基于人体骨骼关键点的视频流动作检测方法与流程
1.本发明涉及视频识别领域,具体涉及一种基于人体骨骼关键点的视频流动作检测方法。
背景技术:
2.动作检测主要是基于人体的姿态模型,对视频采集的动作画面进行识别,例如公开(公告)号 cn107194344a 的中国专利,就公开了一种自适应骨骼中心的人体行为识别方法。主要解决现有技术动作识别精度低的问题。其实现步骤是:1)从骨骼序列数据集中获取三维骨架序列,并对其进行预处理,得到坐标矩阵;2)根据坐标矩阵选择特征参数,自适应选择坐标中心,重新对动作进行归一化,得到动作坐标矩阵;3)通过dtw方法对动作坐标矩阵进行降噪处理,借助ftp方法减少动作坐标矩阵时间错位和噪声问题,再使用svm进行对动作坐标矩阵进行分类。本发明相比于现有的行为识别方法,有效地提高了识别精度。可应用于监控、视频游戏和人机交互。该技术解决的主要是短视频的动作识别,其主要应用场景主要在于一些门禁或安防识别系统中,对于长视频识别效果就很一般。在现有技术中针对短视频的动作分类有不错的效果,即输入为一个短视频,输出这个视频的动作分类。相关技术例如c3d、st-gcn、2s-agcn等。此类方法针对于长视频或者视频流的动作检测却无能为力。再者此类方法,对硬件的要求过高,难以达到实用的效果。
技术实现要素:
3.本发明的目的在于克服现有技术的不足,提供一种基于人体骨骼关键点的视频流动作检测方法,主要针对不定长视频的动作检测和识别。且在2080ti级别的gpu上能达到1倍实时的速度,使得视频动作检测和识别具有实用效。
4.本发明的目的是通过以下技术方案来实现的:基于人体骨骼关键点的视频流动作检测方法,该方法包括:1)利用一个m秒的滑动窗口,每次截取视频中的m秒,每秒n帧,得到m*n帧图像;2)将m*n帧图像分别进行人体骨骼关键点识别,取每帧中top k个骨骼关键点,这里的top k是表示一张图片里面会有多个人,需要按照一定规则取前k个,比如取置信度最高的k个,或者面积最高的k个。
5.3)将帧间骨骼数据根据欧式距离拆分为多个骨骼序列,即一个人一个骨骼序列;4)每个骨骼序列送入深度学习网络模型预测结果。
6.进一步的,所述3)中还包括一个骨骼数据归一化处理方法,包括:11)将坐标数据缩放到高1080,宽度适应;12)以骨骼中心为原点,平移整个骨骼数据,使得骨骼数据与图像分辨率无关,将骨骼数据乘以s0=1.0;13)计算后帧-前帧之前的关键点的位移数据,首帧为0, 然后将位移数据乘以s1=4.0;,其中s0用以调整归一化后特征数据空间信息的分布范围,s1用以调整归一化后特征
数据运动信息的分布范围;14)将骨骼关键点与位移数据相连堆叠在一起,形成训练以及预测的输入数据,最后得到相应的训练数据。
7.进一步的,所述骨骼中心是指两髋中间点。
8.进一步的,所述骨骼数据归一化到-0.5~0.5之间,处于激活函数tanh梯度最大范围,利于深度学习网络模型的训练收敛。概括来说,是基于大量统计信息,观察到归一化后的数据,大致分布在[-0.5, 0.5]区间。
[0009]
进一步的,所述深度学习网络模型预测方法是将骨骼序列 [x0, x1, x2,
ꢀ…
]输入一个双向循环神经深度学习网络模型,预测每帧的标签;输出结果例如:[o, o, o, o, o, b_t, i_t, i_t, i_t, i_t, i_t, o, o ,o ,o, o, b_z, i_z, i_z, i_z, i_z, i_z, i_z, i_z, i_z, i_z, o, o, o, o, o],其中o为无动作序列,非o为动作序列;该例中t为跳, z为转, b_为动作的开始,i_为动作的继续。
[0010]
进一步的,还包括一个训练数据集制作方法,包括:111)将待标注视频按照每秒10帧进行抽帧;112)以图像质量从高到底抽取10组;113)将其中一组数据人工打标,即将一个动作序列放入到对应的动作目录中;两个动作序列之间必须帧号必须不连续;114)剩余组数据,自动按照人工打标的数据自动分组;115)逐帧抽取骨骼关键点;116)将骨骼关键点数据按照前面所说的归一化方式进行归一化;117)随机组合训练数据为30~70的序列,其中包含动作序列和无动作序列;118)训练数据分为帧号序列和标签序列,分别存放于不同文件中。帧号对应的特征数据,也存放于一个单独的特征文件中。
[0011]
进一步的,单流模型的详细描述:输入数据为归一化的骨骼关键点数据;每帧一个,支持输入1~n帧;输入形状为(batch_size, seq_len, feat_num);经过线性变化和tanh激活;送入多层双向lstm深度学习网络模型;利用crf层强化序列标签转化关系;b_代表一个动作的开始,i_代表一个动作的继续,o代表无动作。
[0012]
o的下一个可以是o, b_,不可以是i_;b_的下一个可以是i_,不可以是b_, o;i_的下一个可以是i_,o,b_。
[0013]
本发明的有益效果是:本发明能针对长视频进行特征提取, 其识别准确率更高,适用于长时段的流媒体播放下的特征提取。
附图说明
[0014]
图1为归一化后的数据分布示意图(空间特征部分);图2为归一化后的数据分布示意图(运动特征部分);
图3为单流模型示意图;图4为三流融合模型示意图;图5为三流数据分别线性变化并tanh非线性激活示意图。
具体实施方式
[0015]
下面结合具体实施例进一步详细描述本发明的技术方案,但本发明的保护范围不局限于以下所述。
[0016]
利用一个m秒的滑动窗口,每次截取视频中的m秒,每秒n帧。将m*n帧图像分别进行人体骨骼关键点识别,取每帧中top k个骨骼关键点。然后将帧间骨骼数据根据欧式距离拆分为多个骨骼序列,即一个人一个骨骼序列,这里的top k是表示一张图片里面会有多个人,需要按照一定规则取前k个,比如取置信度最高的k个,或者面积最高的k个。
[0017]
由于原始骨骼数据是图像中的坐标,不利于深度学习网络模型的训练和预测,本方法对骨骼数据做了归一化,具体归一化方法如下。
[0018]
将坐标数据缩放到高1080,宽度适应。
[0019]
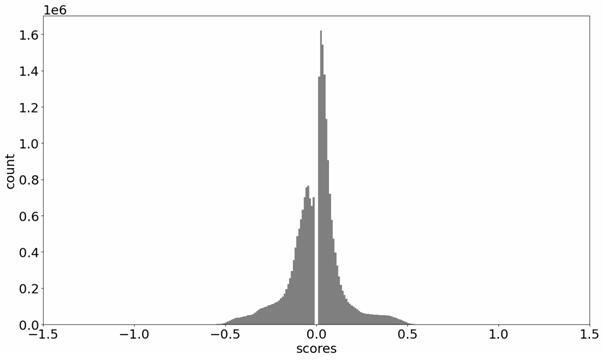
以骨骼中心(两髋中间点)为原点,平移整个骨骼数据,使得骨骼数据与图像分辨率无关,将骨骼数据乘以s0=1.0。数据分布如图1:计算后帧-前帧之前的关键点的位移数据,首帧为0, 然后将位移数据乘以s1=4.0。数据分布如图2:,其中s0用以调整归一化后特征数据空间信息的分布范围,s1用以调整归一化后特征数据运动信息的分布范围。
[0020]
将骨骼关键点与位移数据相连堆叠在一起,形成训练以及预测的输入数据。将数据归一化到-0.5~0.5之间,处于激活函数tanh梯度最大范围,利于深度学习网络模型的训练收敛。
[0021]
例如:1、提取原图骨骼关键点包括67个关键点,其中25个身体关键点位、21个左手关键点位和21个右手关键点位,每个关键点由(横坐标,纵坐标)组成,坐标原点为图像左上角。
[0022]
输入图像示例(分辨率544x960):输出示例s1out:输出为一个134维度的数组,每两个值为一个关键点位。
[0023]
[315, 368, 302, 428, 263, 428, 242, 502, 242, 562, 342, 428, 397, 399, 386, 349, 302, 557, 271, 560, 260, 660, 250, 743, 326, 557, 336, 659, 342, 746, 305, 360, 323, 363, 286, 368, 331, 371, 352, 788, 365, 783, 328, 757, 252, 773, 239, 767, 255, 746, 382, 348, 375, 348, 365, 343, 357, 337, 352, 333, 365, 325, 358, 315, 353, 310, 350, 305, 372, 322, 366, 310, 364, 301, 362, 293, 378, 321, 374, 308, 372, 301, 371, 293, 385, 321, 386, 313, 387, 308, 388, 305, 256, 569, 244, 568, 241, 583, 240, 592, 240, 599, 243, 578, 242, 589, 240, 595, 241, 601, 244, 577, 241, 586, 242, 592, 242, 600, 245, 579, 240, 584, 242, 590, 242, 601, 244, 580, 241, 597, 240, 597, 241, 601]2、将纵坐标缩放到1080大小,横坐标缩放相同比例。
[0024]
此例中:
y_scale = 1080/960=1.125, 将第一步中的全部67*2=134个值全部乘以y_scale,得到s2out:[354.375, 414.0, 339.75, 481.5, 295.875, 481.5, 272.25, 564.75, 272.25, 632.25, 384.75, 481.5, 446.625, 448.875, 434.25, 392.625, 339.75, 626.625, 304.875, 630.0, 292.5, 742.5, 281.25, 835.875, 366.75, 626.625, 378.0, 741.375, 384.75, 839.25, 343.125, 405.0, 363.375, 408.375, 321.75, 414.0, 372.375, 417.375, 396.0, 886.5, 410.625, 880.875, 369.0, 851.625, 283.5, 869.625, 268.875, 862.875, 286.875, 839.25, 429.75, 391.5, 421.875, 391.5, 410.625, 385.875, 401.625, 379.125, 396.0, 374.625, 410.625, 365.625, 402.75, 354.375, 397.125, 348.75, 393.75, 343.125, 418.5, 362.25, 411.75, 348.75, 409.5, 338.625, 407.25, 329.625, 425.25, 361.125, 420.75, 346.5, 418.5, 338.625, 417.375, 329.625, 433.125, 361.125, 434.25, 352.125, 435.375, 346.5, 436.5, 343.125, 288.0, 640.125, 274.5, 639.0, 271.125, 655.875, 270.0, 666.0, 270.0, 673.875, 273.375, 650.25, 272.25, 662.625, 270.0, 669.375, 271.125, 676.125, 274.5, 649.125, 271.125, 659.25, 272.25, 666.0, 272.25, 675.0, 275.625, 651.375, 270.0, 657.0, 272.25, 663.75, 272.25, 676.125, 274.5, 652.5, 271.125, 671.625, 270.0, 671.625, 271.125, 676.125]3、坐标点归一化到人体中心点。
[0025]
参考上图“身体关键点位图”,以身体第8个关键点(s2out标红)为中心点,即第二步输出中(s2out[16], s2out[17])的两个值。计算67个关键点的相对位置。即全部横坐标减去s2out[16], 全部纵坐标减去s2out[17]。
[0026]
以第一个点(354.375, 414.0)为例, 变换后为:(354.375, 414.0)-(s2out[16], s2out[17])=(354.375, 414.0)
-ꢀ
(339.75, 626.625)= (354.375-339.75, 414.0-626.625)= (14.625,
ꢀ-
212.625), 然后将得到的相对坐标除以1080,得到 (0.01354,
ꢀ-
0.19687),再乘以s0=1.0用以调节输出值得分布范围,这里默认取1.0,相当于不做调节。
[0027]
全部67个点位经过变换后得到s3out:[0.01354,
ꢀ-
0.19687, 0.0,
ꢀ-
0.13437,
ꢀ-
0.04063,
ꢀ-
0.13437,
ꢀ-
0.0625,
ꢀ-
0.05729,
ꢀ-
0.0625, 0.00521, 0.04167,
ꢀ-
0.13437, 0.09896,
ꢀ-
0.16458, 0.0875,
ꢀ-
0.21667, 0.0, 0.0,
ꢀ-
0.03229, 0.00313,
ꢀ-
0.04375, 0.10729,
ꢀ-
0.05417, 0.19375, 0.025, 0.0, 0.03542, 0.10625, 0.04167, 0.19687, 0.00313,
ꢀ-
0.20521, 0.02187,
ꢀ-
0.20208,
ꢀ-
0.01667,
ꢀ-
0.19687, 0.03021,
ꢀ-
0.19375, 0.05208, 0.24063, 0.06563, 0.23542, 0.02708, 0.20833,
ꢀ-
0.05208, 0.225,
ꢀ-
0.06563, 0.21875,
ꢀ-
0.04896, 0.19687, 0.08333,
ꢀ-
0.21771, 0.07604,
ꢀ-
0.21771, 0.06563,
ꢀ-
0.22292, 0.05729,
ꢀ-
0.22917, 0.05208,
ꢀ-
0.23333, 0.06563,
ꢀ-
0.24167, 0.05833,
ꢀ-
0.25208, 0.05312,
ꢀ-
0.25729, 0.05,
ꢀ-
0.2625, 0.07292,
ꢀ-
0.24479, 0.06667,
ꢀ-
0.25729, 0.06458,
ꢀ-
0.26667, 0.0625,
ꢀ-
0.275, 0.07917,
ꢀ-
0.24583, 0.075,
ꢀ-
0.25938, 0.07292,
ꢀ-
0.26667, 0.07187,
ꢀ-
0.275, 0.08646,
ꢀ-
0.24583, 0.0875,
ꢀ-
0.25417, 0.08854,
ꢀ-
0.25938, 0.08958,
ꢀ-
0.2625,
ꢀ-
0.04792, 0.0125,
ꢀ-
0.06042, 0.01146,
ꢀ-
0.06354, 0.02708,
ꢀ-
0.06458, 0.03646,
ꢀ-
0.06458, 0.04375,
ꢀ-
0.06146, 0.02187,
ꢀ-
0.0625, 0.03333,
ꢀ-
0.06458, 0.03958,
ꢀ-
0.06354, 0.04583,
ꢀ-
0.06042, 0.02083,
ꢀ-
0.06354, 0.03021,
ꢀ-
0.0625, 0.03646,
ꢀ-
0.0625, 0.04479,
ꢀ-
0.05937, 0.02292,
ꢀ-
0.06458, 0.02813,
ꢀ-
0.0625, 0.03438,
ꢀ-
0.0625, 0.04583,
ꢀ-
0.06042, 0.02396,
ꢀ-
0.06354, 0.04167,
ꢀ-
0.06458, 0.04167,
ꢀ-
0.06354, 0.04583]统计大量数据得到以下分布图,其中横坐标为归一化以后的取值,纵坐标为各取值的计数,纵坐标单位为百万次(1e6)。观察图2可以发现位于(-0.5,0.5)这个区间的数值为绝大多数,相当于数据大致归一化到了(-0.5,0.5)之间。如果需要将数据归一化到(-1,1)之间,则仅需调整参数s0=2.0即可。
[0028]
4、通过1、2、3步以后,得到了最终特征数据的前半部分,即空间位置特征部分。还需要继续获取运动特征信息。获取运动特征信息的过程相对来说比较简单。
[0029]
假设有相邻的两帧图像,f0,f1,分别做1,2的变换后得到s2out0, s2out1,则运动数据为(s2out1
-ꢀ
s2out0)/1080*s1,这里引入参数s1,作用是调整运动特征部分的取值范围,使得其与空间特征部分取值范围接近,利于后续的神经深度学习网络模型训练。当s1=4.0时,运动特征数据的分布图2。
[0030]
统计大量运动特征数据得到以下分布图,其中横坐标为归一化以后的取值,纵坐标为各取值的计数,纵坐标单位为百万次(1e6)。
[0031]
5、将空间特征和运动特征前后拼接在一起形成一个268维的特征向量。
[0032]
将骨骼序列 [x0, x1, x2,
ꢀ…
]输入一个双向循环神经深度学习网络模型,预测每帧的标签。输出结果例如:[o, o, o, o, o, b_t, i_t, i_t, i_t, i_t, i_t, o, o ,o ,o, o, b_z, i_z, i_z, i_z, i_z, i_z, i_z, i_z, i_z, i_z, o, o, o, o, o],其中o为无动作序列,非o为动作序列。该例中t为跳, z为转, b_为动作的开始,i_为动作的继续。
[0033]
骨骼数据的归一化方法,如上所述。
[0034]
采用双向循环深度学习网络模型bi-lstm + 条件随机场crf。
[0035]
训练数据整个序列随机缩放,以及动作序列之间必须包含无动作的序列。
[0036]
训练数据集的制作(训练视频数据只能包含单个人)。
[0037]
将待标注视频按照每秒10帧进行抽帧。
[0038]
以图像质量从高到底抽取10组。
[0039]
将其中一组数据人工打标,即将一个动作序列放入到对应的动作目录中。两个动作序列之间必须帧号必须不连续。
[0040]
剩余组数据,自动按照人工打标的数据自动分组。
[0041]
逐帧抽取骨骼关键点。
[0042]
将骨骼关键点数据按照前面所说的归一化方式进行归一化。
[0043]
随机组合训练数据为30~70的序列,其中包含动作序列和无动作序列。
[0044]
训练数据分为帧号序列和标签序列,分别存放于不同文件中。帧号对应的特征数据,也存放于一个单独的特征文件中。
[0045]
深度学习网络模型模型本实施例中采用端到端,单流模型,其原理参考图3所示。
[0046]
三流融合模型,参考图4所示:
流1 :骨骼数据,骨骼数据是有关联的骨骼关键点之间的长度。关联关系例如,腕关节-肘关节,肘关节-建关键。该数据可由空间特征计算生成。
[0047]
流2:关节数据,关节数据即前文提到的归一化特征数据的空间部分流3:运动数据。
[0048]
三流数据分别线性变化并tanh非线性激活,其原理参考图5所示。
[0049]
参考图3,单流模型的详细描述。
[0050]
输入数据为归一化的骨骼关键点数据。每帧一个,支持输入1~n帧。输入形状为(batch_size, seq_len, feat_num)。
[0051]
经过线性变化和tanh激活。
[0052]
送入多层双向lstm深度学习网络模型。
[0053]
利用crf层强化序列标签转化关系。
[0054]
动作序列需以b_开头。
[0055]
b_的下一个不会是o。
[0056]
b_的下一个为该动作的继续动作及i_。
[0057]
视频流动作检测和识别。
[0058]
以一个滑动窗口m秒,步长s秒,依时间序滑过视频。
[0059]
每个窗口抽取x帧图片。
[0060]
提取各帧人物骨骼关键点。
[0061]
将骨骼关键点按照欧式距离远近组合为多个骨骼序列。
[0062]
每个骨骼序列送入深度学习网络模型预测结果。
[0063]
以上所述仅是本发明的优选实施方式,应当理解本发明并非局限于本文所披露的形式,不应看作是对其他实施例的排除,而可用于各种其他组合、修改和环境,并能够在本文所述构想范围内,通过上述教导或相关领域的技术或知识进行改动。而本领域人员所进行的改动和变化不脱离本发明的精神和范围,则都应在本发明所附权利要求的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1