一种基于特征对齐和关键点辅助激励的目标检测方法与流程
本申请属于图像处理
技术领域:
,具体涉及一种基于特征对齐和关键点辅助激励的目标检测方法。
背景技术:
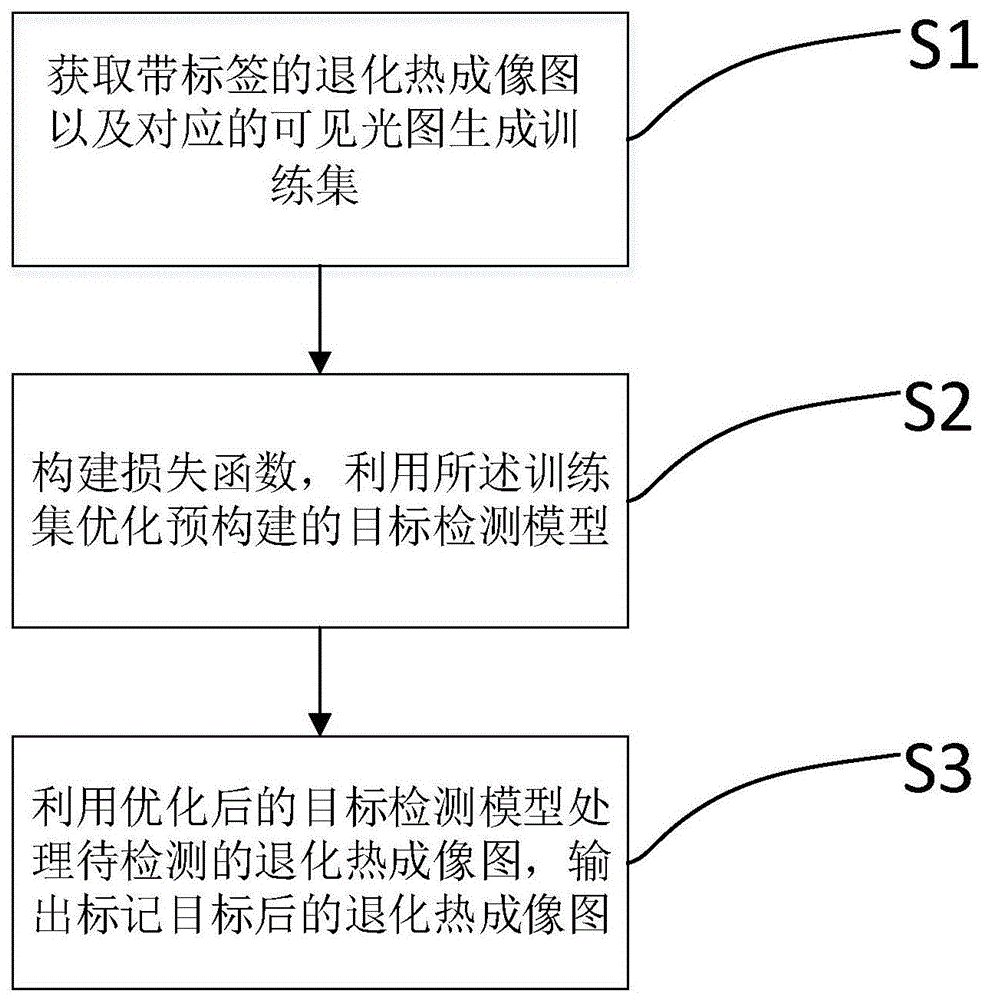
:由于热成像在恶劣天气(黑夜、雨雪、大雾)下的稳定性,热成像图目标检测已经广泛应用于全天候自动驾驶,工业安保和国防军事领域。虽然现阶段热成像图目标检测已经取得了长足的发展,但是仍然存在一些问题。首先,热成像图存在低对比度,高噪声和单一颜色空间的退化现象。现有方法为了从退化热成像图中提取更多特征,往往采用图像预处理和特征融合的策略,此策略虽然能在一定程度上提升退化热成像图目标检测的精度,但是模型依赖融合后的特征进行后续检测。其次,退化热成像图中的目标边界模糊,而且现有深度学习方法网络高层细节信息不足,导致模型很难准确定位到热成像目标。最后,主流方法预定义的锚点框,并不能很好地覆盖热成像目标,导致模型检测精度不高。退化热成像图目标检测方法可分为传统机器学习方法和基于深度学习的方法。传统机器学习方法主要通过手工提取目标特征和使用分类器进行检测。例如引入lbp进行目标纹理分类,然后使用hog提取特征,最后运用svm进行检测。还有使用稀疏字典来分别计算退化热成像图的前景与背景,通过计算样本与稀疏表示之间的差异来进行加进行检测。传统机器学习方法能达到的精度有限,而且速度不快,很难实现大规模的商业化应用。随着计算机硬件技术的发展和深度学习的崛起,基于卷积神经网络的端到端的方法成为主流方法。受益于卷积神经网络的细节、语义信息提取和多尺度预测,基于此方法的检测精度大大高于传统机器学习方法。现阶段大部分基于深度学习的方法主要采取的策略是特征融合与域适应。特征融合算法主要通过融合可见光图特征与退化热成像图特征来进行训练和检测,该策略弥补了退化热成像图中特征不足的问题,检测精度相比基准也有所提高,但是应用该策略的模型对融合特征有较强的依赖性(在模型训练和检测阶段均需要融合特征)。域适应方法是通过将图像进行迁移变换,从而拉近可见光域与热成像域之间的距离,此策略能取得较高的检测精度,但是模型设计相对复杂。技术实现要素:本申请的目的在于提供一种基于特征对齐和关键点辅助激励的目标检测方法,其检测精度高,定位热成像目标精准,可拓展性强。为实现上述目的,本申请所采取的技术方案为:一种基于特征对齐和关键点辅助激励的目标检测方法,用于基于退化热成像图进行目标检测实现目标定位,所述基于特征对齐和关键点辅助激励的目标检测方法,包括:步骤s1、获取带标签的退化热成像图以及对应的可见光图生成训练集;步骤s2、构建损失函数,利用所述训练集优化预构建的目标检测模型;步骤s3、利用优化后的目标检测模型处理待检测的退化热成像图,输出标记目标后的退化热成像图;其中,所述目标检测模型基于yolov3模型构建,所述目标检测模型包括骨干网络、特征对齐单元、网络优化单元和检测网络;所述骨干网络采用yolov3模型的darknet53网络,所述darknet53网络共有75层,其中包含53个卷积层,75层依次命名为layer-0至layer-74,在layer-0至layer-74中,前一层的输出作为后一层的输入,所述退化热成像图作为darknet53网络的输入;所述特征对齐单元包括31层,31层与darknet53网络的前31层,即layer-0至layer-30层相同,所述特征对齐单元的输入为与退化热成像图对应的可见光图,所述骨干网络的layer-30层的输出和特征对齐单元layer-30层的输出进行对齐,对齐后的特征再输入骨干网络的layer-31层;所述网络优化单元包括特征图级联单元,所述特征图级联单元接收骨干网络layer-4层输出的特征,然后将该特征进行下采样并与骨干网络layer-11层输出的特征进行通道叠加得到特征c1,接着将叠加后的特征c1送入1×1卷积层,减少通道数至一半,然后进行下采样并与骨干网络layer-36层输出的特征进行通道叠加特征c2,接着将上一步叠加得到的特征c2送入1×1卷积层,减少通道数至一半,再次下采样并与骨干网络layer-61层输出的特征进行通道叠加得到特征c3,将特征c1、特征c2、特征c3输入检测网络;所述检测网络包括3个辅助检测器和3个yolo检测器,辅助检测器和yolo检测器输出的检测结果合并后得到标记目标后的退化热成像图;所述辅助检测器包括关键点辅助激励单元和全卷积一步分类回归单元,所述关键点辅助激励单元接收特征图级联单元输出的对应特征,首先将该特征在通道维度上进行平均,其次将平均后的特征乘以基于目标关键点的二值图,然后将上一步得到的特征乘以系数因子α,接着将乘以系数因子α后的特征叠加到特征图级联单元输出的对应特征的每个通道上,最后得到的特征作为所述关键点辅助激励单元的输出;所述全卷积一步分类回归单元接收关键点辅助激励单元输出的特征,该特征被送入两个分支中,每个分支包含4个卷积层,第一个分支计算分类和特征上每个位置的中心度,第二个分支回归特征上每个位置到预测的目标矩形框四边的距离(l,t,r,b),将两个分支预测得到的分类、每个位置的中心度以及每个位置到预测的目标矩形框四边的距离(l,t,r,b)作为辅助检测器的输出。以下还提供了若干可选方式,但并不作为对上述总体方案的额外限定,仅仅是进一步的增补或优选,在没有技术或逻辑矛盾的前提下,各可选方式可单独针对上述总体方案进行组合,还可以是多个可选方式之间进行组合。作为优选,所述yolo检测器预测(x,y,w,h,c),其中x为预测目标中心点的横坐标,y为预测目标中心点的纵坐标,w为预测的目标矩形框的宽度,h为预测的目标矩形框的高度,c为预测的目标的分类。作为优选,所述3个yolo检测器包括接收layer-36层通道叠加的特征c2的52×52的检测器,接收layer-61层通道叠加的特征c3的26×26的检测器,以及接收layer-4层和layer-11层通道叠加后的特征c1的104×104的检测器。作为优选,所述标记目标后的退化热成像图中采用关键点标记目标,每个目标包含5个关键点,5个关键点分别为一个目标的中心点,以及取自目标中心点十字交叉线上的四个点。作为优选,所述步骤s2中利用所述训练集优化预构建的目标检测模型,包括:基于所述训练集,采用随机梯度下降法优化目标检测模型。作为优选,所述构建损失函数,包括:l=lfam+lyolo+laux式中,l为所构建的损失函数,lfam为特征对齐损失,lyolo为yolov3损失,laux为辅助检测器损失;其中,所述特征对齐损失lfam的公式如下:lfam=(tf-vf)2式中,tf是特征对齐单元layer-30层输出的特征图,vf是骨干网络layer-30层输出的特征图;其中,yolov3损失lyolo定义如下:lyolo=lx+ly+lw+lh+lconf+lcls式中,(lx,ly,lw,lh)分别代表预测的目标矩形框中心点坐标(x,y)、预测的目标矩形框宽和高的损失,lconf代表置信度损失,lcls代表分类损失;其中,(lx,ly,lw,lh)采用均方误差(meansquareerror,mse),公式如下:式中,tx为预测的目标矩形框的中心点x坐标相对于该中心点所在网格左上角点x坐标的偏移量,gx为根据真实标签计算出的目标矩形框的中心点x坐标相对于中心点所在网格左上角点x坐标的偏移量,ty为预测的目标矩形框的中心点y坐标相对于该中心点所在网格左上角点坐标的偏移量,gy为根据真实标签计算出的目标矩形框的中心点y坐标的偏移量,tw为真实标签中目标矩形框的宽度,gw为预测的目标矩形框的宽度,th为真实标签中目标矩形框的高度,gh为预测的目标矩形框的高度;其中,lconf和lcls采用二分类交叉熵(binarycrossentropy,bce),具体公式如下:lconf、cls=yilogxi+(1-yi)log(1-xi)式中,xi表示第i个样本预测为正样本概率,yi表示第i个样本的分类;其中,所述辅助检测器损失laux定义如下:laux=ll+lt+lr+lb+lc+lctn其中,(l,t,r,b)代表特征上每个位置到预测的目标矩形框四边的距离,c代表分类,ctn代表每个位置到目标中心点的中心度;其中,(l,t,r,b)采用giou计算,公式如下:其中,iou表示真实标签中目标矩形框和预测的目标矩形框交集和并集的比值(交并比),ac表示包围真实标签中目标矩形框和预测的目标矩形框的最小框的面积,u表示真实标签中目标矩形框和预测的目标矩形框的并集面积;lctn采用bcewithlogitsloss计算;lc采用focalloss来计算,lc定义为:其中,y为真实值,y′为预测值,α和γ分别取值0.25和2。本申请提供的基于特征对齐和关键点辅助激励的目标检测方法,与现有技术相比,具有以下有益效果:(1)本申请的目标检测模型包括骨干网络,特征对齐单元,网络优化单元和检测网络,利用卷积神经网络进行特征提取和预测,实现了输入待检测图像即可获得检测结果,使得整个模型实现了端到端的训练和检测。(2)本申请在骨干网络部分加入了特征对齐单元,通过对指定层可见光图特征和退化热成像图特征进行差异计算,来缩小两域之间的差距,从而辅助骨干网络进行特征学习,提高目标检测模型的检测精度。(3)本申请在骨干网络部分加入特征图级联单元,在检测网络修改检测尺度。通过上述优化,网络更低层的细节信息将通过连接被传输到网络高层,从而提高模型定位热成像目标的能力。(4)本申请在检测网络中加入包含关键点辅助激励的辅助检测器,该检测器与原始检测器配合使用。关键点辅助激励增加模型定位热成像目标能力,辅助检测器帮助模型学习那些锚点框覆盖较差的实例。附图说明图1为本申请的基于特征对齐和关键点辅助激励的目标检测方法的流程图;图2为本申请的基于特征对齐和关键点辅助激励的目标检测方法的框架图;图3为本申请特征图级联单元和检测尺度修改的示意图;图4为本申请辅助检测器的结构示意图。具体实施方式下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。除非另有定义,本文所使用的所有的技术和科学术语与属于本申请的
技术领域:
的技术人员通常理解的含义相同。本文中在本申请的说明书中所使用的术语只是为了描述具体的实施例的目的,不是在于限制本申请。其中一个实施例中,提供一种基于特征对齐和关键点辅助激励的目标检测方法,针对退化热成像图可实现精确、快速的目标检测。基于本申请检测到的标记目标后的退化热成像图可以对工业领域的作业人员的位置进行实时监控,确保人员安全;可以对指定防控领域的闲散人员位置进行标记,防止群众聚集;可以对军事领域的可疑人员进行布控,阻止非法分子越境;可以对自动驾驶领域的行人进行定位,实现汽车对行人的自动避让等。如图1所示,本实施例中的基于特征对齐和关键点辅助激励的目标检测方法,包括以下步骤:步骤s1、获取带标签的退化热成像图生成训练集。为了得到具有针对性的目标检测模型,通常需要获取相关图像对模型进行训练,直至模型达到预想的输出效果。在模型训练中需要准备足够量的样本图像,通常样本图片可以是直接使用现有的数据集,也可以是自行获取并标注图片后生成样本图片。为了保证训练数据的有效性,本实施例提供两种训练集和测试集生成方法如下。a、数据样本准备获取现有的kaist退化热成像标签数据集,该数据集包含95000对可见光图和退化热成像图,仅包含“人”一个分类。获取现有的flir-adas退化热成像标签数据集,该数据集包含14452对可见光图和退化热成像图,其中10288对为短片取样。这里使用该数据集的3个分类(“人”,“车”和“自行车”)。b、训练集、测试集准备采用kaist数据集中的22134对可见光图和退化热成像图用作训练集,9982张热成像图用做测试集。采用fliradas数据集短片取样中的7860对可见光图和退化热成像图用作训练集,1366张热成像图做测试集。c、数据增强退化热成像图数据集数量远少于传统可见光图数据集,且数据集内样本数量较少,场景的场景单一。为了防止训练数据过拟合,提升模型的泛化能力,这里采用三种数据增强方式:翻转、旋转、缩放。需要指出的是,数据增强为常用技术,这里就不对各项操作的具体步骤进行说明。步骤s2、构建损失函数,利用所述训练集优化预构建的目标检测模型。如图2所示,本实施例使用的目标检测模型主要基于yolov3模型,它包含骨干网络,特征对齐单元,网络优化单元和检测网络。可见光图和退化热成像图被分别送入骨干网络和特征对齐单元,两图特征在layer-30层进行对齐,对齐后的特征被送入网络优化单元,经过网络优化单元后的特征被送入检测网络进行目标预测。检测网络包含3个原始yolo检测器和3个无锚点辅助检测器。两类检测器的预测结果合并后即可作为目标检测模型的输出,但本实施例为了进一步提升预测结果,两类检测器的预测结果合并后被送入非极大抑制(non-maximumsuppression,nms)进行筛选,得到最终的预测结果。以下分别介绍本实施例目标检测模型中的各个模块。a、骨干网络骨干网络采用yolov3模型的darknet53网络。通过类似于残差网络结构的前后连接,darknet53网络在特征提取上相比于传统的网络结构有很大的优势。本实施例中的darknet53网络根据特征图的大小分为六个阶段。以输入图像大小416×416为例,具体阶段为:阶段0(416×416),阶段1(208×208),阶段2(104×104),阶段3(52×52),阶段4(26×26),阶段5(13×13)。本实施例通过加载在imagenet上预训练过的权重,避免网络从零开始训练。本实施例中骨干网络的具体结构为:采用darknet53网络提取退化热成像图特征,所述darknet53网络共有75层,其中包含53个卷积层,75层依次命名为layer-0至layer-74,在layer-0至layer-74中,前一层的输出作为后一层的输入,所述退化热成像图作为darknet53网络的输入。这里提及的darknet53网络为yolov3模型中的原始darknet53网络,darknet53网络本身为现有网络,这里就不再对网络的结构内容展开赘述。b、特征对齐单元如图2左上角所示,为了缩小热成像域与可见光域之间的差距,本实施例中引入特征对齐单元。特征对齐单元包括31层,31层与darknet53网络的前31层,即layer-0至layer-30层相同,特征对齐单元的输入为与退化热成像图对应的可见光图,所述骨干网络的layer-30层的输出和特征对齐单元layer-30层的输出进行对齐,对齐后的特征再输入骨干网络的layer-31层。在特征对齐时,特征对齐单元将两个层的输出进行相似度计算,得到一个差值,并基于这个差值进行特征对齐,通过简单的相似度计算,两个特征之间的差距被逐渐缩小,模型在两域之间的泛化能力进一步提升,检测精度也随之提高。c、网络优化单元yolov3模型在公共数据集上取得了较高的检测精度,但是该模型仍然存在缺陷:其网络高层语义信息丰富,但是细节信息缺乏。这导致模型在检测时不能很好地定位目标。基于热成像图的退化现象,该问题会在退化热成像图目标检测中被放大。为了解决上述问题,本实施例使用网络优化单元来丰富网络高层的细节信息。具体的,本实施例中的网络优化单元包括特征图级联单元和检测尺度修改。特征图级联单元接收layer-4层输出的特征,然后将骨干网络各个阶段的特征进行通道叠加。即特征图级联单元以阶段1的layer-4为起始层(图3左上角虚线框),将该层的输出特征送入核大小(kernelsize)为3×3和步长(stride)为2的卷积块进行下采样,得到大小为104×104×128的特征图。将此特征图和阶段2最后一层(layer-11)输出的特征图进行通道叠加(concatenation),得到104×104×256的特征图(即特征c1)。通道叠加后的特征图被送入核为1×1的卷积块来减少通道数至128(减少网络参数量),然后输入核大小(kernelsize)为3×3和步长(stride)为2的卷积块进行下采样,得到大小为52×52×256的特征图,将此特征图和阶段3最后一层(layer-36)输出的特征图进行通道叠加,得到52×52×512的特征图(即特征c2)。通道叠加后的特征图被送入核为1×1的卷积块来减少通道数至256(减少网络参数量),然后输入核大小(kernelsize)为3×3和步长(stride)为2的卷积块进行下采样,得到大小为26×26×512的特征图,将此特征图和阶段4最后一层(layer-61)输出的特征图进行通道叠加,得到26×26×1024的特征图(即特征c3)。从结构角度看,特征图级联单元包括依次连接的核大小为3×3、步长为2的卷积块a(用于下采样),核大小为1×1、步长为1的卷积块b(用于减少通道数),核大小为3×3、步长为2的卷积块c(用于下采样)。其中卷积块a与layer-4连接,卷积块b与layer-11连接,卷积块c与layer-36连接。后续阶段的网络结构和上述网络结构相似。通过以上操作,骨干网络中低层的细节信息被尽可能地保留下来,以丰富后续高层的细节信息。检测尺度修改基于原始的yolov3模型进行,首先将已经和layer-36通道叠加的特征c2连接至第三(52×52)检测层。然后将已经和layer-61通道叠加的特征c3连接至第二(26×26)检测层。接着,在原有第三检测层之后新增大小为104×104的检测层,将layer-4和layer-11通道叠加后的特征c1连接至新增检测层(图3左下角虚线框)。新增检测层的网络参照原始检测层设计。最后为了防止模型臃肿,删除原有的阶段5网络层和原有的第一(13×13)检测层(图3右侧带叉的虚线框)。通过上述优化,更低层细节信息通过连接捷径传输到高层。d、检测网络检测网络包含3个yolo检测器和3个辅助检测器,辅助检测器和yolo检测器输出的检测结果合并后得到标记目标后的退化热成像图。经过检测尺度修改,本实施例中的3个yolo检测器包括接收layer-36层通道叠加的特征c2的52×52的检测器,接收layer-61层通道叠加的特征c3的26×26的检测器,以及接收layer-4层和layer-11层通道叠加后的特征c1的104×104的检测器yolo检测器自身为yolov3模型的原始设置,在本实施例中不做修改。yolo检测器预测(x,y,w,h,c),其中x为预测目标中心点的横坐标,y为预测目标中心点的纵坐标,w为预测的目标矩形框的宽度,h为预测的目标矩形框的高度,c为预测的目标的分类。并且本实施例中3个辅助检测器也分别接收特征图级联单元输出的特征c1、特征c2、特征c3。如图4所示,本实施例中的辅助检测器包括关键点辅助激励单元和全卷积一步分类回归单元。关键点辅助激励单元通过手工增强目标5个关键点来帮助模型更好地定位目标。在模型训练时,手工增强的5个关键点为真实标签的目标矩形框的1个中心点,中心点十字交叉线与真实标签的目标矩形框的4个交点。具体步骤为:首先,将输入特征图在通道维度上进行平均;接着,将平均后的特征图乘以目标关键点的二值图(二值图根据真实标注(groundtruth)的坐标信息,将目标关键点位值置1,其他点位值置0的张量);然后,将前一步骤的特征图乘以加权因子α;最后,将结果加到输入特征图的每个通道。加权因子α定义为:其中current_epoch的取值范围是0到9,total_epoch的值为10。关键点辅助激励单元在训练的初始阶段帮助模型定位热成像目标。随着训练的进行,加权因子α逐渐衰减为0(current_epoch是从0开始到9,然后每迭代一次,α的值就会比上一次小,最后为0,是cos函数的0到π/2的曲线)。通过此种方式,模型可以在泛化方面获得更好的性能。全卷积一步分类回归单元采用的是fcos的头模块,该模块包含2个分支,第一个分支进行分类(classification)和计算每个位置(指特征图上的每个点位)与目标中心点距离损失(“center-ness”),即中心度,第二个分支进行4个边距回归(regression),4个边距指特征上每个位置和预测的目标矩形框四边的距离(l,t,r,b)。全卷积一步分类回归单元独立进行预测,预测结果与原yolo检测器结果合并,辅助检测器帮助模型学习那些与预定义锚点框匹配较差的实例。本实施例选定meanaverageprecision(map)评价指标对目标检测模型的输出结果进行评价,基于所述训练集,采用随机梯度下降法优化目标检测模型。对目标检测模型训练后,保存达到收敛的权重文件,作为后续测试或者分类使用的输入权重。本实施例中,收敛条件是看损失函数的值和最终的评价指标,如果损失函数和评价指标基本不提升,就表明已完成训练。本实施例采用的损失函数,包括:l=lfam+lyolo+laux式中,l为所构建的损失函数,lfam为特征对齐损失,lyolo为yolov3损失,laux为辅助检测器损失;其中,所述特征对齐损失lfam的公式如下:lfam=(tf-vf)2式中,tf是特征对齐单元layer-30层输出的特征图,vf是骨干网络layer-30层输出的特征图;其中,yolov3损失lyolo定义如下:lyolo=lx+ly+lw+lh+lconf+lcls式中,(lx,ly,lw,lh)分别代表预测的目标矩形框中心点坐标(x,y)、预测的目标矩形框宽和高的损失,lconf代表置信度损失,lcls代表分类损失;其中,(lx,ly,lw,lh)采用均方误差(meansquareerror,mse),公式如下:式中,tx为预测的目标矩形框的中心点x坐标相对于该中心点所在网格左上角点x坐标的偏移量,gx为根据真实标签计算出的目标矩形框的中心点x坐标相对于中心点所在网格左上角点x坐标的偏移量,ty为预测的目标矩形框的中心点y坐标相对于该中心点所在网格左上角点y坐标的偏移量,gy为根据真实标签计算出的目标矩形框的中心点y坐标的偏移量,tw为真实标签中目标矩形框的宽度,gw为预测的目标矩形框的宽度,th为真实标签中目标矩形框的高度,gh为预测的目标矩形框的高度;其中,lconf和lcls采用二分类交叉熵(binarycrossentropy,bce),具体公式如下:lconf、cls=yilogxi+(1-yi)log(1-xi)式中,xi表示第i个样本预测为正样本概率,yi表示第i个样本的分类;其中,所述辅助检测器损失laux定义如下:laux=ll+lt+lr+lb+lc+lctn其中,(l,t,r,b)代表特征上每个位置到预测的目标矩形框四边的距离,c代表分类,ctn代表每个位置到目标中心点的中心度;其中,(l,t,r,b)采用giou计算,公式如下:其中,iou表示真实标签中目标矩形框和预测的目标矩形框交集和并集的比值(交并比),ac表示包围真实标签中目标矩形框和预测的目标矩形框的最小框的面积,u表示真实标签中目标矩形框和预测的目标矩形框的并集面积;lctn采用bcewithlogitsloss计算;lc采用focalloss来计算,lc定义为:其中,y为真实值,y′为预测值,α和γ分别取值0.25和2。步骤s3、利用优化后的目标检测模型处理待检测的退化热成像图,输出标记目标后的退化热成像图。由于特征对齐单元以及输入特征对齐单元的可见光图主要用于辅助目标检测模型的训练,因此在得到优化后的目标检测模型后,即可脱离可见光图的使用,即本实施例仅向目标检测模型中输入待检测的的退化热成像图输入骨干网络即可。与模型训练时相对应的,本实施例标记目标后的退化热成像图中采用矩形框标记目标,预测的目标矩形框刚好能够完全包围目标,或者与训练时的真实标签的目标矩形框具有比例关系。与模型训练时不同的是,在检测时不使用特征对齐单元和手工增强的关键点,而是通过骨干网络自行提取特征,然后将特征送入检测网络进行检测。为了更好地证明本申请的检测效果,以下通过一具体实例进一步说明。a、参数设置本实验是在ubuntu16.04下进行的,框架为pytorch1.0,显卡为nvidiartx2080ti。模型采用随机梯度下降(stochasticgradientdescent,sgd)作为优化器,初始学习率为1e-5,权重衰减为5e-4,动量为0.9,批次大小为2,迭代次数为10。b、评价指标为map(meanaverageprecision)。c、实验结果在kaist和flir-adas数据集中对比了多个目前主流的方法,结果分别如表1和表2所示:表1:kaist数据集中各个方法的评价结果表2:flir-adas数据集中各个方法的评价结果方法评价指标(map)faster-rcnn47.00retinanet35.00foveabox43.70mmtod-cg61.40mmtod-unit61.54本申请的目标检测方法62.27表中faster-rcnn,retinanet和foveabox为主流的基于光的目标检测方法。多模态热成像目标检测(multimodalthermalobjectdetection,mmtod)为基于伪双光融合的退化热成像图目标检测方法。从表1中的数据可以看出,本申请提出的方法的精度比faster-rcn高5.54%,比retinanet和foveabox高约4.4%。即使与特定模型mmtod-cg相比,本方法的精度也提高了1.4%。结合表1和表2可以看出,本申请提出的方法的精度优于主流通用方法,也比特定双光融合方法高。应该理解的是,虽然图1的流程图中的各个步骤按照箭头的指示依次显示,但是这些步骤并不是必然按照箭头指示的顺序依次执行。除非本文中有明确的说明,这些步骤的执行并没有严格的顺序限制,这些步骤可以以其它的顺序执行。而且,图1中的至少一部分步骤可以包括多个子步骤或者多个阶段,这些子步骤或者阶段并不必然是在同一时刻执行完成,而是可以在不同的时刻执行,这些子步骤或者阶段的执行顺序也不必然是依次进行,而是可以与其它步骤或者其它步骤的子步骤或者阶段的至少一部分轮流或者交替地执行。以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。以上所述实施例仅表达了本申请的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本申请构思的前提下,还可以做出若干变形和改进,这些都属于本申请的保护范围。因此,本申请专利的保护范围应以所附权利要求为准。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1