一种自适应结构化的文档抽取方法
技术领域:
本发明涉及网页信息抽取的一种结构化抽取方法,特别是涉及一种自适应结构化的文档抽取方法。
背景技术:
:
网页信息抽取,通常指从网页文本中抽取出指定的一类信息并将其形成结构化数据的过程。来自网络的页面大多以html形式存在。浏览器使用html标签和脚本来诠释网页内容,但直接从网络上得到的html文件,html中涉及大量格式、业务逻辑代码,以及和核心主题无关的网页介绍、广告等内容。自动化信息抽取是通过程序自动化的输出无关内容,只保留有价值的内容,同时便于后续自动化处理。
常见的一些抽取方法存在不足。比如基于html的dom树结构,对不同的网站手动配置不同规则进行抽取的方法,很大程度上依赖于目的网页结构,可扩展性不强。在网站数量过大时需要大量人工干预,抽取难度、抽取代价过大。而基于自然语言处理的方法,比如将html文档以文本方式处理,通过对文档的词法和句法分析,制定抽取规则。然而现实中html文档通常包含大量的代码和网页噪音,导致该方法的实用性不高。另外,对于某一固定的信息源,网络上的信息和网页结构时刻处于动态变化的状态,常见的抽取方法大多难以适应站点的更新和变化。
技术实现要素:
:
本发明旨在解决上述问题。本发明的实施方案是:首先从互联网中采集待抽取的网页并存储,然后对采集到的原始网页原文进行通用无意义清洗,接下来根据xpath定位网页中的元素,自动对比抽取出网页中有价值的信息,最后将抽取到的内容按照结构化的格式存储起来。本发明的核心改进点主要是对于抽取规则的改进,不需要先验知识和人工标注数据,而是通过挖掘网页之间的语义相似性,自动生成适用的抽取模式。
一种自适应结构化的文档抽取方法,包括如下步骤:
步骤1:根据指定的网页地址从互联网采集公开原始网页,并获得原始网页的文档内容;
步骤2:将步骤1抽取的文档内容存储到数据库中;存储时同步存储文档内容对应的url;
步骤3:对文档内容进行清洗;
步骤4:对清洗后的文档内容进行自适应抽取;
步骤5:实现抽取结果的字段对齐,存储抽取结果,将抽取结果进行整合后存入数据库中,确保数据库中信息的一致性和完整性。
进一步的,步骤1具体实现如下:
1-1所述网页地址即url链接网址,是因特网上标准的资源地址,用于定位互联网上的资源,以获得指定网页的文档内容;
1-2通过url获得对应网页全部的文档内容。
进一步的,步骤3具体实现如下:
3-1对于文档内容中与主题内容无关的节点进行清除,所述的节点包括<meta>、<font>标签;
3-2清除注释、脚本语言<script>、样式定义<style>标签及标签对应内容;
3-3清除导航栏、分类表、广告区域或友情链接;对于导航栏、分类表、广告区域或友情链接,若在它们的内容块中链接文字所占的比例小于设定阈值,则说明该表是一个可保留的链接列表;由于内容块中链接文字多以链接列表的形式存在,因此可计算表中链接文字和普通文字总数的比值,若该比值小于设定阈值,则说明该表有较大可能是一个可保留的链接列表;
3-4清除空表。
进一步的,步骤4具体实现如下:
4-1基于xpath对文档内容进行抽取;
4-2整理抽取结果;经过抽取后,剩余的文档内容均可以被整理为<标签:文本>的结构化表示;其中,标签为文档内容中某元素对应的xpath,文本为该xpath对应元素的具体内容;
4-3将抽取后的文本和数据库中存储的同站点下历史采集进行比较,分别计算相同标签下对应文本的相似度;现有文本s1、文本s2;计算两个文本相似度具体步骤如下:
4-3-1文本分词,将文本拆分成粒度更细的单位处理;英文文本由空格作为自然分隔符,直接得到单词;中文以字为单位,进行拆分;
4-3-2文本向量化,使用词袋模型统计词频;假设文本s1、文本s2构成的词袋中共有n个词,得到文本s1、文本s2对应的向量表示分别为x=[x1,x2,...,xn],y=[y1,y2,...,yn],其中xi和yi表示分别表示词袋中第i个词在文本s1、文本s2中出现的次数;
4-3-3使用余弦相似度算法计算文本相似度;空间中的两个向量的夹角余弦可用来度量文本之间的相似度,夹角余弦值越大,两个向量的夹角越小,表示两个文本越相似;
计算公式为:
4-3-4根据步骤4-3-3计算出的文本相似度清洗标签,更新同一站点下的抽取规则;若文本相似度高于设定阈值,则说明该标签含信息量较小,对应标签可被清除;否则文本相似度较低,即不同页面之间内容差异较大,说明该标签对应文本质量更高,在抽取中更具价值;根据更新后的抽取标签,同步更新同一站点下的抽取规则。
本发明有益效果如下:
1)自适应抽取,抽取规则由目标网站自身特点决定,对不同站点兼容性较强,具有较高的可扩展性。
2)一个网站或者一个子域下的页面通常会有相似的数据内容和页面结构,因此通过同站点下相似数据的关联和对比,自动实现过滤冗余内容。
3)数据对比的依据为计算出的文本相似度,引入自然语言处理技术,实现了基于网页结构和基于文本特征抽取的有效结合。
附图说明
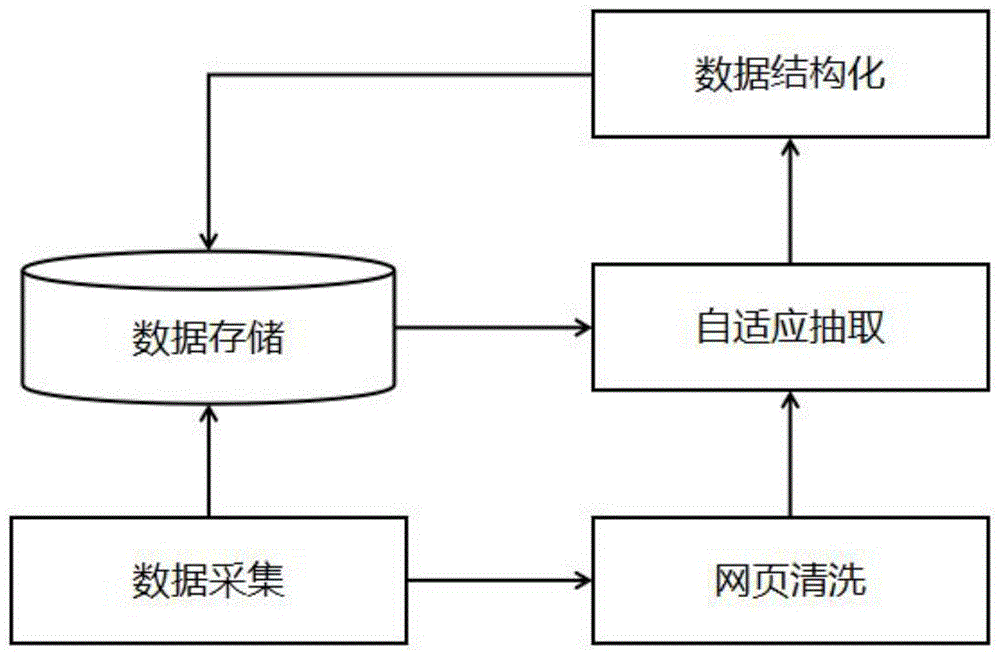
图1整体结构框架图;
图2自适应抽取规则更新流程图;
图3文本相似度计算流程图。
具体实施方式
下面结合实施例对本发明作进一步说明。
如图1、图2和图3所述,本发明首先从互联网中采集原始网页并存储,然后对采集到的原始网页中的原文进行通用无意义清洗,接下来根据xpath定位网页中的元素,自动对比抽取出网页中有价值的内容,最后将抽取到的内容按照结构化的格式存储起来。本发明的核心改进点主要是对于抽取规则的改进,不需要先验知识和人工标注数据,而是通过挖掘网页之间的语义相似性,自动生成适用的抽取模式。
步骤1:根据指定的网页地址从互联网采集公开原始网页,并获得原始网页的文档内容。
1-1所述网页地址即url链接网址,是因特网上标准的资源地址,用于定位互联网上的资源,以获得指定网页的文档内容。
1-2通过url获得对应网页全部的文档内容。
步骤2:将步骤1抽取的文档内容存储到数据库中。存储时同步存储文档内容对应的url。
步骤3:对文档内容进行清洗。
通过对文档内容的清洗过滤掉采集的广告、网页中的meta信息等无效信息。由于原始文档内容中噪音数据较多,它们或许使用户浏览页面更方便,但保留这些数据对信息抽取没有意义,具体清洗实施步骤如下:
3-1对于文档内容中与主题内容无关的节点进行清除,所述的节点包括<meta>、<font>等标签。
3-2清除注释、脚本语言<script>、样式定义<style>等标签及标签对应内容。
其中,对于步骤3-1、3-2中提及的html语法中固定标签的删除较为简单,可以直接利用预设的正则表达式集合,进行模式匹配,找到对应标签删除即可。
3-3清除导航栏、分类表、广告区域或友情链接。对于导航栏、分类表、广告区域或友情链接,若在它们的内容块中链接文字所占的比例小于设定阈值,则说明该表是一个可保留的链接列表。由于内容块中链接文字多以链接列表的形式存在,因此可计算表中链接文字和普通文字总数的比值,若该比值小于设定阈值,则说明该表有较大可能是一个可保留的链接列表。
3-4清除空表。在清除噪音数据后,可能会产生一些内容被清空的空表。这些空表信息价值较小,需要被清除。
步骤4:对清洗后的文档内容进行自适应抽取。
4-1基于xpath对文档内容进行抽取。
具体的,xpath为我们提供了一个对页面数据进行解析提取的方法。xpath是一门用于在html和xml文档中查找信息的语言,它使用路径表达式在文档中进行导航,即页面中的每一个元素都可以通过与之对应的xpath进行定位。xpath依赖页面dom结构,即通常情况下,同一站点内的不同页面框架结构基本相同,同样一组xpath往往可以覆盖一个子域甚至一个站点下的众多页面。
4-2整理抽取结果。经过抽取后,剩余的文档内容均可以被整理为<标签:文本>的结构化表示。其中,标签为文档内容中某元素对应的xpath,文本为该xpath对应元素的具体内容。
4-3将抽取后的文本和数据库中存储的同站点下历史采集进行比较,分别计算相同标签下对应文本的相似度。现有文本s1、文本s2。计算两个文本相似度具体步骤如下:
4-3-1文本分词,将文本拆分成粒度更细的单位处理。英文文本由空格作为自然分隔符,直接得到单词。中文以字为单位,进行拆分。
4-3-2文本向量化,使用词袋模型统计词频。词袋模型是用于描述文本的一个简单数学模型,也是常用的一种文本特征提取方式。对于一个文本,词袋模型忽略其次序和语法,将其当作若干个词汇组成的集合。文本的向量化可通过计算词袋中的每个词在当前文本中出现的次数得到。假设文本s1、文本s2构成的词袋中共有n个词,得到文本s1、文本s2对应的向量表示分别为x=[x1,x2,...,xn],y=[y1,y2,...,yn],其中xi和yi表示分别表示词袋中第i个词在文本s1、文本s2中出现的次数。
4-3-3使用余弦相似度算法计算文本相似度。空间中的两个向量的夹角余弦可用来度量文本之间的相似度,夹角余弦值越大,两个向量的夹角越小,表示两个文本越相似。
计算公式为:
4-3-4根据步骤4-3-3计算出的文本相似度清洗标签,更新同一站点下的抽取规则。若文本相似度高于设定阈值,则说明该标签含信息量较小,对应标签可被清除。否则文本相似度较低,即不同页面之间内容差异较大,说明该标签对应文本质量更高,在抽取中更具价值。根据更新后的抽取标签,同步更新同一站点下的抽取规则。
步骤5:实现抽取结果的字段对齐,存储抽取结果。一般而言,数据库中的数据大多以结构化形式保存。将抽取结果进行整合后存入数据库中,确保数据库中信息的一致性和完整性。
本发明方法实现的系统包含五个模块,分别为数据采集模块、数据存储模块、网页清洗模块、自适应抽取模块和数据结构化模块。数据采集模块主要是根据指定的网页地址从互联网采集公开网页全文。数据存储模块主要是存储抽取过程中涉及到的数据,包括历史数据、当前数据采集得到的网页原文和url以及抽取后得到的解析化的结构化数据。网页清洗模块,主要是对采集得到的网页进行清洗、清除冗余数据。自适应抽取模块主要实现网页的精细化抽取,是本发明的核心模块。数据结构化模块主要实现字段对齐和结构化存储。具体关系如图1所示。
- 还没有人留言评论。精彩留言会获得点赞!