一种基于ES的检验检测机构快速检索排序方法与流程
本发明设计一种快速检索排序方法,特别是一种基于es的检验检测机构快速检索排序方法。
背景技术:
国内具有资质的检验检测机构达数万家,每家机构又各自拥有数千至数万条不同检测资质的对应检测能力项目,其数据结构与分类规范皆不相同,将普通用户输入的关键词和专业的检验检测数据进行关联,从数据量大、数据结构不同的专业性原始数据中筛选出符合检测领域需求的有效数据的难度极高,现有技术不足以支撑完成上述工作。
因此,需要一种基于es(elasticsearch)的检验检测机构快速检索排序方法。
技术实现要素:
本发明提供了一种基于es的检验检测机构快速检索排序方法。
本发明采用如下技术方案:
一种基于es的检验检测机构快速检索排序方法,
1)建立具有统一数据结构的归档库,归档库从原始数据库获取检验检测机构的识别信息、检验检测机构的的检验检测证书数据、检验检测机构的检测对象类别及检验检测机构的检测能力项目,原始数据库从官方数据来源获取,检测对象类别与多个自定义检测对象类别关联,自定义检测对象类别为包含待检产品的类别集合,关联方式为根据tf-idf算法将检测对象类别与多个自定义检测对象类别关联;检验检测机构的检测能力项目至少包含项目名称、项目类别、检测标准;
2)将elasticsearch分布式部署,在elasticsearch中至少建立一个索引,索引为第一对象集合,第一对象集合的数据从归档库获取,其一个对象为一个检验检测机构的识别信息、检验检测证书数据、检测对象类别及检测能力项目的组合,检验检测机构的识别信息、检验检测证书数据、检测对象类别及检测能力项目均包含待匹配字段;
3)将归档库的数据增量同步进elasticsearch;
4)根据用户输入的关键词,采用bm25算法,分别计算所述关键词与索引中待查对象的每个待匹配字段的相似度评分,待查对象包括检验检测机构的识别信息、检验检测机构的检验检测证书数据、检验检测机构的检测对象类别及检验检测机构的检测能力项目,将各待匹配字段的相似度评分加权求和得到待查对象总得分,各检测检验机构的待查对象总得分即为检测检验机构的总得分,对检验检测机构总得分进行倒序排序。
进一步地,elasticsearch中还建立有一个副索引,副索引为第二对象集合,其一个对象为一检测能力项目。
进一步地,调整bm25算法的参数,使得待匹配字段的长度对相似度评分的影响为0,增加关键词在待匹配字段中的词频对相似度评分的影响权重。
与现有技术相比,本发明基于es的检验检测机构快速检索排序方法和系统的有益效果在于:
本发明提供的一种基于es的检验检测机构快速检索排序方法,建立贴近用户习惯的自定义分类,其中,利用elasticsearch将数据索引化分布式部署,同时根据具体的应用场景对bm25算法优化。本发明能够做到将普通用户输入习惯(自定义检测对象)和专业的检验检测能力项目(归档库中的检测对象类别)智能关联,在千万级数据中精准匹配,毫秒级返回可靠结果集,能按照产品名称、检测方法、标准依据、检测项目等属性精准定位和匹配符合用户需求的检验机构,实现了智能检验检测机构快速检索。
附图说明
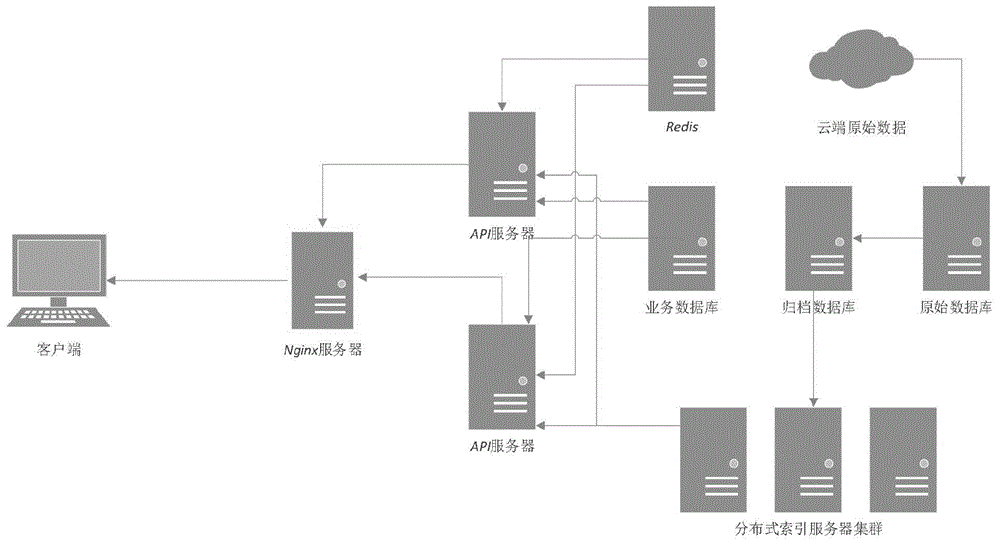
图1是本发明基于es的检验检测机构快速检索排序方法的系统架构示意图;
图2是本发明基于es的检验检测机构快速检索排序方法的业务流程图
具体实施方式
本申请涉及一种基于es的检验检测机构快速检索排序方法,下面结合附图详细说明具体实施步骤如下:
如图1所示,本实施例由10台服务器组成,其中1台nginx服务器,两台api服务器,1台业务数据库服务器,1台redis服务器,3台分布式索引服务器,1台归档数据库服务器,1台原始数据库服务器。
其中,nginx服务器负责实现反向代理及负载均衡,api服务器负责具体的业务接口实现,并和redis服务器、分布式索引服务器、业务数据库服务进行交互,业务数据库服务器负责存放具体的业务数据,redis服务器负责为业务数据库服务器实现缓存,分布式索引服务器负责存放基于归档数据库数据建立的elasticsearch索引,归档数据库服务器负责存放归档库数据及数据归档服务,数据归档服务即处理原始数据形成归档库数据后保存到归档库的服务,原始数据库服务器则负责存放原始数据和原始数据获取服务。原始数据获取服务即从云端(各官方数据源)获取原始数据保存到原始数据库的服务程序。
本实施例中将原始库、归档库、业务库、索引、数据库缓存分别存放,从物理上隔绝了不同业务之间的资源竞争,并通过负载均衡大幅提高了并发处理能力和系统的稳定性。
如图2所示,为本发明公开的一种基于es的检验检测机构快速检索排序方法的业务流程图,其具体流程步骤如下:
步骤一:从浙江省市场监督管理局、中国合格评定国家认可委员会、外省市场监督管理局官方公布数据等官方数据来源获取检验检测机构的识别信息、检验检测机构的的检验检测证书数据、检验检测机构的检测对象类别、检验检测机构的检测能力项目及授权签字人数据等,并以一个数据来源一套数据结构,每套数据结构中每种类型数据单独一张表的原则,分表存入关系型原始数据库。
步骤二:结合用户输入习惯和普遍性社会常识,建立贴近生活的自定义检测对象类别,并将自定义检测对象类别和检测对象类别(原始数据库中不同类型的检测能力项目自带的分类,数据量大)进行关联,以此在后续建立索引时大幅缩短索引路径长度;
建立的自定义分类及关联的过程如下:
1.根据用户习惯,建立自定义检测对象类别,每一条分类至少包括分类名称、分类代码、分类特征词、分类关键词4个字段,在本实施例中,分类名称等于分类特征词(例如:有自定义关键词“包装饮用水”,分类代码“000100”,其特征词为“饮用水”,分类关键词“农夫山泉,百岁山,恒大冰泉,冰露,矿泉水,纯净水”)。
对自定义检测对象类别进行分词(如果有分类特征词,则以分类特征词为准)(使用ik分词器组件),遍历原始分类,使用相对简单快速的tf-idf算法,将自定义分类与海量原始分类数据进行比对后,取其分词相似度之和大于某个值(因原始分类复杂度较高,此处取0.3)的部分进行初步关联。
单纯使用相似度算法并不能100%保证关联的准确性,需求通过测试校验原始分类的特征词修订是否合理,并对分类关联结果进行抽查校对审核,以提高分类关联的准确性。
步骤三:在关系型数据库建立归档库,制定统一数据结构;
其主体数据结构当根据具体业务范围确立,归档库的检验检测机构的检测能力项目部分主要由两张表组成,一张为检验检测机构的识别信息数据表,一张为检验检测机构的检测能力项目表,表字段由各来源原始数据的数据结构综合归纳得出,此外,步骤二中建立的自定义检测对象类别也单独建立一张表存于归档库。
因此,该归档库从原始数据库获取检验检测机构的识别信息、检验检测机构的的检验检测证书数据、检验检测机构的检测对象类别及检验检测机构的检测能力项目,原始数据库从官方数据来源获取,检测对象类别与多个自定义检测对象类别关联,自定义检测对象类别为包含待检产品的类别集合,关联方式为根据tf-idf算法将检测对象类别与多个自定义检测对象类别关联。
步骤四:本实施例中,为了去除归档库中无效数据,对原始数据库进行清洗,去除格式不正确(原始数据格式千奇百怪,主要是对时间格式进行矫正,去除多余的空格和空行,去除乱码字符串和异常字符等)的部分。
建立归档库的目的是为了保存清洗关联完毕的数据,使索引数据有迹可循,有根可依,极大地提高了数据的准确性和可靠性。
步骤五:将es分布式部署后,在es中建立两个独立索引,分别为主索引和副索引,其中主索引为嵌套格式的检验检测机构的识别信息和检验检测机构的检测能力项目的对象集合,而副索引仅为检验检测机构的检测能力项目的对象集合,索引数据均来自于数据处理完成后的归档库;
在本实施例中,关于es的详细配置步骤如下:
1.配置config/elasticsearch.yml
配置节集群名称和主节点名、配置集群成员ip端口集合,最小主节点数,集群主节点名称,启用http跨域,关闭xpack机器学习,在本实施例中采用的阿里云服务器不支持机器学习,不关就会报错;
2.配置config/jvm.options
配置分配给jvm的初始内存数和最大内存数,两个值必须要配成一样大,不然会报错,内存看硬件条件尽可能大,对性能影响极大,具体遵从服务器硬件配置,20g以上为佳;
配置堆栈大小,默认是64k,在本实施例中配置为4m
3.通过restful接口对索引进行配置
配置评分算法模块为bm25,其中b为0,k1为1.5、分词类型为ik_max_word、并修改嵌套文档个数为100000。
步骤六:将归档库的数据增量同步进es;
首次同步时,将归档库中所有检验检测机构的识别信息、检验检测机构的的检验检测证书数据、检验检测机构的检测对象类别及检验检测机构的检测能力项目按照步骤五中建立的索引数据结构全部同步到es中,后续同步时,以归档库更新后的检验检测机构的识别信息、检验检测机构的检验检测证书数据、检验检测机构的检测对象类别及检验检测机构的检测能力项目为基准进行目标索引的整条重建。
步骤七:根据检验检测领域的特殊性,在bm25算法的基础上进行优化,使系统能够更快、更准确的筛选出符合检测领域需求的检测机构数据及其相关检测能力项目,并进行根据用户匹配度进行排序。根据用户输入的关键词,采用bm25算法,分别计算所述关键词与索引中待查对象的每个待匹配字段的相似度评分,待查对象包括检验检测机构的识别信息、检验检测机构的检验检测证书数据、检验检测机构的检测对象类别及检验检测机构的检测能力项目,将各待匹配字段的相似度评分加权求和得到待查对象总得分,各检测检验机构的待查对象总得分即为检测检验机构的总得分,对检验检测机构总得分进行倒序排序。
具体地,由于待匹配字段的长度对获取符合检测领域需求的检验检测机构的识别信息、检验检测证书数据、检测对象类别及检测能力项目项并无影响,故待匹配字段的长度常数取0,以取消待匹配字段的长度对评分的影响,关键词在待匹配字段中的词频常数取1.5,增加关键词在待匹配字段中的词频对相似度评分的影响权重。
步骤八:本实施例中,为了方便用户使用,对检验检测机构查询排序、检测能力项目匹配、检测用户输入内容智能匹配关键词等业务场景分别编写api接口,供前端调用;同时,web前端组装查询条件,通过api接口进行查询,并呈现返回内容。
在此步骤中,对api接口进行分布式部署,通过nginx实现反向代理及负载均衡,进一步减少服务端压力,提高查询效率。
- 还没有人留言评论。精彩留言会获得点赞!