基于卷积神经网络的胃癌病灶检测方法及装置
本发明涉及图像处理技术领域,尤其涉及一种基于卷积神经网络的胃癌病灶检测方法及装置。
背景技术:
人工智能(artificialintelligence,ai)是计算机科学的一个分支,致力于设计并执行近似人类智能的计算机算法,使计算机算法达到与人类智能执行任务时相似的工作效果。机器学习(machinelearning,ml)是人工智能领域的分支,指所有通过非显性编程就能使机器从数据集中学习、预测阳性事件并进行决策。机器学习分为有监督学习、无监督学习、半监督学习及强化学习。深度学习(deeplearning,dl)属于机器学习范畴,其中应用最广泛的深度学习模型便是卷积神经网络(convolutionalneuralnetwork,cnn),该算法是一类包括卷积计算并且具有深度网络结构的深度学习算法,在医学图像处理领域能够用于图像分类、目标检测及语义分割等多个方面。cnn具有优秀的图像特征提取能力,该类模型常作为目标检测及语义分割的特征提取骨架(backbone)对模型特征进行提取。常用的cnn模型包括vgg、inception、resnet、mobilenet、xception等。
目标检测(objectdetection)一直以来都是计算机视觉领域的研究热点。目标检测的目的是确定某张给定图像中是否存在给定类别的目标。例如,在医学影像领域,可以明确图像中是否有肿瘤病灶,如果该图像中存在目标病灶,目标检测算法就返回每个目标实例的空间位置和覆盖范围,返回一个目标检测预测框,并在框的上方标注置信度(confidence)。随着cnn模型的出现,结合以cnn算法作为主干特征提取网络骨架的目标检测算法应运而生。
语义分割(semanticsegmentation)是通过对给定图像内的每个像素点进行识别后作出分类,能够在像素层面精确的分割图像中目标区域与背景区域。语义分割与单纯提取病灶的目标检测不同之处在于,能够对图像中的病灶区域进行精准勾勒,更符合肿瘤精准诊断与精准治疗的实际需求。常用的语义分割算法包括segnet、unet、pspnet和deeplab等。语义分割算法中的unet算法及其衍生算法因其结构简单并能够充分利用编码(encoder)过程中提取深层及浅层图像特征,在医学图像处理分析领域具有十分广泛的应用前景。
胃肿瘤外科治疗后的手术切除标本图像是医生明确病灶数目、病灶侵犯深度、病灶扩散程度的第一手资料,需要切取准确的病灶部位制备病理切片做出精准诊断,从而指导后续的治疗方案选择。迄今为止一直依赖于外科医师和病理科医师的肉眼判断,难免存在微小病灶或者转移病灶被遗漏的现象。
随着诊疗技术的不断提高和胃镜检查等的普及,早期胃癌的检出率正在逐年提高,从而得到及时的手术切除治疗。但早期胃癌手术切除标本中病灶的精准定位是目前临床病理切取标本的难题之一,有时候只能凭借医师的经验识别,或者依靠手术医师在可疑病灶处使用缝合线作为标注提示,而对于胃内的多发性病灶或者主病灶出现胃内的多发性转移灶、以及胃周围转移淋巴结或者癌结节灶识别则是世界范围内公认的难点。
技术实现要素:
本发明的目的在于提供一种基于卷积神经网络的胃癌病灶检测方法及装置,以解决早期胃癌手术切除标本临床病理精准切取标本的难题,以及微小病灶或者转移病灶被遗漏的现象。
为此,本发明公开了一种基于卷积神经网络的胃癌病灶检测方法,包括下列步骤:
s1、待测的胃癌样本大体图像的预处理;
s2、基于目标检测算法模型的病灶目标提取及置信度分析,输出病灶检测结果;或
s3、基于语义分割算法模型的病灶目标精细分割与勾勒,输出病灶检测结果。
进一步,所述步骤s1具体为:
s101、胃癌样本大体图像的采集,包括收集胃癌患者手术切除后标本的整体图像,同时采集全面的临床相关信息,如性别、年龄、肿瘤大体类型等等。
s102、图像裁剪。为减小图像训练过程中计算机处理的负荷,充分利用图像的每个像素,对图像裁去周围过多的无关区域信息,比如出血区、纱布区、器械区或者过多的网膜组织等等,仅保留胃部主体图像部分。同时注意裁去能提示患者个人信息部分,做好患者隐私保护。该图像裁剪预处理过程必不可少,主要是防止模型训练过程中过多无关信息会影响模型的效能。
进一步,所述目标检测模型是以cnn模型作为主干特征提取网络,构建目标检测模型。主干特征网络可使用多种cnn模型,包括vgg16、mobilenet、resnet50、inceptionv3、inception-resnet-v2和xception等。同时可结合使用多种目标检测模型,包括ssd、fasterr-cnn、yolo、centernet和efficientdet等。具体过程包括:
(1)输入图像大小的调整。目标检测模型根据网络结构调整输入图像的大小,所需输入图像的结构为长×宽×通道数(height×width×channel)。
(2)主干特征提取网络的构建。使用主干cnn模型提取有效特征层。有效特征层的表示方法为有效特征层长×宽×通道数(height×width×channel)。主干特征模型可将采用大多数cnn模型,包括vgg16、mobilenet、resnet50、inceptionv3、inception-resnet-v2和xception等。
(3)单脉冲多盒探测器(singleshotmultiboxdetector,ssd)目标检测模型的构建。根据主干特征模型提取的特征层结构对图像标注先验框(priorframe),不同大小特征层标注不同数量的先验框;对于一个大小为height×width×channel的特征层,预先设定对于每个像素值设置先验框数量n,可获得height×width×n个先验框,将所有特征层所提取的先验框数量相加,可获得所有总先验框数量。而后对提取的每一个有效特征层使用两个卷积进行处理。第一个卷积是num_priors×4的卷积,使用4个参数对该特征层上的每个像素每个先验框位置进行调整;第二个卷积是num_priors×num_class的卷积,可获得该特征层上的每个像素每个先验框识别病灶的种类及置信度。
(4)最终获得所有调整后的先验框情况及每个调整后先验框里的病灶预测的置信度。
进一步,所述胃癌样本图片中病灶目标提取及置信度分析,包括下列步骤:
(1)图像大小调整(resize)。根据不同目标检测模型的结构,将图像输入尺寸调整为模型训练所需的长×宽(height×width)。letterboximage函数对图像尺寸归一处理,该过程不对图像进行拉伸,而是利用灰色像素值填充空白图像区域,获得不失真图像,使图像达到所需的height×width。
(2)图像归一化。将大小调整后的图像像素值归一化为[0,1]。
(3)训练权重载入。为实现对输入图像目标的预测,首先载入目标检测模型结构及模型训练权重,而后使用该训练权重对图像进行预测,获得预测结果。预测结果包括目标检测预测结果,先验框调整后预测框内病灶的置信度,先验框位置信息。
模型每层权重本质为矩阵滤波器,对原始输入层图像获得的不同通道权重处理,为每个通道施加不同权重,部分具有目标特征的通道获得较高的权值,而非重点目标权值降低,以提取出具有特征信息的特征层。权值具体作用示意图如下。
该模型结构为本专利原创设计的mobilenet-ssd模型,使用mobilenet卷积神经网络进行主干特征提取,层数为81层。同时该模型使用ssd模型进行目标检测的层数为62,本模型总层数为143层,总权重参数量达6,272,140,训练获得权值参数为6,246,796,每个权重参数均为本专利进行模型学习过程中自行建立,为本专利特有权重参数。本专利涉及权重参数量过多(附表1),仅以模型中第2层(conv1_bn层)的权重参数为例进行列举说明。
附表1.mobilenet-ssd模型结构及参数量
以mobilenet-ssd模型中第2层(conv1_bn层)的权重参数为例进行列举说明如下:
conv1_bn层权值参数表为模型经过训练后,保存在conv1_bn层的权值参数,该参数量为128,由4个数组组成,当进行图像预测时,输入图像经过该层,获得不同的通道数,利用该参数对各通道进行权重处理,使计算机区分不同通道的权重重要性,以便提取出图像中的特征部分,传入下一层继续进行处理。该参数仅为整个模型中conv1_bn层权值参数(附表2)。
本发明中整个模型内全部权值参数总计6,272,140个,其中训练获得权值参数为6,246,796个,均为模型边训练边调整获得,为本发明所特有。
附表2.mobilenet-ssd模型conv1_bn层权值参数
(4)预测结果解码(decoder)。利用先验框和目标检测预测结果处理获得的预测框位置。将预测结果传入bboxutility函数进行解码,将目标检测预测结果转换为预测框。而后,对每个预测框中病灶进行分类,并且判断分类结果的置信度是否大于阈值(threshold)。结果大于阈值的预测框保留,结果小于阈值的预测框丢弃。而后进行iou的非极大值抑制(non-maximumsuppression,nms),筛选出置信度较高且重合程度较小的预测框。而后依照不同分类对不同框的置信度进行排序,最后挑选出置信度较高的预测框。
(5)图像复原。使用correctboxes函数去除尺寸大小调整过程中给原图像添加的灰色像素值,使图像恢复原来大小。
(6)输出预测框。输出预测框内病灶分类的标签及该预测框的置信度。
本发明所述语义分割模型为以cnn模型作为主干特征提取模型构建语义分割模型;主干特征cnn模型可包括vgg16、mobilenet、resnet50、inceptionv3、inception-resnet-v2和xception等,同时可使用多种语义分割模型,包括segnet、unet和pspnet等。具体过程包括:
(1)输入图像大小调整;根据语义分割模型网络结构训练要求的图像大小,调整输入图像的长×宽×通道数(height×width×channel)。
(2)主干特征提取模型构建。使用主干特征提取网模型获取n个有效特征层。有效特征层的表示方法为有效特征层的长×宽×通道数(height×width×channel)。主干特征模型可采用cnn分类网络模型,包括vgg16、mobilenet、resnet50、inceptionv3、inception-resnet-v2和xception等。
(3)语义分割模型构建。语义分割模型分为编码(encoder)和解码(decoder)过程。编码过程为特征提取部分,主要由主干特征提取模型进行特征提取,获得特征层(f1-fn)。解码部分为上采样过程,将特征图像恢复为与输入图像相同尺寸的携带分割信息的分割图像。
进一步,所述胃癌样本图片中目标病灶精细分割与勾勒,包括下列步骤:
(1)输入图像备份。对输入图像进行备份,便于预测结果与原始图像进行叠加观察。
(2)图像大小调整(resize)。根据不同语义分割模型结构,将图像输入尺寸调整为模型训练所需的长×宽(height×width)。图像尺寸归一过程利用letterboximage函数,但该过程不对图像进行拉伸处理,而是利用灰色像素值填充空白图像区域,获得不失真图像,使图像大小达到所需height×width。
(3)图像归一化。将调整大小后图像归一化,对每个像素值除以255,将像素值归一为[0,1]。
(4)训练权重载入。为实现输入图像中病灶的预测,首先载入语义分割模型结构及模型训练权重。
该模型结构为本发明原创设计的mobilenet-unet模型,使用mobilenet卷积神经网络进行主干进行特征提取,层数为81层。同时该模型使用unet语义分割模型进行语义分割,层数为17层,本模型总层数为98层,总权重参数量达12,346,050,其中训练获得权值参数为12,327,234,每个权重参数均为本专利进行模型训练中边训练边调整获得,为本发明特有的权重参数。由于本发明权重参数量过多(附表3),无法完全列举,仅以模型中第2层(conv1_bn层)权重参数为例做列举说明。
附表3.mobilenet-unet模型结构及参数量
以mobilenet-unet模型中第2层(conv1_bn层)的权重参数为例进行列举说明如下:
mobilenet-unet模型conv1_bn层的权值参数表(附表4)为模型经过训练后保存在conv1_bn层的权值参数,该参数量为128个,由4个数组组成,当进行图像预测时,输入图像经过该层,提取获得的通道,利用该参数进行权重处理,使计算机明确通道中具有较高权重的特征区域,以便提取出图像中的特征部分,传入下一层继续进行处理。
本发明中整个模型的权值参数有12,346,050个,其中训练获得的权值参数为12,327,234个,均是模型边训练边调整获得,为本发明所特有。
附表4.mobilenet-unet模型conv1_bn层权值参数
(5)对传入模型的图像中每一个像素点进行预测。使用augmax函数提取出对每个像素点预测后的分类结果。
(6)图像复原。使用correctboxes函数去除尺寸大小调整过程中给原图像添加的灰色像素值,使图像恢复原来大小。
(7)结果输出。判断每个像素点的分类结果,不同分类结果像素点给予不同颜色标注,而后将手术切除的胃原始图片与模型预测的结果进行混合,获得预测结果图像。
第二方面,本发明实施例提供一种基于卷积神经网络的胃癌病灶检测装置,包括:
胃癌样本大体图像提取单元,用于提取待检测的胃癌样本大体图像;
病灶检测单元,用于将所述胃癌样本区域输入至目标检测算法模型和语义分割算法模型,得到所述病灶检测模型输出的病灶检测结果;
其中,所述病灶检测模型是基于样本胃癌大体图像中的每一像素点,以及样本病灶检测结果训练得到的;
所述病灶检测模型用于确定所述胃癌样本区域中每一像素点的区域病灶识别结果,并基于每一像素点的区域病灶识别结果,或者基于每一像素点的区域病灶识别结果和所述胃癌样本区域的候选病灶检测结果,确定所述病灶检测结果。
第三方面,本发明实施例提供一种电子设备,包括图像处理器、通信接口、存储器和总线,其中,图像处理器,通信接口,存储器通过总线完成相互间的通信,处理器可以调用存储器中的逻辑命令,以执行如第一方面所提供的方法的步骤。
第四方面,本发明实施例提供一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现如第一方面所提供的方法的步骤。
本发明与现有技术相比,具有如下优点和有益效果:
1、现有技术尚缺乏对手术切除胃标本中的癌症病灶定位和转移灶预测手段。本发明基于cnn模型、目标检测和语义分割算法,其中目标检测算法可以自动化定位胃切除标本中癌症病灶和胃内或胃周转移性癌灶,在定位癌症病灶的同时还可以给出分析结果的置信度,辅助标本检验医师对标本中可能存在病变的部位进行准确切取,提高癌症病灶检出效率,减少漏诊率。
2、本发明技术方案能够实现自动化对胃切除术标本内的胃癌病灶进行定位与勾勒,能将病灶区域与背景区域清晰地分割开来。本发明的最大优势是可以识别到医师肉眼难以发现的转移病灶(包括为胃内主癌周围以及侵犯到胃癌的癌结节),对于指导手术后医师的精准取材与后续病理学检验具有很好的指导作用。
3、本发明构建的胃癌手术切除大体标本图像不属于常规诊疗生成的临床影像数据,该图像数据集为发明者专有数据集。通过训练mobilenet-ssd目标检测网络及mobilenet-unet语义分割网络获得的模型权值文件为本专发明专有权重文件。采用本发明内权重参数整合的模型便能够实现胃癌大体标本图像中胃癌病灶的目标检测和精准分割。
附图说明
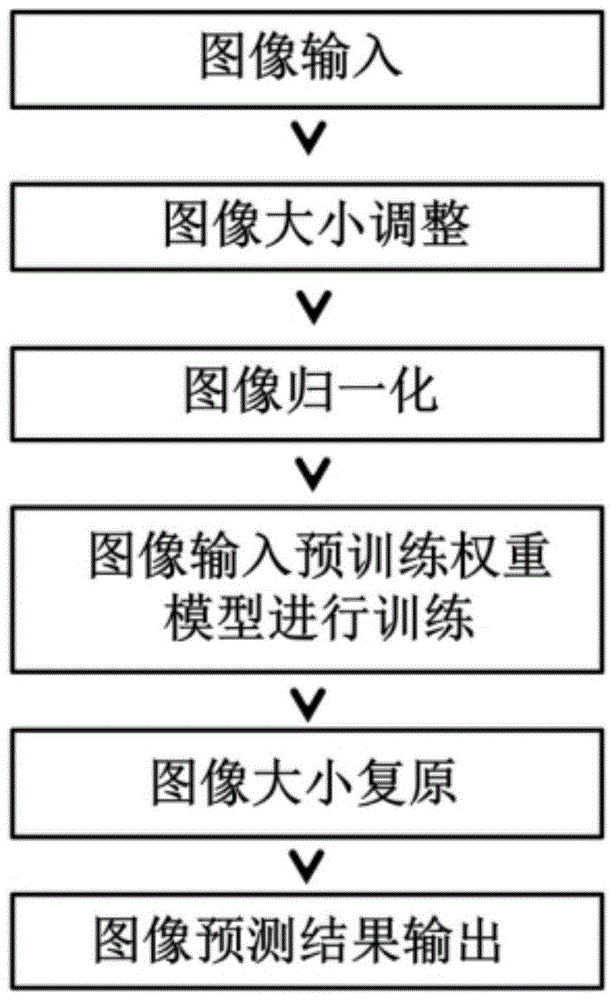
图1为本发明总体流程图;
图2为目标检测算法模型的总体运行流程图;
图3为目标检测算法模型的图像预测运行流程图;
图4为目标检测算法模型预测结果说明图;
图5为语义分割算法模型的总体运行流程图;
图6为语义分割算法模型的的图像预测运行流程图;
图7为语义分割算法模型预测结果说明图;
图8为模型权重说明图;
具体实施方式
下面结合具体实施例,进一步阐述本发明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。
本发明中的相关术语如下所示:
胃癌(gastriccancer,gc):是起源于胃黏膜上皮细胞的恶性肿瘤,胃癌恶性程度较高,在中国,胃癌发病率居所有恶性肿瘤的第二位,死亡率据所有恶性肿瘤的第三位。胃癌分为早期胃癌及进展期胃癌。
卷积神经网络cnn:是深度学习的一类模型,其基于模拟人类大脑中的神经网络结构,构建计算机模型和算法网络。cnn的基本结构由输入层、卷积层、激励函数、池化层及全连接层构成。
mobilenet:是卷积神经网络算法的一个模型,该模型属于一种可置于移动端或者嵌入式设备中轻量级cnn网络,mobilenet的基本结构为深度可分离卷积。
ssd(singleshotmultiboxdetector)目标检测算法:ssd作为目前主流的目标检测框架之一,是2016年由weiliu等人提出。ssd模型兼顾了yolo及fasterr-cnn模型的优缺点,具有较快的检测速度及能与fasterr-cnn比肩的目标检出率,其借鉴了fasterr-cnn模型的先验框和特征金字塔层的感兴趣区提取方式,相比于yolo和fasterr-cnn模型,具有比yolo更高的准确率和漏检率,具备比fasterr-cnn模型更快的检测速度。由于ssd模型参数量较小,对于计算机显存占用率相对较小。ssd模型继承了单级式目标检测方法,在一个封装模型内完成区域建议和目标分类,较其他模型框架拥有更快的运行速度和检测精度。
unet语义分割算法:unet模型是目前医学影像语义分割模型中应用最为广泛的模型。unet网络结构为一个对称结构,其结构类似于字母u,由下采样(特征提取)和上采样构成,其过程也被称为编码-解码过程。通过下采样对图像特征进行提取,而后通过上采样输出图像特征,获得图像分割结果。unet模型结构简单,参数量少,特别适用于数据量较小的医学图像分类。因为较多的医学图像获取难度较大,若模型涉及参数过大则容易导致过拟合。因此,具有简单结构的unet模型在大多数医学图像数据集研究上都取得了较好的表现。
本实施例是一种基于人工智能卷积神经网络的胃癌大体图像病灶提取及分割方法,包括下述步骤:
s1、胃癌切除标本大体图像的预处理,包括图像裁剪、训练集、验证集及测试集图像的划分、训练集和验证集图像的扩增。
s101、胃癌切除标本大体图像的采集。收集胃部肿瘤手术切除后大体标本,并进行数字化图像拍照。本实施例入组了171幅手术切除的胃癌大体标本图像,并同时收集性别、年龄、肿瘤分型和淋巴结转移情况等临床基本信息。
s102、图像裁剪。为减小图像训练过程中计算机处理负荷,并且充分利用图像的每个像素,使用ps手工对图像进行裁剪,裁去区域主要包括去除患者身份可识别信息条,背景垫布,多余的网膜组织,仅保留胃部主体图像。这样,可以避免凹凸不平的周围信息对模型训练产生干扰。裁去能识别患者的信息条是为了保护患者隐私。
s103、训练集、验证集及测试集的划分。根据目标检测及语义分割模型训练的需要,将采集的数据集划分为训练集、验证集及测试集。在本次模型训练过程中,目标检测模型训练集和验证集图像123幅,测试集图像42幅;在语义分割模型中训练集和验证集110幅图像,测试集47幅图像。
s104、训练集和验证集图像的扩增。由于医学图像的获取难度较大,为获得足够的数据量满足深度学习的训练需求,对训练集和验证集图像可以进行图像扩增。增强方式包括:随机旋转(rotation=15,最大旋转角度15°)、随机水平平移(widthshift=0.1,最大值为水平平移图像宽度10%)、随机垂直平移(heightshift=0.1,最大值为垂直平移图像高度10%)、水平或垂直投影变换(shear=0.1,最大变换比例为图像尺寸的10%)、按比例随机缩放图像尺寸(zoom=0.1,随机缩放图像尺寸最大值为图像长或宽10%)、随机水平翻转和填充(nearest,选择最近的像素进行填充)。目标检测模型训练集和验证集扩增至2502幅图像,最终数据集结构为训练集2127幅图像,验证集375幅图像,测试集42幅图像;而语义分割模型训练集和验证集扩增至1044幅图像,最终数据集结构为训练集892幅图像,验证集158幅图像,测试集47幅图像。
s2、目标检测病灶的目标提取及置信度分析——以mobilenet-ssd为例。
s201、数据标注及数据集的生成。原始图像格式为.jpg格式,先由有经验的医学专家对训练集、验证集及测试集的图像进行标注,标注方式为矩形框标注,标注范围为胃癌病灶,标注工具为labelimg,将标注后的标签(label)文件储存为.xml格式。voc数据集的生成。目标检测算法模型的训练依赖于voc训练集,以原始图像和标签文件为基础,利用算法生成对应的训练集,验证集和测试集标签.txt文件(train.txt;val.txt;test.txt)。同时生成对应图片存放位置,图像中病灶真实位置的真实框的坐标及病灶种类的.txt文件(2007_train.txt;2007_val.txt;2007_test.txt)。
s202、目标检测模型的构建。该目标检测模型以cnn模型mobilenet作为目标检测模型的特征提取骨架,构建ssd目标检测模型。采用深度可分离卷积(depthwiseseparableconvolution)进行图像特征的提取。具体过程包括:
(1)输入图像大小调整。ssd网络所需输入图像长×宽×通道数为300×300×3。
(2)主干特征提取网络构建。使用mobilenet主干特征提取网络进行特征提取,获取6个有效特征层;图像输入后,在不同卷积层提取特征,经过卷积操作后,共输出6个有效特征层,包括19×19×512,10×10×1024,5×5×512,3×3×256,2×2×256,1×1×256特征层。
(3)ssd目标检测。根据主干特征网络提取的特征层大小对图像标注先验框,不同大小特征层标注不同数量的先验框;19×19×512特征层每个像素设置6个先验框,共2166个先验框;10×10×1024特征层每个网格设置6个先验框,共600个先验框;5×5×512特征层每个设置6个先验框,共150个先验框;3×3×256网格每个设置6个先验框,共54先验框;2×2×256特征层每个设置6个先验框,共24个先验框;1×1×128特征层每个设置6个先验框,共6个先验框。经过该过程,总共提取的先验框数量3000个。然后对提取的每一个有效特征层使用两个卷积进行处理。第一个卷积是num_priors×4的卷积,使用4个参数对该特征层上的每个像素每个先验框进行调整;第二个卷积是num_priors×num_class的卷积,可获得该特征层上的每个像素每个先验框识别病灶的种类及置信度。
(4)最终获得所有调整后的先验框情况及每个调整后先验框里的病灶预测的置信度。
s203、目标检测模型训练。
(1)参数设置;
分类数量(numclass)设置。分类病灶个数+1(背景参数);在本实验中,numclass=2(分为两类,胃癌及背景:gc和backgroud)。
训练参数。包括modelcheckpoint(将拥有最佳验证集损失函数值(valloss)的训练模型保存)、reducelronplateau(学习率自动调整,当验证集损失函数值(valloss)5个周期不下降、则将学习率调整为原来的1/2)、earlystopping(当验证集损失函数(valloss)25个周期不下降、则停止训练)和batchsize(批大小,每次实验传入多少图片进入模型,本实验设置batchsize为16)。
(2)载入预训练模型。为提高训练效率,使用迁移学习策略,将在imagenet数据集训练完成的预训练权重(essay_mobilenet_ssd_weights.h5)加载入本模型进行训练。
(3)输入图像大小调整(inputshape)。将输入图像大小调整为300×300。
(4)训练验证集划分。将输入图像划分为训练集和验证集,训练集与验证集划分比例为9:1(90%用于训练集,10%用于验证集)。
(5)使用数据生成器generator处理图像,将图像转化为ssd模型能够训练的信息格式,为模型传入数据进行训练。
打乱读入图像信息(shuffle)。打乱图像处理过程中生成的2007_train.txt文件中图像信息,而后依次读入图像,图像中病灶位置信息及病灶分类。
图像处理。对输入图像进行随机裁剪,随机增加噪声。
真实框编码(assignboxes)。将输入的真实框信息编码为卷积神经网络训练所需的结构。计算真实框与所有先验框的iou,找到与真实框重合程度较高的先验框,提取出该类先验框,意味着可以通过调整该类先验框进行预测框预测;计算真实框的中心及长宽;再计算与先验框重合度较高的先验框的中心及长宽;获得真实框及先验框编码后结果。而后提取出与真实框重合程度最高的先验框,并且获得该先验框的索引信息,并将该信息保存至矩阵中。最终将真实框信息转换成与预测结果相同的信息结构,以便于与输入图像进行ssd预测后获得的预测结果进行对比,求取损失函数(loss)。
损失函数计算(multiboxloss)。y-true表示真实框信息;y-pred表示ssd预测结果信息,使用损失函数softmax计算损失函数值。获得先验框病灶分类的损失函数值和位置的损失函数值;对于病灶分类损失函数的计算,首先进行正样本和负样本的筛选,筛选出的正负样本比例为1:3,分别计算置信度损失函数值,然后对总体损失函数值进行计算,获得训练后的模型。
(6)冻结训练。冻结mobilenet中前81层,主要冻结特征提取层,设置初始学习率(learningrate,lr)为5×10-4,由于该初始学习率相对较大,因此该部分训练为粗略训练,目的是对81层以后的模型进行训练。
(7)解冻训练。解除前81层冻结,设置初始学习率为1×10-5,该初始学习率相对较小,对模型进行精细训练。
s204、胃切除标本图像中胃癌病灶的定位。
(1)图像大小调整(resize)。由于ssd模型预测图像要求输入的图像尺寸为300×300×3,对于不同大小的输入图像首先进行尺寸大小调整,变成300×300×3。图像尺寸归一过程利用letterboximage过程,将输入图像的归一化为300×300×3,该过程不对图像进行拉伸处理,而是利用灰色像素值填充空白图像区域,获得不失真图像,使图像大小达到300×300×3。
(2)图像预处理和图像归一化。将resize后的图像归一化,像素值归一为[0,1]。
(3)预训练权重的载入。为实现输入图像预测,首先载入ssd模型结构及模型训练权重(该预训练模型是模型训练过程中获得,ep302-loss1.765-val_loss2.027.h5)。
(4)图像预测。使用该训练权重对图像进行预测,获得预测结果,预测结果包括ssd预测结果,先验框调整后预测框内病灶的置信度,先验框位置信息。
(4)预测结果解码(decoder)。利用先验框信息和ssd预测结果,处理获得预测框位置。将预测结果传入bboxutility函数进行解码,将ssd预测结果转换为预测框。而后,对每个预测框中病灶进行分类,并且判断分类结果置信度是否大于阈值,大于则对该预测框进行保留,小于的则放弃。而后进行iou非极大值抑制,筛选出置信度较高且重合程度较小的预测框。而后依照不同分类对不同框的置信度进行排序,最后挑选出置信度最高的预测框。
(5)图像复原。使用ssdcorrectboxes函数去除尺寸大小调整过程中给原图像添加的灰色像素值,使图像恢复原来大小。
(6)预测结果输出。输出预测框,预测框内病灶分类标签及该预测框置信度。
s3、语义分割目标病灶精细分割及胃内和胃周转移性癌症病灶的预测——以mobilenet-unet为例。
s301、数据标注及数据集生成。原始图像格式为.jpg格式,先由有经验的医师对训练集、验证集及测试图像进行标注,标注方式为勾勒出病灶边缘,标注范围为医师肉眼可见胃癌病灶,标注工具为labelme,标注后文件储存为.json格式。voc数据集生成。语义分割模型训练也依赖于voc训练集,以原始图像和标签文件.json为基础,利用算法生成与原始图像对应的mask图像,mask图像使用灰度图像储存图像标注信息,格式为.png图像。同时利用算法生成对应的训练集,验证集和测试集标签.txt文件(train.txt;val.txt;test.txt)。
s302、语义分割模型的构建。
(1)输入图像大小调整。unet网络所需输入图像长×宽×通道数为416×416×3。
(2)主干特征提取网络构建。使用mobilenet主干特征提取网络进行特征提取,经过深度可分离卷积提取特征及图像压缩,获取5个有效特征层。提取的特征层(长×宽×特征通道数)包括:416×416×64(f1);208×208×128(f2);104×104×256(f3);52×52×512(f4);26×26×512(f5)。
(3)unet语义分割模型的构建;unet语义分割模型分为编码(encoder)和解码(decoder)过程。编码过程为特征提取部分,主要由主干特征提取网络进行特征提取,获得提取的特征层(f1,f2,f3,f4,f5)。解码部分为上采样过程,将特征图像恢复为与输入图像相同尺寸的携带分割信息的分割图像。
第一次上采样。解码过程将传入的特征层f5(26×26×512)进行零填充(zeropadding2d),卷积(conv2d)和标准化(batchnormalization)后进行上采样,将f4特征层变为长×宽×通道数为52×52×512后,与编码过程中的f4特征层(52×52×512)进行合并连接(concatenate)后,获得52×52×1024图像结构后,再进行零填充(zeropadding2d),卷积(conv2d)和标准化(batchnormalization)获得52×52×512特征层结构,而后进行第二次上采样。
第二次上采样。将传入的第一次上采样结果(52×52×512)进行第二次上采样,将特征层变为长×宽×通道数为104×104×512后,与编码过程中的f2特征层(104×104×256)进行合并连接(concatenate)后,获得104×104×768图像结构后,再进行零填充(zeropadding2d),卷积(conv2d)和标准化(batchnormalization)获得104×104×256特征层结构,而后进行第三次上采样。
第三次上采样。将传入的第二次上采样结果(104×104×256)进行第三次上采样,将特征层变为长×宽×通道数为208×208×256后,与编码过程中的f2特征层(208×208×128)进行合并连接(concatenate)后,获得208×208×384图像结构后,再进行零填充(zeropadding2d),卷积(conv2d)和标准化(batchnormalization)获得208×208×128特征层结构。
第四次上采样。将传入的第二次上采样结果(208×208×128)进行第三次上采样,将特征层变为长×宽×通道数为416×416×128后,与编码过程中的f2特征层(416×416×64)进行合并连接(concatenate)后,获得416×416×192图像结构后,再进行零填充(zeropadding2d),卷积(conv2d)和标准化(batchnormalization)获得208×208×128图像结构,最后进行卷积输出416×416×2结构层。
最后使用softmax函数求取每一个像素点属于每一个病灶类别的概率。
s303、语义分割模型的训练。
(1)参数设置。
分类数量(numclass)设置;分类病灶个数+1(背景参数);在本实验中,numclass=2(分为两类,胃癌及背景:gc和backgroud)。
训练参数设置。modelcheckpoint(将拥有最佳验证集损失函数值(valloss)的训练模型保存);reducelronplateau(学习率自动调整,当验证集损失函数值(valloss)5个周期不下降、则将学习率调整为原来的1/2);earlystopping(当验证集损失函数(valloss)20个周期不下降、则停止训练);batchsize(批大小,每次实验传入多少图片进入模型,本实验设置batchsize为8)。
(2)载入预训练模型。为提高训练效率,使用迁移学习策略,将在imagenet数据集训练完成的预训练权重(mobilenet_1_0_224_tf.h5)加载入本模型进行训练。
(3)输入图像大小调整(inputshape)。将输入图像大小调整为416×416。
(4)训练集和验证集划分。将输入的图像划分为训练集和验证集,训练集验证集比例为9:1(90%用于训练集,10%用于验证集)。
(5)冻结训练;冻结mobilenet中前81层,主要冻结特征提取层,设置初始学习率(learningrate,lr)为5×10-4,由于该初始学习率相对较大,因此该部分训练为粗略训练,目的是对81层以后的模型进行训练。
(6)解冻训练。解除前81层冻结,设置初始学习率为1×10-5,该初始学习率相对较小,对模型进行精细训练。
s304、胃手术切除标本图像中胃癌灶的定位与病灶分割。
(1)输入图像备份。对输入图像进行备份,便于预测结果输出。
(2)图像大小调整(resize)。首先读取输入图像尺寸。由于unet预测图像要求输入的图像尺寸为416×416×3,对于不同大小的输入图像首先进行尺寸大小调整,变成416×416×3。图像尺寸归一过程利用letterboximage过程,将输入图像的归一化为416×416×3,该过程不对图像进行拉伸处理,而是利用灰色像素值填充空白图像区域,获得不失真图像,使图像大小达到416×416×3。
(3)图像预处理和图像归一化。将resize后的图像归一化,像素值归一为[0,1]。
(4)预训练权重的载入。为实现输入图像预测,首先载入unet模型结构及模型训练权重(该预训练模型是模型训练过程中获得,ep289-loss0.179-val_loss0.163.h5)。
(5)图像的预测。使用该训练权重对传入模型的图像中每一个像素点进行预测。而后使用augmax函数,提取出每个像素点预测后的分类结果。
(6)图像复原。使用correctboxes函数去除尺寸大小调整过程中给原图像添加的灰色像素值,使图像恢复原来大小。
(7)结果输出。判断每个像素点的分类结果,不同分类结果像素点给予不同颜色标注(本发明的实例预测中胃癌被标注为红色;背景为灰色)。而后将原始图像与预测结果进行混合,获得预测结果图像。
基于本发明对胃癌主病灶和胃周围转移癌灶预测结果的精确性分析
我们以手术后病理诊断作为金标准,计算了本发明判别为胃癌与病理诊断为胃癌的一致性显示(附表5),本发明的评估结果与病理诊断金标准的一致性达到98%。同样,我们以术后病理诊断作为胃周有无癌结节或者淋巴结转移作为金标准,分析了本发明预测胃周癌症病灶的转移显示,本发明判别为有胃周围癌症转移结节与病理诊断金标准的一致性为51%(附表6)。
附表6.本发明判定胃内胃癌病灶与病理诊断金标准的一致性分析
*注释:一例预测阴性为早期胃癌,浅表平坦性(ⅱb),病灶形态与周围正常胃黏膜差异较小,特征性欠缺故而漏检;另外一例为进展期胃癌,溃疡型。由于部位位于胃大弯侧与胃黏膜皱襞相交织而出现漏检。未来可以通过增加早期胃癌病例以及训练识别大弯侧病变得到改善。
附表7.本发明预测胃周围转移癌结节与病理诊断金标准的一致性分析
综上为本发明具体实施例的详细描述,显示本发明的预测胃内癌症病灶显示良好的准确性;对于预测胃周围转移性癌结节具有一定的一致性。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种调整或修改,这并不影响本发明的实质。
- 还没有人留言评论。精彩留言会获得点赞!