一种优化低比特模型训练的方法与流程
1.本发明涉及图像处理技术领域,特别涉及一种优化低比特模型训练的方法。
背景技术:
2.近年来,随着科技的飞速发展,大数据时代已经到来。深度学习以深度神经网络(dnn)作为模型,在许多人工智能的关键领域取得了十分显著的成果,如图像识别、增强学习、语义分析等。卷积神经网络(cnn)作为一种典型的dnn结构,能有效提取出图像的隐层特征,并对图像进行准确分类,在近几年的图像识别和检测领域得到了广泛的应用。
3.现有技术中在训练全精度模型多采用的时relu函数,由于全精度数表示的实数范围很广,可以满足训练过程中需要的数值范围,可是在训练低比特时,由于位宽的限制,所以其表示范围是有有限的,导致训练过程中模型无法有效的收敛,最终模型的精度并不理想。
4.现有技术中的常用术语包括:
5.卷积神经网络(convolutional neural networks,cnn):是一类包含卷积计算且具有深度结构的前馈神经网络。
6.量化:量化指将信号的连续取值(或者大量可能的离散取值)近似为有限多个(或较少的)离散值的过程。
7.低比特:将数据量化为位宽为8bit,4bit或者2bit的数据。
技术实现要素:
8.为了解决上述问题,本方法旨在克服上述现有技术中存在的缺陷,解决现有2bit模型在训练过程中精度损失严重和难以收敛的问题。
9.基于全精度模型微调低比特模型:先用数据集训练一版全精度模型达到目标精度,然后基于全精度模型微调训练一版低比特模型。
10.具体地,本发明提供一种优化低比特模型训练的方法,所述方法包括以下步骤:
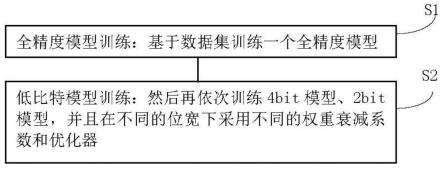
11.s1,全精度模型训练:基于数据集训练一个全精度模型;
12.s2,低比特模型训练:然后再依次训练4bit模型、2bit模型,并且在不同的位宽下采用不同的权重衰减系数和优化器。
13.所述步骤s1进一步包括:
14.s1.1,训练数据:
15.训练模型的数据集是imagenet1000,该数据集是imagenet数据集的一个子集,有大约1.2million的训练集,5万验证集,15万测试集,1000个类别;
16.s1.2,建立模型:
17.训练采用的基础神经网络模型是mobilenetv1,该网络是一种基于深度可分离卷积的模型;
18.s1.3,训练网络:
19.对于网络的训练基本步骤是:将权重衰减系数设置为0.0005,先采用adam优化器训练60个epoch,然后再用sgd优化器直至训练结束;
20.s1.4,测试网络效果:利用测试集测试网络结果。
21.所述步骤s2进一步包括:
22.s2.1,数据量化:对于待量化的数据进行量化,得到低比特的数据;
23.s2.2,进行低比特模型训练:
24.s2.2.1,训练4bit模型;
25.s2.2.2,训练2bit模型;
26.s2.2.3,测试网络效果:
27.s2.2.4,输出网络。
28.所述步骤s2.1,按照公式1进行量化:
[0029][0030]
变量说明:wf为全精度数据是一个数组,wq为模拟量化后的数据,maxw全精度数据wf中最大值,minw全精度数据wf中最小值,b为量化后的位宽。
[0031]
所述步骤s2.2.1,所述训练4bit模型:训练时将权重和激活量化到4bit,并将权重衰减系数置位0即不采用权重衰减;并且采用adam优化器,训练模型直至收敛。
[0032]
所述步骤s2.2.2,所述训练2bit模型:经过步骤s2.2.1训练后得到一个权重和激活都量化成4bit的模型,然后再基于该模型训练权重和激活都量化成2bit的模型,在训练2bit模型时需将权重衰减系数置位0.00005,并且在前60epoch训练时采用adam优化器,之后调低学习率为0.0001,采用sgd优化器,训练模型直至收敛。
[0033]
由此,本技术的优势在于:本方法简单,通过先基于数据集训练一个全精度模型,然后再训练4bit模型,2bit模型,并且在不同的位宽下采用不同的权重衰减系数和优化器的方法,实现了卷积神经网络在量化时提高模型精度的目的。
附图说明
[0034]
此处所说明的附图用来提供对本发明的进一步理解,构成本技术的一部分,并不构成对本发明的限定。
[0035]
图1是本发明方法的流程示意图。
[0036]
图2是本发明中低比特模型训练流程示意图。
具体实施方式
[0037]
为了能够更清楚地理解本发明的技术内容及优点,现结合附图对本发明进行进一步的详细说明。
[0038]
如图1所示,本发明涉及一种优化低比特模型训练的方法,所述方法包括以下步骤:
[0039]
s1,全精度模型训练:基于数据集训练一个全精度模型;
[0040]
s2,低比特模型训练:然后再依次训练4bit模型、2bit模型,并且在不同的位宽下采用不同的权重衰减系数和优化器。
[0041]
具体地,所述方法包括以下内容:
[0042]
1全精度模型训练:
[0043]
1)训练数据:
[0044]
训练模型的数据集是imagenet1000,该数据集是imagenet数据集的一个子集,有大约1.2million的训练集,5万验证集,15万测试集,1000个类别。
[0045]
2)模型:
[0046]
本次训练采用的基础神经网络模型是mobilenetv1,该网络是一种基于深度可分离卷积的模型。
[0047]
3)训练网络:
[0048]
对于网络的训练基本步骤是:将权重衰减系数设置为0.0005,先采用adam优化器训练60个epoch,然后再用sgd优化器直至训练结束。
[0049]
4)测试网络效果:
[0050]
利用测试集测试网络结果。
[0051]
2低比特模型训练:
[0052]
数据量化:对于待量化的数据按照以下所示的公式进行量化,得到低比特的数据。
[0053][0054]
变量说明:wf为全精度数据是一个数组,wq为模拟量化后的数据,maxw全精度数据wf中最大值,minw全精度数据wf中最小值,b为量化后的位宽。
[0055]
低比特模型训练流程如图2所示,主要分成2步,分别为:
[0056]
1)训练4bit的模型:
[0057]
训练时将权重和激活量化到4bit,并将权重衰减系数置位0即不采用权重衰减。并且优化器采用adam,训练模型直至收敛。
[0058]
2)训练2bit的模型:
[0059]
经过第一步训练后得到一个权重和激活都量化成4bit的模型,然后再基于该模型训练权重和激活都量化成2bit的模型,在训练2bit模型是需将权重衰减系数置位0.00005,并且在前60epoch训练时采用adam优化器,之后调低学习率为0.0001,采用sgd优化器,训练模型直至收敛。
[0060]
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明实施例可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1