基于RANSAC算法的多元随机抽查方法、系统、装置与流程
本发明属于随机抽查技术领域,特别是涉及一种基于ransac算法的多元随机抽查方法、系统、装置。
背景技术:
2014年,国家市场监督管理局(原质检总局)、国家标准委部署开展了企业标准自我声明公开试点工作。为进一步规范企业标准自我声明公开工作,加强事中事后监管,上海、浙江、广州等地相继开展自我声明公开企业产品标准监督抽查工作。自2015年起,公司受浙江省市场监督管理局及各地市局委托,探索开展自我声明公开企业标准监督检查。
但由于各地产业发展情况和抽查要求不尽相同、企业标准数据资源受限、线下抽查效率低下、检查数据可追溯性差、检查结果运用不充分等原因,严重阻碍了自我声明公开企业产品标准监督抽查工作的顺利开展,不利于提升企业标准化整体水平。
技术实现要素:
本发明的目的之一在于提供一种基于ransac算法的多元随机抽查方法、系统、装置,发明通过提取原始企业标准数据的各种属性,形成原始关系型数据库。运用ransac算法,通过迭代的方式计算抽样的最佳模型,能满足精准开展企业标准事后监管工作的需求。同时,充分运用大数据分析手段,全面掌握浙江省企业标准现状,为及时调整标准化工作政策、策略和重点提供现实依据,为提高企业标准整体水平,提升我省标准化工作质量,助推产业高质量发展贡献一份力量。
为解决上述技术问题,本发明是通过以下技术方案实现的,当然,实施本发明的任一产品并不一定需要同时达到以上所述的所有优点:
一种基于ransac算法的多元随机抽查方法,包括如下步骤:
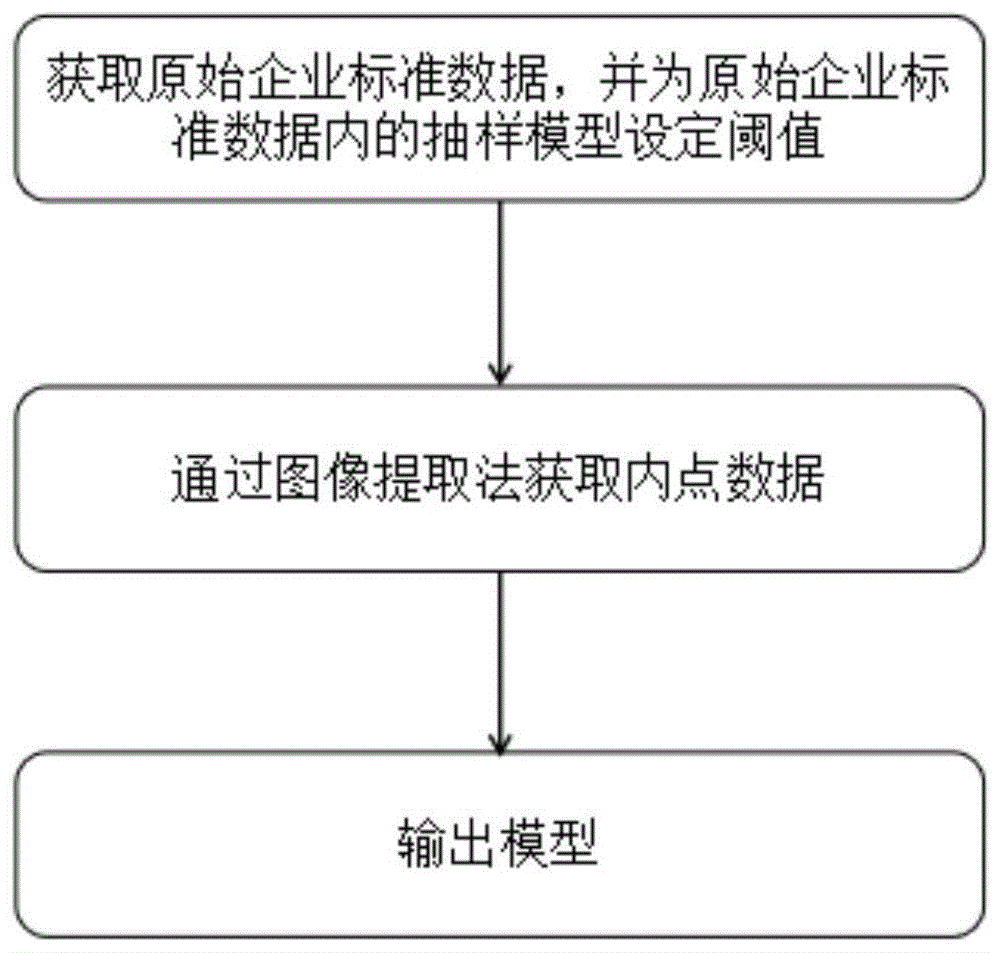
步骤s10:获取原始企业标准数据,并为原始企业标准数据内的抽样模型设定阈值;
步骤s20:选取m个标准,计算标准与各个抽样条件的相关性,误差在设定的阈值以内的为内点,即匹配成功;
其中,计算标准与各个抽样条件的相关性具体包括:
将原始企业标准数据转化为图片格式,然后对其进行特征提取;
选取相对应的标准和任一抽样条件,使用暴力匹配法进行初次匹配;
将两幅图片网格化,根据网格区域匹配的数目,找出最有可能代表相同区域的网格对;
根据运动平滑性,判断网格区域的正确匹配率,提取出误匹配率极低的网格区域;
对于提取出的网格区域内的特征点,运用ransac算法计算对应的单应矩阵;
通过计算得到的单应矩阵,与预设定的阈值进行匹配;
步骤s30:重复步骤s20、步骤s30,迭代次数达到预设值后,保存最多的内点数对应的模型参数作为最终抽样模型。
可选的,原始企业标准数据包括标准编号数据、标准名称数据、标准状态数据、标准类型数据、标准性质数据、公开时间数据、行政区划数据、标准种类数据、所属产业类别数据。
可选的,步骤s01中,获取原始企业标准数据后,将所获取的原始企业标准数据存入原始关系型数据库,并为原始关系型数据库内的抽样模型设定阈值。
可选的,计算抽样的最佳模型具体包括如下步骤:
步骤s11:输入匹配的特征点;
步骤s12:随机选取m个点估计模型;
步骤s13:计算数据点的误差,并保存内点;以及
步骤s14:判断是否出现最佳模型,若否,则回到步骤s12,若是,则进入步骤s20。
可选的,步骤s20中还包括如下步骤:
步骤s21:随机选取m个点估计模型;
步骤s22:使用新的阈值计算内点并保存模型;
步骤s23:在内点中选取子集并估计模型。
可选的,步骤s30中,判断是否达到设定的迭代次数,若否,则回到步骤s21,若是,则进行捆集调整操作。
可选的,在进行捆集调整操作后,输出最终抽样模型。
可选的,原始企业标准数据从企业标准信息服务平台中获取。
一种基于ransac算法的多元随机抽查系统,该系统加载有如上任一项所述的方法。
一种基于ransac算法的多元随机抽查装置,该系统应用有如上任一项所述的方法。
附图说明
构成本申请的一部分的说明书附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
图1为本发明一实施例的流程图;
图2为本发明一实施例的ransac算法流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
为了保持本发明实施例的以下说明清楚且简明,本发明省略了已知功能和已知部件的详细说明。
请参阅图1-2所示,在本实施例中提供了一种基于ransac算法的多元随机抽查方法,包括如下步骤:
步骤s10:获取原始企业标准数据,并为原始企业标准数据内的抽样模型设定阈值;
步骤s20:选取m个标准,计算标准与各个抽样条件的相关性,误差在设定的阈值以内的为内点,即匹配成功;
其中,计算标准与各个抽样条件的相关性具体包括:
将原始企业标准数据转化为图片格式,然后对其进行特征提取;
选取相对应的标准和任一抽样条件,使用暴力匹配法进行初次匹配;
将两幅图片网格化,根据网格区域匹配的数目,找出最有可能代表相同区域的网格对;
根据运动平滑性,判断网格区域的正确匹配率,提取出误匹配率极低的网格区域;
对于提取出的网格区域内的特征点,运用ransac算法计算对应的单应矩阵;
通过计算得到的单应矩阵,与预设定的阈值进行匹配;
步骤s30:重复步骤s20、步骤s30,迭代次数达到预设值后,保存最多的内点数对应的模型参数作为最终抽样模型;
其中,ransac算法迭代次数k满足如下公式:
1-pm=(1-ηm)k
其中,m表示计算模型参数所需的最少数据;pm表示置信度,表示所选的m个数据至少有一个是内点的概率;η表示所选数据是外点的概率;
k的解析式为:
本实施例通过图像提取法对标准与抽样条件的匹配关系进行计算,不仅能够提高匹配的实时性,而且能够显著的提高匹配算法的召回率,从而满足精准开展企业标准事后监管工作的需求。
在本实施例中,原始企业标准数据包括标准编号数据、标准名称数据、标准状态数据、标准类型数据、标准性质数据、公开时间数据、行政区划数据、标准种类数据、所属产业类别数据。
在本实施例中,步骤s01中,获取原始企业标准数据后,将所获取的原始企业标准数据存入原始关系型数据库,并为原始关系型数据库内的抽样模型设定阈值。
在本实施例中,计算抽样的最佳模型具体包括如下步骤:
步骤s11:输入匹配的特征点;
步骤s12:随机选取m个点估计模型;
步骤s13:计算数据点的误差,并保存内点;以及
步骤s14:判断是否出现最佳模型,若否,则回到步骤s12,若是,则进入步骤s20。
在本实施例中,步骤s20中还包括如下步骤:
步骤s21:随机选取m个点估计模型;
步骤s22:使用新的阈值计算内点并保存模型;
步骤s23:在内点中选取子集并估计模型。
在本实施例中,步骤s30中,判断是否达到设定的迭代次数,若否,则回到步骤s21,若是,则进行捆集调整操作,并输出最终抽样模型。
可选的,原始企业标准数据从企业标准信息服务平台中获取。
一种基于ransac算法的多元随机抽查系统,该系统加载有如上任一项所述的方法。
一种基于ransac算法的多元随机抽查装置,该系统应用有如上任一项所述的方法。
上述实施例可以相互结合。
需要说明的是,本申请的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本申请的实施方式能够以除了在这里图示或描述的那些以外的顺序实施。
以上公开的本发明优选实施例只是用于帮助阐述本发明。优选实施例并没有详尽叙述所有的细节,也不限制该发明仅为所述的具体实施方式。显然,根据本说明书的内容,可作很多的修改和变化。本说明书选取并具体描述这些实施例,是为了更好地解释本发明的原理和实际应用,从而使所属技术领域技术人员能很好地理解和利用本发明。本发明仅受权利要求书及其全部范围和等效物的限制。
- 还没有人留言评论。精彩留言会获得点赞!