一种基于不确定性估计的图像补全方法与流程
1.本发明涉及图像补全技术领域,涉及基于不确定性估计的图像补全方法。
背景技术:
2.图像补全任务(image inpainting),是指生成给定损坏图像中缺失区域的替代内容,且使得修复的图像在视觉上逼真和在语义上合理。图像补全任务可在其他应用中使用,如图像编辑,当图像中存在分散人注意力的场景元素时,如人或者物体(通常是不可避免的),允许用户移除图像中不需要的元素,同时在空白区域填充视觉和语义上合理的内容。
3.生成对抗网络启发自博弈论中二人零和博弈的思想,具有生成式网络和判别式网络两个网络,利用它们间相互竞争从而不断提升网络性能,最终达到平衡。基于生成对抗网络思想,衍生出许多变种网络,并且这些网络在图像合成、图像超分、图像风格转换和图像修复等方面都取得了显著的进步。图像补全,包括图像修复、图像去水印、图像去雨和图像去雾都得到了研究者们的关注。
4.人类的内容注意力机制和掩码先验(attention mechanism)是从直觉中得到,它是人类利用有限的注意力资源从大量信息中快速筛选出高价值信息的手段。深度学习中的内容注意力机制和掩码先验借鉴了人类的注意力思维方式,被广泛的应用在自然语言处理(nature language processing,nlp)、图像分类及语音识别等各种不同类型的深度学习任务中,并取得了显著的成果。
5.随着科技不断发展,人们在不同领域的需求也在相应提高,包括电影广告动画制作和网络游戏等,逼真的图像修复技术对用户的良好体验具有重要意义。
6.在此背景下,开发基于不确定性估计的图像补全方法,使得修复后的图像在视觉上逼真和在语义上合理,具有重要的意义。
技术实现要素:
7.本发明的目的是为了提高图像补全任务中图像的生成质量,包括丰富的纹理细节和结构上的连续性,而提供一种不确定性估计的图像补全方法。
8.为实现本发明的目的所采用的技术方案是:
9.一种不确定性估计的图像补全方法,包括步骤:
10.s1.将图像数据预处理,使用二值掩码合成损坏图像;
11.s2.使用损坏图像和对应的二值掩码作为网络模型的输入,训练学习损坏图像到目标图像之间的复杂非线性变换映射,得到进行图像补全的生成对抗网络模型:训练包括通过生成器对损坏图像处理得到补全的生成图像,与目标真实图像在判别器中进行对抗损失的计算;迭代多次稳定后完成模型训练;生成对抗网络模型的输出同时包含生成图像和不确定性图,不确定性图用于表示补全图像补全结果的不确定性;
12.s3.使用训练好的生成对抗网络模型,对测试数据进行图像补全处理。
13.其中,预处理之后的人脸图像和自然图像大小一致。
14.其中,所述步骤s2包括:
15.s21.初始化图像补全任务中的网络权重参数,其中,生成器的损失函数是l
total
,判别器的损失函数是l
d
;
16.s22.将损坏图像和二值掩码图输入到生成器网络g中进行图像补全任务,生成的补全图像和目标图像一起输入到判别器网络d中,依次迭代训练使得生成器的损失函数l
total
和判别器的损失函数l
d
均降低至趋于稳定;
17.s23.同时训练表情生成和去除任务,直至所有的损失函数不再降低,从而得到最终的生成对抗网络模型。
18.其中,所述生成对抗网络模型中所有编码器的卷积层为局部卷积,卷积层的输出值取决于未损坏的区域,数学描述如下:
[0019][0020]
其中,
⊙
表示像素级乘法,1表示所有元素均为1且形状和m相同的矩阵。w表示卷积层的参数,f表示前层卷积层的输出特征图,b表示卷积层的偏差,m表示对应的二值掩码图,可以视为是缩放因子,调整已知区域的权重。
[0021]
在执行了局部卷积之后也需要更新二值掩码图m,数学描述如下:
[0022][0023]
即若卷积层能够根据有效输入得到输出结果,那么将二值掩码中的该处位置标记为1。
[0024]
其中,所述生成对抗网络模型中包含内容注意力机制,缺失区域的生成是基于内容注意力机制的输出的,包括如下步骤:
[0025]
首先计算缺失部分和已知部分的特征相似度先提取已知区域的块,然后重新调整大小之后作为卷积核的参数;已知区域块{f
x,y
}和未知区域块{b
x
′
,y
′
}之间的余弦相似度可通过如下式子计算:
[0026][0027]
然后在x
′
y
′
维度上用缩放的softmax对相似度进行权衡,得到每个像素点的注意力值:
[0028][0029]
其中,λ是一个常数,最后把选取出来的未知区域块{b
x
′
,y
′
}作为反卷积的卷积核参数重建出缺失区域;
[0030]
为了获得注意力机制的一致性,按以下方式进行注意力传播:首先进行一个从左到右的注意力传播,然后再做一个核大小为k的自顶向下传播;
[0031][0032]
其中,对所述不确定性图,采用如下损失函数以减少不确定性:
[0033][0034]
其中,l
unc
表示不确定性估计,ω表示像素空间,μv表示图像的某点,l
rec
表示图像之间的l1范数,u表示不确定性图。
[0035]
其中,图像补全中的总损失函数为:
[0036]
l
total
=λ
unc
l
unc
+λ
per
l
per
+λ
style
l
style
+λ
tv
l
tv
+λ
adv
l
adv
[0037]
其中,l
unc
表示不确定性估计,l
per
表示感知损失函数,l
style
表示风格损失函数,l
tv
表示全变分损失函数,l
adv
表示对抗损失函数,λ
rec
、λ
per
、λ
style
、λ
tv
和λ
adv
表示权重因子。
[0038]
其中,重建损失函数表示为:
[0039][0040]
其中,||
·
||1表示l1范数,cat表示连结操作。
[0041]
其中,感知损失函数表示为:
[0042][0043]
其中φ是预训练的vgg
‑
16网络,φ
i
输出第i个池化层的特征图,使用vgg
‑
16中的pool
‑
1,pool
‑
2和pool
‑
3层,n为选取的层数。
[0044]
其中,风格损失函数表示为:
[0045][0046]
其中c
i
表示预训练模型vgg
‑
16的第i层输出的特征图的通道数。
[0047]
其中,全变分损失函数表示为:
[0048][0049]
其中ω表示图像中损坏区域,全变分损失函数是一个平滑惩罚顶,定义在缺失区域一个像素的膨胀域上,i,j表示图像中的某点。
[0050]
其中,对抗损失函数表示为:
[0051][0052]
其中,d表示判别器,y
′
是某个样本的随机缩放版本,该样本是从y
′
和y中采样得到的,λ被设置为10,e(*)表示取均值,y~p
y
表示样本y从分布p
y
中采样得到。
[0053]
本发明提出的基于不确定性估计的图像补全方法,通过局部卷积层,使得生成对抗网络可以利用二值掩码的先验信息,提升生成图像的质量。通过内容注意力机制可以学习根据已知区域重建出未知区域,提高生成高分辨率的图像。通过不确定性估计使得网络同时输出补全结果和不确定性图,最后根据不确定性图减少补全结果的不确定性。
[0054]
本发明在图像层面和特征层面引入了重建损失函数、风格损失函数、全变分损失函数和对抗损失函数作为约束,提高网络的鲁棒性和准确性。
附图说明
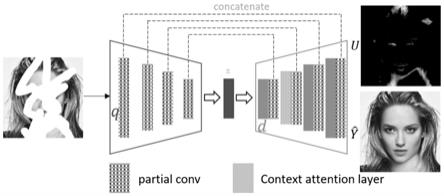
[0055]
图1是本发明中基于不确定性估计的图像补全方法的流程图,partial conv表示局部卷积层,concatenate表示连结操作;q和d表示编码器和解码器,z表示解码器的输入,为输入图像的特征。
[0056]
图2是本方明中的内容注意力流程图,图示中background和foreground分别表示缺失的特征图和缺失部分,input feature表示输入的特征图,extractpatches表示从缺失特征图中提取块(patch),reshape表示重新调整大小,convfor matching表示计算余弦相似度,softmax for comparison表示根据注意力值选取最相似的块。
[0057]
图3是本发明在公开数据集上图像补全的效果图。从左往右依次是损坏图像x、二值掩码图m、补全图像(生成图像)和真实图像y(目标图像记)。
具体实施方式
[0058]
以下结合附图和具体实施例对本发明作进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
[0059]
本发明通过基于不确定性估计的生成对抗网络学习一组高度非线性的变换,用来进行图像补全任务,使得补全的图像含有丰富的纹理细节和连续的结构。
[0060]
如图1所示,本发明基于不确定性估计的图像补全方法的流程如下:
[0061]
步骤s1,首先使用二值掩码算法离线生成二值掩码图。
[0062]
对输入的图像(包括自然和人脸图像)进行预处理操作:对于人脸图像,利用双眼位置校正并裁剪图像,对于自然图像,首先将图像放大然后随机裁剪图像。
[0063]
具体的,对于人脸图像,根据双眼的位置将图像规范化并裁剪到统一大小256*256;对于自然图像,首先将图像大小放大到350*350,然后对放大的图像进行随机裁剪到统一大小256*256。随机选取一张离线生成的二值掩码图,与为损坏图像相乘得到损坏图像。将损坏图像和对应的二值掩码图进行结合作为输入数据;
[0064]
步骤s2,利用训练输入数据,训练基于不确定性估计的生成对抗网络模型,以用来完成图像补全任务。具体的,是通过生成对抗网络模型的生成器中的编码器对输入的损坏图像以及二值掩码图m通过局部卷积层进行编码、由解码器根据内容注意力机制选取所获得的隐码解码到损坏图像x中,得到补全图像的。
[0065]
为了扩大输入数据样本量,提高网络的泛化能力,本发明采取了数据增广操作,包括随机翻转等。
[0066]
本发明中,对抗生成网络中利用编码器对输入数据提取特征,使用解码器把获得
的隐码解码到图像中,利用内容注意力机制输出最终的补全图像。
[0067]
所述编码器和解码器均有8个卷积层组成。其中,编码器中的卷积层滤波器大小分别为7,5,3,3,3,3,3,3;解码器中的卷积层滤波器大小均为3。
[0068]
在本发明实例中,使用传统方法对特征图进行上采样。卷积层的层数和每层卷积层中滤波器的个数及大小可根据实际情况进行选择设置。
[0069]
在判别器中,采用卷积神经网络结构将真实图像对和生成的补全图像对作为输入,输出采用分块对抗损失函数来判断真假。
[0070]
其中,所述步骤s2包括:
[0071]
s21.初始化图像补全任务中的网络权重参数,其中,生成器的损失函数是l
total
,判别器的损失函数是l
d
;
[0072]
s22.将损坏图像和二值掩码图输入到生成器网络g中进行图像补全任务,生成的补全图像和目标图像一起输入到判别器网络d中,依次迭代训练使得生成器的损失函数l
total
和判别器的损失函数l
d
均降低至趋于稳定;
[0073]
s23.同时训练表情生成和去除任务,直至所有的损失函数不再降低,从而得到最终的生成对抗网络模型。
[0074]
其中,所述生成对抗网络模型中所有编码器的卷积层为局部卷积,卷积层的输出值取决于未损坏的区域,数学描述如下:
[0075][0076]
其中,
⊙
表示像素级乘法,1表示所有元素均为1且形状和m相同的矩阵。w表示卷积层的参数,f表示前层卷积层的输出特征图,b表示卷积层的偏差,m表示对应的二值掩码图,可以看做是缩放因子,调整已知区域的权重。
[0077]
在执行了局部卷积之后也需要更新二值掩码图m,数学描述如下:
[0078][0079]
即若卷积层能够根据有效输入得到输出结果,那么将二值掩码中的该处位置标记为1。
[0080]
其中,所述生成对抗网络模型中包含内容注意力机制,缺失区域的生成是基于内容注意力机制的输出的,包括如下步骤:
[0081]
首先计算缺失部分和已知部分的特征相似度先提取已知区域的块,然后重新调整大小之后作为卷积核的参数;已知区域块{f
x,y
}和未知区域块{b
x
′
,y
′
}之间的余弦相似度可通过如下式子计算:
[0082][0083]
然后在x
′
y
′
维度上用缩放的softmax对相似度进行权衡,得到每个像素点的注意
力值:
[0084][0085]
其中,λ是一个常数,最后把选取出来的未知区域块{b
x
′
,y
′
}作为反卷积的卷积核参数重建出缺失区域;
[0086]
为了获得注意力机制的一致性,按以下方式进行注意力传播:
[0087][0088]
其中,对所述不确定性图,采用如下损失函数以减少不确定性:
[0089][0090]
其中,l
unc
表示不确定性估计,ω表示像素空间,μv表示图像的某点,l
rec
表示图像之间的l1范数,u表示不确定性图。
[0091]
其中,图像补全任务中的总目标损失函数(生成器的损失函数)为:
[0092]
l
total
=λ
unc
l
unc
+λ
per
l
per
+λ
style
l
style
+λ
tv
l
tv
+λ
aav
l
adv
[0093]
其中,l
unc
表示不确定性估计,l
per
表示感知损失函数,l
style
表示风格损失函数,l
tv
表示全变分损失函数,l
adv
表示对抗损失函数,λ
rec
、λ
per
、λ
style
、λ
tv
和λ
adv
表示权重因子。
[0094]
上述的基于不确定性估计的生成对抗网络,主要是完成图像补全任务,所述生成对抗网络的最终目标为l
total
,使其该损失函数降至最低并且保持稳定。
[0095]
其中,重建损失函数表示为:
[0096][0097]
其中,||
·
||1表示l1范数。cat表示连结操作。
[0098]
其中,感知损失函数表示为:
[0099][0100]
其中φ是预训练的vgg
‑
16网络。φ
i
输出第i个池化层的特征图。本发明中使用vgg
‑
16中的pool
‑
1,pool
‑
2和pool
‑
3层。
[0101]
其中,风格损失函数表示为:
[0102][0103]
其中c
i
表示预训练模型vgg
‑
16的第i层输出的特征图的通道数。
[0104]
其中,全变分损失函数表示为:
[0105][0106]
其中ω表示图像中损坏区域。全变分损失函数是一个平滑惩罚顶,定义在缺失区域一个像素的膨胀域上。
[0107]
其中,对抗损失函数表示为:
[0108][0109]
其中,d表示判别器,y
′
是某个样本的随机缩放版本,该样本是从y
′
和y中采样得到的,λ被设置为10。
[0110]
本发明中利用所述基于不确定性估计的生成对抗网络的高度非线性拟合能力,针对图像补全这一任务,提出局部卷积层利用二值掩码图中的先验信息。其次,本发明提出内容注意力模块,使得算法可以根据图像的已知区域重建出未知区域。该编码器可以逐渐增加生成图像中的纹理细节。特别的,网络通过外加损失函数的限制可以很好地生成高质量的图像。这样通过如图1所示的网络,可以训练得到一个图像补全的模型。在测试阶段,同样使用二值掩码和损坏图像作为模型的输入,得到生成的图像补全结果,如图3所示。
[0111]
基于上述的损失函数,基于不确定性估计的生成对抗网络进行如下训练:
[0112]
初始化网络的权重参数,λ
unc
、λ
per
、λ
style
、λ
tv
和λ
adv
分别为10,0.1,240,0.1,0.001,批处理大小为32,学习率为10
‑4。
[0113]
利用损坏图像和二值掩码图输入到生成器g中进行图像补全任务。生成的补全图像和真实的目标图像输入到判别器d中,依次迭代使得网络总损失函数l
total
降低至趋于稳定。
[0114]
用训练好的基于不确定性估计的生成对抗网络模型,对测试数据补全处理。
[0115]
为了详细说明本发明的具体实施方式及验证本发明的有效性,将本发明提出的方法应用于四个公开的数据库(一个人脸数据库和三个自然数据库)——celeba
‑
hq、imagenet、places2和pairs street view。celeba
‑
hq中包含30000张高质量的人脸图像。places2包含365个场景,总图像数量超过8000000张。pairs street view包含15000张巴黎街景图。
[0116]
imagenet是一个大型数据集,超过14亿张图像。对于places2、pairs street view和imagenet,本发明中使用原始的验证和测试集。对于celeba
‑
hq,本发明中随机选取28000张图像用于训练,剩余的图像用于测试。利用二值掩码算法离线生成60000张二值掩码图。本发明中随机选取55000张二值掩码图用于训练,剩余的5000张二值掩码图用于测试(二值掩码图用于生成损坏图像)。使用本发明中设计的基于不确定性估计的生成对抗网络和目标函数,以损坏图像和对应的二值掩码图作为输入,利用生成器和判别器之间的对抗及梯度反传训练该深度神经网络。训练过程中不断调整不同任务的权重,直至最后网络收敛,得到用来人脸表情编辑的模型。
[0117]
为了测试该模型的有效性,使用测试集数据进行图像补全的操作,可视化结果如图3所示。有效证明了本发明所提出方法能够生成高质量的图像。
[0118]
本发明针对图像补全,提出了一个更具有广泛应用意义的方法。通过局部卷积层,
可以利用二值掩码的先验信息,更加准确地补全损坏图像。内容注意力模块可以使得模型根据图像的已知区域重建出图像中的未知区域,以此生成丰富的细节信息。本发明提出的不确定性估计可以使得网络同时输出补全结果和不确定性图,最后根据不确定性图减少补全结果的不确定性。本发明提出的生成对抗网络模型,使用了多目标的优化方式,使得模型收敛更快,效果更好,并且泛化性能更强。
[0119]
以上所述仅是本发明的优选实施方式,应当指出的是,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1