基于多因素模糊时间序列的高陡边坡形变趋势预测的方法与流程
[0001]
本发明属于露天矿山坡体形变监测技术领域,具体涉及一种基于多因素模糊时间序列的高陡边坡形变趋势预测的方法。
背景技术:
[0002]
随着我国经济的快速发展,露天矿的开采范围和开采深度在不断的增加,从而形成了众多大型的高陡边坡。一方面,高陡边坡极大地改变了局部区域的应力条件,进而影响露天矿周边的建构筑物;另一方面,高陡边坡形变一旦超出了限度,很容易发生滑坡等事故,对矿区安全生产和人民生命安全带来了很大的威胁。
[0003]
传统的矿山边坡形变数据主要是通过多期形变监测获得,采用的方法主要是水准沉降监测和经纬仪或全站仪平面监测。随着变形监测仪器如gps、insar等新技术及相关理论的不断完善,出现了实时动态变形监测技术。目前常用的变形预测理论和方法主要包括时间序列分析、回归分析、灰色理论、神经网络模型以及一型模糊时间预测模型。其中,时间序列分析突出时间序列且暂不考虑外界因素的影响,但是由于矿山环境复杂多变且不确定因素很多,因而时间序列分析往往存在较大偏差。由于矿山边坡条件复杂多变且因子众多,回归分析的建模精度会因为建模因子选取不合理而存在较大偏差。由于矿山边坡原始监测数据来源复杂,则对原始监测数据要求严格的灰色预测模型会存在较低的预测精度。bp神经网络模型预测结果与初值选取有关,而在复杂的矿山边坡环境下很难确定最合理的初值。一型模糊时间预测模型可以提高预测精度,但是只考虑了变量自身的变化,即只能分别预测多个变量。然而在实际问题中,变量的发展不仅与自身有关,也与环境变量影响因素等有关,所以一型模糊时间预测模型的预测效果往往不是十分理想。如何对矿山坡体动态形变数据进行处理分析,利用最准确的预测模型预测出坡体变形,防患于未然,是矿山坡体形变监测的最终目的。
技术实现要素:
[0004]
为了解决现有技术存在的问题,本发明的目的在于提供一种基于多因素模糊时间序列的高陡边坡形变趋势预测的方法,利用整体分布优化算法优化论域划分,具有预测精度高的优点。
[0005]
本发明的目的是通过下述技术方案实现的:
[0006]
本发明的一种基于多因素模糊时间序列的高陡边坡形变趋势预测的方法,其特征在于,包括以下步骤:
[0007]
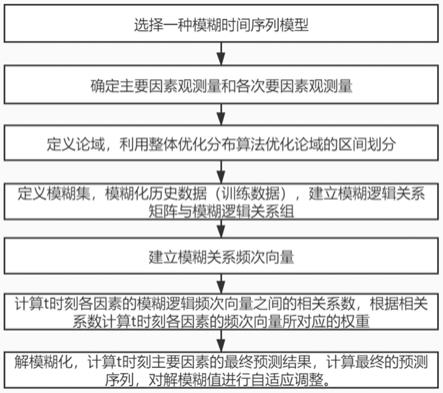
s1、选择一种模糊时间序列模型作为基准;
[0008]
s2、确定影响边坡形变的主要因素和各次要因素,根据历史数据即训练数据,确定主要因素观测量和各次要因素观测量,并计算主要因素相邻历史数据之间的变化率以及各次要因素相邻历史数据之间的变化率;
[0009]
s3、定义论域,利用整体分布优化算法去优化论域的区间划分;
[0010]
s4、定义模糊集,并模糊化历史数据;建立主要因素观测量和各次要因素观测量的模糊逻辑关系矩阵,并建立模糊逻辑关系组;
[0011]
s5、计算主要因素观测量与各次要因素观测量的一阶至最高阶模糊逻辑关系在相应的模糊关系组中出现的频次,建立模糊关系频次向量;
[0012]
s6、计算t时刻各因素的模糊逻辑频次向量之间的相关系数,根据相关系数计算t时刻各因素的频次向量所对应的权重;
[0013]
s7、解模糊化,计算t时刻主要因素的最终预测结果,计算最终的预测序列,对解模糊值进行自适应调整。
[0014]
在步骤s1中,选择以chen提出的经典模糊时间序列模型作为基础模型。
[0015]
在步骤s2中,选取天顶距作为主要因素,选取斜距和天顶距作为次要因素,根据历史数据确定主要因素观测量和各次要因素观测量,并进行一阶差分,建立训练集。
[0016]
在步骤s3中,根据各因素观测量历史数据的变化范围,确定各因素的论域u,然后,利用整体分布优化算法进行模糊区间划分及其优化,获取最佳的模糊区间划分方式,历史数据按照划分结果进行模糊化,进而产生相应的模糊规则,最后进行预测得到相应的预测精度。
[0017]
在步骤s4中,包括以下子步骤:
[0018]
s4.1、定义模糊集,将历史数据模糊化
[0019]
定义由主要因素观测量的数据序列得到的模糊集为a1,a2,...,a
14
,定义次要因素观测量的数据序列得到的模糊集分别为b1,b2,...,b
14
和c1,c2,...,c
14
;
[0020]
s4.2、建立主要因素观测量和各次要因素观测量的模糊逻辑关系矩阵,并建立模糊逻辑关系组
[0021]
模糊化各因素相邻历史数据之间的变化率,由历史数据建立一定时间间隔内的模糊逻辑值之间的联系,以形成从一阶直到最高阶的全部模糊逻辑关系,并将拥有相同lhs(相同左操作数)关系的模糊逻辑关系归并至一组,得到各因素的模糊逻辑关系组;对历史数据进行模糊化时,将数据序列所对应的隶属度最大的模糊集作为对于该数据点的模糊描述。
[0022]
在步骤s5中,根据各因素的模糊逻辑关系组,计算主要因素观测量和各次要因素观测量的一阶至最高阶模糊逻辑关系在相应的模糊关系组中出现的频次,建立各因素的模糊关系频次向量。
[0023]
在步骤s6中,包括以下子步骤:
[0024]
s6.1、根据各因素的模糊关系频次向量,计算t时刻各因素的模糊逻辑频次向量之间的相关系数;
[0025]
s6.2、根据相关系数计算t时刻各因素的模糊关系频次向量所对应的权重;
[0026]
在步骤s7中,包括以下子步骤:
[0027]
s7.1计算t时刻主要因素的最终预测结果
[0028]
求解权重后,根据模糊逻辑变量fvar
f
(t)的最终预测结果,计算t时刻主要因素的最终预测值;
[0029]
s7.2、计算最终预测序列;
[0030]
s7.3、对解模糊值进行自适应调整。
[0031]
与现有技术相比,本发明的优点是:
[0032]
本发明提供的一种基于多因素模糊时间序列的高陡边坡形变趋势预测的方法,采用了二型模糊时间序列算法,其建模过程与一型经典模糊时间序列建模相似,主要区别在于多元信息处理上,例如本文预测方位角、天顶距、斜距等边坡形变要素,经典一元模糊模糊时间序列只能在数据本身进行预测,而多元模糊时间序列可以使数据三者联合预测,以其中一个变量为一型观测量,其他两个变量作为二型观测量辅助预测,较大程度的提高了模型的预测精度。
[0033]
采用了整体分布优化算法优化后,使得模糊时间序列的论域划分更加合理。模糊时间序列算法的核心之一是模糊化过程,不同的论域区间划分会定义不同的语意值,产生不同的模糊集,合理的模糊集确一直是模糊时间序列的重点。传统的模糊时间序列是均值划分论域,其特点是结构简单,但是精度不够,对数据处理具有片面性,预测效果不理想。
[0034]
提高了边坡动态变形预测精度,提升了对小样本和和波动数据预测的准确性,可以预测未来一定时期内边坡的数据变化。
附图说明
[0035]
图1为本发明的多因素模糊时间序列流程图;
[0036]
图2为本发明的整体分布优化算法流程图;
[0037]
图3为本发明提供的方法的预测结果输出图;
[0038]
图4为本发明的均方根误差rmse随区间间隔数量的变化示意图。
具体实施方式
[0039]
为了更好的解释本发明,以便于理解,下面结合附图,通过具体实施方式,对本发明作详细描述。
[0040]
本发明的一种基于多因素模糊时间序列的高陡边坡形变趋势预测的方法,其特征在于,包括以下步骤:
[0041]
s1、选择一种模糊时间序列模型作为基准;
[0042]
本发明选择以chen提出的经典模糊时间序列模型作为基础模型,因为这个模型计算过程简单且预测结果的精度也较好。
[0043]
s2、确定影响边坡形变的主要因素和各次要因素,根据历史数据即训练数据,确定主要因素观测量和各次要因素观测量,并计算主要因素相邻历史数据之间的变化率以及各次要因素相邻历史数据之间的变化率;
[0044]
历史数据集中主要包括“斜距”、“方位角”、“天顶距”等观测量。选取天顶距作为主要因素(即一型观测量),选取斜距和天顶距作为次要因素(即二型观测量),并对原始时间序列的数据进行一阶差分,建立训练集,t时刻各因素相邻历史数据之间的变化率r
k
(t)计算公式如下:
[0045][0046]
其中close
t
和close
t-1
分别表示t时刻和t-1时刻的历史数据,r
k
(t)表示t时刻第k个因素的变化率。
[0047]
s3、定义论域并进行区间划分,利用整体分布优化算法去优化论域的区间划分;
[0048]
根据各观测量r
k
(t)(k=1,2,3)历史数据的变化范围,确定各因素的论域u,将论域划分成区间。为了保证预测值在有界的论域范围内,取论域的边界为变化率的最大值并向绝对值变大的方向取整,因为一阶差分后的数据有正有负,为保证所研究的区间都是正数,对所有一阶差分后得到的数据添加相同的正常数const,其中const大于最小负数的绝对值。将数据序列按上述方式调整后,设其最大值和最小值分别为u
max
和u
min
,定义论域u的起点为u
min-d
min
,终点为u
max-d
max
,其中d
min
,d
max
为两个正整数,用来调整界限。因此,论域被定义为u=[u
min-d
min
,u
max-d
max
],从历史数据中,可以得到u
min
和u
max
,并设定d
min
和d
max
的值,从而确定论域u。在实例中将论域划分为14个区间间隔进行预测,将主观测量r1(t)的论域划分为14个子区间u1,u2,
…
u
14
,将辅助观测量r2(t)的论域划分为14个子区间v1,v2,
…
v
14
,将辅助观测量r3(t)的论域划分为14个子区间w1,w2,
…
w
14
。对于模糊区间的数量,根据均方根误差rmse随区间间隔数量的变化图而获得。
[0049]
然后,利用整体分布优化算法计算各个粒子的适应度值。整体分布优化算法的主要作用在于可优化子区间的长度,同时不用改变划分的个数。通过粒子群中的各个粒子的位置得出不同的模糊区间划分,数据按照划分结果进行模糊化,进而产生相应的模糊规则,然后进行预测得到相应的预测精度,亦即粒子的适应度。粒子通过不断的更新自身位置和速度,同时不断更新个体最优位置和全局最优位置,来保存最优的位置划分。待算法终止后,全局最优位置即为最优的论域划分。具体实现步骤如图2所示。
[0050]
(1)初始化。在整个定义域内随机的产生初始种群,即区间内不同的划分点,同时初始化柯西分布的半径为覆盖整个定义域的0.5倍,初始化参数。柯西分布尺度参数γ=0.1,种群直径递减率α=0.93,停滞次数β=9,最大迭代次数10000或者种群直径的标度小于0.000001,种群的规模为70。
[0051]
(2)计算种群中每个个体的适应度值,其中适应度函数定义为所有真实值到其所在区间中间点距离平方之和的平均值,找出本次最好的个体并与上次的最好个体比较,如果好于上次的最好个体,替换上次最好的个体,作为本次的最好个体,种群的直径保持不变。如果差于上次的最好个体,则保留上次最好个体,作为本次的最好个体,同时使停滞次数减1,若停滞次数为0,则使种群直径缩减为原来直径的0.93,同时使停滞次数变为9;若停滞次数不为0,则保持原来的种群直径不变。迭代次数减1。
[0052]
(3)以已经找到的最好个体的坐标为中心,用柯西分布产生新的种群。
[0053]
(4)如果当前迭代次数达到了预先设定的最大次数或种群直径的标度小于0.000001,则停止迭代、输出最优解、否则转到(2)。
[0054]
利用整体分布优化算法计算各个粒子的适应度值,使用粒子元素得到的论域区间划分对数据模糊化,进而产生相应的模糊规则,然后由预测模型进行预测,并使每个粒子相应的预测精度作为粒子的适应度值。这里采用数据预测精度的均方根误差rmse作为粒子的适应度值。设第i个粒子的适应度值为fitness(i),其值由如下公式计算得出:
[0055]
fitness(i)=rmse(i)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0056]
[0057]
其中,s表示预测数据的个数,ad_forecast(j)表示时刻j的预测值,actual(j)表示时刻j的实际值。
[0058]
计算出第i个粒子的适应度值后,更新当前粒子的个体最优位置和全局最优位置。然后计算第i+1个粒子的适应度值,直至循环至第k个粒子。
[0059]
s4、定义模糊集,并模糊化历史数据(训练数据);建立主要因素观测量和各次要因素观测量的模糊逻辑关系矩阵,并建立模糊逻辑关系组;
[0060]
在步骤s4中,包括以下子步骤:
[0061]
s4.1、定义模糊集,将历史数据模糊化
[0062]
根据论域区间,定义利用主要因素观测量的数据序列r1(t)得到的模糊集为a1,a2,
…
a
14
,每个模糊集表征一个对应区间的语言值,每一个模糊集可以由区间u1,u2,
…
u
14
所定义,通常采用三角形函数来表示,其形式如下:
[0063][0064]
同样的,定义利用第一个次要因素观测量的数据序列r1(t)得到的模糊集为b1,b2,
…
b
14
,每个模糊集表征一个对应区间的语言值,每一个模糊集可以由区间v1,v2,
…
v
14
所定义,通常采用三角形函数来表示,其形式如下:
[0065][0066]
定义利用第二个次要因素观测量的数据序列r3(t)得到的模糊集为c1,c2,
…
c
14
,每个模糊集表征一个对应区间的语言值,每一个模糊集可以由区间w1,w2,
…
w
14
所定义,通常采用三角形函数来表示,其形式如下:
[0067][0068]
模糊化各因素相邻历史数据之间的变化率,得到各因素的模糊逻辑关系组。对历史数据进行模糊化时,将数据序列所对应的隶属度最大的模糊集作为对于该数据点的模糊描述。首先,对各时刻主要因素的变化率进行模糊化,得到相应的模糊集合,例如t时刻主要因素变化率的数据属于论域区间u
i
(1≤i≤14),根据等式(1),模糊集a
i
相对于u
i
的隶属度值d
i
=1,比其他的模糊集都大,所以将该数据点模糊化为a
i
。其次,对各时刻次要因素的变化率进行模糊化,得到相应的模糊集合,例如t时刻某个次要因素数据属于论域区间v
j
(1≤
j≤14),根据等式(2),模糊集b
j
相对于v
j
的隶属度值d
j
=1,比其他的模糊集都大,所以将该数据点模糊化为b
j
。例如t时刻某个次要因素数据落在论域区间w
k
(1≤k≤14),根据等式(3),模糊集c
k
相对于w
k
的隶属度值d
k
=1,比其他的模糊集都大,所以将该数据点模糊化为c
k
。
[0069]
s4.2、建立主要因素观测量和各次要因素观测量的模糊逻辑关系矩阵,并建立模糊逻辑关系组
[0070]
由历史数据建立一定时间间隔内的模糊逻辑值之间的联系,以形成从一阶直到最高阶的全部模糊逻辑关系,并将拥有相同前件(lhs关系)的模糊逻辑关系归并至一组,构造模糊逻辑关系组。例如,假设t-1和t时刻主要因素r1(t)对应的模糊逻辑值分别为a
j
和a
k
,则形成的模糊逻辑关系映射为a
j
→
a
k
,并且假设t+m-1和t+m时刻主要因素对应的模糊逻辑值分别为a
j
和a
m
,则形成有模糊逻辑关系映射为a
j
→
a
m
。所以模糊逻辑值a
k
和a
m
从属于一个模糊逻辑关系组,可以建立主要因素一阶模糊逻辑关系组groupa
j
:a
k
,a
m
。对于次要因素r2(t),假设t-1和t时刻对应的模糊逻辑值分别为b
j
和a
k
,则形成的模糊逻辑关系映射为b
j
→
a
k
,并且假设t+n-1和t+n时刻对应的模糊逻辑值分别为b
j
和a
m
,则形成的模糊逻辑关系映射为b
j
→
a
m
,那么就可以构造次要因素一阶模糊逻辑关系组groupb
j
为groupb
j
:a
k
,a
m
。
[0071]
同理可以构建高阶模糊逻辑关系组。假设l≥2是正整数,建立全部的l阶模糊关系,需要在训练数据中找出l个连续的模糊集,其建立形式如下:考虑t-l,t-l+1,
…
,t-2,t-1,t时刻对应的变化率的数据r1(t-l),r1(t-l+1),
…
,r1(t-2),r1(t-1),r1(t),其中r1(t-l),r1(t-l+1),
…
,r1(t-2),r1(t-1)称为当前状态,r1(t)称为下一状态,如果当前状态r1(t-l),r1(t-l+1),
…
,r1(t-2),r1(t-1)对应的模糊集分别为a
t-p
,a
t-p+1
,
…
,a
t-2
,a
t-1
,t时刻下一状态r1(t)对应的模糊集为a
k
,则可以得到一个l阶的模糊逻辑关系即a
t-l
,a
t-l+1
,
…
,a
t-2
,a
t-1
→
a
k
。将训练集中主要因素形成的所有l阶模糊关系提取出来,合并具有相同前件(lhs关系)的模糊关系,即可形成一个主要因素l阶模糊关系组groupa
t-l
,a
t-l+1
,
…
,a
t-2
,a
t-1
.如果当t-l,t-l+1,
…
,t-2,t-1,t时刻变化率的数据r1(t-l),r1(t-l+1),
…
,r1(t-2),r1(t-1)对应的模糊集分别为b
t-l
,b
t-l+1
,
…
,b
t-2
,b
t-1
,t时刻变化率的数据r1(t)对应的模糊集为a
k
,则可以得到一个l阶的模糊关系即b
t-l
,b
t-l+1
,
…
,b
t-2
,b
t-1
→
b
k
。将训练集中次要因素形成的所有l阶模糊关系提取出来,合并具有相同前件(lhs关系)的模糊关系,即可形成一个次要因素l阶模糊关系组groupb
t-l
,b
t-l+1
,
…
,b
t-2
,b
t-1
。如果历史数据中下一状态数据所对应的模糊集不知道,则用“#”象征的表示不知道的模糊集,在模糊关系未知的情况下,下一个状态的数据是用于测试的
[0072]
s5、计算主要因素观测量与各次要因素观测量的一阶至最高阶模糊逻辑关系在相应的模糊关系组中出现的频次,建立模糊关系频次向量;
[0073]
根据模糊逻辑关系组,可以对各因素模糊规则出现的频次进行计算。以主要因素的一阶模糊逻辑关系频次向量计算为例,其它主要因素的高阶模糊逻辑关系频次向量计算类似。如果在时t-1刻r1(t-1)所属的模糊集为a
u
(1≤u≤14),t-1时刻r2(t-1)所属的模糊集为b
v
(1≤v≤14),t-1时刻r3(t-1)所属的模糊集为c
w
(1≤w≤14)。假设a
m1
,a
m2
,
…
,a
mp
是一阶模糊关系组groupa
m
中出现的全部模糊关系,令n
m1
,n
m2
,
…
,n
mp
表示模糊关系a
m1
,a
m2
,
…
,a
mp
在一阶模糊逻辑关系组groupa
m
中出现的频次。假设a
s(i)1
,a
s(i)2
,
…
,a
s(i)q
是一阶模糊关系组groupb
s
中出现的全部模糊关系,令n
s(i)1
,n
s(i)2
,
…
,n
s(i)q
表示模糊关系a
s(i)1
,a
s(i)2
,
…
,
a
s(i)q
在一阶模糊逻辑关系组groupb
s
中出现的频次,其中p和q是正整数,取值范围是1≤p≤14和1≤q≤14,i为次要因素的个数。建立t时刻主要因素对应的一阶模糊关系组groupa
m
的模糊逻辑频次向量和t时刻第i个次要因素对应的一阶模糊关系组groupb
s
的模糊逻辑频次向量表示如下:
[0074][0075]
通过简单的例子对上述过程进行说明,假设t-1时刻主要因素对应的模糊逻辑关系为a9,主要因素中以a9为前件的模糊逻辑关系组groupa9中出现的模糊逻辑关系值,即对应的后件为
[0076][0077]
其中模糊逻辑关系a5,a6,a7,a8,a9,a10,a11,a13在主要因素模糊逻辑关系组groupa9中出现的频次为2,5,13,6,2,1,1,1,假设t-1时刻次要因素对应的模糊逻辑关系为b7,主要因素中以b7为前件的模糊逻辑关系组groupb7中出现的模糊逻辑关系值,即对应的后件为
[0078][0079]
其中模糊逻辑关系a3,a5,a6,a7,a8,a9,a10,a13在第i个次要因素模糊逻辑关系组groupb7中出现的频次为1,5,11,24,25,10,2,1。因此t时刻主要因素的一阶模糊逻辑频次向量和t时刻第i个次要因素的一阶模糊逻辑频次向量可以表示如下:
[0080][0081][0082]
按照上述方法可以建立t时刻主要因素的l阶模糊逻辑频次向量和t时刻第i
个次要因素的l阶模糊逻辑频次向量其中l≥2。
[0083]
s6、计算t时刻各因素的模糊逻辑频次向量之间的相关系数,根据相关系数计算t时刻各因素的频次向量所对应的权重;
[0084]
在步骤s6中,包括以下子步骤:
[0085]
s6.1、根据各因素的模糊关系频次向量,计算t时刻各因素的模糊逻辑频次向量之间的相关系数
[0086]
相关系数表示第i种次要因素和主要因素之间的相互关系和相关方向。相关系数越大,则其在预测时所占的比重越高。根据t时刻主要因素的一阶模糊逻辑频次向量建立数据序列t
vm
(t),同时根据t时刻第i个次要因素的一阶模糊逻辑频次向量建立数据序列t
vs(i)
(t)。如果模糊逻辑关系值a
mp
在一阶模糊逻辑频次向量中出现的频次为n
mp
,则数据序列t
vm
(t)中相应的值设为n
mp
(p=1,2,
…
,14)。如果模糊逻辑关系值a
s(i)q
在一阶模糊逻辑频次向量中出现的频次为n
s(i)q
,则将数据序列t
vs(i)
(t)中相应的值设为n
s(i)q
(q=1,2,
…
,14)。因此可以建立对应t时刻一阶模糊逻辑频次向量和的数据序列t
vm
(t)和t
vm
(t),表示如下:
[0087][0088][0089]
进一步计算t时刻主要因素对应的数据序列t
vm
(t)=(x1,x2,
…
,x
n
)和第i个次要因素对应的数据序列t
vs(i)
(t)=(y1,y2,
…
,y
n
)间的相关系数,计算公式如下:
[0090][0091]
其中表示主要因素数据序列t
vm
(t)=(x1,x2,
…
,x
n
)的平均值,表示第i个次要因素数据序列t
vs(i)
(t)=(y1,y2,
…
,y
n
)的平均值,r
i
的取值范围是[-1,1]。如果r
i
=0,表明在预测阶段第i个次要因素与主要因素不相关,当r
i
>0时,r
i
的绝对值越大,表明在预测阶段第i个次要因素与主要因素的正相关程度越高,当r
i
<0时,r
i
的绝对值越大,表明在预测阶段第i个次要因素与主要因素的负相关程度越高。如果r
i
>0,则使用第i个次要因素参与到主要因素的预测阶段,否则,不使用第i个次要因素参与主要因素的预测。
[0092]
s6.2、根据相关系数计算t时刻各因素的模糊关系频次向量所对应的权重
[0093]
根据相关系数的大小,计算主次因素在预测时所占的比重。设t时刻主要因素的一阶频次向量所对应的权重为w
vm
(t),第i个次要因素的一阶频次向量所对应的权重为w
vs(i)
(t),计算公式如下:
[0094][0095][0096]
其中,n表示次要因素的个数,r
i
(1≤i≤n)表示数据序列t
vm
(t)(根据t时刻主因素的一阶模糊逻辑频次向量建立)和数据序列t
vs(i)
(t)(根据t时刻第i个次要因素的一阶模糊逻辑频次向量建立)间的相关系数。如果r
i
≤0,表明数据序列t
vm
(t)和数据序列t
vs(i)
(t)之间不相关或者负相关,这种情况下,认为第i个次要因素的频次向量对于主要因素模糊逻辑值的预测结果不产生影响,因此在t时刻主要因素的预测过程中不采用此种次要因素。如果r
i
>0,根据数据序列t
vm
(t)和数据序列t
vs(i)
(t)之间的相关系数,可以计算出主要因素频次向量所对应的权重w
vm
(t)和第i个次要因素频次向量所对应的权重w
vs(i)
(t)。c
m
表示主要因素模糊逻辑关系组中数据的可信度,取值范围是[0,1]。c
i
表示第i个次要因素模糊逻辑关系组中数据的可程度,取值范围是[0,1]。当训练数据中与之对应的二阶模糊逻辑关系组中模糊规则的个数很少时,则使用此种数据进行预测的可信度低于使用其他数据进行预测的可信度,故适当减少其在预测结果中所占的比重。d
m
表示主要因素构成的二阶模糊逻辑关系组中包含的模糊规则的个数,d
i
表示第i个次要因素构成的二阶模糊逻辑关系组中包含的模糊规则的个数,d为算法给定的二阶模糊逻辑关系组中所包含的模糊规则的下限,则可信度计算公式如下:
[0097][0098][0099]
s7、解模糊化,计算t时刻主要因素的最终预测结果,计算最终的预测序列,对解模糊值进行自适应调整。
[0100]
在步骤s7中,包括以下子步骤:
[0101]
s7.1、计算t时刻主要因素的最终预测结果
[0102]
根据各因素高阶模糊逻辑频次向量,解模糊化其所对应的各模糊集的权重系数。假设t时刻主要因素对应的高阶模糊逻辑关系为l
m
阶,t时刻第i个次要因素对应的高阶模糊逻辑关系为l
i
(1≤i≤n)阶,其中n为次要因素的个数,t时刻主要因素的l
m
阶模糊逻辑频次向量和第i个次要因素的l
i
阶模糊逻辑频次向量表示如下:
[0103]
[0104][0105]
则根据模糊逻辑频次向量的值,模糊逻辑关系a
mh
所对应的权重w
amh
可以计算如下:
[0106][0107]
再根据模糊逻辑频次向量的值,模糊逻辑关系a
s(i)k
所对应的权重w
as(i)k
可以计算如下:
[0108][0109]
其中1≤h≤p,1≤k≤q.于是对应模糊逻辑频次向量的模糊逻辑变量fvar
m
(t)的预测结果,及对应模糊逻辑频次向量的模糊逻辑变量fvar
s(i)
(t)的预测结果可以计算如下:
[0110][0111][0112]
其中表示模糊集a
mh
对应区间u
h
(1≤h≤p)的中心值,即语义变量a
mh
相对于区间u
h
具有最大隶属度,其中表示模糊集a
s(i)k
对应区间u
k
(1≤k≤q)的中心值,即语义变量a
s(i)k
相对于区间u
k
具有最大隶属度。如果t时刻主要因素的l
m
阶模糊关系组不存在,则根据t时刻主要因素的l
m-1阶模糊逻辑频次向量的值计算模糊逻辑关系a
mh
所对应的权重w
amh
,如果t时刻第i个次要因素的l
i
阶模糊关系组不存在,则根据t时刻第i个次要因素的l
i-1阶模糊逻辑频次向量的值计算模糊逻辑关系a
s(i)k
所对应的权重w
as(i)k
,重复上述过程,如果t时刻各因素的二阶模糊关系组也不存在,则根据t时刻各因素的一阶模糊逻辑频次向量和的值计算相应的权重w
amh
和权重w
as(i)k
,如果t时刻主要因素的各阶模糊关系组都不存在,则令fvar
m
(t)=fvar
m
(t-1),如果t时刻第i个次要因素的各阶模糊关系组也都不存在,则令fvar
s(i)
(t)=fvar
s(i)
(t-1)。
[0113]
根据t时刻主要因素的一阶频次向量所对应的权重w
vm
(t),以及t时刻第i个次要因素的一阶频次向量所对应的权重w
vs(i)
(t),利用t时刻主要因素的模糊逻辑变量fvar
m
(t)的预测结果,及t时刻第i个次要因素的模糊逻辑变量fvar
s(i)
(t)的预测结果,t时刻主要因素模糊逻辑变量fvar
f
(t)的最终预测结果可以计算如下:
[0114][0115]
其中,w
vm
(t)表示t时刻主要因素对应的频次向量的权重,fvar
m
(t)表示t时刻主要因素的模糊逻辑变量的预测值,w
vs(i)
(t)表示t时刻第i个次要因素对应的频次向量的权重,fvar
s(i)
(t)表示t时刻第i个次要因素的模糊逻辑变量的预测值,其中1≤i≤n,n表示次要因素的个数。
[0116]
s7.2、计算最终的预测序列
[0117]
根据模糊逻辑变量fvar
f
(t)的最终预测结果,t时刻主要因素的预测值可以计算如下:
[0118][0119]
其中actual
m
(t-1)表示t-1时刻主要因素的真实值。当fvar
f
(t)=0时,令因为t时刻主要因素的预测值f(t)与t-1时刻主要因素的模糊逻辑变量的预测值fvar
m
(t-1)密切相关,采用上述预测公式可以得到更准确的预测结果。
[0120]
s7.3、对解模糊值进行自适应调整
[0121]
建模时使用自适应预测模型来对预测结果进行修正。对t时刻主要因素进行预测时,在解模糊化后,采用自适应期望调整的方式对预测结果进行调整,二阶自适应预测模型对预测结果进行修正的具体计算公式如下:
[0122]
ad_f(t)=actual(t-1)+h1(f(t)-actual(t-1))+h2(f(t-1)-actual(t-2))
ꢀꢀꢀ
(27)
[0123]
其中ad_f(t)表示t时刻主要因素调整后的最终预测结果,actual(t-1)和actual(t-2)表示t-1和t-2时刻主要因素的真实值,f(t)和f(t-1)表示t和t-1时刻解模糊化后的值,h1和h2表示自适应调整参数,取值范围为[-1,1],取值方法为使用步长为0.001的h1和h2,以训练集的均方根误差rmse为目标函数,找出对应训练集rmse值达到最小时的参数h1和h2,并以此对测试集的结果进行自适应调整,得到最终的预测值。
[0124]
高阶自适应预测模型对预测结果进行修正的具体计算公式如下:
[0125][0126]
其中ad_f(t)表示t时刻主要因素调整后的最终预测结果,actual(t-1)表示t-1时刻主要因素的真实值,f(t-k+1)表示t-k+1时刻的解模糊值,n为多因素模糊时间序列模型的阶数,自适应模型的预测误差随着阶数的增长进行调整,h表示自适应调整参数,取值范围为[-1,1],取值方法为使用步长为0.001的h,以预测阶段的均方根误差rmse为目标函数,找出对应训练集rmse值达到最小时的参数h,并以此对测试集的结果进行自适应调整,得到最终的预测值。
[0127]
均方根误差的定义由下式给出:
[0128][0129]
其中f
forecasted
(j)表示第j个数据的预测值,f
actual
(j)表示第j个数据的真实值,n表示数据的个数。
[0130]
s8、模型具体实现及仿真:
[0131]
s8.1、首先以经典一型模糊时间序列为建模基础,然后确定一型和二型观测量,本发明拟选定一型观测量为天顶距,二型观测量为方位角和斜距来建立模型,从而预测模型中天顶距的均值误差。
[0132]
s8.2、根据一型观测量天顶距定义论域区间记为u,将论域区间根据整体分布优化算法划分为优化区间,即将一型观测量天顶距的论域区间以整体分布优化算法划分为14个模糊区间,同理将二型观测量方位角和斜距也分为14个子区间。
[0133]
s8.3、根据三角隶属度函数将数据进行模糊化,把数据分配至各个模糊区间中。进而创建模糊关系。
[0134]
s8.4、根据相关系数的计算可以得出天顶距和方位角的相关系数为-0.3257,天顶距和斜距的相关系数为0.1884,方位角与斜距的相关系数为-0.8133。如果两个变量的相关系数为负即负相关,二型观测量对一型观测量的预测起不到预测作用。所以这也是选定天顶距为一型观测量的原因,同时选定斜距为其二型观测量。方位角数据舍去。
[0135]
s8.5、构建各观测量的一阶至高阶模糊逻辑关系组在相应模糊关系组中出现的频次,建立模糊向量,由于模型的观测量只有天顶距和斜距,所以只需要建立两个变量的频次向量即可。
[0136]
s8.6、求得一型观测量一阶频次向量所对应的权重和二型观测量所对应的权重,再通过上文所对应的一阶模糊逻辑向量频次求得模糊关系所对应的权重和模糊关系所对应的权重。计算最终的预测值,进而计算误差。
[0137]
s9、边坡失稳预警
[0138]
在获取天顶距(α)、方位角(β)、斜距(χ)之后,可以获取x、y、z三维坐标方向的位移,通过设置相邻位移值的差值阈值来进行边坡失稳预警。一般情况下,土质边坡的预警阈值为2cm,岩质边坡的预警阈值小于1cm。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1