基于DDADSM跨被试迁移学习脑电精神状态检测方法与流程
本发明属于生物特征识别领域中的脑电信号识别领域,具体用到了一种基于双子空间映射的动态分布对齐(ddadsm,dynamicdistributionalignmentwithdual-spacemapping)跨被试迁移学习脑电精神状态检测方法。
背景技术:
疲劳驾驶是指驾驶人连续行车时间过长,产生的生理机能和心理机能的失调现象,由于疲劳驾驶所引起的交通事故越来越频繁给世界经济与社会发展带来严重损失,而有效的疲劳检测分类方法的提出将对这一严重的社会问题的缓解十分有利。
脑电波是一种自发的有节律的神经电活动,脑电信号是人脑活动的直接体现,可以快速的反映人的生理及心理变化过程,当前被认为是最便捷和有效的疲劳分析方法。随着脑电采集设备的不断更新,脑电作为生物信号特征用于疲劳检测的尝试被越来越多的研究学者采用。
当前基于脑电信号的疲劳检测方法主要有传统机器学习方法和基于深度学习的方法。传统的机器学习方法主要是通过提取不同频率范围内的脑电特征再使用分类器进行分类。由于脑电信号的独特性,跨被试差异即个体间的脑电信号的差异性总是存在,手工的提取特征与浅层的机器学习方法难以避免地存在特征提取依赖专家知识,操作繁杂,跨被试识别率不足等问题。深度学习方法通过采用大量的数据在已有的模型下训练自动提取信号的特征,从而实现对于脑电信号的分类工作,近几年已有很多学者将深度学习的技术应用到基于脑电的疲劳检测中去,并取得了较好的效果。但是基于深度神经网络的学习过程比较复杂,需要大量的标注数据、脑电信号的获取有时序性的特点,与图像、文本的获取相比大量数据的获取更加困难。
显然,采用少样本的脑电数据并且能够克服传统的机器学习方法的局限性将是脑电信号疲劳检测的重要突破。迁移学习技术可以通过相对少量样本,利用个体数据分布的相似性,将已经学习过的知识应用在新的领域上,目前已经被很多学者应用在脑电处理中。领域自适应学习是迁移学习的代表方法,能够利用信息丰富的源域样本来提升目标域模型的性能,目前主要的方法有:概率分布适配法、特征选择法和子空间学习法。领域自适应学习的方法已被很多学者引用,对于解决源域和目标域属于同一类任务但分布不同的情况效果显著。本发明所采用的基于双子空间映射动态分布对齐迁移学习的脑电疲劳检测方法,在迁移学习中属于领域自适应的方法。
技术实现要素:
(一)要解决的技术问题
本发明要解决的技术问题是:1、单一生物信号的脑电疲劳检测中识别率低并且依赖大量标签数据,跨被试检测效果差;2、传统的迁移学习的子空间投影方法将数据投影到一个公共的子空间或流形空间中,不能克服投影空间偏移带来的损失;3、由于脑电信号是非稳定的高维信号并且自身具有特殊性和复杂性的特点,源域和目标域数据并不服从相同分布,因此无论采取直接利用数据分布相同的计算方法还是将数据的条件分布和边缘分布采用相同权重的计算方法,均不能反映数据分布的真实状态。本发明所采用的基于双子空间映射动态分布对齐迁移学习的脑电疲劳检测方法能够较好的解决以上问题。通过实验发现,该方法在疲劳驾驶脑电数据的分类问题上能够取得很好的效果,能够为复杂脑电数据的处理提高新的研究手段。
(二)技术方案
为了解决上述技术问题,本发明提出了一种基于ddadsm的跨被试迁移学习脑电疲劳检测方法。
本发明的特点是:本发明与现有技术相比,主要有以下两方面的特点:1、本方法能够将预处理后的原始脑电源域数据和目标域数据进行统计学方法特征映射,映射到两个具有更好迁移能力的子空间中,能减少映射偏差,使跨被试迁移学习能力得到显著提升;2、现有的领域学习的方法中多采用非动态的数据分布对齐,忽略了数据统计特征分布的差异性,用动态分布对齐的方法能解决高维非稳定脑电信号数据分布复杂导致的迁移效果差的问题。以上两个特点能够使本方法在不依赖大量标签的情况下采用非深度学习的迁移学习方法取得显著的实验效果。
按照本发明提供的技术方案,以下是基于双子空间映射动态分布对齐的迁移学习的脑电疲劳检测方法的具体步骤:
步骤(1)、对原始脑电数据进行预处理,然后对其划分后获取源域和目标域数据;
所述预处理主要是数据合并、脑电预览、基线校正、带通滤波和独立成分分析。以上预处理手段用现有工具均能实现,属于现有成熟技术,故不详解。
本预处理工作能够有效去除噪声和干扰杂质因素,按照实验范式得到以被试为单位的数据,该数据将作为输入进行以下步骤的操作。
在步骤(2)之前需要人为划分源域和目标域。根据迁移学习的概念,定义带有标签的源域数据为
源域数据和目标域的边缘概率分别定义为ps(xs)和pt(xt),源域数据和目标域的条件概率分别定义为qs(ys|xs)和qt(yt|xt),yt为目标域的类别数据,ys是源域的类别标签。
由于本方法涉及到跨被试分类故将同一被试的脑电数据作为一个领域,包含特征信息和类别信息,并将所有被试依次作为目标域测试算法效果得到最终检测分类准确率。由于数据采集中已经获取了所有被试的类别信息,而在实际应用中目标域数据标签信息未知,故本方法中目标域的标记信息不作为实验输入使用,仅用作真实值用于验证数据分类准确率。
步骤(2)、脑电信号的特征提取
采用常规技术公共空间模式(csp,commonspatialpattern)算法进行共空间特征提取,将步骤(1)原始源域和目标域高维时域信号数据,通过共空间滤波器将其投影到低维空间。
2.1将源域数据归一化并分别计算两类(多类则任取两类)源域样本的协方差矩阵,并进行2.2-2.5步骤;
2.2根据步骤2.1得到的协方差矩阵累加并取平均,得到源域数据的混合空间协方差矩阵;
2.3计算步骤2.2得到的混合空间协方差矩阵的特征向量和特征值;
2.4对步骤2.3得到的特征值进行排序,选取最大值,求出白化特征值矩阵q;
2.5将步骤2.1不同类别源域样本的协方差矩阵与步骤2.4得到的白化特征值矩阵q进行变换,并做主分量分解得到共同特征向量n;共同特征向量n与白化特征值矩阵q进行公式(1)运算可得到共空间滤波器g:
g=ntq(1)
其中t表示转置。
2.6若待分类任务具有多类,则重复步骤2.1-2.5得到所有共空间滤波器,并相加求平均得到最终的共空间滤波器g’,经过特征提取之后得到的共空间特征为:
xs'=g’×xs
xt'=g’×xt(2)
其中x′t,x′s分别表示经过共空间特征提取之后的源域和目标域共空间特征。
步骤(2)提取共空间特征为常规技术,此处仅给出关键步骤,不做详细解释。
步骤(3)、源域数据目标域数据双子空间映射
所述源域数据和目标域数据双子空间模型表示如下:
其中α、θ、μ是平衡参数,为人为设定;
目标域特征方差采用公式(4)目标域数据的散度矩阵进行优化:
其中st表示目标域数据的散度矩阵,运算tr()表示矩阵的迹。
源域类间方差采用公式(5)源域数据的最大化类间散度矩阵进行优化:
其中sb是源域数据的类间散度矩阵;
源域类内方差采用公式(6)源域数据的最小化类内散度矩阵进行优化:
其中sw是源域数据的类内散度矩阵;
上述a、b分别表示源域的投影子空间、目标域的投影子空间;是利用步骤(2)处理得到的源域和目标域共空间特征学习两个耦合的投影变换,即将源域和目标域的共空间特征投影到相应的两个低维投影子空间a、b内,利用matlab编程工具的计算特征值和特征向量的函数eigs()能够求解出子空间映射a和子空间映射b,其矩阵表示为:
其中,i是单位矩阵。
步骤(4)、动态数据分布适应对齐
对进行步骤(3)的源域和目标域子空间数据进行动态的边缘分布对齐和条件分布对齐,估算动态自适应系数η,并采用计算mmd(maximummeandiscrepancy)距离的方式来分别计算源域和目标域数据的边缘概率和条件概率的分布距离。
4.1生成目标域伪标签。由于目标域的标签是未知的,所以目标域的条件分布的具体类别c不能够直接求出,采用低时间复杂度的knn分类器的方法通过少量次(10次以内)迭代生成较为可靠的伪标签的方式得到类别标签。
4.2用mmd距离来度量源域数据和目标域数据的边缘分布和条件分布在再生核希尔伯特空间(rkhs,reproducingkernelhilbertspaces)的距离。
源域与目标域数据的边缘分布距离表示为:
df(ps(xs),pt(xt))=||e(f(a))-e(f(b))||rk2(5)
其中,e(f(a))表示源域子空间在rkhs投影之后的样本,e(f(b))表示目标域子空间在rkhs投影之后的样本。rk表示rkhs。
类似地,源域与目标域条件分布表示为:
其中,e(f(a(c)))表示使用带有类别信息的源域子空间样本在rkhs上投影,e(f(b(c))表示使用带有伪标签信息的目标域样本在rkhs上投影。
4.3a-distance方法估计动态自适应系数η。采用a-distance的计算方法估计不同分布之间的距离,建立一个线性分类器区分两个数据领域的hinge损失。
本发明的自适应系数η采用的是交叉验证的方法利用步骤4.1生成的伪标签不断迭代生成,其中a-distance定义为:
da(ds,dt)=2(1-2ε(g))(7)
其中,ε(g)表示利用简单的线性分类器区分源域和目标域数据分布的误差。可以计算边缘分布和条件分布的适配量分别表示为:
dm=da(ds,dt),do(c)=da(ds(c),dt(c))(8)
其中,dm表示边缘分布的a-distance,do(c)表示第c类源域数据条件分布的a-distance,dt(c)和ds(c)分别第c类的源域数据和目标域数据。
用这种方法可以通过不断迭代更新的方式可以估计出η:
4.4根据步骤4.2-4.3源域和目标域的动态分布对齐可以表示为:
其中,用
引用核矩阵具体可以化简为:
其中,k为核矩阵,是源域和目标域数据使用径向基核函数得到的矩阵,并且k∈r(n+m)×(n+m);β是所求的系数矩阵,m为mmd矩阵,表示为:
其中,mm、
步骤(5)、基于srm原则构建全局学习分类器。
通过srm(structuralriskminimizatin)原则增加l2范数项和拉普拉斯正则化项,将子空间数据转化至再生希尔伯特空间内学习一个域不变的分类器f。
拉普拉斯正则化表示如下:
其中,
总模型表示为:
这里
通过核技巧代入并整合公式可以得到分类器如下表示:
对公式求偏导
本发明的另一个目的是提供一种计算机可读存储介质,其上存储有计算机程序,当所述计算机程序在计算机中执行时,令计算机执行上述的方法。
本发明的又一个目的是提供一种计算设备,包括存储器和处理器,所述存储器中存储有可执行代码,所述处理器执行所述可执行代码时,实现上述的方法。
本发明的有效效果:
1.已有的基于脑电的疲劳检测方法中,多采用浅层机器学习或基于大量样本的深度学习的方法,此二种方法均具有局限性,跨被试精神状态的检测能力有限。本发明结合对脑电数据的统计量特征的分析,能够在样本数据相对较少的情况下快速学习分类器进行分类,通过10次以内的迭代能够取得较好的跨被试实验效果。
2.过去使用的领域适应迁移学习方法多采用单子空间映射以及特定子空间映射的方法,容易忽略数据自身的统计特征,这种统计特征对于迁移准确率的提升以及减少映射子空间偏移具有很重要的作用,特别是针对跨被试的精神状态迁移,迁移效果突出。
3.传统的分布对齐方式往往并没有采用动态计算特征空间和标记空间数据边缘分布和条件分布的权重。但是脑电数据是非线性高维数据,其自身具有复杂性、个体化差异非常大的特点。本发明采用了一种基于先生成目标域伪标签再计算源域和目标域数据的条件分布和边缘分布的权重,将该权重代入全局优化中,能够显著提升迁移学习分类的准确率。
附图说明
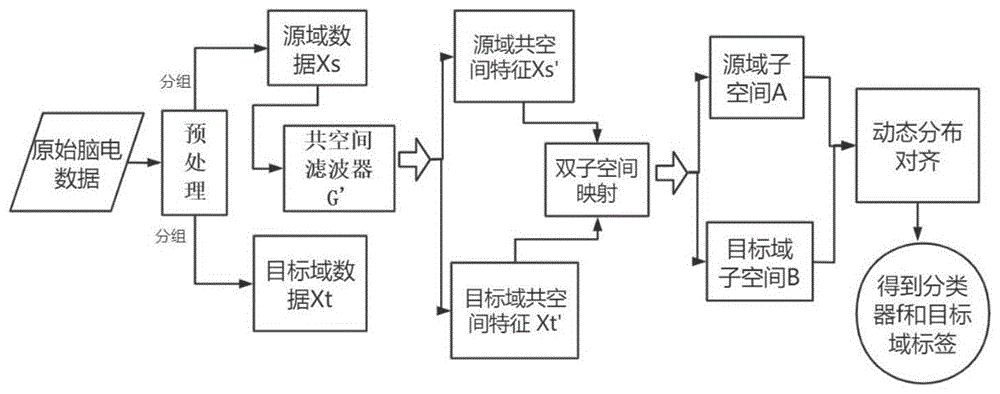
图1为本方法总体处理流程图。
图2为本发明选取的检测脑电62通道位置。
图3为共空间特征提取过程脑电数据处理变化流程图。
图4为双子空间映射与动态分布对齐示意图。
具体实施方式
下面结合具体实施例对本发明做进一步的实施分析。
本方法的目标是从源域ds的特征与标签的对应关系中学习一个分类器f来预测dt的标签。以由19名被试组成的驾驶员脑电数据“疲劳”“清醒”和“中性”三分类精神状态为例,实验所用数据为64通道脑电数据,在实际使用中除去两个参考电极,得到了62通道的脑电数据。图1为该方法的总体流程图,按照上述总体流程,在本发明设计的实验范式下采集多名疲劳驾驶实验被试的原始脑电数据,按照步骤(1)进行原始脑电数据预处理。图2为本发明采集的疲劳驾驶被试的62通道脑电位置。数据利用eeglab工具对原始脑电信号进行预处理,去除脑电原始信号中的干扰信号并进行带通滤波和独立成分分析。最终结果得到多名被试原始脑电数据特征空间的分类存储数据。
步骤(2)、脑电信号的特征提取
采用公共空间模式csp算法进行特征提取,将原始数据预处理得到的高维时域信号,通过设计出的csp滤波器,将其投影到低维空间。
2.1将源域数据归一化并分别计算两类(多类则任取两类)源域样本的协方差矩阵,并进行2.2-2.5步骤;
2.2根据步骤2.1得到的协方差矩阵累加并取平均,得到源域数据的混合空间协方差矩阵;
2.3计算步骤2.2得到的混合空间协方差矩阵的特征向量和特征值;
2.4对步骤2.3得到的特征值进行排序,选取最大值,求出白化特征值矩阵q;
2.5将步骤2.1不同类别源域样本的协方差矩阵与步骤2.4得到的白化特征值矩阵q进行变换,并做主分量分解得到共同特征向量n;共同特征向量n与白化特征值矩阵q进行公式(1)运算可得到共空间滤波器g:
g=ntq
(1)
其中t表示转置。
2.6重复2.1得到其他两两分类组合的共空间滤波器,并相加求平均的方式获取最终共空间滤波器g’,
经过特征提取之后得到的共空间特征为:
xs'=g’×xs
xt'=g’×xt(2)
图3所示为特征提取过程脑电数据处理变化的数据流程图,以三分类为例,原始脑电数据的清醒类数据大小为62*400*4012,表示采集的原始数据的组织结构为通道数*采样点*试验数,疲劳类脑电数据大小为62*400*6628,正常类脑电数据大小为62*400*3879,上述过程得到的csp滤波器大小为62*62,投影之后的数据经过降采样与逆置与叠加之后得到新目标域与源域数据量分别为源域数据特征空间为:4812*62,标记空间为4812*1,记录的是源域的类别信息,目标域数据的特征空间为:531*62,将类别信息另外存储。本发明的降采样的特征是采用的是按照清醒类:正常类:疲劳类为2.5:2.5:4的比例进行随机缩小的。
步骤(3)、源域数据目标域数据双子空间映射
所述源域数据和目标域数据双子空间模型表示如下:
其中α、θ、μ是平衡参数,为人为设定;
目标域特征方差采用公式(4)目标域数据的散度矩阵进行优化:
其中st表示目标域数据的散度矩阵,运算tr()表示矩阵的迹。
源域类间方差采用公式(5)源域数据的最大化类间散度矩阵进行优化:
其中sb是源域数据的类间散度矩阵;
源域类内方差采用公式(6)源域数据的最小化类内散度矩阵进行优化:
其中sw是源域数据的类内散度矩阵;
上述a、b分别表示源域的投影子空间、目标域的投影子空间;是利用步骤(2)处理得到的源域和目标域共空间特征学习两个耦合的投影变换,即将源域和目标域的共空间特征投影到相应的两个低维投影子空间a、b内,利用matlab编程工具的计算特征值和特征向量的函数eigs()能够求解出子空间映射a和子空间映射b,其矩阵表示为:
其中,i是单位矩阵。
步骤(4)、动态数据分布适应对齐
对进行步骤(3)的源域和目标域子空间数据进行动态的边缘分布对齐和条件分布对齐,估算动态自适应系数η,并采用计算mmd距离的方式来分别计算源域和目标域数据的边缘概率和条件概率的分布距离。
4.1生成目标域伪标签。由于疲劳驾驶脑电数据中选择的目标域标签是未知的,采用knn分类器的方法通过迭代生成伪标签的方式得到分类标签。
4.2用mmd距离来度量源域数据和目标域数据的边缘分布和条件分布在rkhs的距离。
源域与目标域数据的边缘分布距离表示为:
df(p(xs),p(xt))=||e(f(a))-e(f(b))||rk2(5)
其中,e(f(a))表示源域子空间在rkhs投影之后的样本,e(f(b))表示目标域子空间在rkhs投影之后的样本。rk表示rkhs。
源域与目标域条件分布表示为:
其中,e(f(a(c)))表示使用带有类别信息的源域子空间样本在rkhs上投影,e(f(b(c))表示使用带有伪标签信息的目标域样本在rkhs上投影。
4.3a-distance方法估计动态自适应系数η。采用a-distance的计算方法估计不同分布之间的距离,建立一个线性分类器区分两个数据领域的hinge损失。本发明的自适应系数η采用的是交叉验证的方法利用步骤4.1生成的伪标签不断迭代生成,其中a-distance定义为:
da(ds,dt)=2(1-2ε(g))(7)
其中,ε(g)表示利用简单的线性分类器区分源域和目标域数据分布的误差。可以计算边缘分布和条件分布的适配量分别表示为:
dm=da(ds,dt),do(c)=da(ds(c),dt(c))(8)
其中,dm表示边缘分布的a-distance,do(c)表示第c类源域数据条件分布的a-distance,dt(c)和ds(c)分别第c类的源域数据和目标域数据。
用这种方法可以通过不断迭代更新的方式可以粗略估计出η:
4.4根据4.2和4.3源域和目标域的动态分布对齐可以表示为:
其中,用
引用核矩阵具体可以化简为:
其中,k为核矩阵是源域和目标域数据使用径向基核函数得到的矩阵,并且k∈r(n+m)×(n+m);β是所求的系数矩阵,m为mmd矩阵,表示为:
其中,mm、
步骤(5)、基于srm原则构建全局学习分类器。
通过srm原则增加l2范数项和拉普拉斯正则化项,将子空间数据转化至rkhs内学习一个域不变的分类器f。
拉普拉斯正则化表示如下:
其中,
总模型表示为:
这里
通过核矩阵代入并整合公式可以得到如下表示:
对公式求偏导
图4为步骤(3)和步骤(4)主方法的简要示意图,用三种不同形状的图形表示三分类脑电数据,最左部分为源域和目标域原始脑电数据,其中源域由若干名被试组成,目标域由一名被试的脑电数据组成,其原始分布杂乱无序。经过双子空间映射其数据分布能够有效改善,通过动态分布对齐在rkhs空间下得到动态自适应系数η并学习到最终分类器f,完成分类任务。
- 还没有人留言评论。精彩留言会获得点赞!