成学习计算机集群性能过剩,大部分学习计算机无足够数据分析学习,从而造成资源和性能浪费。
因此,急需研发出能够快速有效的管理多线程加载过程,避免传统多线程加载数据过慢或者无序、数据无法同步、甚至数据加载错误的现象出现的多线程数据处理系统。
技术实现要素:
本发明的目的在于提供一种序列化多线程数据处理系统,其可以满足以亿兆为单位的企业级数据多线程加载,且不会出现导致计算机死机,内存溢出、蓝屏等现象。同时,通过序列化多线程技术对数据加载过程进行管控,有效提高数据加载性能和速度。
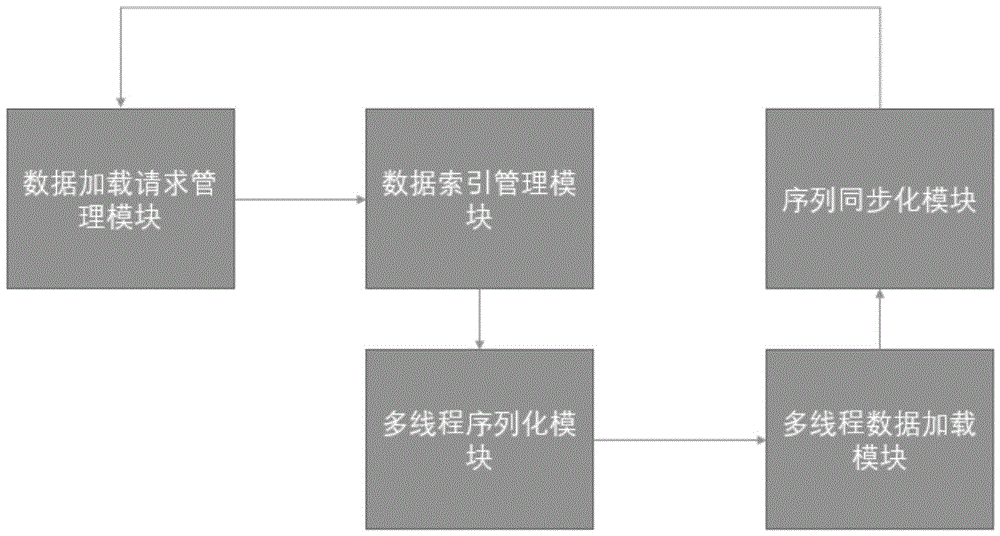
为实现上述目的,本发明提供如下技术方案:一种序列化多线程数据处理系统包括:
数据加载请求管理模块,用于对待加载数据进行解析和处理后形成数据加载请求信息包,并将该数据加载请求信息包向数据索引管理模块发起发送指令;
数据索引管理模块,用于根据多线程序列化模块的解析分析结果,向多线程数据加载模块发起数据加载指令,并管控多线程数据加载过程;
多线程序列化模块,用于根据加载数据的服务器的处理数据能力,对待加载数据进行多线程序列化;
多线程数据加载模块,用于根据数据索引管理模块和多线程序列化模块的解析对待加载数据进行序列化加载;
序列化同步模块。用于对多线程加载后的数据进行同步数据恢复,同步还原数据,完成数据的加载。
优选地,所述数据加载请求管理模块的数据加载请求信息包由请求标识编码、数据特征码、数据量范围、数据索引值、数据同步值、数据加载值构成;请求标识编码为用户终端唯一标识,数据特征码为数据类型,数据量范围包括数据关键字、数据关键信息或者数据关键识别码,数据索引值为数据起始点,数据同步值为数据同步节点,数据加载值为数据加载进度。
优选地,所述数据类型为文本数据、图像数据或视频数据。
优选地,所述数据索引管理模块包括数据请求接收模块、数据请求分析模块、数据索引存储模块、数据索引计算模块、数据索引集;数据请求接收模块接收数据加载请求管理模块发送的数据加载请求信息包,并根据多线程序列化模块和多线程数据加载模块的进度进行实时更新;数据请求分析模块对数据加载请求信息包进行识别,并解析为对应数据库地址、数据库、数据表;数据索引计算模块依据数据特征码、数据量范围、数据索引值、数据同步值、数据索引进行实时计算,建立形成数据索引集;数据索引储存模块根据数据库地址、数据库、数据表,读取数据索引信息,并动态实时更新数据索引信息。
优选地,所述多线程序列化模块包括数据索引集分解模块、线程准备模块、数据序列化管理线程、数据多线程序列化模块、线程序列启动模块、多线程监测模块;数据索引集分解模块根据收到数据索引集的体量进行性能需求计算,依据cpu数量、硬盘读取速度、传输速度进行分解多个数据索引子集,并根据配套的多线程需求量将多线程pid与数据索引子集匹配,建立数据帧单元;线程准备模块依据线程需求量进行线程准备,即通知多线程序列化模块线程进行线程编号1,2,3,4,5(线程编号过程中以cpu的pid为特征进行序列化顺序编号)……准备完成后,启动数据序列化管理线程,监控所有序列化模块线程;数据序列化管理线程对于停止、锁死、中断异常情况,依据线程编号进行线程重启。
优选地,所述线程准备过程包括:数据多线程序列化模块加载分派读取数据帧单元序列号、读取数据库地址、数据库、数据表、子索引集信息;线程序列启动模块通知多线程数据加载模块执行启动单元,依据数据序列化管理线程指令启动线程,通知多线程监测模块进行线程监测;多线程监测模块依据线程编号、线程状态进行实时监测,并将检测信息反馈给数据序列化管理线程。
优选地,所述多线程数据加载模块包括线程响应模块、加载线程编码模块、线程启动准备模块、线程执行模块、线程关闭模块、线程恢复模块;线程响应模块响应来自线程序列启动模块指令,启动指令、关闭指令、恢复指令,并反馈线程状态信息;加载线程编码模块依据数据类型完成对数据加载,并对文字类型数据、图像类型数据、视频类型数据编码化;线程执行模块执行线程开始命令完成cpu线程启动;线程关闭模块用于执行线程关闭命令完成cpu线程关闭;线程恢复模块用于执行线程重启命令完成cpu线程重启。
优选地,所述序列化同步模块包括多线程序列化目录、多线程数据侦测模块、多线程同步管理模块、同步加载模块、同步变更模块、同步恢复模块;多线程序列化目录接收来自数据索引集分解模块的数据帧单元标识;多线程数据侦测模块启动同步线程,依据数据帧单元标识对序列线程编码进行数据重组;多线程同步管理模块依据线程编码读取线程执行数据信息;同步加载模块依据数据请求分析模块数据类型进行数据编码,将获取的数据恢复成用户可读取数据;同步变更模块用于检测错位数据,依据序列化模块进行变更修正数据;同步恢复模块将对意外终止线程数据发送恢复请求数据序列化管理线程,数据序列化管理线程执行线程恢复模块,完成对应线程恢复;恢复后的非序列化数据交由同步变更模块,如变更数据未形成完整数据,即由同步加载模块重新加载为用户可阅读数据。
优选地,所述数据帧单元标识包含数据分解后的数据索引和对应线程编码信息。
优选地,所述线程编码信息为对应cpu中的pid信息。
与现有技术相比,本发明的有益效果如下:
1、本发明的序列化多线程数据处理系统可以满足以亿兆为单位的企业级数据多线程加载,且不会出现导致计算机死机,内存溢出、蓝屏等现象。同时,通过序列化多线程技术对数据加载过程进行管控,有效提高数据加载性能和速度。在一定条件下,可将数据加载性能提高2倍以上。同时序列化后的多线程数据加载,根据按需进行数据加载,也不会造成性能浪费。
2、本发明序列化多线程数据处理系统的通过序列化管理建立多线程的序列化数据加载过程;通过同步管理的多线程加载技术,建立加载和被加载数据的同步化。本发明通过建立同步序列化数据信道,数据传输信道,全程对大数据自动加载的过程,可应用于客户端对服务器存储的大数据进行分析。
3、本发明序列化多线程数据处理系统可以分散管理在多个硬盘、多个数据库、多个数据表中的大体量数据,统一进行多线程数据索引管理。本发明依据服务器cpu、硬盘、网络、索引集的性能,优化数据加载,序列化分多线程管理数据加载过程。
4、本发明序列化多线程数据处理系统采用数据监测同步化技术,围绕多线程数据加载过程,采取保护措施,避免由于通信、报错、序列化顺序错位所导致的数据错误,在加速数据读取的同时,保障了数据的正确性。
5、本发明序列化多线程数据处理系统的能更加有效快速的对大数据进行序列化后分派给多线程进行数据加载,完成快速数据加载,可适用于大数据运算、机器学习、渲染场景、业务分析等场景。
附图说明
图1为本发明序列化多线程数据处理系统的结构示意图。
图2为本发明数据加载请求管理模块的结构示意图。
图3为本发明数据索引管理模块的结构示意图。
图4为本发明多线程序列化模块的结构示意图。
图5为本发明数据帧单元建立过程的结构示意图。
图6为本发明多线程数据加载模块的结构示意图。
图7为本发明序列化同步模块的结构示意图。
图8为本发明数据重组的结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
在发明的描述中,需要说明的是,术语“上”、“下”、“内”、“外”“前端”、“后端”、“两端”、“一端”、“另一端”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性。
在发明的描述中,需要说明的是,除非另有明确的规定和限定,术语“安装”、“设置有”、“连接”等,应做广义理解,例如“连接”,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通。对于本领域的普通技术人员而言,可以具体情况理解上述术语在本发明中的具体含义。
如图1所示,一种序列化多线程数据处理系统包括:数据加载请求管理模块、数据索引管理模块、多线程序列化模块、多线程数据加载模块、序列化同步模块。
如图2所示,数据加载请求管理模块的数据加载请求信息包由请求标识编码、数据特征码、数据量范围、数据索引值、数据同步值、数据加载值构成。请求标识编码是标志用户及终端系统唯一标识(可以是用户id、信息系统、系统功能、功能数据特征关键字、功能数据范围关键字。例如user账号,使用《财务系统》中《发票数据分析》,分析2016年至今全部数据的数据特征——发票数据(关键字)数据范围——2016年、至今(关键字)),是数据加载通信过程的唯一标识,保障了数据安全性。数据特征码标志数据类型,如文本数据、图像数据、视频数据等。数据量范围是标志着数据关键字、关键信息、关键识别码,如订单中的性别男、图像数据中的红色、视频数据中的时长等。数据索引值是数据起始点,标志着数据从哪里开始进行加载。数据同步值标志着数据同步节点,是否继续进行通信。数据记载值标志着数据加载进度。完成数据加载请求信息包后,交由数据加载请求管理模块进行发送。
如图3所示,数据索引管理模块包括数据请求接收模块、数据请求分析模块、数据索引存储模块、数据索引计算模块、数据索引集。数据请求接收模块接收数据加载请求管理模块发送的数据加载请求信息包,随着多线程序列化模块、多线程数据加载模块的进度而进行时时更新,保障数据进行有效加载。数据请求分析模块,识别数据加载请求信息包信息,解析为对应数据库地址、数据库、数据表。数据索引储存模块,根据数据库地址、数据库、数据表,读取数据索引信息,并用于更新最新的数据索引,动态实时更新。数据索引计算模块,依据数据特征码、数据量范围、数据索引值、数据同步值、数据索引进行实时计算,建立形成数据索引集。
如图4所示,多线程序列化模块包括数据索引集分解模块、线程准备模块、数据序列化管理线程、数据多线程序列化模块、线程序列启动模块、多线程监测模块。数据索引集分解模块,将按照收到的数据索引集体量进行性能需求计算,依据cpu数量、硬盘读取速度、传输速度进行分解多个数据索引子集,根据配套的多线程需求量将将多线程pid与数据索引子集匹配建立数据帧单元。
如图5所示,即数据帧单元建立过程为:
第一步:分解成多个数据索引子集;
第二步:计算配套的多线程需求量;
第三步:将多线程pid与数据索引子集配,建立数据帧单元;数据帧单元是将大数据总量(及时时增量)按照服务器cpu、内存、硬盘读写性能定义的子数据量。例如:数据总量1亿条,数据帧单元1:cpu-a:670万条;cpu-b:830万条;cpu-c:1000万条;数据帧单元2:cpu-a:550万条;cpu-b:990万条;cpu-c:330万条。线程准备模块,依据线程需求量进行线程准备,通知多线程序列化模块线程1,2,3,4,5....准备完毕,启动数据序列化管理线程,监控所有序列化模块线程。准备过程包含数据多线程序列化模块、线程序列启动模块、多线程监测模块。数据多线程序列化模块,加载分派读取数据帧单元序列号、读取数据库地址、数据库、数据表、子索引集信息。线程序列启动模块(通知多线程数据加载模块执行启动单元),依据数据序列化管理线程指令启动线程,通知多线程监测模块进行线程监测。多线程监测模块,依据线程编号、线程状态进行实时监测,并将检测信息反馈给数据序列化管理线程,进行管理。数据序列化管理线程,对于停止、锁死、中断等情况,依据线程编号进行线程重启。
如图6,多线程数据加载模块包括线程响应模块、加载线程编码模块、线程启动准备模块、线程执行模块、线程关闭模块、线程恢复模块。线程响应模块,响应来自线程序列启动模块指令,启动指令、关闭指令、恢复指令,并反馈具体线程状态信息。加载线程编码模块,依据数据完成对数据加载,文字类型数据、图像类型数据、视频类型数据编码化。线程执行模块,执行线程start命令完成cpu线程启动。线程关闭模块,执行线程stop命令完成cpu线程关闭。线程恢复模块构成,执行restart命令完成cpu线程重启。
如图7,序列化同步模块包括多线程序列化目录、多线程数据侦测模块、多线程同步管理模块、同步加载模块、同步变更模块、同步恢复模块。
多线程序列化目录接收来自数据索引集分解模块中序列化的数据帧单元标识。
数据帧单元标识包含数据分解后数据索引和对应线程编码信息。数据帧单元标识,包含数据帧单元序列号、读取数据库地址、数据库、数据表、子索引集信息、线程编号(以cpu的pid为特征,对cup进行了顺序编号1、2、3、4、5……)、数据特征码、数据类型。线程编码信息是带有序列化了(1、2、3、4、5……)的对应cpu中pid信息,通过pid信息通知后续的同步加载模块、同步变更模块、同步恢复模块对数据进行加载。
多线程数据侦测模块,启动同步线程,依据数据帧单元标识对于序列线程编码进行数据重组。即以序列化的形式有管理的对数据进行重组,而不是像传统多线程加载方式的先到先组合。
如图8所示:依据数据帧单元标识中的序列线程编码(数据帧单元1、数据帧单元2、数据帧单元3、数据帧单元4)进行数据重组的具体过程为:
多线程数据加载模块,启动多线程数据侦测模块。
多线程数据侦测模块,启动同步线程与多线程同步管理模块。
多线程数据侦测模块(同步线程),时时接收来自数据帧单元线程返回的数据信息包。
多线程同步管理模块依据索引子集目录,比对数据帧单元标识,对同步线程中的数据信息包进行序列数据重组。
多线程同步管理模块,依据数据帧单元标识中的线程编码(以cpu的pid为特征,对cup进行了顺序编号1、2、3、4、5……)读取线程执行数据信息。同步加载模块将获取的数据,依据数据请求分析模块数据类型进行数据编码恢复成用户可读取数据,如文字数据、图像数据、视频数据。同步变更模块,将检测数据帧单元标识错位数据,依据序列化模块进行变更处理。
同步恢复模块将对意外终止多线程数据侦测模块的同步线程,发送恢复请求,重启多线程数据侦测模块的同步线程多线程同步管理模块,完成对应线程恢复。恢复后的非序列化数据交由同步变更模块,变更数据没有形成完整数据,再由同步加载模块重新加载为用户可阅读数据。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!