使用沙漏预测器生成对象的方法与流程
1.本公开总体上涉及一种用于通过使用来自相似类型的对象和相关对象的信息的沙漏预测器来生成二维或三维对象的系统和方法。本公开的各种实施例涉及将这些方法应用于牙科、正畸和耳部相关对象。
背景技术:
2.机器学习可用于从大组数据中得出信息并使用该数据生成新对象。但是,许多用于生成新对象的方法仅使用相似类型的对象。这些方法没有考虑不是来自对象本身的相关数据,因此可能会遗漏有关环境和其他因素的重要考虑。
技术实现要素:
3.公开了一种被配置为生成输出数据的计算机实现的方法。该方法包括:
4.在第一组训练输入数据上训练自动编码器以识别第一组潜变量并生成第一组输出数据,其中,自动编码器包括第一编码器和第一解码器,其中,第一编码器将第一组输入数据转换为第一组潜变量,其中,第一解码器将第一组潜变量转换为第一组输出数据,其中,第一组输出数据至少与第一组训练输入数据基本相同;
5.训练沙漏预测器以返回第二组潜变量,其中,沙漏预测器包括第二编码器和第一解码器,其中,第二编码器将第二组训练输入数据转换为第二组潜变量,其中,第二组潜变量具有与第一组潜变量可比较的数据格式,第一解码器将第二组潜变量转换为至少与一组训练目标数据基本相同的第二组输出数据,并且第二组训练输入数据与第一组训练输入数据不同;和
6.对第三组输入数据使用沙漏预测器以生成第三组输出数据,其中,第三组输出数据是与第一组输出数据的数据格式可比较的数据格式。
7.典型的机器学习方法基于现有的相同类型的对象生成新对象。例如,可以通过在现有牙冠的大数据组上训练机器学习方法来生成牙冠。然而,以这种方式生成的牙冠并没有考虑到牙科环境的独特情况,例如可用空间。沙漏预测器添加来自牙科环境的信息以生成类似于牙科专业人员可针对一组独特的牙科环境制作的牙冠的牙冠。该实施例是沙漏预测器的灵活性的单个示例,因为沙漏预测器可以与任何相关的输入数据组一起使用。
8.沙漏预测器可以被配置为不仅基于相似对象而且基于相关对象来生成对象。例如,一个实施例使用沙漏预测器基于来自牙科患者的牙科环境生成牙冠。牙冠是一种牙齿修复体,它盖住或覆盖牙齿,使其恢复到正常的形状、大小或功能。牙科环境是牙冠或牙冠预备物周围对象的集合,包括但不限于:邻牙、对牙、牙龈、颌和/或预备物。目前,牙冠通常是根据牙科专业人士的判断手工制作或使用cad软件手动设计的。这是耗时的,并且高度依赖于牙科专业人员的个人判断。
9.创建沙漏预测器的第一步骤是训练自动编码器。自动编码器获取输入数据,将输入数据编码为一组潜变量,然后将潜变量解码为输出数据,其中输出数据至少与输入数据
基本相同,如下所述。它们经常用于去噪应用,例如从数码照片中去除伪影。对象本身可能难以用作输入数据,因此,可以替代地使用对象的表示。例如,2d图像可以表示牙齿。
10.一个实施例使用变分自动编码器。变分自动编码器是一种自动编码器,其中潜变量是从概率分布生成的,而不是直接从编码器生成的。使用概率分布允许对数据进行内插,以便在没有类似输入数据的情况下进行合理的估计。例如,该概率分布可以从均值和标准偏差向量或方差的对数生成。
11.为了训练自动编码器,第一编码器将第一组训练输入数据转换为第一组潜变量,然后第一解码器将第一组潜变量转换为第一组输出数据。编码器和解码器可以是神经网络。神经网络的示例包括但不限于卷积神经网络和密集神经网络。
12.在涉及生成牙冠的实施例中,牙冠可以由采样矩阵表示。在下面讨论的过程中,采样矩阵表示3d对象。采样矩阵使得神经网络能够应用于三维对象,并且能够对多个三维对象给予一致对待,从而可以对它们进行比较。
13.自动编码器可以使用多个采样矩阵作为第一组训练输入数据。每个采样矩阵可以表示为第一组潜变量。在本实施例中,可以存在至少三个潜变量,每个潜变量可以是标量数。然后第一解码器将第一组潜变量中的每一个解码回采样矩阵。
14.当第一组输出数据与第一组输入数据至少基本相同时,训练完成。在自动编码器用于生成牙冠的实施例中,这可以通过生成的牙冠和原始牙冠表面上的点之间的平均距离来衡量,并且足够相似的阈值可以是等于或小于0.1毫米的平均距离。
15.训练自动编码器使第一组潜变量能够参数化一种类型的对象,并允许将潜变量被解码回采样矩阵,该矩阵对应于底层对象(underlying object)的表示。
16.然而,自动编码器本身只生成与输入数据相同类型的输出数据,不考虑其他约束。例如,创建牙冠的自动编码器可以只生成牙冠,而不考虑附加信息,例如牙冠的相邻牙齿。第二步,训练沙漏预测器,允许在生成新对象时并入附加信息。
17.沙漏预测器保持来自自动编码器的第一解码器不变。但是,它使用第二组训练数据,其中第二组训练输入数据具有与第一组训练数据不同但相关的底层对象。尽管这些数据组可能不是同一类型的对象,但它们可彼此相关,因为每个数据组具有一些关于另一数据组的信息。训练目标数据与第一组训练输入数据具有相同类型的底层对象。
18.例如,在制作牙冠的实施例中,第二组训练输入数据是从牙冠或预备部位的牙周围环境得出的一组采样矩阵,并且训练目标数据是适合这些周围环境的牙冠。具有一组数据将告诉我们有关另一组数据的一些信息,例如,针对一组特定周围环境设计的牙冠的大小将会揭示关于相邻牙齿之间距离的一些信息。
19.为了训练沙漏预测器,第二组训练输入数据通过第二编码器进行编码,以返回第二组潜变量。该第二组潜变量具有与第一组潜变量相同的数据格式。在生成牙冠的实施例中,潜变量组的数据格式是标量数的向量。第二组潜变量然后由第一解码器解码以返回第二组输出数据,其具有与第一组输出数据相同类型的底层对象。第二组输出数据可以至少基本匹配训练目标数据。请注意,这些步骤训练第二编码器返回第二组潜变量,这些潜变量可以被解码为与第一组输出数据相同类型的对象。
20.在生成牙冠的实施例中,可以使用牙冠周围环境的表示来训练第二编码器返回解码成牙冠的潜变量。当生成的牙冠至少基本上与初始牙冠相同时,训练可以完成,例如,通
过与上述用于训练自动编码器的步骤相同的度量。
21.一旦沙漏预测器被训练,它就可以用于生成第三组输出数据,其与第一组训练输入数据具有相同类型的底层对象,其中与底层对象相同类型的第三组输入数据作为第二组训练数据。
22.对于生成牙冠的实施例,这意味着给定一组牙周围环境,可以生成牙冠,该牙冠预测牙科专业人员将针对这些牙周围环境创建什么。沙漏预测器应用灵活;如下所述,它可以针对不同情况进行训练,生成不同类型的对象。
23.在一个实施例中,沙漏预测器可用于基于治疗前数字2d图像生成期望牙科设置的提出的数字2d图像。
24.期望的牙科设置表示为患者提出的牙科设置,并可用于设计牙齿修复体或计划正畸治疗。期望的牙科设置可以具有提出的牙科治疗,并且可基于牙科专业人员设计的实际案例。提出的数字2d图像是期望牙科设置的2d图像。
25.治疗前数字2d图像是患者在治疗前的数字图像。它可以是显示患者微笑的2d图像,其中上前牙的一部分是可见的。
26.在牙科治疗中,重要的是能够在保持功能的同时给患者带来美观的微笑。有一些计划工具,其中向患者呈现预期的治疗结果,以使患者能够看到最终的微笑。本实施例中的沙漏预测器可以提供这样做的手段。例如,牙科专业人员可以使用期望牙科设置的提出的2d数字图像向患者展示她的牙齿在提出的治疗过程后的样子。
27.为了训练自动编码器,第一组输入训练数据将是期望牙科设置的一组提出的数字2d图像。2d图像可以是直接的2d图像,例如照片和/或3d模型的渲染作为2d图像,例如基于3d扫描的2d图像。相似性可以通过用于比较数字图像的通用度量来衡量,例如结构相似性指数(ssim)(wang、zhou、eero p.simoncelli和alan c.bovik的“multiscale structural similarity for image quality assessment,”第三十七届asilomar信号、系统和计算机会议,2003年,第2卷,ieee,2003。)
28.为了训练沙漏预测器,第二组输入训练数据将是一组治疗前数字2d图像,例如,患者治疗前的数字照片。该组训练目标数据可以包括一组对应的期望牙科设置的提出的数字2d图像,例如来自治疗前数字2d图像的病例的提出或实际治疗的数字2d图像。相似性度量类似于用于训练自动编码器的度量。
29.因此,经训练的沙漏预测器可以针对由治疗前数字2d图像表示的新病例生成期望牙科设置的提出的数字2d图像,类似于由牙科专业人员设计的那些。这使以前由牙科专业人员手动完成的工作自动化,可以节省治疗牙科患者的时间。如果需要,牙科专业人员可以进一步修改期望牙科设置的提出的数字2d图像。
30.实施例还包括其中第一组潜变量和/或第二组潜变量被用作输入数据和/或输出数据的参数化的情况。
31.参数可用于定义和更改其表征的对象。例如,对象可以被定义为具有5毫米的高度,但高度可以更改为10毫米。可以在欧几里德空间中对对象进行参数化,其中对象可以被平移、缩放、旋转、剪切、反射、映射和/或以其他方式通过各种函数参数化。
32.除了传统的欧几里得参数之外,机器学习方法可以允许基于关于对象信息的新的和有意义的参数。沙漏预测器的潜变量是这样的参数的示例。一组潜变量定义了对象的形
状;至少一个潜变量也可以用来更改对象的形状。
33.例如,作为参数的潜变量可用于通过一次改变牙齿的多个部分来对于更好的咬合更改牙冠的三维形状。如果更改不成功,可以简单地将参数值设置回其原始值。参数也允许优化。当对象根据参数值改变时,可以改变参数直到某个方面被优化。
34.实施例还包括这样的情况,其中第一组训练输入数据、第二组训练输入数据、该组训练目标数据和/或第三组输入数据基于三维对象,例如3d对象的三维扫描。
35.三维对象是存在于三个维度中的对象。在本公开的各种实施例中,三维对象包括但不限于:诸如牙齿修复体和牙列的物理对象、诸如各个牙齿模型的数字对象以及诸如牙齿修复体和耳部的物理对象的扫描。
36.实施例还包括其中第一组训练输入数据、第二组训练输入数据、第三组输入数据、该组训练目标数据、第一组输出数据、第二组输出数据和/或第三组输出数据包括以下一项或多项:对象的2d图像、深度图、伪图像、点云、3d网格和/或体积数据。
37.三维对象可以用二维和三维表示来进行表示。
38.三维对象的二维表示包括但不限于:深度图、基于面信息的伪图像、其他多角度图像。
39.二维表示在沙漏预测器中可能相对容易使用,因为它们通常是具有编码器/解码器神经网络可以直接使用的结构的图像。例如,二维图像可以由像素阵列组成,其中像素相对于其他像素具有定义的位置,以及可以作为标量数被读取的rgb或灰度值。标量数可以被标准化,也可以进行其他在神经网络预处理中有用的过程。
40.三维对象的三维表示包括但不限于:体积表示、点云、基于基元(primitive)的模型、网格。
41.三维表示也可以由沙漏预测器使用,尽管它们的数据格式在被神经网络使用之前可能需要一些预处理。三维机器学习在本领域可能是一个具有挑战性的问题,因为三维数据格式可能太大而无法高效处理,并且对于三维数据格式可能不存在常用的机器学习操作。
42.体积表示,其本质上是三维像素,可以被表示为矩阵格式,其中每个元素有三个维度——x、y和z坐标。点云是三维空间中点的集合,可以通过诸如pointnet的系统使用(qi,charles r.等人的“pointnet:deep learning on point sets for3dclassification and segmentation,”计算机视觉和模式识别(cvpr)论文集,ieee 1.2(2017):4)。基元也可以用作神经网络,例如,通过至少一个深度图像和包含关于基元配置信息的数字(zou,chuhang等人的“3d
‑
prnn:generating shape originals with recurrent neural networks,”2017年ieee计算机视觉国际会议(iccv),ieee,2017年。
43.网格是顶点、边和面的集合。顶点是表示表面的单个点,边是连接顶点的线,面是由顶点和边包围的连续区域。网格也可以用在神经网络中,或者以类似于点云的方式,或者通过下面讨论的过程。
44.实施例还包括一种方法,其中第一组训练输入数据、第二组训练输入数据、第三组输入数据、该组训练目标数据、第一组输出数据、第二组输出数据和/或第三组输出数据是对应的3d网格,对应于采样矩阵,其中采样矩阵是通过包括下述的方法生成的:
45.将初始三维网格变换为平面网格,初始三维网格包括第一组顶点和边,并且平面
网格包括第二组顶点和边,其中:
46.‑
第二组顶点中的每个顶点是来自第一组顶点的顶点的变换,并且包括来自第一组顶点的顶点的值,并且
47.‑
第二组边中的每个边是来自第一组边的边的变换并且包括来自第一组边的边的值;
48.对平面网格进行采样以生成多个样本,使得来自多个样本的每个样本包括:
49.‑
包括表示三维空间中的点的三个数值的三维坐标,其中三个数值直接从初始三维网格得出和/或获取,和
50.‑
包括表示样本相对于多个样本中的其他样本的位置的数值的坐标;和
51.基于多个样本生成采样矩阵;
52.将采样矩阵表示为对应的3d网格。
53.虽然三维网格是表示三维对象的流行方式,但它们很难直接用于许多机器学习算法。三维网格通常是不均匀的,具有不确定的特征,因此很难通过机器学习直接比较它们。对于三维网格,可能不存在常用的机器学习操作,例如卷积。此外,三维网格的计算机可读格式可能非常大,需要大量的处理能力来分析。
54.实施例在三维网格上使用沙漏预测器,通过与采样矩阵对应的3d网格。该方法将三维网格平坦化为二维网格,将它们表示为矩阵。此外,矩阵可以是表示不同对象的统一数据格式。
55.在各种实施例中,该方法在生成牙科、正畸和耳部相关对象时可能特别有用,如下文所讨论的。
56.尽管本公开中的一些实施例使用来自三维扫描的三维网格,但是可以使用可以嵌入平面中的任何三维网格。
57.初始三维网格可能来自开放表面或封闭表面。开放表面的示例包括但不限于:牙冠的外表面、牙齿到牙龈边缘的3d扫描、颌的3d扫描。封闭表面的示例包括但不限于:牙冠的整个表面、牙齿的三维模型、种植体引导件的3d扫描。
58.为了将初始三维网格平坦化为平面网格,应设置边界。在具有开放表面的三维对象的实施例中,该边界可以是开放表面的边界、沿表面形成的切口和/或两者的组合。
59.在具有零属封闭表面的三维对象的实施例中,边界可以是单个小面,或者沿着表面的至少一个切口。对于封闭曲面,可能会有明显的进行切割位置,例如顶部和底部之间的边缘。在牙齿的三维网格中,进行切割的位置包括但不限于:诸如牙龈边缘、牙齿长轴的解剖特征;几何特征,例如沿半球的平面;和/或与这些正交的任何轴。
60.切割三维网格可以产生多个平面网格。这对于捕获3d对象的更多细节可能有用。
61.然后将三维对象的表面边界固定到平面对象的边界。平面对象可以是不同的形状,包括但不限于:三角形、四边形、圆形、包括方圆的弯曲四边形、基于三维对象本身的形状。
62.一旦边界固定,其余的顶点和边就被映射到平面对象,从而将初始三维网格平坦化为平面网格。各种实施例可以使用不同的方法用于该映射。最初,可以创建每个顶点到其他顶点连接性的矩阵,并且求解矩阵系统将每个顶点的坐标映射到平面(tutte,william thomas的“how to draw a graph,”伦敦数学学会会刊3.1(1963):743
‑
767)。这种连接性可
以以不同的方式加权,从而产生不同的映射。在各种实施例中,这些方法包括但不限于:均匀权重(tutte,1963)、基于角度的权重(floater,michael s.和ming
‑
jun lai的“polygonal spline space and the numeric solution of the poisson equation,”siam数值分析杂志54.2(2016):797
‑
824)、基于余切的权重(meyer、mark等人的“discrete differential
‑
geometry operators for triangulated 2
‑
manifolds,”可视化和数学iii,springer,柏林,海德堡,2003年。35
‑
57)。
63.有关将初始3d扫描平坦化为平面网格的示例,请参见下文。
64.以这种方式平坦化初始3维网格允许初始3维网格和平面网格是双射的(bijective),这意味着每个顶点可以在两个网格之间来回映射。
65.然后对平面网格进行采样,其中每个样本是平面网格上的点。平面网格可以随机采样,也可以使用晶格采样,也可以是两者的结合。
66.晶格采样基于平面网格上的晶格进行采样。在各种实施例中,晶格可以基于极坐标或直角坐标,规则的或不规则的。规则晶格具有均匀间隔的线,例如正方形或三角形的规则网格。不规则晶格没有均匀间隔的线,并且在信息分布不均匀的情况下可能很有用。例如,边界设置在牙龈边缘的牙齿表面的平面网格在网格中心比边缘具有更多信息。因此,从中心收集更多样本的不规则晶格具有更多关于牙齿的有用信息。有关更多示例,请参见下文。
67.基于晶格的样本可以取自线的交叉点、沿线的不同位置或甚至取自晶格的单元。晶格采样可以与随机采样相结合,例如,从每个晶格单元中选择随机点。
68.平面网格上的每个样本具有基于初始三维网格的对应三维欧几里得坐标。如果样本在顶点上,则欧几里得坐标与顶点相同。如果样本位于边或面上,则基于边或面的顶点对欧几里得坐标进行内插。
69.每个样本还具有在晶格上的位置。该晶格可以是采样矩阵的基础,其中矩阵的每个元素是样本,并且每个元素的位置对应于样本的晶格位置。采样矩阵可以被认为是二维数组,每个数组具有三个维度的元素;三个二维数组,每个数组具有一个维度的元素;或者任何其他既能表达样本的欧几里得坐标又能表达晶格位置的格式。
70.采样矩阵可以在视觉上表示为二维红绿蓝矩阵(2d rgb矩阵)。在二维rgb矩阵中,每个矩阵元素的位置是样本的晶格位置,并且每个矩阵元素的rgb值是样本的欧氏坐标。2d rgb矩阵等同于采样矩阵,并且两者可以来回转换。
71.可以使用用于二维数据的机器学习方法来分析采样矩阵。与用于三维数据的类似方法相比,这要求较少的计算力。此外,还有更多关于二维机器学习方法的工作,可能允许以前无法应用于三维对象的新方法。
72.由于采样矩阵的每个元素相对于其相邻元素具有特定的位置,因此可以应用需要已知相邻元素的机器学习方法。例如,卷积池化几个相邻的元素,以更好地捕获有关对象的底层信息并降低改变整体结果机会变化风险。这些用于卷积神经网络。
73.采样矩阵还允许其他改进。采样矩阵可以表示具有较少数据点的对象,从其要求较少的处理力。此外,采样矩阵允许非均匀对象的统一数据格式,从而允许3d对象之间的直接比较。
74.本公开还包括将采样矩阵表示为对应的3d网格。由于采样矩阵的每个元素包括欧
几里得空间中的三维点,因此其也可以表示为点云。对采样矩阵进行的分析也将是对点云的分析,并且对采样矩阵的操纵将对点云产生对应的影响。
75.点云可以重新连接成三维网格。虽然点云可以以任何方式重新连接,但三角形网格对于计算机辅助设计和制造是典型的。
76.实施例还包括其中第三组输出数据用于估计未扫描和/或错误扫描区域的情况。
77.沙漏预测器可用于估计未扫描和/或错误扫描的区域。通常,由于位置、阻挡对象或对象本身的形状,取得对象的完整扫描是很困难的。在这种情况下,具有与扫描相匹配的3d模型网格允许不管怎样对底层对象进行建模,如下所述。
78.在估计未扫描和/或错误扫描区域的实施例中,为了训练自动编码器,第一组训练输入数据可以是模型对象的三维网格。为了训练沙漏预测器,第二组训练输入数据可以使用相似类型对象的不完整和/或错误扫描,并且该组训练目标数据可以是对应于相似类型的对象的不完整和/或错误扫描的3d网格。因此,第三组输出数据可以是拟合到不完整和/或错误扫描的模型对象的三维网格。下面讨论牙科示例。
79.实施例还包括一种估计未扫描和/或错误扫描区域的方法,其中未扫描和/或错误扫描区域是牙齿区域或耳部区域。
80.在牙科扫描中,可以对患者的牙齿和下颌进行扫描,例如,通过对患者使用口腔内扫描仪,或通过扫描患者口腔状况的石膏模型。但是,个别牙齿的某些区域可能无法完全扫描,包括但不限于:邻间区域,其中相邻牙齿阻挡扫描仪;支架和其他器具下方的区域,其中器具阻挡扫描仪;龈下区域,其中牙龈阻挡扫描仪。对于面部扫描,牙齿区域包括面部特征后面的区域,其中嘴唇可能会阻挡扫描仪。在这些情况下,使用已知的牙齿或库模型作为初始模型,可以借助沙漏预测器估计不完整区域。
81.例如,对于切牙的不完整扫描,可以用沙漏预测器估计至少一个未扫描和/或错误扫描区域。在训练自动编码器时,第一组训练输入数据可以是完整切牙的一组3d表示,可能取自完整切牙的扫描或数字模型。完整切牙的3d表示也可以通过自动编码器的潜变量进行参数化。
82.在训练沙漏预测器时,第二组输入数据可以是切牙的不完整和/或错误扫描的一组3d表示。该第二组输入训练数据的训练目标数据组将是完整切牙的对应3d表示组。可以人为地创建训练数据组,例如,通过切除在一般扫描中不被扫描的切牙表面的部分。
83.在这个训练数据组上训练沙漏预测器会产生这样的沙漏预测器,该预测器基于切牙的不完整和/或错误扫描的3d表示的输入输出完整切牙的3d表示估计。
84.可以直接使用来自沙漏预测器的第三组输出数据,或者可以将其中的一些部分与现有扫描拼接在一起。
85.未扫描和/或错误扫描区域的估计可用于模拟正畸治疗。正畸治疗可能会移动或旋转牙齿,并且最终结果中可见的牙齿表面最初可能无法扫描。所需的表面包括但不限于:邻间区域、龈下区域、牙根和/或上述组合的任何部分。因此,牙齿的未扫描和/或错误扫描区域的估计可用于模拟治疗。
86.实施例还包括估计至少一个未扫描和/或错误扫描的耳部区域。耳部区域包括但不限于:第一弯曲、第二弯曲、前切迹、对耳轮、对耳屏、外耳、耳道、包括孔的耳道、螺旋、耳屏间切迹和/或耳屏。
87.扫描耳部可能很困难。耳道的大小和曲率限制了扫描仪的大小和范围。耳部的某些部分可能被毛发、耵聍和/或耳部的其他部分阻挡。耳部不是刚性的,因此扫描仪或其他对象可能会使耳部变形并影响扫描。因此,对耳部的未扫描和/或错误扫描区域进行估计以对耳部扫描应当是什么进行建模是有帮助的,即使原始扫描不完整或有其他错误。
88.用于估计耳部扫描的沙漏预测器,为了训练自动编码器,可以使用完整的耳部扫描作为第一组输入数据。为了训练沙漏预测器,第二组输入训练数据可以是不完整和/或错误的耳部扫描,并且训练目标数据组可以是对应的完整耳部扫描。这些完整的耳部扫描可以来自耳部管型的实验室扫描或一组良好的扫描。该过程将类似于上述用于估计切牙的沙漏预测器。
89.实施例还包括使用沙漏预测器来使用第三组输出数据、其任何部分和/或其组合中的至少一个设计牙齿修复体、正畸器具或耳部相关装置。
90.牙科修复体包括以下中的一个或多个:牙桥、假牙、牙冠、种植体、种植体引导件、内嵌体、上嵌体、桩和核和/或贴面。正畸器具包括以下中的一个或多个:托槽导向器、透明矫正器、扩张器、舌线和/或四螺旋。耳部相关装置包括以下中的一个或多个:配戴的助听器、入耳式监听器和/或噪音保护装置。
91.通过改变训练数据,可以生成不同类型的对象。例如,在生成牙冠的实施例中,第一组训练输入数据可以是作为贴面模型的多个牙冠和/或牙齿,第二组训练输入数据可以是牙冠的多个周围环境,并且该组训练目标数据可以是对应于这些周围环境的牙冠。下面讨论使用沙漏预测器生成冠的详细示例。
92.实施例还包括使用沙漏预测器来识别三维扫描中的不可移动对象,从而允许将可移动对象从三维扫描中排除。
93.当扫描不可移动对象以获得不可移动对象的虚拟3d模型时,可在子扫描中捕获可移动对象。例如,在使用牙科扫描仪扫描牙科患者的口腔状况时,可能包括诸如患者的脸颊、舌头或牙科专业人员的器械或手指的可移动对象。
94.目标是通过区分可移动对象的表面和不可移动对象的表面,在生成虚拟3d模型时仅使用来自不可移动对象的表面。
95.用于估计不可移动对象的沙漏预测器可以使用已知不可移动对象的扫描作为第一组输入数据来训练自动编码器。为了训练沙漏预测器,第二组输入训练数据可以是连同可移动对象的不可移动对象的扫描,并且该组训练目标数据可以是不可移动对象的对应扫描。不可移动对象的对应扫描可以是例如牙科患者的颌和牙列的扫描,并且连同可移动对象的不可移动对象的扫描可以是包括有可移动对象(如舌头、手指、棉球等)的牙科患者的颌和牙列的对应扫描。该过程将类似于上述用于估计切牙的沙漏预测器。
96.在一些实施例中,不可移动对象是患者的口腔状况。可移动对象包括但不限于:患者口腔的部分的软组织,例如脸颊内侧、舌头、嘴唇、牙龈和/或松动的牙龈;暂时存在于患者口腔中的牙科器械或补救措施,例如牙科抽吸装置、棉卷和/或棉垫;手指,例如牙科专业人员的手指。
97.实施例还包括使用沙漏预测器来识别对象、对象类别。
98.如上所述,沙漏预测器的潜变量可以是一种类型的对象的参数化。因此,来自编码对象的潜变量可能是足够独特的以将该对象与其他相同类型的对象区分开来。
99.在实施例中,沙漏预测器可用于基于不完整和/或错误扫描来识别牙齿的类别。为了训练自动编码器,第一组输入训练数据可能是完整牙齿的3d表示。为了训练沙漏预测器,第二组输入训练数据可以是牙齿的不完整和/或错误扫描的3d表示,并且该组训练目标数据可以是完整牙齿的对应3d表示的3d表示。
100.然后可以通过第一编码器运行具有牙齿类型(切牙、二尖牙、臼齿、前臼齿等)标签的完整牙齿的一组3d表示。潜变量被保留并用标签注释。基于潜变量的值、范围和/或其他特性,可以划分类别。当使用第二编码器将新的不完整和/或错误扫描编码为潜变量时,可以将这些潜变量与类别进行比较,并识别牙齿的类型。
101.在实施例中,这也可以用于识别相似的对象,例如,在用于牙科护理的患者监测系统中来自同一牙科患者的先前扫描中。为此将只需要自动编码器。第一组训练输入数据可以是一组颌和牙列扫描。将训练第一编码器将这些编码为第一组潜变量。新的输入数据,例如颌和牙列的新扫描,然后可以由第一编码器编码成一组潜变量。潜变量可以足够独特以基于对颌和牙列的新扫描来识别类似的扫描,尤其是与颌和牙列的现有扫描的多个潜变量相比。颌和牙列的现有扫描的多个潜变量可以基于牙科诊所或实验室的一组现有记录。
102.还公开了一种用于变换对象的计算机实现的方法,包括:
103.在一组训练输入数据上训练自动编码器以识别潜变量并生成一组训练输出数据,其中自动编码器包括编码器和解码器,其中编码器将训练输入数据转换为潜变量,其中解码器将潜变量转换为训练输出数据,其中训练输出数据至少与训练输入数据基本相同;
104.识别具有至少一个数据对的变换向量,其中至少一个数据对中的每一个包括处于初始状态的初始对象和处于变换状态的变换对象,通过:通过使用每个初始对象的表示作为编码器的输入数据,生成每个初始对象的初始状态潜变量;通过使用每个变换对象的表示作为编码器的输入数据,生成每个变换对象的变换状态潜变量;
105.基于初始状态潜变量和变换状态潜变量之间的差识别变换函数;和
106.使用变换函数变换新对象,通过:通过使用新对象的表示作为编码器的输入数据生成新的潜变量;通过将变换向量和/或基于变换向量的函数应用于新的潜变量来生成变换的新的潜变量;通过使用解码器解码变换的新潜变量来生成变换的输出数据。
107.在实施例中,可以通过生成潜变量的变换向量来将对象变换为自身的修改版本。通过从初始对象和变换对象的数据对生成变换函数,可以以类似方式变换新对象。这可用于例如预测牙齿的老化,如下所述。牙齿将以从原始牙齿和老化牙齿的数据对得出的变换函数“老化”。此外,实施例可以使用向量作为变换函数,允许变换函数充当“滑块(slider)”来以不同的间隔老化牙齿,允许延时查看牙齿随着老化会是什么样子。
108.实现此的实施例首先训练自动编码器以识别潜变量。可以通过将训练输入数据编码为潜变量,将潜变量解码为训练输出数据,并相应地调整编码器和解码器的权重使得训练输出数据至少与训练输入数据基本相同来训练自动编码器。上面更详细地讨论了该过程。
109.训练自动编码器后,至少使用一个数据对作为编码器的输入数据。数据对包括处于初始状态的初始对象和处于变换状态的变换对象。数据对的示例包括:初始牙齿和老化牙齿、初始牙齿和具有凸起牙尖的牙齿、初始牙齿和具有增加的角对称性的牙齿。
110.初始对象和变换对象可能需要转换为可用作编码器输入数据的表示。例如,如果
初始对象是牙齿,则可能需要将其转换为3d网格,并且在编码之前将3d网格转换为数值矩阵。上面讨论了这样的表示的示例。
111.接下来,可以通过比较从初始对象和变换对象生成的潜变量来识别变换函数。初始状态潜变量可以通过将初始对象的表示输入到编码器中来生成。可以通过将转换对象的表示输入到编码器中来生成变换状态潜变量。生成变换函数,将初始状态潜变量转换为变换状态潜变量。
112.变换函数可以是例如基于数据对的潜变量之间的平均变化的向量。向量可以体现为与潜变量数量相同长度的数列表。向量衡量每个初始状态潜变量与变换状态潜变量中对应的潜变量之间的差。在存在多于一个数据对的情况下,可以为每个潜变量取这些距离的平均值,其中平均值构成向量。然后可以将该向量添加到一组新的潜变量中,从而产生变换的新潜变量。下面讨论这种向量的实施例。
113.变换函数也可以例如是将初始状态潜变量转换为变换状态潜变量的线性或多项式函数。示例包括,其中x表示初始状态潜变量,f(x)表示变换状态潜变量,c表示某个常数,并且m表示斜率:
114.f(x)=mx+c
115.f(x)=mx
c
116.一旦识别了变换函数,就可以使用它来变换新对象。新对象的表示用作编码器的输入数据并被编码为新的潜变量。新的潜变量然后由变换函数进行变换,并且变换的新潜变量通过解码器运行。解码器然后输出变换的新输出数据,该数据可以被转换为变换的新对象。
117.实施例还包括其中变换函数是向量,并且改变向量控制变换的程度。
118.如上所述,向量可以是数列表。因此,向量可以具有对其执行的简单操作,从而改变值。例如,如果向量被减半,然后应用于初始状态潜变量,则导致的变换的新对象将仅部分被变换。如果向量被加倍,则导致的变换的新对象将被变换到超出原始。下面讨论了这被用于使牙齿老化的实施例。
119.实施例还包括其中初始对象是原始牙齿并且变换的对象是原始牙齿的老化版本。
120.在实施例中,变换函数可用于使牙齿老化。牙齿和牙科对象会随着时间的推移而磨损。预测它们如何老化可以有助于从一开始就设计出更好的牙科装置。例如,牙冠通常预计可以使用10到30年。在设计牙冠时,预测牙冠和相邻牙齿随时间如何变化可能很有用。
121.在实施例中,初始对象可以是原始牙齿并且变换对象可以是原始牙齿的老化版本。一个/多个原始牙齿的表示被用作编码器中的输入数据,生成表示一个/多个原始牙齿的初始状态潜变量。此外,一个/多个老化牙齿的表示被用作编码器中的输入数据,生成变换状态潜变量。
122.然后可以通过比较变换状态潜变量和初始状态潜变量之间的差来识别变换函数。如上所述,这可以是向量、线性函数和/或多项式函数。
123.现在可以使用自动编码器和变换函数对新对象(例如另一牙齿)进行老化。这里,新牙齿或牙冠的表示将用作编码器中的输入数据,编码为一组潜变量,由变换函数变换,然后解码回到输出数据中,可以使用该输出数据生成数字或物理对象。
124.在变换函数是向量的实施例中,该向量可以用作控制老化量的“滑块”。如果每个
数据对由原始牙齿和原始牙齿的老化版本组成,并且原始牙齿被认为是在0年,而老化牙齿在20年,则可以考虑基于平均差的向量使牙齿老化20年。一半值的向量会使牙齿老化10年;值两倍的向量会使牙齿老化40年;依此类推,这假设向量与老化之间存在线性关系。也可以识别非线性关系。
125.实施例还包括其中初始状态是原始牙齿的初始状态并且变换状态是与原始牙齿相比具有增加的角对称性的牙齿。
126.在实施例中,对象为牙齿,牙齿的初始状态为原始牙齿,并且变换状态为角对称性增加的牙齿。增加角对称性使牙齿更圆,主要凸起不那么突出。这使牙齿能够更好地贴合邻牙并优化咀嚼。
127.像这样的特性通常难以量化;虽然直圆柱体的角对称性容易计算,但生成的牙齿需要逼真且像牙齿。这保留了使对象像牙齿的特征(例如隆起和裂缝),同时在功能上允许控制牙齿的圆度。此外,无需仔细计算旋转角度和表面变化即可完成此;使用的数据对提供了一系列示例,并且变换函数捕获了自动编码器对变化的了解内容。
128.实施例还包括输出到数据格式,该数据格式被配置为从第三组输出数据、其任何部分和/或前述的任何组合中的至少一个制造物理对象。
129.一旦生成对象的对应3d网格或变换的3d网格,就可以将网格或其一部分转换为适合进行制造的数据格式。在各种实施例中,生成的3d网格可以是3d对象的标准文件类型,包括但不限于:协作设计活动(collada)、初始图形交换规范(iges)、iso 10303(step)、stl、虚拟现实建模语言(vrml)。
130.实施例还包括通过3d打印或铣削从对应的3d网格、变换的网格、3d模型网格、前述网格的任何部分和/或前述的任何组合生成物理对象。
131.本发明中描述的方法旨在应用于物理世界。铣削和3d打印是将3d网格或3d文件格式转变为物理对象的方法。铣削在牙科中很常见,因为它允许使用经久耐用、经过良好测试的材料。牙科铣床雕刻出可能需要后处理(例如固化)的3d对象。3d打印是另一种生成物理对象的方法,并且正在迅速改进。与传统铣削相比,它可以使定制对象的制造浪费更少。
132.在本公开中,术语数据格式已被用作数学和计算机科学中常用的术语,作为用于存储相关数据的格式类型。数据格式的示例包括:标量、向量、标量数向量、矩阵、字符、字符串等。
附图说明
133.本发明的上述、附加目的和/或特征将通过以下对本发明实施例的说明性和非限制性详细描述,参考附图进一步描述,其中:
134.图1示出了根据本公开实施例的系统的示意图;
135.图2示出了根据实施例的创建沙漏预测器的方法;
136.图3示出了根据实施例的合适的卷积神经网络的示例架构;
137.图4示出了根据实施例生成牙冠的沙漏预测器;
138.图5示出了根据实施例的沙漏预测器基于治疗前数字2d图像生成期望牙科设置的提出的数字2d图像;
139.图6a
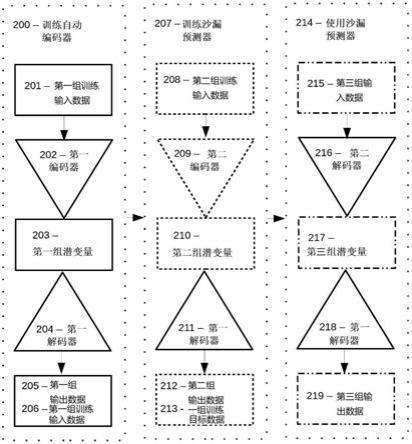
‑
6e示出了各种实施例中3d对象的可能表示;
140.图6a示出了在实施例中的臼齿的深度图;
141.图6b示出了在实施例中的臼齿的伪图像;
142.图6c示出了在实施例中臼齿的体素表示;
143.图6d示出了在实施例中臼齿表面的点云表示;
144.图6e示出了在实施例中臼齿表面的网格表示;
145.图7示出了根据实施例的从扫描或数字对象生成对应的3d网格的方法;
146.图8a
‑
8c示出了根据实施例的2d rgb矩阵、采样矩阵和对应的3d网格之间的对应关系;
147.图8a分别示出了根据实施例的红色、绿色和蓝色矩阵的灰度图像;
148.图8b示出了根据实施例的采样矩阵的子组;
149.图8c示出了根据实施例的与图8b中的采样矩阵和图8a中的图像对应的3d网格;
150.图9示出了使用变换函数变换对象的方法的实施例;
151.图10示出了基于向量的变换函数的简单示例;
152.图11示出了使用向量作为变换函数来老化牙齿的实施例;
153.图12示出了其中牙冠舌侧的角对称性以变换函数增加实施例;
154.图12a示出了原始牙冠;和
155.图12b示出了变换牙冠。
具体实施方式
156.在下面的描述中,参考了附图,这些附图通过说明的方式示出了可以如何实践本发明。
157.尽管已经详细描述和示出了一些实施例,但本发明不限于它们,而是还可以在所附权利要求限定的主题的范围内以其他方式实施。特别地,应当理解,在不脱离本发明的范围的情况下,可以利用其他实施例并且可以进行结构和功能修改。
158.在列举若干装置的设备权利要求中,这些装置中的若干可以由一个且相同的硬件项目来体现。某些措施在相互不同的从属权利要求中陈述或在不同实施例中描述的简单事实并不表示不能使用这些措施的组合。
159.权利要求可以指任何前述权利要求,并且“任何”被理解为表示前述权利要求中的“任何一个或多个”。
160.本说明书中使用的术语“获得”可以指使用医学成像设备物理地获取例如医学图像,但它也可以指例如将先前获取的图像或数字表示加载到计算机中。
161.应当强调的是,在本说明书中使用的术语“包括/包含”用于指定所述特征、整数、步骤或部件的存在,但不排除一个或多个其他特征、整数、步骤、部件或其群组的存在或添加。
162.上面和下面描述的方法的特征可以在软件中实现并且在数据处理系统或由计算机可执行指令的执行引起的其他处理装置上执行。指令可以是从存储介质或经由计算机网络从另一计算机加载到诸如ram的存储器中的程序代码装置。替代地,所描述的特征可以由硬连线电路代替软件或与软件结合来实现。
163.图1示出了根据本公开的实施例的系统的示意图。系统100包括计算机设备102,该
计算机设备102包括计算机可读介质104和微处理器103。该系统还包括视觉显示单元107、用于输入数据和激活在视觉显示单元107上可视化的虚拟按钮的输入单元例如计算机键盘105和计算机鼠标106。视觉显示单元107可以例如是计算机屏幕。
164.计算机设备102能够从例如cbct扫描仪101b获得例如包括颌骨的患者的颌的至少一部分的数字表示。获得的数字表示可以存储在计算机可读介质104中并提供给处理器103。
165.附加地或替代地,计算机设备102还能够从图像获取设备101a,例如3d扫描设备,例如由3shape trios a/s制造的trios口腔内扫描仪,接收例如患者牙齿组和牙龈的表面的数字3d表示,或能够从此类3d扫描设备接收扫描数据并基于此类扫描数据形成患者牙齿组和/或牙龈的数字3d表示。接收或形成的数字3d表示可以存储在计算机可读介质104中并提供给微处理器103。
166.系统100被配置为允许操作者使用从骨扫描和/或表面扫描获得的信息设计定制的牙齿修复体,其中基于预定设计标准设置限制。这可以例如通过在视觉显示单元107上显示患者颌的数字表示来实现,然后操作者可以在视觉显示单元上关于患者骨的表面可视化他/她的修复设计。
167.该系统包括单元108,用于将数字设计作为输出数据传输到制造机器以生成牙科器具,例如定制的牙科修复体;到例如计算机辅助制造(cam)设备109,用于制造定制的牙齿修复体;或到另一个计算机系统,其例如位于制造定制的牙科修复体的铣削或打印中心。用于传输的单元可以是有线或无线连接,并且可以例如使用互联网或文件传输协议(ftp)来进行传输。
168.使用3d扫描设备101a对患者牙齿组和/或牙龈的3d扫描和/或使用cbct扫描仪101b的骨扫描可以在牙医处执行,而定制牙齿修复体的设计可以在牙科实验室执行。在这种情况下,可以通过牙医和牙科实验室之间的互联网连接提供患者牙齿组的数字3d表示和/或从cbct扫描仪和/或扫描设备获取的患者颌的3d表示。
169.如图所示的系统100是说明性示例。例如,计算机设备102可以包括一个以上的微处理器103和/或一个以上的计算机可读介质104,视觉显示单元107可以集成在计算机设备102中或与计算机设备102分开等。
170.图2示出了根据实施例的创建沙漏预测器的方法。沙漏预测器基于不同但相关的数据预测对象应当是什么。
171.第一步骤是200,训练自动编码器。在一个实施例中,第一组输入训练数据201是采样矩阵。第一编码器202将第一组输入训练数据201编码为第一组潜变量203。在一个实施例中,第一编码器202是神经网络,例如卷积神经网络或密集神经网络。
172.在一个实施例中,第一组潜变量203可以具有例如3
‑
50个潜变量,尽管可以有更多或更少的潜变量。潜变量可以充当牙齿本身的参数化,既用于体现对象,也用于转换对象。在一个实施例中,潜变量是标量数。
173.在一个实施例中,第一解码器204为神经网络,包括但不限于:卷积神经网络、密集神经网络。第一解码器204将第一组潜变量203解码为第一组输出数据205。第一组输出数据205具有与第一组训练输入数据201相同的数据格式。在一个实施例中,201和205都是采样矩阵。
174.在目标数据上训练神经网络,输出数据和目标数据之间的相似性决定了分配给神经元的权重。测量目标数据和输出数据之间的匹配在上面的发明内容中进行了讨论。在自动编码器中,训练目标数据是输入数据本身。因此,第一组输出数据205的目标数据是第一组训练输入数据206。一旦第一组输出数据205至少基本匹配目标数据,即第一组训练输入数据201/206,自动编码器就经训练。用于确定基本匹配的具体措施取决于沙漏预测器的用途,但图4中给出了示例。
175.第二步骤是207,训练沙漏预测器。第二组输入数据208具有与第一组输入数据不同的底层对象。然而,在由第一组输入数据和第二组输入数据表示的对象之间应当存在底层连接,使得每个对象提供关于另一个对象的一些信息。例如,针对一组牙周围环境设计的牙冠提供了一些关于邻牙和对牙的位置的信息,而一组牙冠的牙周围环境提供了一些关于牙冠可能大小和形状的信息。
176.第二组输入数据208的数据格式也可以不同于第一组输入数据201。底层对象的示例在图4中。
177.第二编码器209将第二组输入训练数据208编码为第二组潜变量210。在一个实施例中,第二编码器209是神经网络,例如卷积神经网络或密集神经网络。第二组潜变量210必须具有与第一组潜变量203相同的数据格式,包括具有相同数量的潜变量和相同的数据类型。但是,由于它们来自不同的数据组,因此它们将具有潜变量的不同值。
178.第一解码器211与第一步骤的第一解码器204相同,并且将第二组潜变量210解码为第二组输出数据212。因为这里使用第一解码器204/211,所以第二组输出数据212与第一组输出数据具有相同类型的底层对象和相同的数据格式。
179.目标训练数据组通常与第一组训练输入数据具有相同类型的底层对象。训练数据组中表示的底层对象通常足够相似,可以通过相同的潜变量组对它们进行参数化,尽管它们不必完全相同。例如,牙冠的外表面和牙齿的部分表面可能足够相似以被相同的潜变量组参数化,但不是相同的底层对象。
180.在训练沙漏预测器时,目标训练数据组的每个元素与第二组训练输入数据中的元素相匹配。第二组输出数据212至少与训练目标数据213基本匹配,并且第二编码器可以相应地被加权。一旦第二组输出数据212至少基本匹配训练目标数据213,沙漏预测器就经训练。如上所述,此匹配的确切度量取决于沙漏预测器用于的应用。
181.第三步骤是214,使用沙漏预测器。第三组输入数据215和第二组输入数据208具有相同类型的底层对象和相同的数据格式。第二编码器216与第二步骤的第二编码器209相同,并将第三组输入数据215编码为第三组潜变量217。
182.第三组潜变量217具有与第一和第二组潜变量203和210相同的数据格式。
183.第一解码器218与第一步骤和第二步骤的第一解码器204和211相同,并将第三组潜变量217解码为第三组输出数据219。因为这里使用第一解码器204/211,所以第三组输出数据219与第一组和第二组输出数据205和212具有相同类型的底层对象和相同的数据格式。
184.第三组输出数据219是基于第三组输入数据215对底层对象应当是什么的预测。
185.图3示出了根据实施例的合适的卷积神经网络的示例架构。该特定卷积神经网络可以用作编码器。图3基于张量流图,通常用于绘制神经网络图。
186.输入数据301由卷积节点302处理。在本实施例中,输入数据可以是各种牙冠和/或牙齿的采样矩阵。
187.卷积节点302可以由一系列步骤组成,例如:卷积303、偏置相加304、整流线性单元305。
188.卷积303将输入数据301与内核303a卷积。内核303a是一系列滤波器。内核303a是通过反向传播改变的可学习参数。滤波器可以是至少2x2的任何大小,但优选地大小为4x 4。存在至少一个滤波器,但优选地范围为16到512,并且对于该第一卷积,更优选地为64。滤波器可以被随机初始化。卷积303使用的步幅至少为1,但优选至少为2。
189.卷积303输出输入数据301的滤波器激活,然后将其输入到biasadd操作304。
190.biasadd操作304获取卷积303的输出并将偏置304a添加到每个元素。偏置1006是一组标量数。偏置304a是通过反向传播改变的可学习参数。偏置304a可随机初始化或可在全零处初始化。biasadd操作304对于卷积节点是可选的,但可以有助于优化预测结果,这取决于实施例。
191.然后将卷积303的输出或biasadd操作304的输出输入到整流线性单元(relu)305。relu 305是激活函数,如果输入为负则其将输入设置为零,否则不改变输入。整流线性单元是流行的激活函数,但也可以使用其他激活函数,包括但不限于:sigmoid函数、双曲正切。
192.relu 305的输出是一组滤波器激活矩阵,然后可以将其输入到另一个卷积节点中。卷积节点306是一系列与卷积节点302格式相同的卷积节点,尽管它们的滤波器大小、滤波器数量、滤波器初始化、步幅大小、偏置和激活函数可能不同。尽管卷积节点302对于网络的实施例可能就足够,但是更多的卷积节点是优选的。因此,卷积节点306可以是1
‑
24个卷积节点,优选地4个卷积节点。
193.reshape(整形)307获取卷积节点306的最终卷积节点的输出,并用形状307a改变格式。在该实施例中,形状307a将每个滤波器激活矩阵从输出平坦化为标量数向量。在这个实施例中,平坦化是必要的,因为下一步骤是需要向量的密集节点。然而,其他实施例可以使用不同的形状,这取决于下一步骤需要什么输入数据格式。
194.reshape 307的输出向量然后被输入到两个密集节点,密集节点a 308和密集节点b 311。这里,使用两个密集节点,因为变分自动编码器可能需要均值和标准偏差或对数方差两者。然而,其他实施例可以仅使用一个密集节点或多于两个密集节点来直接输出潜变量。
195.密集节点a 308可以由一系列步骤组成,例如:矩阵乘法309、偏置相加(bias add)操作310。密集节点a 308可以输出标准偏差或方差的对数。
196.矩阵乘法309将其输入数据乘以内核309a。内核309a是权重矩阵,可以被随机初始化。内核309a是通过反向传播改变的可学习参数。
197.矩阵乘法309的输出然后被输入到偏置加法操作310。偏置加法操作310将偏置310a添加到输入的每个元素。偏差310a是一组标量数和通过反向传播改变的可学习参数,并且可以被随机初始化或可以在全零处初始化。
198.密集节点b 311具有与密集节点a 308类似的格式,并且可以输出均值。
199.对密集节点308和311的输出进行采样以生成潜变量312。虽然本发明的这个实施例使用两个密集节点,但也可以使用单个密集节点来直接生成潜变量312。
200.然后将这些潜变量馈入解码器中,未图示,该解码器可以是类似的神经网络,但具有去卷积而不是卷积。整个编码器
‑
解码器结构被训练,将不同的权重反向传播到整个结构中的各种可学习参数。
201.图4示出了根据实施例的生成牙冠的沙漏预测器。在该实施例中,沙漏预测器被训练以预测给定牙周围环境的牙冠的外表面。外表面可以连接到适合进一步制造和/或预备的底表面的网格。对于图4,对于对象402、408、409、419、420、429和430,术语“牙冠”可用作牙冠的外表面的简写。
202.第一步骤400训练自动编码器参数化/输出牙冠。对于本实施例的方法,自动编码器为我们提供了一组潜变量来参数化牙冠,以及解码器来将潜变量解码回牙冠。在该实施例中,自动编码器可以是变分自动编码器,其使用概率分布来生成潜变量而不是直接生成它们(goodfellow,ian等人的deep learning,第一卷,剑桥:mit出版社,2016,第12章)。实施例也可以是普通的自动编码器,其直接生成潜变量。使用概率分布的变分自动编码器可以在数据稀疏的情况下进行更好的推断。
203.牙齿401是由输入训练数据402、目标训练数据409和输出数据408表示的底层对象类型的一个示例。根据图7中描述的方法将多个牙齿和/或牙冠处理成采样矩阵。
204.多个牙冠和/或牙齿402的采样矩阵是第一组输入训练数据。由于沙漏预测器在这里仅用于生成牙冠的外表面,因此牙冠和实际牙齿都可以用作训练数据。多个牙冠402的采样矩阵可以基于物理牙冠和/或牙齿的扫描或表示牙冠和/或牙齿的数字对象。
205.卷积神经网络a(403)将多个牙冠402的采样矩阵编码为均值向量404和标准偏差向量405。向量405也可以是方差对数的向量。然后对均值向量404和标准偏差向量405进行采样以估计潜变量,即牙冠和/或牙齿参数化406。图3中进一步详述了该卷积神经网络的示例。
206.潜变量,即牙冠和/或牙齿参数化406可以参数化牙齿,并且可以解码回采样矩阵,具有该牙齿的对应3d网格。这些潜变量的数据格式是一组标量数。可能有3
‑
50个标量数,但组员的总数应当对于给定沙漏预测器保持一致。
207.潜变量是牙齿的参数化,并允许牙齿的形状由一组标量数表示。这些数不容易被人类感知解释,但确实包含机器学习方法发现的牙齿形状信息。此外,这些数可以转换回底层牙齿的对应3d网格。
208.作为参数化,潜变量也可用于改变牙齿。改变潜变量的值会相应改变牙齿的对应3d网格的形状。这允许精确量化变化。
209.卷积神经网络b(407)将潜变量,即牙冠和/或牙齿参数化406解码为牙冠/牙齿的自动编码矩阵408。牙冠/牙齿的自动编码矩阵408是图2中第一组输出数据205的实施例。
210.卷积神经网络基于将输出数据与目标数据进行比较,使用反向传播进行训练。自动编码器是一种特殊的布置,其中输入数据本身就是目标数据。因此,卷积神经网络b(407)的输出数据,即牙冠/牙齿408的自动编码矩阵,基于其与牙冠/牙齿403/409的采样矩阵的相似性进行评估。
211.第二步骤410训练沙漏预测器以基于其周围环境创建牙冠。这一步为我们提供了编码器,以将一组不同但相关的输入数据编码为潜变量。然后可以将潜变量解码回自动编码器的底层对象。在本实施例中,输入数据是牙冠的周围环境的表示,并且输出数据是牙冠
的表示。
212.匹配的牙冠和周围环境411和412是沙漏预测器的训练数据组的底层对象的示例。周围环境412是牙冠或牙冠预备物周围的对象的集合,包括但不限于:邻牙、对牙、牙龈、颌和/或预备物。牙冠411是例如由牙科技师针对周围环境412设计的现有牙冠。
213.周围环境412是输入训练数据413的底层对象,而牙冠411是输出数据419和目标训练数据420的底层对象。按照图7中描述的方法将这些中的多个处理成采样矩阵。
214.匹配的牙周围环境413的采样矩阵是第二组输入训练数据。匹配的牙周围环境的采样矩阵413基于牙周围环境,如412(关于从三维对象获得采样矩阵的方法,请参见图7)。
215.卷积神经网络c(414)将匹配的牙周围环境413的采样矩阵编码为均值向量415和标准偏差向量416。然后对均值向量415和标准偏差向量416进行采样以估计潜变量,即匹配的牙冠/牙齿参数化417。图3中进一步详细说明了卷积神经网络的示例。
216.潜变量,即匹配的牙冠参数化417,具有与来自第一步骤406的潜变量相同的数据格式,并且表示相同的底层对象。
217.卷积神经网络b(418)将潜变量,即匹配的牙冠参数化417,解码为匹配的牙冠419的矩阵。卷积神经网络b(418)与第一步骤(407)中的卷积神经网络b相同。使用卷积神经网络b(407/418)作为两个步骤的解码器意味着潜变量被解码为相同类型的对象,这里是牙冠的外表面。
218.匹配的牙冠419的矩阵等同于图2中的第二组输出数据212。与目标训练数据组,即匹配的牙冠420的采样矩阵相比较来评估该输出数据。
219.匹配牙冠420的每个采样矩阵对应于来自413的匹配牙周围环境的采样矩阵。解码器,即卷积神经网络b(407/418)没有改变,这意味着给定的一组潜变量总是返回相同的输出。因此,在步骤410中仅训练编码器,即卷积神经网络c(414)。
220.总之,步骤410训练卷积神经网络c(414)以返回将解码为与给定周围环境匹配的牙冠的潜变量(417)。
221.第三步骤421针对新环境预测牙冠。在前一步中训练的沙漏预测器用于一组新的牙周围环境以生成牙冠。生成的牙冠是基于来自前一步的训练数据的预测,并且可以被认为是牙科专业人士在给定环境的情况下会设计的牙冠。
222.新周围环境422是沙漏预测器的输入数据的底层对象的示例。这是与匹配的周围环境412相同类型的底层对象。新周围环境422按照图7中的方法被处理成采样矩阵423。采样矩阵423等同于图2中的第三组输入数据215。
223.卷积神经网络c(424)将新牙周围环境423的采样矩阵编码为均值向量425和标准偏差向量426。然后对均值向量425和标准偏差向量426进行采样以估计潜变量,即匹配的牙冠/牙齿参数化427。卷积神经网络c(424)与步骤410中的卷积神经网络c(414)相同。
224.潜变量,即新牙冠参数化427,与来自第一步骤(406)和第二步骤(416)的潜变量具有相同的数据格式,并且表示相同的底层对象。
225.卷积神经网络b(428)将潜变量,即新牙冠参数化427解码为牙冠预测的采样矩阵429。卷积神经网络b(428)与来自第一步骤和第二步骤(407/418)的卷积神经网络b相同。
226.牙冠预测429的矩阵等同于图2中的第三组输出数据219。注意步骤421中没有训练,所以没有目标数据,也没有反向传播。
227.现在可以使用牙冠预测429的矩阵来生成物理牙冠430。牙冠预测429的矩阵被重新连接成网格,并且该网格被连接到适合进行进一步制造和/或制备的底表面的网格。如有必要,将网格转换为配置为制造物理对象的数据格式,然后将其用于铣削、3d打印或以其他方式制造物理牙冠430。
228.物理牙冠430可以放置在新周围环境422中,产生具有牙冠431的新环境。
229.图5示出了根据实施例的基于治疗前数字2d图像生成期望牙科设置的提出的数字2d图像的沙漏预测器。在该实施例中,沙漏预测器被训练以在给定治疗前数字2d图像的情况下预测提出的数字2d图像。
230.第一步骤500训练自动编码器以参数化/输出提出的数字2d图像。对于本实施例的方法,自动编码器为我们提供一组潜变量以参数化提出的数字2d图像以及解码器以将潜变量解码回提出的数字2d图像。在该实施例中,自动编码器可以是变分自动编码器,如上所述。
231.期望牙齿设置501是由输入训练数据502、目标训练数据509和输出数据508表示的底层对象类型的一个示例。上面讨论了潜在的期望牙齿设置。
232.第一组输入训练数据是期望牙齿设置502的一组提出的数字2d图像。由于提出的数字2d图像是像素阵列,因此它们可以由矩阵表示。每个像素可以表示为矩阵元素,其值对应于提出的数字2d图像的rgb或灰度值。这些值可以在进一步处理之前标准化。
233.卷积神经网络a(503)将多个提出的数字2d图像502的矩阵编码为均值向量504和标准偏差向量505,然后对其进行采样以生成潜变量506,过程与图的步骤400类似4,如上所述。向量505可以使用对数方差代替标准偏差。
234.潜变量,即提出的数字2d图像参数化506可以参数化提出的数字2d图像,并且可以解码回具有对应2d数字图像的矩阵。这些潜变量具有与图4中的潜变量406相似的属性,因为它们是具有一定值范围的标量数,并且是底层对象的参数化,如上所述。但是,底层对象可能更好地由一组不同的标量表示,因此组的大小和最优值可能不同。
235.卷积神经网络b(507)将潜变量,即提出的数字2d图像参数化506解码为提出的数字2d图像的自动编码矩阵508。提出的数字2d图像的自动编码矩阵508是图2中的第一组输出数据205的实施例。
236.如上所述,卷积神经网络需要反向传播以进行训练。因此,卷积神经网络b(507)的输出数据,即提出的数字2d图像508的自动编码矩阵,基于其与提出的数字2d图像503/509的矩阵的相似性来评估。
237.第二步骤510训练沙漏预测器以基于对应的治疗前数字2d图像创建提出的数字2d图像。
238.匹配的提出的数字2d图像511和匹配的治疗前数字2d图像512是沙漏预测器的训练数据的底层对象的示例。治疗前数字2d图像是患者在治疗前的数字图像。它可以是显示患者微笑的2d图像,其中上前牙的一部分是可见的。
239.治疗前数字2d图像512是输入训练数据513的底层对象,并且提出的数字2d图像511是输出数据519和目标训练数据520的底层对象。矩阵表示以类似的方式进行的到步骤500中讨论的那些,从而训练自动编码器。
240.卷积神经网络c(514)将匹配的治疗前数字2d图像513的矩阵编码为均值向量515
和标准偏差向量516。然后均值向量515和标准偏差向量516被样本以估计潜变量,即匹配的提出的数字2d图像参数化517。向量516可以使用对数方差代替标准偏差。
241.潜变量,即匹配的提出的数字2d图像参数化517,具有与来自第一步骤506的潜变量相同的数据格式,并且表示相同的底层对象。
242.卷积神经网络b(518)将潜变量,即匹配的提出的数字2d图像参数化517解码成匹配的提出的数字2d图像519的矩阵。卷积神经网络b(518)与第一步骤(507)的卷积神经网络b相同。使用卷积神经网络b(507/518)作为两个步骤的解码器意味着潜变量被解码为相同类型的对象。
243.匹配的提出的数字2d图像519的矩阵等同于图2中的第二组输出数据212。与目标训练数据组,即匹配的提出的数字2d图像520的矩阵进行比较来评估该输出数据。
244.匹配的提出的数字2d图像520的每个矩阵对应于匹配的治疗前数字2d图像513的矩阵。解码器,即卷积神经网络b(507/518)没有改变,这意味着只有卷积神经网络c(514)在步骤510中被训练,如上所述。
245.总之,步骤510训练卷积神经网络c(514)以返回潜变量(517),其解码为与给定治疗前数字2d图像匹配的提出的数字2d图像。
246.第三步骤521为新的治疗前数字2d图像预测提出的数字2d图像,并且可以被认为是牙科专业人员针对治疗前数字2d图像设计的内容。
247.新的治疗前数字2d图像522是沙漏预测器的输入数据的底层对象的示例,与匹配的治疗前数字2d图像512的类型相同。新的治疗前数字2d图像522按照上面讨论的方法处理成矩阵523。
248.卷积神经网络c(524)将新的治疗前数字2d图像523的矩阵编码为均值向量525和标准偏差向量526。如上所述,这些被采样以估计潜变量,即匹配的提出的数字2d图像/牙齿参数化527。卷积神经网络c(524)与来自步骤510的卷积神经网络c(514)相同。
249.潜变量,即新提出的数字2d图像参数化527,具有与来自第一步骤(506)和第二步骤(516)的潜变量相同的数据格式,并且表示相同的底层对象。
250.卷积神经网络b(528)将潜变量,即新提出的数字2d图像参数化527解码为提出的数字2d图像预测529的矩阵。卷积神经网络b(528)与来自第一步骤和第二步骤(507/518)的卷积神经网络b相同。
251.预测的提出的数字2d图像预测529的矩阵等同于图2中的第三组输出数据219。
252.提出的数字2d图像530可以例如通过叠加、覆盖和/或组合而并入新的治疗前数字2d图像522中,从而产生具有预测的提出的数字2d图像531的新的治疗前数字2d图像。
253.图6a
‑
6e示出了各种实施例中3d对象的可能表示。
254.图6a示出了在实施例中的臼齿的深度图。深度图可以从3d对象的图片得出,其中每个像素的尺度(scale)用于估计它与相机的距离,因此它在3d空间中的表示。在这里,从多个视点示出了臼齿。
255.图6b示出了在实施例中的臼齿的伪图像。伪图像是2d图像,其中每个像素的灰度值表示在该点与3d对象的视点的标准化距离。该距离可以从3d扫描得出。在这里,从多个视点示出了臼齿。
256.图6c示出了在实施例中的臼齿的体素表示。体素表示使用三维网格来表示3d对
象。每个体素可以是3d空间中的立方体。如果对象存在于该体素中,则将其标记为存在,如果不存在于该体素中,则标记为不存在。在这里,牙齿以体素表示。注意,在本实施例中,体素大小特别大以更清楚地说明体素。根据应用,也可以使用更小的体素。
257.图6d示出了在实施例中臼齿表面的点云表示。点云是3d空间中点的集合,每个点都有x、y、z坐标。此处,来自图6c的臼齿表面显示为点云,但是点云可以表示体积。
258.图6e示出了在实施例中臼齿表面的网格表示。网格是顶点、边和面的集合。顶点是表示表面的单个点,边是连接顶点的线,并且面是由顶点和边包围的连续区域。此处,图6c
‑
d中的臼齿表面被表示为三角形网格。
259.图7示出了根据实施例的从扫描或数字对象生成对应的3d网格的方法。在701中,对物理对象进行扫描,这里是牙齿或牙冠的表面。此步骤是可选的,因为某些对象仅作为数字对象存在。模型可能是在cad/cam程序中设计的,从来都不是物理对象。702是来自扫描的原始3d网格。
260.从702到703,通过上述网格平坦化过程,将原始3d网格平坦化为平面网格。此时,原始3d网格和平面网格是双射的。对于某些网格平坦化过程,平坦化过程可以是完全可逆的。步骤704示出了被采样的平面网格,尽管如上所述,有几种方法可以这样做。步骤705示出采样矩阵,其中每个样本被内插的或取自平面网格上的样本。
261.步骤706示出了根据实施例的采样矩阵的对应3d网格。这里,对应的网格是一致的网格,并且采样矩阵和对应的3d网格可以来回转换。此外,对任何一个的操作都可以转换回另一个。例如,对采样矩阵的矩阵操作可以转换到对应的3d网格。相反,705中对应3d网格形状的变化也会改变采样矩阵。
262.图8a
‑
8c示出了根据实施例的2d rgb矩阵、采样矩阵和对应的3d网格之间的对应关系。
263.图8a分别示出了根据实施例的红色、绿色和蓝色矩阵的灰度图像。图像800(红色矩阵)表示来自平面网格的样本的x值。图像的每个像素相当于矩阵的矩阵单元。x值已标准化,并且每个像素的尺度值是其对应样本的标准化x值。以类似的方式,图像801(绿色矩阵)表示平面网格的样本的y值,并且图像802(蓝色矩阵)表示平面网格的样本的z值。
264.图8a中的红色、绿色和蓝色矩阵可以组合成单个彩色图像,即2d rgb矩阵(未示出,因为它将是彩色图像)。2d rgb矩阵组合来自图8a的红色、绿色和蓝色值,使得每个像素具有来自图8a中的每个矩阵的对应像素的rgb值。因此,像素的rgb值也对应于像素对应样本的三维坐标。
265.图8b示出了根据实施例的采样矩阵的子组。具体来说,它们示出了采样矩阵的第55
‑
57行、第1
‑
3列。由于可用空间有限,未显示整个采样矩阵。
266.来自平面网格的样本具有位置和三维坐标。位置是包括表示样本相对于其他样本的位置的数值的坐标。三维坐标包括三个数值,表示三维空间中的点,并且可以是欧氏坐标。
267.在采样矩阵中,样本的位置可以是其矩阵元素在采样矩阵中的位置。表示为x、y和z值的三维坐标可以是矩阵元素的值。这可以以多种方式显示,作为具有一个维度的元素的三个二维数组(803
‑
805),或者作为具有三个维度的元素的二维数组(806)。
268.803表示的采样矩阵是具有一个维度(即x维度)的元素的二维数组。每个矩阵元素
表示样本,其中矩阵元素的位置是样本的位置,并且矩阵元素的值是样本的绝对坐标x值,单位为毫米。804和805表示的采样矩阵与803类似,但分别针对y值和z值。
269.806表示的采样矩阵是二维数组,具有三个维度的元素。比较第一元素可以看出,806矩阵元素的值是803
‑
805中相同位置处的矩阵元素的值。因此,806具有所有三个坐标x、y和z。
270.由于806表示的采样矩阵和803
‑
805表示的采样矩阵是相同对象的不同数据格式,因此本文中将两种格式都称为“采样矩阵”。
271.由803表示的采样矩阵类似于图像800,即红色矩阵。对于给定的样本,x值可以由800矩阵元素的值表示为标准化为色标(color scale),或通过803矩阵元素的值表示为欧几里得坐标。欧几里得坐标可以是绝对的或标准化的;图8b表示的矩阵示出绝对坐标。采样矩阵子组803用于第55
‑
57行和第1
‑
3列,它们对应于红色矩阵800中相同位置的像素。
272.以相似方式,804和805表示的采样矩阵分别类似于801和802。
273.806表示的采样矩阵类似于2d rgb采样矩阵。对于给定的样本,x、y、z值可以由对应的2d rgb矩阵元素的值表示为标准化为rgb色标,或通过对应806矩阵元素的值表示为欧几里得坐标。
274.图8c示出了根据实施例的与图8b中的采样矩阵和图8a中的图像对应的3d网格。请注意,与来自扫描的网格不同,图8c中对应的3d网格是一致连接的。来自图8c中对应3d网格的顶点具有来自图8b表示的采样矩阵的对应矩阵元素;例如,图8b中所示的九个矩阵元素是沿牙齿左边界的九个顶点。顶点在图8a的图像中也有对应的像素,这里是第55
‑
57行、第1
‑
3列中的像素。
275.图8a中的一个/多个rgb矩阵、图8b中的采样矩阵和图8c中的对应3d网格是相同底层三维对象的不同表示。此外,这些表示是双射的,可以在格式之间来回转换。
276.通过改变任何一个表示的属性,可以改变其他表示。例如,改变采样矩阵的矩阵操作将改变2d rgb矩阵和对应的3d网格。这在应用依赖矩阵操作和/或统一数据组的机器学习方法时特别有用。采样矩阵允许对三维对象执行机器学习方法。
277.在一个实施例中,可以通过将矩阵的每个元素乘以标量数来完成标量变换;对应3d网格的大小会与标量数成比例地改变。在另一实施例中,可以对采样的矩阵执行主成分分析。基于主成分对采样矩阵的任何改变也会影响对应的3d网格。
278.图9示出了使用变换函数变换对象的方法的实施例。
279.首先,在步骤900中训练自动编码器。训练自动编码器的细节类似于图2步骤200中描述的自动编码器,但总结一下:训练输入数据901由编码器902编码为潜变量903。潜变量903被解码器904解码为训练输出数据905。然后将训练输出数据905与训练输入数据901进行比较,并且相应地改变解码器904和编码器902的权重。该循环重复直到训练输入数据901和训练输出数据905基本相同,此时自动编码器被认为经过训练。
280.编码器902和解码器904可以是神经网络;图3中描述了示例架构。训练输入数据901可以是真实世界对象的表示,例如,牙齿的平坦化3d网格。
281.接下来,在步骤906中为数据对找到潜变量。如上所述,每个数据对907包括初始对象908和变换对象909。这些对象类似于训练输入数据901底层的对象类型,因此可以由自动编码器从步骤900读取。初始对象908和变换对象909各自经过编码器911/914,其为在步骤
900中训练的编码器902。编码输出两组潜变量——初始状态潜变量912和变换状态潜变量915。
282.步骤916基于初始状态潜变量917和变换状态潜变量918找到变换919函数。具体实施例在上面和下面讨论。
283.步骤920将变换函数925应用于新对象921。新对象921可以是与初始对象908相同的类型,并且可以被转换为编码器923可读的新对象输入数据。编码器923与来自步骤906的编码器911/914和来自步骤900的经训练编码器902相同。编码新对象输入数据922生成新的潜变量924。
284.新潜变量然后由变换函数925变换成变换的新潜变量926。变换函数925是在步骤916中得出的变换函数919。
285.变换的潜变量926然后由解码器927解码为变换的输出数据928。解码器927与来自步骤900的经训练解码器904相同。变换的输出数据928可以被转换为变换的新对象929,其是以初始对象908到变换对象909相同方式被变换的新对象921。
286.图10示出了基于向量的变换函数的简单示例。它示出五个数据对,每个数据对有两个潜变量。
287.图1001示出了xy图中的5组初始状态潜变量,每组均由正方形表示,显示了每个初始对象的两个潜变量。虽然可能有更多的潜变量,但为了便于说明,这里只示出了两个,对应于绘图的x和y值。类似地,为了说明目的,显示了给定数据对;训练自动编码器可能涉及更多或更少。
288.图1002进一步示出了xy图中的5组变换状态潜变量,每组由一个圆圈表示。同样,虽然可能有更多的潜变量,但为了便于说明,只示出了两个,其值对应于绘图的x和y值。在该实施例中,变换状态潜变量(圆圈)远离初始状态潜变量(正方形)集群在一起。
289.图1003进一步示出了在每个数据对的初始状态潜变量(正方形)和变换状态潜变量(圆圈)之间绘制为箭头的向量。向量通常有大小和方向;在这个实施例中,向量的作用是为每个潜变量添加常数。因为变换状态被认为是完成状态,所以向量方向指向变换状态潜变量。
290.图1004进一步示出了变换函数的实施例,这里是图1003的向量的平均向量(箭头)。请注意,它从初始状态潜变量(正方形)集群的中心开始,并终止于变换状态潜变量(圆圈)集群的中心。然而,由于向量包括大小和方向,因此向量无需在此处显示的点处开始和终止。而是,向量是相对的,因此可以应用于新的潜变量组,其可以由xy图上的新位置表示。
291.图1005进一步示出了新对象的潜变量,用星号表示。在该实施例中,新对象类似于初始对象,这可以通过其在初始对象潜变量(正方形)集群中的位置看出。
292.图1006示出了变换函数,即图1004中的向量(箭头),其应用于新的对象潜变量(箭头开头的星号)。箭头末端的星号是变换的新潜变量。请注意,变换的新潜变量的位置靠近变换的潜变量(圆圈),表明它与那些底层对象相似。
293.图1007示出了使用向量(箭头)进行部分变换。在这里,向量的大小已经减半,并且变换的新潜变量(箭头末端的星号)现在位于初始对象潜变量和变换对象潜变量之间的中途。这可以用于调整变换级别。
294.图1008示出了使用向量(箭头)进行过度变换。在这里,向量的大小增加了20%,因
此变换的新潜变量(箭头末端的星号)被外推到原始变换之外。
295.图11示出了使用向量作为变换函数来老化牙齿的实施例。图1101是新对象,臼齿。图1105是变换的新对象,老化的臼齿,在100%的向量处。图1102、1103和1104分别使用25%、50%和75%的向量进行了变换。
296.图12示出了实施例,其中牙冠舌侧的角对称性以变换函数增加。图12a示出了原始牙冠,并且图12b示出了变换牙冠。
297.在设计牙冠时可能需要增加角对称性,因为更光滑的牙冠对患者来说更舒适并且更容易进行咀嚼。然而,完美的圆形牙冠看起来不像真的牙齿,并且与相邻的牙齿不太吻合。这会导致调整牙冠使其看起来像逼真的牙齿,同时最大限度地减少某些不合宜的特征(例如过度突出的凸起)的问题。
298.变换函数可用于以一致且可量化的方式解决此问题。图12a示出了原始牙冠;图12b示出了由在一组数据对上训练的变换函数变换的牙冠,其中变换的对象在舌侧具有增加的角对称性。
299.请注意,总体上保持了牙冠的原始形状,但某些特征已被平滑。例如,舌侧的大凸起(如图1201和1204中的图像右侧所示)稍微平坦一些。尽管图中存在细微差别,但由于这种变化,患者可以体验到更好的咀嚼和更舒适的贴合。然而,由于变换函数仅限于舌侧,因此该变化不会影响邻牙。
300.根据实施例,公开了一种体现在非暂时性计算机可读介质中的计算机程序产品。计算机程序产品包括可由硬件数据处理器执行的计算机可读程序代码,以在所述计算机可读程序代码由硬件数据处理器执行时使硬件数据处理器执行方法。该方法可以包括系统部件中的任何一个执行本公开的一个或多个实施例中公开的方法的一个或多个步骤的一个或多个功能。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1