一种人员目标指数计算方法及装置与流程
1.本发明涉及人员领域,具体涉及一种人员目标指数计算方法及装置。
背景技术:
2.目前现有的计算人员目标指数的方法大多依赖在日常中总结的经验规则,根据命中规则的多少来决定人员目标指数的高低。这种方法仅从业务规则层面显式的反映了人员指数的差异,没有从数据层面体现人员潜在的行为差异。此外,目标指标人员的定义是一个模糊的概念,它包含了多个不同类型的标签人员,因此采用单个标签人员模型去发现人员行为特征中潜藏的数据模式差异又缺乏全面性。
技术实现要素:
3.鉴于现有技术中存在的技术缺陷和技术弊端,本发明实施例提供克服上述问题或者至少部分地解决上述问题的一种人员目标指数计算方法及装置,具体方案如下:
4.一种人员目标指数计算方法,所述方法包括:
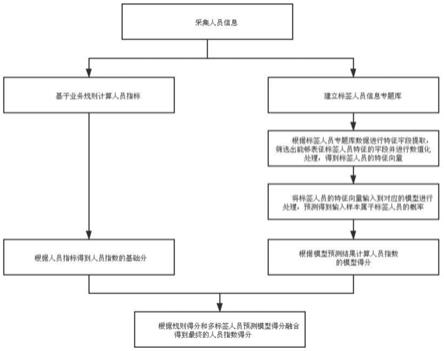
5.s01,采集人员信息;
6.s02,基于业务规则计算人员指标;
7.s03,根据人员指标确定人员目标指数的基础分,即规则得分;
8.s04,建立标签人员信息专题库;
9.s05,基于标签人员信息专题库数据进行特征字段提取,筛选出能够表征标签人员特征的字段并进行数值化处理,得到标签人员的特征向量;
10.s06,将标签人员的特征向量输入到标签人员预测模型进行处理,预测得到输入样本属于标签人员的概率;
11.s07,根据标签人员预测模型预测结果计算人员目标指数的模型得分;
12.s08,根据规则得分和标签人员预测模型得分融合得到最终的人员目标指数得分。
13.进一步地,人员目标指数模型得分的计算公式如下:
14.s
model
=∑a
i
w
i log2p
i
;
15.其中,p
i
为标签人员预测模型预测输入样本为正样本与标签人员模型预测输入样本为负样本的概率之比;a
i
为对应标签人员预测模型的权重;w
i
为对应标签人员预测模型的得分权重。
16.进一步地,最终的人员目标指数得分的计算公式如下:
17.score=rule_score+∑a
i
w
i log2p
i
;
18.其中,rule_score为人员指标确定人员目标指数的基础分,即规则得分。
19.进一步地,s01中,人员信息包括人员基本数据、户籍地高危信息数据、人员出行方式信息数据、人员活动位置信息数据、违法人员基本信息数据以及标签人员信息专题库。
20.进一步地,s02中,具体的人员指标计算规则如下:
21.指标一:户籍地属于相关地区范畴;
22.指标二:年龄段在预设年龄范围之间;
23.指标三:属于第一类人员;
24.指标四:属于第二类人员;
25.指标五:与相关人员存在关联关系;
26.指标六:某一行为异常频繁指标;
27.指标七:第一预设时间内跨市超过n次。
28.进一步地,s03中,根据人员指标确定人员目标指数的基础分具体为:
29.基于人员命中的指标以及预设的爆点规则计算人员目标指数的基础分。
30.进一步地,s06中,采用监督学习算法训练得到标签人员预测模型。
31.作为本发明的第二方面,提供一种人员目标指数计算装置,所述装置包括信息采集模块、指标计算模块、基础分计算模块、标签人员信息专题库构建模块、特征向量提取模块、标签人员概率计算模块、模型得分计算模块以及最终得分计算模块;
32.所述信息采集模块用于采集人员信息;所述指标计算模块用于基于业务规则计算人员指标;所述基础分计算模块用于根据人员指标确定人员目标指数的基础分,即规则得分;所述标签人员信息专题库构建模块用于建立标签人员信息专题库;所述特征向量提取模块用于基于标签人员信息专题库数据进行特征字段提取,筛选出能够表征标签人员特征的字段并进行数值化处理,得到标签人员的特征向量;所述标签人员概率计算模块用于将标签人员的特征向量输入到标签人员预测模型进行处理,预测得到输入样本属于标签人员的概率;所述模型得分计算模块用于根据标签人员预测模型预测结果计算人员目标指数的模型得分;所述最终得分计算模块用于根据规则得分和标签人员预测模型得分融合得到最终的人员目标指数得分。
33.进一步地,人员目标指数模型得分的计算公式如下:
34.s
model
=∑a
i
w
i log2p
i
;
35.其中,p
i
为标签人员预测模型预测输入样本为正样本与标签人员模型预测输入样本为负样本的概率之比;a
i
为对应标签人员预测模型的权重;w
i
为对应标签人员预测模型的得分权重。
36.进一步地,最终的人员目标指数得分的计算公式如下:
37.score=rule_score+∑a
i
w
i log2p
i
;
38.其中,rule_score为人员指标确定人员目标指数的基础分,即规则得分。
39.本发明具有以下有益效果:
40.本发明基于现有技术中的不足,创新性的提出了一种基于规则和标签人员预测模型的人员目标指数计算方法及装置,基于规则确定人员目标指数的基础分,实现从业务规则层面显式的反映了人员目标指标的差异,基于标签人员信息专题库数据进行特征字段提取,筛选出能够表征标签人员特征的字段并进行数值化处理,得到标签人员的特征向量,并通过标签人员预测模型预测输入样本属于标签人员的概率模型得分,实现从数据层面体现人员潜在的行为差异,最后根据规则得分和标签人员预测模型得分融合得到最终的人员目标指数得分,相比于现有技术,本发明的计算方法更加准确。
附图说明
41.图1为本发明实施例提供的一种人员目标指数计算方法的流程图。
具体实施方式
42.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
43.如图1所示,作为本发明的第一实施例,提供一种人员目标指数计算方法,所述方法包括以下步骤:
44.s01:采集人员信息;
45.其中,人员信息包括人员基本数据、户籍地信息数据、人员出行方式信息数据、人员活动位置信息数据、人员基本信息数据以及标签人员信息专题库。
46.其中,人员基本数据字段如下表一所示:
47.说明名称姓名name证件号码card_id性别sex文化程度education家庭住址addess
48.表一
49.户籍地信息数据如下表二所示:
50.说明名称相关区域名称name相关区域编码code相关区域描述desc
51.表二
52.人员出行方式信息数据包括:火车、汽车等出行方式信息数据;
53.其中,火车出行方式信息数据如下表三所示:
54.说明名称姓名ry_xm身份证号ry_sfzh火车开车日期hpkcrq火车开车时间hckcsj座位号zwh起始站名称qszmc终点站名称zdzmc车厢号cxh
购票人姓名xm火车车次hccc
55.表三
56.人员活动位置信息数据包括:旅店、网吧等位置信息数据。
57.其中,旅店位置信息数据如下表四所示:
58.说明名称姓名ry_xm身份证号ry_sfzh入住时间rzsj退房时间tfsj旅馆单位名称lgdwmc旅馆单位地址lgdwdz房间号fjh
59.表四
60.网吧位置信息数据如下表五所示:
61.说明名称姓名ry_xm身份证号ry_sfzh上线时间sxsj下线时间xxsj网吧单位编码wbdwbm网吧单位名称wbdwmc网吧单位地址wbdwdz
62.表五
63.人员基本信息数据如下表六所示:
64.说明名称姓名ry_xm身份证号ry_sfzh人员类型ry_lx标签翻译信息bqxx
65.表六
66.人员信息数据详细见s04:建立标签人员信息专题库。
67.s02:基于业务规则计算人员指标。
68.具体的指标计算规则如下:
69.指标一:人员户籍地属于相关地区范畴;
70.指标二:人员年龄段在16
‑
55岁之间;
71.指标三:人员属于第一类人员;
72.指标四:人员属于第二类人员;
73.指标五:人员与相关人员关系分析(与相关人员同上网、同住宿、同火车、同飞机等);
74.指标六:人员异常频繁指标;频繁入住酒店,频繁夜间上网;
75.指标七:人员2月内跨市超过三次。
76.s03:根据人员指标得到人员目标指数的基础分。
77.根据人员目标指标指标的计算,可以得到人员命中的指标,参照预设的爆点规则可以得到人员目标指数的基础分。例如,单爆规则,基础分为200;双爆规则,基础分为400;三爆规则,基础分为600。本实例中假设人员命中了指标三和指标五,符合双爆规则,因此该人员的目标指数基础分为400。
78.以下为某一具体爆点规则说明:
79.1.单爆规则:属于高危地区人员或者6个月内被打处2次以上
80.2.双爆规则:
81.(一)指标三+指标五
82.(二)指标三+指标六
83.(三)指标五+指标六
84.(四)指标四(近6个月被打处次数1次)+指标五
85.(五)指标三+指标七
86.3.三爆规则:
87.(一)指标三+指标五+指标六
88.(二)指标四+指标五+指标六
89.需要说明的是,爆点规则由人为设定,并非必须为本发明实施例所述的一种。
90.s04:建立标签人员信息专题库。
91.本发明实例中,建立了多个标签人员信息专题库,这里以两种标签人员为例子来说明人员目标指数计算方法中模型预测得分的过程。
92.第一标签人员信息专题库包含了人员话单信息和行为记录信息。
93.第一标签人员话单信息如下表七所示:
94.说明名称人员编号uid电话号码phone_num对端号码opp_num开始时间start_time结束时间end_time通话时长call_duration通话了类型call_type主被叫in_out
95.表七
96.第一标签人员行为记录信息如下表八所示:
97.说明名称人员编号uid
人员手机号码phone_num时间action_time地点action_location
98.表八
99.第二标签人员信息专题库包含了人员的基本信息。
100.第二标签人员基本信息如下表九所示:
101.说明名称人员序号n_xh性别c_xb年龄c_nl文化程度c_whcd民族c_mz特别体貌特征c_tbtmtz婚姻状况c_hyzk健康状况c_jkzk第一标签龄d_dl第一标签类型n_sfzt场所c_xdcs种类ac_xsdpzl种类bc_zsdpzl是否为常住人口czrk是否有户籍变动hjbd是否被重点关注zdgz是否关联案件dpajyg种类cxsctdp种类dxsxxdp与第一标签同户类型ysdth是否与第一标签人员同住宿ysdtz
102.表九
103.s05:根据标签人员专题库数据进行特征字段提取,筛选出能够表征标签人员特征的字段并进行数值化处理,得到标签人员的特征向量。
104.结合第一标签业务的需要,和第一标签人员的话单信息,提取并筛选得到了能够表征该标签人员代表特性的相关特征,如下表十所示,包括:
[0105][0106]
表十
[0107]
结合第二标签业务的需要,和第二标签人员的基本信息,出行交通信息和活动位置信息,提取并筛选得到了能够表征第二标签人员代表特性的相关特征,如下表十一所示,具体包括:
[0108][0109]
表十一
[0110]
s06:将标签人员的特征向量输入到对应的模型进行处理,预测得到输入样本属于标签人员的概率。
[0111]
本发明实例中,采用监督学习算法(逻辑回归,决策树)训练得到标签人员预测模型,针对第一标签业务和第二标签业务分别训练得到了第一标签人员预测模型和第二标签人员预测模型,预测结果实例如下表十二:
[0112][0113]
表十二
[0114]
s07:根据标签人员预测模型预测结果计算人员目标指数的模型得分。
[0115]
本发明实例中人员目标指数模型得分的计算公式如下:
[0116][0117]
其中p
i
为标签人员预测模型预测输入样本为正样本/标签人员预测模型测输入样本为负样本;a
i
为各标签人员预测模型的权重;w
i
为各个标签人员预测模型的得分权重。本实例中训练得到了两种人员标签预测模型,分别是第一标签人员预测模型和第二标签人员预测模型。根据业务需要设定第一标签人员的模型权重a1=0.5,第二标签人员的模型权重a2=0.5;第一标签人员得分权重w1=50,第二标签人员得分权重w2=50。那么对于s06中的预测结果实例可以计算得到输入样本的属于第一标签人员概率与非第一标签人员概率之比p1=0.8456/0.1544;输入样本的属于第二标签人员概率与非第二标签人员概率之比p2=0.3427/0.6573。最终人员目标指数的模型得分为 a1*w1*log2(p1)+a2*w2*log2(p2)= 0.5*50*log2(0.8456/0.1544)+0.5*50*log2(0.3427/0.6573)=61.3326+ (
‑
23.4901)=37.8425。
[0118]
s08:根据规则得分和多标签人员预测模型得分融合得到最终的人员目标指数得分。
[0119]
本实例中,s03中人员的基础分为400,s07中的模型预测人员得分为 37.8425,因此最终的人员目标指数得分为400+37.8425=437.8425。
[0120]
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1