一种多模态深度神经网络的特征融合方法与流程
[0001]
本发明涉及医学影像领域和深度学习领域,尤其涉及一种多模态深度神经网络的特征融合方法。
背景技术:
[0002]
现有的肿瘤检测诊断手段通常通过医学影像技术实现的,包括平面x光成像、ct、mri、pet/ct、超声等模态,对从影像中发现的可疑病灶进行组织活检。但由于肿瘤具有异质性的原因,其性质并不能被单一模态影像上全部表征。如在平面x光和ct影像上,所表征的是肿瘤组织对x射线的吸收程度;而在mri影像上,所表征的是肿瘤组织的氢质子密度;在fdg pet/ct上,所表征的是肿瘤组织代谢葡萄糖的活度;在超声影像上,所表征的是肿瘤组织的对声波的反射程度。因此,现在越来越多基于多模态影像的临床研究,旨在提供更加全面的、综合的、多维度的诊断和预后预测的指标,帮助医生制定治疗方案,从而实现精准医疗。
[0003]
深度卷积神经网络(convolutional neural network,cnn)是近年构建医学人工智能模型的常用方法之一,它通过多层的卷积处理提取图像的高阶特征信息,同时结合池化处理以降低特征的维度,所提取的高阶特征则输入后续特定网络进行特定任务,如分类、分割、配准、检测、降噪等。目前有越来越多的基于多模态影像的研究使用cnn进行,其诊断效能比单一模态有显著的提升。
[0004]
关于现有的基于cnn的多模态智能诊断模型,基本上使用以下三种方法进行各个模态之间的特征融合:(1)多支路:有多条深度卷积神经网络分支,每条分支负责一个模态卷积计算,在每条分支的同一分级上,对所有深度特征图进行相加融合;(2)多通道:在数据输入的时候,把不同模态的图像叠加成一个多通道图像作为输入;(3)图像融合:在数据输入的时候,使用特定的图像融合算法,把多个模态的图像进行融合,获得一个单通道的融合图像作为输入。而这些方法都没有对各个模态的特征权重分布进行分析和处理,只是进行了简单的直接相加、叠加或融合。本发明提出的方式是对深度学习特征域上,对模态、通道、空间中具有重要信息的位置给予更大的关注,从而提高多模态智能诊断系统的诊断效能。
技术实现要素:
[0005]
本发明的目的在于针对现有技术的不足,提供了一种多模态深度神经网络的特征融合方法。在多模态深度三维cnn里,利用压缩激励(squeeze and excitation, s&e)模块,可获得关于模态之间的通道注意力掩膜,即在所有模态中,给予那些对于任务目标有着显著帮助的通道更大的关注,从而显式地建立了多模态三维深度特征图在通道上的权重分布;随后,利用四维卷积和sigmoid激活函数计算,可获得关于模态之间的空间注意力掩膜,即在每个模态的三维特征图中,空间中哪些位置需要给予更大的关注,从而显式地建立了多模态三维深度特征图在空间上的相关性。
[0006]
本发明的目的是通过以下技术方案来实现的:一种多模态深度神经网络的特征融
合方法,具体包括:步骤一:在多分支(multi-branch,mb)的多模态(multi-modality,mm)深度cnn中,将每个分支的第n级输出的三维特征图在通道维度上进行叠加,获得一个原通道数x倍的三维特征图,x表示分支数;对其在深、高、宽三个维度上进行平均池化,并压缩获得一个通道维度的一维向量;对一维向量进行下采样上采样处理,并使用激活函数sigmoid计算后获得多模态通道注意力掩膜;将多模态通道注意力掩膜与原通道数x倍的三维特征图进行相乘获得多模态三维特征图,将多模态三维特征图在通道上按原分支模态下的通道数进行拆分,获得在多模态上加权后的x个单模态三维特征图;其中,每个模态输出的三维特征图其通道数、深、高、宽均相同。
[0007]
步骤二:对多模态三维特征图在通道维度上进行一维平均池化和一维最大池化计算获得两个池化后的三维特征图,在两个池化后的三维特征图中分别新建模态维,并在模态维上进行叠加得到一个四维特征图;使用x个四维卷积核对四维特征图进行卷积,使四维卷积核学习如何获得x个模态在空间上的权重分布。其中,卷积输出的通道数为x,分别对应于每个模态;对每个输出使用激活函数sigmoid 进行计算,并在模态维度上进行压缩,获得x个单模态空间注意力掩膜;步骤三:将步骤二获得的单模态空间注意力掩膜与步骤一获得的单模态三维特征图按对应的模态进行相乘,获得多模态融合特征图,完成多模态的特征融合。
[0008]
进一步地,所述步骤一获得的单模态三维特征图作为对应分支下一级特征融合的输入。
[0009]
进一步地,所述模态包括平面x光成像、ct、mri、pet/ct、超声图等中的至少两种。
[0010]
进一步地,多分支的多模态深度卷积神经网络为resnet、faster rcnn、u-net或centernet。
[0011]
本发明的有益效果是,本发明利用了多模态通道和空间注意力机制,使得多模态深度特征图在多支路深度cnn的每一级上可以进行更加精巧的融合,对多模态特征图中关于通道、模态、空间中具有重要性信息的位置给予更大关注,从而最大化多模态深度cnn智能诊断模型的性能。
附图说明
[0012]
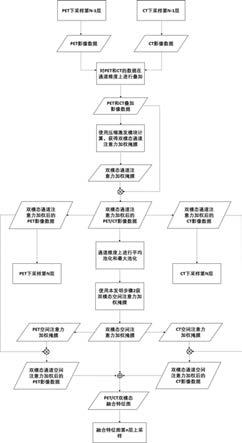
图1是本发明以pet/ct双模态为例的双模态深度特征融合方法的流程图;图2是u-net网络结构示意图。
具体实施方式
[0013]
下面以pet/ct双模态为例(即x=2时),结合附图详细说明本发明。
[0014]
如图1所示,本发明方法具体包括如下步骤:步骤一:在双分支的双模态三维cnn中,两条分支分别对应着pet模态的卷积支路和ct模态的卷积支路。对于两个所述三维卷积支路的第n级输出的三维特征图,将两个模态的三维特征图在通道维度上进行叠加,获得一个原通道数两倍的三维特征图。接着对其在深、高、宽三个维度上进行平均池化,并压缩深、高、宽三个维度,可获得一个通道维度的一维向量。对其以压缩比16:1:16进行下采样上采样处理后,并使用激活函数sigmoid计算后,获得
双模态pet-ct特征图关于各个通道的权重分布,即双模态通道(时序)注意力掩膜。最后把该双模态通道注意力掩膜与先前叠加的原通道数两倍的三维特征图进行相乘,随后在通道上按1:1进行拆分,可获得在pet-ct模态上加权后的两个单模态三维特征图。具体包括以下子步骤:(1.1)在双支路深度三维cnn的第n级中,ct支路的特征图为u
ct (c, d, h, w),pet支路的特征图为u
pt (c, d, h, w),首先对ct和pet支路的三维特征图在通道维度上进行叠加,获得叠加三维特征图u
stack (2
×
c, d, h, w);其中,c, d, h, w分别表示通道、深度、高度和宽度。
[0015]
(1.2)使用公式(1)对叠加三维特征图在深度、高度、宽度这三个维度上进行平均池化获得z
stack (2
×
c, 1, 1, 1),并对这三个维度进行压缩,可获得池化后三维特征图z
stack (2
×
c); (1)式中c
n
为第n级输出的通道数,d
n
、h
n
、w
n
分别为第n级输出的三维特征图的深度、高度、宽度的大小,c
n
优选为可以被16整除的数。
[0016]
(1.3)对步骤(1.2)获得的池化后三维特征图z
stack (2
×
c)在通道维度上按公式(2)进行压缩比16:1:16的线性下采样上采样计算,每次采样后都会叠加一次激活函数的计算,最后获得关于通道的双模态通道注意力掩膜s(2
×
c)。其中w
a
为c
n
’
/16
×
c
n
’
大小的矩阵,w
b
为c
n
’×
c
n
’
/16大小的矩阵,δ为relu函数,σ为sigmoid函数,c
n
’
=2
×
c
n
;
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)(1.4)使用步骤(1.3)获得的双模态通道注意力掩膜,利用广播机制拓展深、高、宽维度为s(2
×
c, d, h, w),对步骤(1.1)获得的叠加三维特征图进行相乘(公式(3)),可获得基于双模态注意力掩膜校正的叠加双模态三维特征图u
stack ’
(2
×
c, d, h, w),最后按各模态原通道数量把叠加三维特征图切片ct和pet按1:1进行拆分校正后得到两个单模态三维特征图分别为u
ct ’
(c, d, h, w)和u
pt ’
(c, d, h, w);(3)步骤二:对叠加双模态三维特征图在通道维度上分别进行一维平均池化和一维最大池化计算获得两个池化后的三维特征图,在两个池化后的三维特征图中分别新建模态维,并在模态维上进行叠加得到一个四维特征图,各维度分别为模态、深、高、宽;对于四维特征图,使用2个四维卷积核对四维特征图进行卷积,使其该四维卷积核学习如何获得两个模态在空间上的权重分布。该四维卷积输出的通道数为2,分别对应于两个模态,即四维卷积输出的融合四维特征图的两个通道对应pet和ct,对其输出使用激活函数sigmoid 进行计算,并对模态维度进行压缩,即可获得单模态空间注意力掩膜。具体包括以下子步骤:(2.1)对于步骤(1.4)获得的经过双模态通道注意力掩膜加权的双模态三维特征图u
stack ’
(2
×
c, d, h, w),分别对它进行在通道维度上的一维平均池化和一维最大池化计算,可获得u
mean
’
(c, d, h, w)和u
max ’
(c, d, h, w)。对这两个经过池化计算的三维特征图分别新建立一个称为模态维的维度m,并把它们在模态维上进行叠加,获得一个双模态四维特征图p
stack (c, m, d, h, w);
(2.2)对步骤(2.1)获得的双模态四维特征图使用输出通道数为2、核尺寸为(2,3,3,3)、步长为(1,1,1,1)、填充为(0,1,1,1)的四维卷积核kernel
4d
进行卷积并经过sigmoid函数σ计算(公式4,其中*表示卷积),获得的双通道四维特征图为双模态空间注意力掩膜p
stack ’
(c, m, d, h, w),其中m=1,c=2。此处可规定通道与模态的对应关系,例如以通道一对应ct、通道二对应pet,提取模态对应通道的四维特征图并对模态维进行压缩,可分别获得ct和pet对应的模态空间注意力掩膜p
ct ’
(c, m, d, h, w)和p
pt ’
(c, m, d, h, w);
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)步骤三:对于步骤(1.4)获得的ct和pet模态特征图和步骤(2.2)获得的ct和pet模态的注意力掩膜,通过公式(5)进行融合,最后获得通过双模态通道空间注意力掩膜加权的pet/ct双模态融合特征图u
fusion
,该融合特征图既考虑两个模态在通道之间的注意力权重,也考虑了两个模态在空间上的注意力权重;
ꢀꢀ
(5)对于计算各自分支下一级(n+1)的单模态三维特征图,将会使用步骤(1.4)获得的经过双模态通道注意力计算后的ct和pet三维特征图u
ct ’
(c, d, h, w)和u
pt ’
(c, d, h, w)进行下一级(n+1)多模态融合特征图的计算。
[0017]
以下以深度卷积神经网络dla34为例子,讲解具体的如何将本发明方法用于深度卷积神经网络上。
[0018]
dla-34网络结构(出自fisher yu, dequan wang, evan shelhamer, and trevor darrell. deep layer aggregation. in proceedings of the ieee conference on computer vision and pattern recognition, pages 2403
–
2412, 2018)在实际的实施过程中,如pet/ct双模态特征融合,需对dla-34拓展其下采样部分,把其拓展成双支路形式(如图2所示),即一个支路对应一个模态的下采样,然后在每一级的融合结点用本发明作双模态特征融合,所融合的特征用于下一级上采样部分的输入。具体实施步骤如下:(1)输入pet/ct双模态数据,支路1输入ct影像数据,支路2输入pet影像数据;(2)在下采样模块的每个融合结点中,对于支路1、2输出的三维特征图,使用本发明的方法进行了特征融合,并作为残差项输出到上采样部分。同时,对于使用本发明获得的经过双模态通道注意力计算后的支路1、2单模态三维特征图,将会作为下一级的输入(图2中,原图1/8的三维特征图融合得到的单模态三维特征图作为原图1/16下采样模块融合的输入)进行特征融合和下采样处理。如此类推,直到下采样末端。
[0019]
(3)上采样过程保持和原单支路一样,只是输入的特征图是使用发明进行特征融合的双模态特征图。
[0020]
由于多模态特征图中关于通道、模态、空间中具有重要性信息的位置给予更大关注,从而可以最大化上锁多模态深度cnn智能诊断模型的性能。
[0021]
此外,在深度二维卷积神经网络中,同样可以使用本发明方法。具体方法同上,不同的地方只在于没有深度维度(d,depth)。
[0022]
显然,上述实施例仅仅是为清楚地说明所作的举例,而并非对实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其他不同形式的变化或变动。这里无需也无法把所有的实施方式予以穷举。而由此所引申出的显而易见的变化或
变动仍处于本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1