由处理单元实现的方法、可读存储介质和处理单元与流程
由处理单元实现的方法、可读存储介质和处理单元
1.本公开要求2019年9月24日提交的申请号为62/904,953的美国临时申请的优先权,该申请通过引用全文并入本文。
技术领域
2.本公开实施例涉及神经网络领域,尤其是一种由处理单元实现的方法、可读存储介质和处理单元。
背景技术:
3.在机器学习(ml)或深度学习(dl)方面,神经网络(nn)是一种非常强大的、能够大体上模仿人脑的学习方式的架构。深度神经网络(dnn)是神经网络的一个分类。多年来,dnn在计算机视觉、自然语言处理等领域取得了巨大的成功。一个典型的dnn模型可能有数百万个参数,这需要大量的计算和存储资源来进行模型的训练和部署。现代大规模并行处理设备的发展为dnn技术在各种应用中的落地提供了机遇。
4.十年前,通用图形处理器(gpgpu)被开发出来以加速科学计算。目前,gpu被广泛地应用于实施dnn技术。虽然gpu的资源利用率随着dnn的计算需求不断提高,但由于诸多原因,gpu的资源利用率基本上仍是次优的。例如,gpu的内存层次结构限制芯片内快速存储,而dnn需要快速访问海量数据。此外,gpu维护全面的通用指令集,这需要额外的资源,而dnn只需要少量的专用可编程操作。
技术实现要素:
5.在一些实施例中,提供一种示例性的由处理单元实现的方法,处理单元包括命令解析器和至少一个核,命令解析器用于分配命令和计算任务,至少一个核与命令解析器耦合通信并用于处理所分配的计算任务,每个核包括卷积单元、池化单元、至少一个操作单元和定序器,定序器与卷积单元、池化单元和至少一个操作单元耦合通信并用于将所分配的计算任务的指令分配给卷积单元、池化单元和至少一个操作单元以供执行,该方法包括:由卷积单元从至少一个操作单元的本地存储器读取数据;由卷积单元对数据执行卷积操作以生成特征映射;和由池化单元对特征映射执行池化操作。
6.在一些实施例中,提供一种示例性的非暂时性计算机可读存储介质,可读存储介质存储一组指令,该组指令可由至少一个处理单元执行以使计算机执行方法,处理单元包括命令解析器和至少一个核,命令解析器用于分配命令和计算任务,至少一个核与命令解析器耦合通信并用于处理所分配的计算任务,每个核包括卷积单元、池化单元、至少一个操作单元和定序器,定序器与卷积单元、池化单元和至少一个操作单元耦合通信并用于将所分配的计算任务的指令分配给卷积单元、池化单元和至少一个操作单元以供执行,方法包括:由卷积单元从至少一个操作单元的本地存储器读取数据;由卷积单元对数据执行卷积操作以生成特征映射;和由池化单元对特征映射执行池化操作。
7.在一些实施例中,提供一种示例性的处理单元,该处理单元包括:命令解析器,用
于分配命令和计算任务;和与所述命令解析器耦合通信的至少一个核,用于处理所分配的计算任务,每个核包括:卷积单元,其具有通过卷积指令执行卷积操作以生成特征映射的电路;池化单元,其具有通过池化指令对所述特征映射执行池化操作的电路;至少一个操作单元,其具有处理数据的电路;和定序器,与所述卷积单元、所述池化单元和所述至少一个操作单元耦合通信,并且具有将所分配的计算任务的指令分配给所述卷积单元、所述池化单元和所述至少一个操作单元以执行的电路。
8.本公开的附加特征和优点的一部分将在下文中有详细描述,一部分可从详细描述中显而易见地得到,或者可通过本公开的实践来了解。本公开的特征和优点将通过所附权利要求中特别指出的元素和组合来实现和获得。
9.应当理解,上述一般描述和以下的详细描述仅是示例性和说明性的,而不是对本公开的实施例的限制。
附图说明
10.构成本说明书一部分的附图示出了几个实施例,并且与描述一起用于解释本公开的各个实施例的原理和特征。在附图中:
11.图1是根据本公开的一些实施例的神经网络的示意图。
12.图2是根据本公开的一些实施例的示例性的基于神经网络进行推理的工作流(pipeline workflow)的示意图;
13.图3a是根据本公开的一些实施例的在一示例性的卷积神经网络(cnn)中构建块的一个片段的示意图;
14.图3b是根据本公开的一些实施例的在另一示例性的卷积神经网络(cnn)中构建块的一个片段的示意图;
15.图4是根据本公开的一些实施例的示例性的神经网络处理单元(npu)的示意图。
16.图5a是根据本公开的一些实施例的示例性的机器学习系统的示意图;
17.图5b是根据本公开的一些实施例的多层软件体系结构的示意图;
18.图5c是根据本公开的一些实施例的包含了npu的示例性的云系统的示意图;
19.图6a是根据本公开的一些实施例的npu的核的示例性的推理工作流的示意图;
20.图6b是根据本公开的一些实施例的npu的核的示例性的推理工作流的示意图;
21.图7是根据本公开的一些实施例的示例性的神经网络的工作流的示意图;
22.图8是根据本公开的一些实施例的npu的核中的示例性的数据移动的示意图;
23.图9是根据本公开的一些实施例的npu的核中的各个处理单元之间的工作流的示意图;
24.图10示出了根据本公开的一些实施例的npu的示例性指令;
25.图11是根据本公开的一些实施例的由处理单元实现的示例性方法的流程图。
具体实施方式
26.下面将详细描述示例性的实施例,其示例性的附图在随后的附图中示出。下面的描述将参考附图,其中不同附图中的相同数字表示相同或类似的元件,除非另有表示。下面在示例性的实施例的描述中阐述的实现并不代表与本技术一致的所有实现。相反,它们只
是与所附权利要求中所述的、与本发明相关的各个方面一致的装置、系统和方法的示例。
27.这里公开的装置和系统可用在各种基于神经网络的体系结构中,例如卷积神经网络(cnn)、循环神经网络(rnn)等,并且可被配置为例如神经网络处理单元(npu)等的体系结构。
28.图1是神经网络(nn)100的示意图。如图1所示,神经网络100可以包括输入层120,输入层120用于接收诸如输入110-1至输入110-m的输入。输入可以包括由神经网络100处理的图像、文本或任何其他结构化或非结构化数据。在一些实施例中,神经网络100可以同时接受多个输入。例如,在图1中,神经网络100可以同时接收多达m个输入。附加地或替代地,输入层120可以快速且连续地接收多达m个输入,例如,输入110-1是输入层120在一个周期内接收的输入,第二输入是输入层120在第二周期内接收的输入,在第二周期内,输入层120将来自输入110-1的数据推送到第一隐藏层,诸如此类。任何数目的输入可以是同时输入、快速且连续的输入、诸如此类。
29.输入层120可包括一个或多个节点,例如,节点120-1、节点120-2、
…
、节点120-a。每个节点可以将激活函数应用于相应的输入(例如,输入110-1至输入110-m中的一个或多个)并通过与节点相关联的特定权重对激活函数的输出进行加权。激活函数可包括heaviside阶跃函数、高斯函数、多重二次函数、反多重二次函数、sigmoidal函数、relu函数、leaky relu函数、tanh函数、等等。权重可以包括介于0.0和1.0之间的正值,或任何其他允许一个层中的一些节点的输出比该层中的其他节点的输出规模更大或更小的数值。
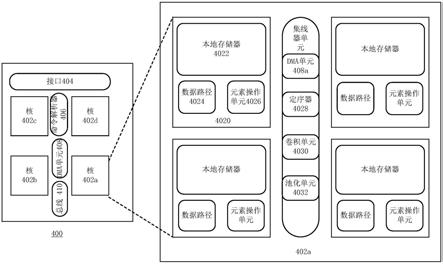
30.如图1进一步描述的,神经网络100可以包括一个或多个隐藏层,例如隐藏层130-1至隐藏层130-n。每个隐藏层可以包括一个或多个节点。例如,在图1中,隐藏层130-1包括节点130-1-1、节点130-1-2、节点130-1-3、
…
、节点130-1-b,并且隐藏层130-n包括节点130-n-1、节点130-n-2、节点130-n-3、
…
、节点130-n-c。与输入层120的节点类似,隐藏层的节点可以将激活函数应用于前一层的连接节点的输出,并通过与节点相关联的特定权重对激活函数的输出进行加权。
31.如图1中进一步描述的,神经网络100可以包括用于完成输出(例如输出150-1、输出150-2、
…
、输出150-d)的输出层140。输出层140可包括一个或多个节点,例如,节点140-1、节点140-2、
…
、节点140-d。与输入层120和隐藏层的节点类似,输出层140的节点可以将激活函数应用于前一层的连接节点的输出,并通过与节点相关联的特定权重对激活函数的输出进行加权。
32.尽管在图1中描述全连接,但神经网络的各个层100可以使用任何连接方案。例如,可以使用卷积方案、稀疏连接方案或类似连接方案连接一个或多个层(例如,输入层120、隐藏层130-1、
…
、隐藏层130-n、输出层140等)。这样的实施例在当前层和前一层之间使用比图1所示更少的连接。
33.此外,尽管在图1中描述前馈网络,但神经网络100可以另外或替代地使用反向传播(例如,通过使用长短期记忆节点或类似节点)。因此,尽管神经网络100被描绘为类似于卷积神经网络(cnn),但神经网络100可以包括循环神经网络(rnn)或任何其他神经网络。
34.一般来说,神经网络在深度学习的工作流中有两个阶段:训练和推理。在训练阶段,神经网络通过迭代更新参数值来持续学习参数值,以最小化预测误差。当收敛时,具有学习到的参数值的神经网络可用在新案例中执行推理任务。
35.图2是根据本公开的一些实施例的示例性的基于神经网络进行推理的工作流200的示意图。尽管推理工作流200涉及图像识别,但应理解这只是示例而不是限制。如图2所示,经由训练得到的神经网络(例如,图1的神经网络100)可以接收输入201,例如,蜜獾的图像,并对输入201执行计算203。具体地说,在神经网络中前向传播(fp)开始,数据从输入层通过一个或多个隐藏层流向输出层。如图1所示意的,神经网络中的每一层接收来自前一层(或多层)的输入,对输入进行计算,并将输出发送给后一层(或多层)。在计算之后,神经网络提供输出205,例如评估结果。如图2所示,输出205可以包括分别具有概率的多个可能的评估项目。概率最高的项目可确定为最终评估结果。
36.卷积神经网络(cnn)是dnn的一个分类。cnn被广泛应用于许多技术领域。例如,cnn可以执行视觉任务,例如,图像特征或模式的学习或识别。
37.图3a示出了在示例性的cnn中构建块的片段310。例如,示例性的片段310可以是初始模块。如图3a所示,片段310可以包括并行的多个分支,例如卷积分支311、313、315和池化分支317。卷积分支311包括1
×
1卷积块(conv)。卷积分支313包括3
×
3卷积块(conv)和位于其之前的1
×
1卷积块(conv)。卷积分支315包括5
×
5卷积块(conv)和位于其之前的1
×
1卷积块(conv)。池化分支317包括3
×
3池化块(pool)和位于其之后的1
×
1卷积块(conv)。例如,池化块可以是3
×
3最大池化块。与每个卷积块一起,可以有一个批量归一化块(bn)和一个激活块(relu)。例如,激活块可为relu、leaky relu、sigmoid、tanh等。
38.如图3a所示,片段310还可以包括连接块(concat)319。连接块319可以连接到多个分支,例如,分支311、313、315和317。分支可以从前一层(前多个层)接收输入并执行计算。连接块319可以将来自卷积分支311、313、315和池化分支317的结果连在一起,并将结果提供给其他块或层。cnn可以包括多个片段310、输入层、输出层和一个或多个其他层。
39.图3b示出了另一示例性的cnn中的构建块的片段330。例如,示例性的cnn可以是残差网络。如图3b所示,片段330可以包括多个分支,例如分支331和卷积分支333。卷积分支333包括1
×
1卷积(conv)块333-1、3
×
3卷积块333-2和3
×
3卷积块333-3。卷积分支333从前一层(前多个层)接收输入并对输入执行计算。分支331包括一个跨过卷积分支333的跳跃连接。片段330还包括加法块335,其从分支331和333接收输入并执行加法。此外,片段330还可以包括一个或多个批量归一化(bn)块和激活块(例如,relu块)。cnn可以包括多个片段330、输入层、输出层和一个或多个其他层。
40.图4示出了根据本公开的一些实施例的示例性的神经处理单元(npu)400。如图4所示,npu 400可以包括至少一个核402(例如,402a、402b、402c和402d)、接口404、命令解析器(cp)406、直接存储器访问(dma)单元408、等等。可以理解,npu 400还可以包括总线410、全局存储器(未示出)、等等。
41.接口404可以提供npu 400与外部设备之间的通信。例如,接口404可以包括高速串行计算机扩展总线标准(pci-e)接口,其提供与主机单元(图4中未示出)的连接。接口404还可以包括通用串行总线(usb)、联合测试动作组(jtag)接口、tun/tap接口等中的至少一个。
42.命令解析器406可以在内核模式驱动程序(kmd)的监督下与主机单元交互,并将神经网络任务、相关命令(或指令)和数据传递给每个核402。命令解析器406可以包括一电路,该电路执行与主机单元的交互以及将神经网络任务、相关命令(或指令)和数据传递到每个核402。在一些实施例中,命令解析器406可以从主机单元接收dma命令,并根据dma命令将用
于神经网络的指令(例如,由主机单元中的编译器生成的用于神经网络的指令序列)、神经网络的权重或比例/偏置(scale/bias)常数加载到核402。例如,命令解析器406可以根据dma命令将用于神经网络的指令从外部存储器加载到核402的指令缓冲器,将权重加载到核402的本地存储器4022,或者将比例/偏置常数加载到核402的常数缓冲器。在一些实施例中,命令解析器406可以与主机单元或kmd一起工作以将神经网络任务(例如,图像的识别,包括图像的数据)分配给核402。例如,主机单元或kmd可以向一个核402的队列发送一个神经网络任务,该核402被指派了该神经网络任务,并且命令解析器406将该神经网络任务分配给该核402。在一些实施例中,当核402完成神经网络任务时(例如,核402可以向命令解析器406发送“计算完成”的消息),命令解析器406可以通知主机单元或kmd。新的神经网络任务可以由主机单元或kmd指派给核402。
43.dma单元408可以协助在npu 400的各个组件之间传送数据。dma单元408可以包括用于执行数据传输或命令的电路。例如,dma单元408可以协助在多个核(例如,核402a-402d)之间传送数据或在每个npu核内传送数据。dma单元408还可以允许片外设备经由接口404访问片上存储器和片外存储器而不引起中断。例如,dma单元408可以将数据或指令加载到核的本地存储器中。因此,dma单元408还可以生成存储器地址并启动存储器读或写周期。dma单元408还可以包含可由一个或多个处理器写入和读取的若干个硬件寄存器,这些硬件寄存器包括存储器地址寄存器、字节计数寄存器、一个或多个控制寄存器和其他类型的寄存器。这些寄存器可以指定源、目的、传输方向(从输入/输出设备读取或向输入/输出设备写入)、传输单元的大小和/或在一个脉冲中要传输的字节数的某种组合。可以理解,每个核(例如,核402a)可以包括子dma单元,该子dma单元可以用于在核内传输数据。
44.dma单元408还可以经由总线410在各个核之间移动块数据。虽然单个的核能够处理典型的推理任务(例如,resnet50 v1),但核也可以通过总线一起工作以承担大型和复杂的任务(例如restnet101、掩码r-cnn等)。
45.总线410可以提供高速跨核通信。总线410还将npu的各个核与其他单元耦合,例如与片外存储器或外围设备耦合。
46.核402(例如,核402a)可以包括一个或多个处理单元,处理单元可用于基于命令(例如从命令解析器(cp)406接收的命令)执行一个或多个操作(例如,乘法、加法、乘法累加、元素操作等)。例如,核402可以从命令解析器406接收神经网络任务、指令和数据(例如,神经网络的权重或比例/偏置常数),并使用数据执行指令。在一些实施例中,当核402完成神经网络任务时,它可以通知命令解析器406。例如,核402可以向命令解析器406发送“计算完成”的消息。如图4所示,核402a可以包括至少一个操作单元4020、定序器4028、卷积单元4030、池化单元4032和dma单元408a,它们可以经由数据结构和仲裁子系统(也称为集线器单元)连接。在一些实施例中,集线器单元可以包括用于分别向卷积单元4030和池化单元4032提供与神经网络任务相关联的卷积数据和池化数据的电路。
47.操作单元4020可以包括用于对接收的数据(例如,矩阵)执行操作的电路。在一些实施例中,每个操作单元4020可进一步包括本地存储器4022、矩阵乘法数据路径(dp)4024和内嵌式元素操作(ewop)单元4026。本地存储器4022可以提供具有快速读/写速率的存储空间。为了减少与全局存储器的可能交互,本地存储器4022的存储空间可以是180兆字节(mb)及以上。利用海量的存储空间,大部分数据访问可以在核402内进行,从而减少了数据
访问带来的延迟。dp 4024可以包括用于执行矩阵乘法(例如,点积(dot production))的电路,并且ewop单元4026可以包括用于对接收数据执行元素操作(例如,向量和向量的乘法)的电路。可以理解的是,尽管图4示出了四个操作单元4020,但核402a可以包括更多或更少的操作单元4020。
48.定序器4028可与指令缓冲器耦合,并包括用于检索指令(或命令)并将指令分配给例如核402的组件的电路。例如,定序器4028可以包括用于将卷积指令分配到卷积单元4032以执行卷积操作或将池指令分配给池化单元4033以执行池化操作的电路。在一些实施例中,定序器4028可以包括用于修改存储在每个核402的指令缓冲器中的相关指令的电路,以便各个核402可以尽可能并行地工作。定序器4028还可以包括用于监视神经网络任务的执行并将神经网络任务的子任务并行化以提高执行效率的电路。
49.卷积单元4030可与定序器4028和一个或多个操作单元4020耦合,并包括用于指示一个或多个操作单元4020执行卷积操作的电路。在一些实施例中,卷积单元4030可以向本地存储器4022发送命令,以向数据路径4024发送激活数据和加权数据,以执行卷积操作。
50.池化单元4032可进一步包括插值单元、池数据路径等,并包括用于执行池化操作的电路。例如,插值单元可以包括用于对池化数据进行插值的电路。池化数据路径可以包括用于对插值后的池化数据执行池化操作的电路。
51.dma单元408a可以是dma单元408的一部分或每个核的独立单元。dma单元408a包括用于传送数据或命令的电路。命令可分配给dma单元408a,以指示dma单元408a将来自本地存储器(例如,图4的本地存储器4022)的指令/命令或数据加载到相应的单元中。然后,将所加载的指令/命令或数据分配给已经指派了相应任务的处理单元,并且这些一个或多个处理单元可处理这些指令/命令。
52.图5a是根据本公开的一些实施例的示例性的机器学习系统500的示意图。如图5a所示,机器学习系统500可以包括主机处理器502、磁盘504、主机存储器506和神经网络处理单元(npu)400。在一些实施例中,主机存储器506可以是与主机处理器502相关联的整体存储器或外部存储器。主机存储器506可以是本地存储器或全局存储器。在一些实施例中,磁盘504可以包括用于为主机处理器502提供额外存储器的外部存储器。
53.主机处理器502(例如,x86或arm中央处理单元)可以与用于处理通用指令的主机存储器506和磁盘504耦合。神经网络处理单元400可以通过外围接口(例如,接口404)连接到主机处理器502。如本文所述,神经网络处理单元(例如,npu 400)可以是用于加速神经网络推理任务的计算设备。在一些实施例中,npu 400可以用作主机处理器502的协处理器。
54.在一些实施例中,编译器可以部署在主机单元(例如,图5a的主机处理器502或主机存储器506)或npu 400上,用于将一个或多个命令推送到npu 112。编译器是将用一种编程语言编写的计算机代码转换成用于npu 400的指令以创建可执行程序的程序或计算机软件。在机器学习应用中,编译器可以执行各种操作,例如,预处理、词法分析、解析、语义分析、将输入程序转换为中间表示、神经网络的初始化、代码优化和代码生成、或以上组合。例如,在机器学习系统500中,编译器可以编译神经网络以生成静态参数,例如,神经元之间的连接和神经元的权重。
55.如上文所述,这些指令或命令可由npu 400的命令解析器406进一步加载,临时存储在npu 400的指令缓冲器中,并相应地分配(例如,由定序器4028分配)给npu 400的处理
单元(例如,卷积单元4030、池化单元4032和dma单元408a)。
56.可以理解,由npu的每个核接收的前几个指令可以指示核将数据从主机存储器506加载/存储到核内的一个或多个本地存储器(例如,图4的本地存储器4022)中。npu的每个核然后可以启动指令流水线,这包括从指令缓冲器中提取指令(例如,通过定序器)、解码指令(例如,通过dma单元)并生成本地存储器地址(例如,对应于操作数)、读取源数据、执行或加载/存储操作,然后写回结果。
57.可以采用多层软件体系结构围绕着npu 400构建灵活且易于扩展的环境。图5b示出了根据本公开的一些实施例的多层软件体系结构520的示意图。
58.为了部署神经网络模型,可以将由不同的神经网络框架5211(例如,tensorflow,mxnet等)构建的不同的神经网络拓扑转换为图形中间表达形式(图形ir)。前端部署和编译器527可以从图形ir开始,在模型量化523、分段524和优化525的方面执行一系列开发和细化,然后生成满足精度要求同时具有最佳性能的可执行文件。为了分发任务,运行时(runtime)层526可以充当要分发到npu 400的任务的唯一接入点。rt层526可以与用户模式驱动程序(umd)528协作建立任务部署,并经由内核模式驱动程序(kmd)529将其发布到npu 400。rt层526还可以将及时绑定和完成的信息馈送到驱动程序,以对npu 400提供所需的设备和上下文管理。由于npu 400可以在上下文资源上提供完全可见性,并且与主机直接地在任务级别上进行交互,因此可以提供稳健且一致的结果。
59.现在参考图5c,图5c是根据本公开的一些实施例的包含了npu的示例性的云系统的示意图。
60.在npu 400的协助下,云系统540可以提供图像识别、面部识别、翻译、3d建模等扩展的ai能力。
61.应当理解,npu 400可以以其他形式部署到计算设备。例如,npu 400还可以集成在计算设备中,例如智能手机、平板电脑和可穿戴设备。
62.图6a是根据本公开的一些实施例的npu的核的示例性的推理工作流的示意图。例如,npu的核可以是图4中的核402a至402d中的任何一个。尽管推理工作流610涉及到图像识别,但应理解这只是示例而不是限制。如图6a所示,npu的核可以接收输入,例如,一个蜜獾的图像。例如,npu的核的dma单元(未示出)(例如,图4中的核402a的dma单元408a)可以与外部组件通信,例如访问片上或片外存储器,以接收输入数据。dma单元可以将输入数据加载到核的本地存储器(未示出)(例如,图4中的核402a的本地存储器4022)中。npu的核可以执行神经网络以输入数据执行计算。例如,可以通过图的核402a中的本地存储器4022、定序器4028、操作单元4020、卷积单元4030、池化单元4032和dma单元408a的协作来执行计算。通过协同工作,可以不间断地进行计算。npu的核可以产生输出,例如,评估结果。如图6a所示,输出可以包括具有各自概率的多个可能的评估项目。概率最高的项目(例如,蜜獾的概率为80%)可以被确定为最终评估结果。例如,dma单元可以将输出(例如,评估结果)发送到外部,例如另一个核、主机单元、片上或片外存储器等。
63.图6b是根据本公开的一些实施例的npu的核的示例性的推理工作流630的示意图。例如,npu的核可以是图4中的核402a至402d的任何一个。尽管推理工作流630涉及图像识别,但应理解这只是示例而不是限制。如图6b所示,npu的核可以接收一系列输入,例如猫图像作为第一输入图像631-1、汽车图像作为第二输入图像631-2、青蛙图像作为第三输入图
像631-3和狗图像作为第四输入图像631-4。例如,npu的核的dma单元(未示出)(例如,图4中的核402a的dma单元408)可以与外部组件通信,例如访问片上或片外存储器,以接收输入数据。dma单元可以将输入数据加载到npu的核的本地存储器(未示出)(例如,图4中的核402a的本地存储器4022)中。如图6b所示,npu的核(例如,npu的核中的dma单元)可以接收第一输入图像631-1并执行神经网络以对第一输入图像631-1执行第一计算633-1。在第一计算633-1期间,npu的核可以接收第二输入图像631-2。在第一计算633-1之后,npu的核可以对第二输入图像631-2执行第二计算633-2。在第二计算633-2期间,npu(例如,npu核的dma单元)可以输出第一计算633-1的结果(例如,第一输出635-1),例如,猫的评估结果,并且还可以接收第三输入图像631-3。
64.类似地,在第二计算633-2之后,npu的核可以对第三输入图像631-3执行第三计算633-3。在第三计算633-3期间,npu可以输出第二计算633-2的结果(例如,第二输出635-2),例如,汽车的评估结果,并且还可以接收第四输入图像631-4。在第三计算633-3之后,npu的核可以对第四输入图像631-4执行第四计算633-4。在第四计算633-4期间,npu可以输出第三计算633-3的结果(例如,第三输出635-3),例如,青蛙的评估结果。在第四计算633-4之后,npu可以输出第四计算633-4的结果(例如,第四输出635-4),例如,狗的评估结果。因此,可以在当前计算期间进行下一个输入数据的输入和上一个计算结果的输出,并且可以通过计算有效地隐藏i/o延迟,反之亦然。
65.在一些实施例中,计算,例如计算633-1、633-2、633-3或633-4,可以通过图4的npu的核402a中的本地存储器4022、定序器4028、操作单元4020、卷积单元4030、池化单元4032和dma单元408a的协作来执行。通过协同工作,可以不间断地进行计算。如图6b所示,输出,例如输出635-1、635-2、635-3或635-4可以包括具有各自概率的多个可能的评估项。概率最高的项目(例如猫的概率为80%、车的概率为85%、蛙的概率为81%、狗的概率为82%,等等)可以确定为最终评价结果。例如,dma单元可以将输出(例如,评估结果)发送到外部,例如另一内核、主机单元、片上或片外存储器等。
66.在一些实施例中,融合或聚合神经网络的两个或更多层,或者融合或聚合神经网络任务的两个或更多操作。融合或聚合后的层或者融合或聚合后的操作可以由粗粒度指令(coarse-grain instruction)或高级别指令(high-level instruction)执行。粗粒度指令可以降低处理指令流的成本,提高每条指令的有效计算量。在一些实施例中,粗粒度指令可以包含控制指令流的标志。例如,卷积指令“conv”可以包括一个修改(modify)标志,该标志允许对指令的各个字段进行在线修改以运行时绑定和控制。池化指令“pool”可以包括用于指定各个层之间的数据依赖关系的等待(wait)标志。如果等待标志未被断言(assert),则意味着与该指令相关联的层可以与池化指令中指定的层并行执行。分支指令“br”可以包括用于协调不同核中的任务的同步(synchronization)标志。基于指令的各种标志,神经网络任务的操作可以一起、串行或并行地执行,这使得指令流处理紧凑和高效。
67.图7是根据本公开的一些实施例的示例性的神经网络701的工作流的示意图。如图7所示,神经网络701可以包括多个构建块,例如,输入块701-1、7
×
7卷积(conv)块701-2、3
×
3池化(pool)块701-3、1
×
1卷积块701-4、3
×
3卷积块701-5、1
×
1卷积块701-6、通道连接块701-7、3
×
3卷积块701-8、元素求和(elm求和)块701-9、等等。7
×
7卷积块701-2连接到输入块701-1和3
×
3池化块701-3。3
×
3池化块701-3以并联的方式连接到1
×
1卷积块701-4、3
×
3卷积块701-5和1
×
1卷积块701-6。1
×
1卷积块701-4和3
×
3卷积块701-5连接到通道连接块701-7。1
×
1卷积块701-6连接到3
×
3卷积块701-8。通道连接块701-7和3
×
3卷积块701-8连接到元素求和块701-9。元素求和块701-9可以连接到另一个块或层。神经网络701还可以包括多个批量归一化(bn)块和激活块(例如,relu块)。在图7中,实线箭头指示通过神经网络701的数据流,而虚线箭头指示不同块之间的依赖关系。
68.神经网络701由npu的核(例如,图4的核402a-d中的任何一个)执行。在工作流703a中,npu的核执行输入块701-1以接收输入。然后,核执行7
×
7卷积块701-2以对输入进行7
×
7卷积,然后分别执行bn块和relu块以执行批量归一化和relu。npu的核执行3
×
3池化块701-3以对relu块的结果进行3
×
3池化。对于3
×
3池化的结果,npu的核执行1
×
1卷积块701-4以执行1
×
1卷积,然后执行批量归一化操作;执行3
×
3卷积块701-5以执行3
×
3卷积,然后执行批量归一化操作;执行1
×
1卷积块701-6以执行1
×
1卷积,然后执行批量归一化和relu操作。在通道连接块701-7,npu的核执行来自1
×
1卷积块701-4之后的bn块和3
×
3卷积块701-5之后的bn块的输出的级联。npu的核在1
×
1卷积块701-6之后对来自relu块的输出执行3
×
3卷积块701-8以执行卷积,随后进行bn操作。npu的核在3
×
3卷积块701-8之后对来自通道连接块701-7和bn块的输出执行元素求和块701-9以进行求和,随后是relu操作。npu的核还在其他块或层执行其他操作并产生输出。工作流703a可以基于块或层,并且由npu以直接的方式执行。在一些实施例中,工作流703a的第一行中的操作,例如,卷积,可以由卷积单元(例如,图4的卷积单元4030)执行。工作流703a的第二行中的操作,例如bn操作、relu操作、元素操作和池化,可以由池化单元(例如图4的池化单元4032)、dp(例如图4的dp 4024)、元素操作单元(例如,图4的元素操作单元4026)等执行。工作流703a的第三行中的操作,例如,连接,可以由dma单元(例如,图4的dma单元408a)执行。
69.在工作流703b,npu核可以将bn操作和relu操作与卷积或元素操作相融合。例如,卷积的结果可以被传递到元素操作单元以进行进一步处理,例如,bn或其他元素操作,而无需将其存储在本地存储器中。如图7所示,在工作流703b中,npu的核可以串联执行7
×
7卷积、3
×
3池化、1
×
1卷积、3
×
3卷积、1
×
1卷积、连接、3
×
3卷积、元素操作等。因此,与工作流703a相比,工作流703b可以减少用于执行神经网络701的时间。
70.在工作流703c中,npu的核可以将卷积(例如,在3
×
3卷积块701-8的卷积)与元素操作(例如,元素求和块701-9的元素操作)聚合。例如,卷积的结果可以传递到元素操作单元进行元素操作,而不需要将其存储在本地存储器中。如图所7示,在工作流703c中,npu的核可以串联执行7
×
7卷积、3
×
3池化、1
×
1卷积、3
×
3卷积、1
×
1卷积、连接、3
×
3卷积等。因此,与工作流703b相比,工作流703c可以进一步减少用于执行神经网络701的时间。
71.在工作流703d,如果卷积和连接彼此不依赖并且它们之间没有资源冲突,npu的核可以并行地执行卷积(例如,在1
×
1卷积块701-6处的卷积)和连接(例如,通道连接块701-7的连接)。如图7所示,在工作流703d,npu的核可以串联执行7
×
7卷积、3
×
3池化、1
×
1卷积、3
×
3卷积、并行执行的1
×
1卷积和连接、3
×
3卷积等。因此,与工作流703c相比,工作流703d可以进一步减少用于执行神经网络701的时间。
72.在工作流703e,npu的核至少可以部分地与在它之前的卷积(例如,7
×
7卷积块701-2的卷积)或在它之后的卷积(例如,1
×
1卷积块701-4的卷积)并行地执行池化(例如,在3
×
3池化块701-3处的池化)。例如,npu的核(例如,定序器)可以在池化之前监视卷积的
结果。如果已经完成一部分结果,池化单元可以对该部分结果执行池化操作。npu的核还可以在卷积之前监视池化结果。如果已经完成一部分结果,则卷积单元可以对该部分结果执行卷积操作。如图7所示,在工作流703e中,npu的核可以串联执行:部分地与3
×
3池化并行的7
×
7卷积、部分地与1
×
1卷积并行的3
×
3池化的剩余部分、1
×
1卷积的剩余部分、3
×
3卷积、与连接并行的1
×
1卷积、3
×
3卷积、等等。因此,与工作流703d相比,工作流703e可进一步减少用于执行神经网络701的时间。
73.图8是根据本公开的一些实施例的npu的核中的示例性的数据移动的示意图。npu的核可以包括本地存储器和集线器系统。本地存储器可以为多个操作存储数据。集线器系统可以同时支持多个数据流。例如,数据移动800可以通过图4的dp 4024、ewop单元4026、卷积单元4030、池化单元4032、dma单元408a、本地存储器4022和npu的核402a的集线器系统来完成。
74.如图8所示,npu的核中可以存在多个数据流,例如,卷积读取数据流801、池化和存储读取数据流802、输入引擎写入数据流803等。卷积读取数据流801可以包括一个或多个组件,诸如数据路径(例如,图4的dp 4024)、卷积单元(例如,图4的卷积单元4030)和ewop单元(例如,图4的ewop单元4026)。因此,卷积读取数据流801可以包括从本地存储器806a-806d(例如,图4的本地存储器4022)读取的多个数据,诸如权重数据(wgt)、用于激活的数据(act)和用于元素操作的数据(elm)。池化和存储读取数据流802可以包括一个或多个组件,例如池化单元(例如,图4的池化单元4032)、dma单元或xdma单元(例如,图4的dma单元408a)等。因此,池化和存储读取数据流802可以包括从本地存储器806a-806d(例如,图4的本地存储器4022)读取的多个数据,诸如用于池化的数据(pool)、输出数据(out)、跨核读取的数据(xdmar)等。输入引擎写入数据流803可以涉及一个或多个组件,例如写入控制单元或后端(wcu/be)等。例如,写入控制单元或后端可以包括用于卷积引擎的wcu或be(例如,图4的卷积单元4030)、池化单元(例如,图4的池化单元4032)、dma单元(例如,图4的dma单元408a)等。池化和存储读取数据流802可以包括要写入到本地存储器806a-806d(例如,图4的本地存储器4022)的多个数据,诸如卷积写数据(convw)、池化写数据(poolw)、输入数据(in)(例如,来自主机单元的输入数据)、跨核写数据(xdmaw)等。
75.集线器系统(例如,图4的核402a的集线器系统)可以协调从或者到本地存储器(例如,本地存储器806a至806d)的多个数据流,并形成多个读数据组和写数据组。如图所示,在集线器系统协调之后,数据移动800可以包括读数据组804a至804f和写数据组805a至805b。读数据组804a、804c、804d和804f中的每一个可以包括一个或多个权重、激活数据等。读数据组804b可以包括用于按元素操作和池化等的数据。写数据组805a可以包括一个或多个卷积写数据、池化写数据、输入数据等。读数据组804e可以包括用于元素操作和池化的数据、dma读取的数据、跨核读数据等。写数据组805b可以包括一个或多个卷积写数据、池化写数据、跨核写数据(xdmaw)等。
76.在一些实施例中,通过集线器系统与其他组件的合作,np的核可以利用数据局部性和通道合并,并提供良好平衡的带宽、计算或并行多任务解决方案。
77.图9是根据本公开的一些实施例的npu的核中的各个处理单元之间的工作流的示意图。
78.如图9所示,定序器(例如,图4的定序器4028)可以从指令缓冲器中检索指令,并将
该指令分发给npu的核(例如,图4的核402a)的处理单元。在一些实施例中,定序器还可以在发出指令之前修改它们。修改后的指令可以分别被发送到用于卷积操作的卷积单元(例如,图4的卷积单元4030)、用于池化操作的池化单元(例如,图4的池化单元4032)和用于数据传输的dma单元(例如,图4的dma单元408a)。
79.例如,卷积单元可以与定序器、矩阵乘法数据路径(例如,图4的数据路径4024)和元素操作单元(例如,图4的元素操作单元4026)耦合,并且被配置成指示矩阵乘法数据路径和元素操作单元执行卷积操作。在一些实施例中,卷积单元还可以向本地存储器(例如,本地存储器4022)发送命令,以向数据路径发送激活数据和权重数据,以执行卷积操作。例如,卷积单元可以将权重数据的读取地址发送到本地存储器,并通过dma单元和数据结构(data fabric)和仲裁子系统从本地存储器中检索相应的权重数据。然后,数据路径可以对激活数据和权重数据执行矩阵乘法。可以理解,一个以上的数据路径可以一起工作以产生矩阵乘法的结果。如图9所示,矩阵乘法可由四条数据路径执行。元素操作单元可以进一步处理矩阵相乘的结果以生成作为卷积输出的特征映射。特征映射可以经由例如dma单元临时存储到本地存储器。
80.池化单元还可以包括插值单元、池化数据路径等,并用于执行池化操作。在一些实施例中,插值单元可以在池化之前对特征映射执行插值(例如,双线性插值)。然后,可根据池化尺寸将插值后的特征映射进行池化,以生成池化输出。例如,可以在特征映射上执行最大池化或平均池化。池化输出也可以经由例如dma单元临时存储到本地存储器。
81.除了在这些处理单元和npu的核之间传输矩阵、特征映射等之外,dma单元还可以重塑、打包和合并数据。在一些实施例中,dma单元可以将图像变换成矩阵,反之亦然。例如,图像形式的数据可用于卷积运算,矩阵形式的数据可用于矩阵运算(例如,矩阵-矩阵乘法)。
82.下面表格1进一步给出了npu 400的关键特性列表。
83.表格1
[0084][0085]
图10示出了根据本公开的一些实施例的npu 400的示例性指令。
[0086]
如上文所述,指令可以被发送到卷积单元、池化单元和dma单元,以使这些单元执行神经网络任务的各种操作。如图10所示,指令可以存储在指令缓冲器中,包括但不限于“lmcpy”、“conv”、“pool”、“matmul”、“trans”、“br”、“roi”、“interp”、“sop”和“vop”。指令缓冲器中的指令可以通过指向指令地址的指针来定位。例如,指向指令的地址的指针可以基于程序计数器来确定。程序计数器可以被初始化并且包括下一条指令的地址。在图10中,程序计数器的起始值被初始化为指令“lmcpy”的起始地址。当一条指令被执行时,该程序计数器指向下一条指令。在一些实施例中,程序计数器以设定距离(对应代码中的labeldistance)跳转到下一条指令。
[0087]
指令“lmcpy”是本地内存复制指令,可用于执行本地内存复制操作。例如,指令“lmcpy”使dma单元从读取地址复制块数据并将块数据发送到写入地址。
[0088]
指令“conv”是卷积指令,可以用于指示卷积单元执行卷积操作。指令“conv”可包括一个修改标志字段,允许对指令的各个字段进行在线修改以运行时绑定和控制。修改标志字段可以是一比特位。
[0089]
指令“pool”是一个池指令,可以用来指示池化单元执行池化操作。指令“pool”可以包括等待标志字段,指示当前层的池化操作必须等待指定层的输出才能继续。因此,等待标志字段可包括等待标志和指定层。换句话说,等待标志字段可以指定层之间的数据依赖关系。如果在等待标志字段中没有设置等待标志,则意味着与该指令相关联的层可以与在等待标志字段中指定的层并行执行。
[0090]
指令“matmul”是矩阵乘法指令,可以用于指示矩阵乘法数据路径执行矩阵乘法。
[0091]
指令“trans”是变换指令,可以用来指示dma单元将图像变换为矩阵,反之亦然。
[0092]
指令“br”是分支指令,可以用来修改程序计数器以指向下一条指令的指定地址。在一些实施例中,指令“br”可以包括同步字段以协调不同核中的任务。同步字段可以是一比特位字段,且它还可被称为屏障标志或同步标志。在一些实施例中,当核完成其任务时,核可以设置(assert)同步字段以通知npu任务已经完成。然后核被挂起,直到其他核也完成它们的任务并被分配一个新的任务。因此,可以将一个神经网络任务划分并分配给不同的核进行并行计算。
[0093]
指令“roi”是区域设置指令,可用于指示感兴趣区域(roi)。在一些实施例中,可以确定用于池化的感兴趣区域以提高推理的准确性。指令“roi”可以指定至少一个roi和该至少一个roi的数目的坐标。roi的坐标可以包括roi的四个角的四对坐标。
[0094]
指令“interp”是插值指令,并且可以用于池化单元,以便在特征映射上执行插值。例如,插值可以是双线性插值。
[0095]
指令“sop”是标量运算指令,可用于执行标量运算。例如,可以执行标量运算以基于当前程序计数器和标签距离来确定分支程序计数器。在一些实施例中,指令“sop”可以由分支/标量单元执行,并且标量操作结果可以存储在标量寄存器文件中,如图9所示。
[0096]
指令“vop”是向量指令,可用于执行向量运算。例如,指令“vop”可以使元素操作单元执行向量操作,例如加法、向量和向量的乘法等。在一些实施例中,指令“vop”还可以包括“结束”字段,以指示神经网络任务完成或神经网络任务的各种操作在此结束。
[0097]
由于npu 400的指令被设计为优化提供额外的选项和标志,因此可以获得高质量的结果,而无需经历繁琐且通常效果较差的过程(例如数据库搜索和低级程序集调优)。
[0098]
图11是根据本公开的一些实施例的由处理单元实现的示例性方法的流程图。在一些实施例中,方法1100可以由图4、图5a或图5c中的npu 400执行。在一些实施例中,方法1100可以由包含在计算机可读介质中的计算机程序产品来实现,该计算机程序产品包括由计算机(例如,图4、图5a或图5c中的npu 400)执行的诸如程序代码的计算机可执行指令。
[0099]
在一些实施例中,处理单元可以包括命令解析器(例如,图4的命令解析器406),用于分配命令和计算任务;以及至少一个核(例如,图4的核402a、402b、402c或402d),其与命令解析器耦合通信并被配置为处理所分配的计算任务。每个核可以包括卷积单元(例如,图4的卷积单元4030)、池化单元(例如,图4的池化单元4032)、至少一个操作单元(例如,图4的操作单元4020)和定序器(例如,图4的定序器4028)。所述定序器可与所述卷积单元、所述池化单元和所述至少一个操作单元耦合通信,并被配置为将所分配的计算任务的指令分配给所述卷积单元、所述池化单元和所述至少一个操作单元以供执行。
[0100]
在步骤1102,卷积单元从至少一个操作单元的本地存储器(例如,图4的本地存储器4022)读取数据。
[0101]
在步骤1104,卷积单元对数据执行卷积操作以生成特征映射。例如,卷积单元可以通过卷积指令执行卷积操作以生成特征映射。在一些实施例中,卷积指令可以包括修改标志字段,修改标志字段与运行时绑定和控制的卷积指令的各个字段的在线修改相关联。
[0102]
在步骤1106,池化单元对特征映射执行池化操作。在一些实施例中,池化单元可以包括插值单元和池化数据路径。插值单元可以对特征映射进行插值(例如,通过执行插值指
令)。池化数据路径可以对插值后的特征映射执行池化操作(例如,通过执行池化指令)。池化单元可以确定特征映射上的感兴趣区域(例如,通过执行区域设置指令)。
[0103]
在一些实施例中,至少一个操作单元可以包括矩阵乘法数据路径(例如,图4的数据路径4024)和ewop单元(例如,图4的ewop单元4026)。矩阵乘法数据路径可以对来自卷积单元的卷积数据执行矩阵乘法操作(例如,通过执行矩阵乘法指令)以生成中间数据,并且ewop单元可以执行ewop(例如,通过执行向量指令)以基于中间数据生成特征映射。
[0104]
在一些实施例中,定序器可以监视神经网络任务的执行,并将神经网络任务的多个子任务并行化。例如,定序器可以使用分支指令的同步字段来协调神经网络任务在多个不同核中的多个子任务。
[0105]
在一些实施例中,每个核可进一步包括dma单元(例如,图4的dma单元408a)。dma单元可以在每个核内以及在至少一个核之间传送数据。例如,通过本地内存复制指令,dma单元可在核内传输数据。在一些实施例中,dma单元可以与卷积单元、池化单元或至少一个操作单元的计算并行地输入或输出数据(例如,通过执行复制指令)。在一些实施例中,dma单元可以在图像和矩阵两种形式之间变换数据(例如,通过执行变换指令)。
[0106]
在一些实施例中,池化单元的至少一部分的池化操作可与卷积单元的卷积操作并行地执行。例如,通过池化指令的等待标志字段,池化单元的至少一部分池化操作与卷积单元的卷积操作并行地执行。
[0107]
在一些实施例中,每个核可以进一步包括标量单元和标量寄存器文件。标量单元可以执行标量操作(例如,通过执行标量运算指令)并将标量操作的结果写入标量寄存器文件。
[0108]
本公开的实施例可应用于许多产品、环境和场景。例如,本公开的一些实施例可应用于ali-npu(例如,汉光npu)、ali-cloud、ali pim-ai(用于ai的处理器存储器)、ali-dpu(数据库加速单元)、ali-ai平台、gpu、张量处理单元(tpu)等。
[0109]
可以使用以下语句进一步描述实施例:
[0110]
1、一种由处理单元实现的方法,所述处理单元包括命令解析器和至少一个核,所述命令解析器用于分配命令和计算任务,所述至少一个核与所述命令解析器耦合通信并用于处理所分配的计算任务,每个核包括卷积单元、池化单元、至少一个操作单元和定序器,所述定序器与所述卷积单元、所述池化单元和所述至少一个操作单元耦合通信并用于将所分配的计算任务的指令分配给所述卷积单元、池化单元和所述至少一个操作单元以供执行,所述方法包括:
[0111]
由所述卷积单元从所述至少一个操作单元的本地存储器读取数据;
[0112]
由所述卷积单元对所述数据执行卷积操作以生成特征映射;和
[0113]
由所述池化单元对所述特征映射执行池化操作。
[0114]
2、根据编号1所述的方法,其中,所述至少一个操作单元包括:矩阵乘法数据路径(dp)和元素操作单元(ewop),所述方法还包括:
[0115]
通过所述矩阵乘法数据路径对来自所述卷积单元的卷积数据执行矩阵乘法运算,以生成中间数据;和
[0116]
由所述元素操作单元执行ewop以基于所述中间数据生成特征映射。
[0117]
3、根据编号1或2所述的方法,其中,所述池化单元包括:插值单元和池化数据路
径,所述方法还包括:
[0118]
由插值单元对所述特征映射进行插值;和
[0119]
由池化数据路径对插值后的特征映射执行池化操作。
[0120]
4、根据编号3所述的方法,还包括:
[0121]
由池化单元确定特征映射上的感兴趣区域。
[0122]
5、根据编号1至4任一项所述的方法,还包括:
[0123]
由定序器监视神经网络任务的执行;和
[0124]
由所述定序器并行化所述神经网络任务的多个子任务。
[0125]
6、根据编号1至5所述的方法,其中,每个核还包括:直接存储器访问单元,并且所述方法还包括:
[0126]
由所述直接存储器访问单元在每个核内以及在所述至少一个核之间传送数据。
[0127]
7、根据编号6所述的方法,还包括:由所述直接存储器访问单元执行的输入输出数据与卷积单元、池化单元或至少一个操作单元的计算并行。
[0128]
8、根据编号6或7所述的方法,还包括:
[0129]
由直接存储器访问单元在图像和矩阵两种形式的数据之间进行变换。
[0130]
9、根据编号1至8任一项所述的方法,还包括:
[0131]
由池化单元将至少一部分的池化操作与所述卷积单元的卷积操作并行执行。
[0132]
10、根据编号1至9任一项所述的方法,其中,每个核还包括:标量单元和标量寄存器文件,所述方法还包括:
[0133]
由标量单元执行标量运算;和
[0134]
由标量单元在标量寄存器文件中写入标量运算的结果。
[0135]
11、一种非暂时性计算机可读存储介质,用于存储一组指令,所述一组指令可由至少一个处理单元执行以使计算机执行方法,所述处理单元包括命令解析器和至少一个核,所述命令解析器用于分配命令和计算任务,所述至少一个核与所述命令解析器耦合通信并用于处理所分配的计算任务,每个核包括卷积单元、池化单元、至少一个操作单元和定序器,所述定序器与所述卷积单元、所述池化单元和所述至少一个操作单元耦合通信并用于将所分配的计算任务的指令分配给所述卷积单元、所述池化单元和所述至少一个操作单元以供执行,所述方法包括:
[0136]
由所述卷积单元从所述至少一个操作单元的本地存储器读取数据;
[0137]
由所述卷积单元对所述数据执行卷积操作以生成特征映射;和
[0138]
由所述池化单元对所述特征映射执行池化操作。
[0139]
12、根据编号11所述的非暂时性计算机可读存储介质,其中,所述至少一个操作单元包括:矩阵乘法数据路径(dp)和元素操作单元(ewop),并且所述一组指令由所述至少一个处理单元执行以使所述计算机执行:
[0140]
通过矩阵乘法数据路径对来自所述卷积单元的卷积数据执行矩阵乘法运算,以生成中间数据;和
[0141]
由元素操作单元执行ewop以基于所述中间数据生成特征映射。
[0142]
13、根据编号11或12所述的非暂时性计算机可读存储介质,其中,所述池化单元包括插值单元和池化数据路径,所述一组指令被所述至少一个处理单元执行,以使所述计算
机执行:
[0143]
由插值单元对特征映射进行插值;和
[0144]
由池化数据路径对插值后的特征映射执行池化操作。
[0145]
14、根据编号13所述的非暂时性计算机可读存储介质,其中,所述一组指令由所述至少一个处理单元执行,以使所述计算机执行:
[0146]
由池化单元确定特征映射上的感兴趣区域。
[0147]
15、根据编号11至14任一项所述的非暂时性计算机可读存储介质,所述一组指令由所述至少一个处理单元执行,以使所述计算机执行:
[0148]
由定序器监视神经网络任务的执行;和
[0149]
由定序器并行化所述神经网络任务的多个子任务。
[0150]
16、根据编号11至15任一项所述的非暂时性计算机可读存储介质,其中,每个核还包括直接存储器访问单元,并且所述一组指令由所述至少一个处理单元执行,以使所述计算机执行:
[0151]
由所述直接存储器访问单元在每个核内以及在所述至少一个核之间传送数据。
[0152]
17、根据编号16所述的非暂时性计算机可读存储介质,其中,所述一组指令由所述至少一个处理单元执行,以使所述计算机执行:
[0153]
由所述直接存储器访问单元执行的输入输出数据与卷积单元、池化单元或至少一个操作单元的计算并行。
[0154]
18、根据编号17所述的非暂时性计算机可读存储介质,其中,所述一组指令由所述至少一个处理单元执行,以使所述计算机执行:
[0155]
由直接存储器访问单元在图像和矩阵两种形式的数据之间进行变换。
[0156]
19、根据编号11至18任一项所述的非暂时性计算机可读存储介质,其中,所述一组指令由所述至少一个处理单元执行,以使所述计算机执行:
[0157]
由所述池化单元将至少一部分的池化操作与所述卷积单元的卷积操作并行执行。
[0158]
20、根据编号11至19任一项所述的非暂时性计算机可读存储介质,其中,每个核还包括标量单元和标量寄存器文件,所述一组指令由所述至少一个处理单元执行,以使所述计算机执行:
[0159]
由标量单元执行标量运算;和
[0160]
由标量单元在标量寄存器文件中写入标量运算的结果。
[0161]
21、一种处理单元,包括:
[0162]
命令解析器,用于分配命令和计算任务;和
[0163]
与所述命令解析器耦合通信的至少一个核,用于处理所分配的计算任务,每个核包括:
[0164]
卷积单元,其具有通过卷积指令执行卷积操作以生成特征映射的电路;
[0165]
池化单元,其具有通过池化指令对所述特征映射执行池化操作的电路;
[0166]
至少一个操作单元,其具有处理数据的电路;和
[0167]
定序器,与所述卷积单元、所述池化单元和所述至少一个操作单元耦合通信,并且具有将所分配的计算任务的指令分配给所述卷积单元、所述池化单元和所述至少一个操作单元以执行的电路。
[0168]
22、根据编号21所述的处理单元,其中,所述至少一个操作单元包括:
[0169]
本地存储器,用于存储数据;
[0170]
矩阵乘法数据路径,其具有通过矩阵乘法指令执行矩阵乘法操作的电路;和
[0171]
元素操作单元,其具有通过向量指令执行ewop的电路。
[0172]
23、根据编号22所述的处理单元,其中,所述矩阵乘法数据路径具有通过矩阵乘法指令对来自所述卷积单元的卷积数据执行矩阵乘法运算,以生成中间数据的电路;所述ewop单元具有通过向量指令基于中间数据生成特征映射的电路。
[0173]
24、根据编号22或23所述的处理单元,其中,每个核还包括:
[0174]
集线器单元,具有在所述卷积单元、所述池化单元、所述至少一个操作单元和所述本地存储器之间传送与所述神经网络任务相关联的读取数据和写入数据的电路。
[0175]
25、根据编号22至24任一项所述的处理单元,其中,向量指令还包括:结束字段,用于指示神经网络任务已经完成。
[0176]
26、根据编号21至25任一项所述的处理单元,其中,池化单元还包括:
[0177]
插值单元,具有通过插值指令对特征映射进行插值的电路;和
[0178]
池化数据路径,具有通过池化指令对插值后的特征映射执行池化操作的电路。
[0179]
27、根据编号21至26任一项所述的处理单元,其中,所述定序器还具有用于监视神经网络任务的执行,并使用分支指令的同步字段来协调分布在多个不同核中的神经网络任务的多个子任务的电路。
[0180]
28、根据编号21至27任一项所述的处理单元,其中,每个核还包括:
[0181]
与所述定序器耦合通信的指令缓冲器。
[0182]
29、根据编号21至28任一项所述的处理单元,其中,每个核还包括:
[0183]
直接存储器访问单元,其具有通过本地内存复制指令在核内传输数据的电路。
[0184]
30、根据编号29所述的处理单元,其中,所述直接存储器访问单元具有通过复制指令与所述卷积单元、所述池化单元或所述至少一个操作单元的计算并行地输入或输出数据的电路。
[0185]
31、根据编号29或30任一项所述的处理单元,其中,所述直接存储器访问单元具有用于在图像和矩阵两种形式的数据之间进行变换的电路。
[0186]
32、根据编号21至31任一项所述的处理单元,其中,所述池化单元具有通过所述池化指令的等待标志字段将至少一部分的池化操作与所述卷积单元的卷积操作并行的电路。
[0187]
33、根据编号21至32任一项所述的处理单元,其中,所述池化单元具有用于通过区域设置指令来确定所述特征映射的感兴趣区域的电路。
[0188]
34、根据编号21至33任一项所述的处理单元,其中,每个核进一步包括标量单元和标量寄存器文件,所述标量单元具有通过标量运算指令执行标量运算并将标量运算结果写入到变量寄存器文件的电路。
[0189]
35、根据编号21至34任一项所述的处理单元,其中,所述卷积指令还包括:与运行时绑定和控制的卷积指令中的字段的在线修改相关联的修改标志字段。
[0190]
上文在方法的步骤或过程的通用上下文中描述了各种示例性的实施例,一方面,这些方法的步骤或过程可以由包含在计算机可读介质中的计算机程序产品来实现,该计算机程序产品包括由网络环境中的计算机执行的诸如程序代码的计算机可执行指令。计算机
可读介质可以包括可移动和不可移动存储设备,包括但不限于只读存储器(rom)、随机存取存储器(ram)、光盘、数字通用盘(dvd)等。通常,程序模块可以包括执行特定任务或实现特定抽象数据类型的例程、程序、对象、组件、数据结构等。计算机可执行指令、相关数据结构和程序模块表示用于执行本文所公开的方法的步骤的程序代码的示例。这种可执行指令或相关数据结构的特定序列代表用于实现此类步骤或过程中描述的功能的相应动作的示例。
[0191]
本公开为了说明的目的提供上述描述。它不是穷尽性的,并且不限于所公开的精确形式或实施例。通过考虑所公开的实施例的说明书和实践,对实施例的修改和改编将是显而易见的。例如,所描述的实现包括硬件,但是与本公开一致的系统和方法可以用硬件和软件来实现。此外,虽然某些组件已经被描述为彼此耦合,但这些组件可以彼此集成或以任何合适的方式部署。
[0192]
此外,虽然这里已经描述了说明性的实施例,但范围包括在本公开基础上具有等效元素、修改、省略、组合(例如,将不同实施例的各个方面组合)、自适应或改编的任何和所有实施例。权利要求中的元素将基于权利要求中使用的语言广义地解释,并且不限于在本说明书中或申请过程中描述的示例,这些示例将被解释为非排他性的。此外,可以以任何方式修改所公开的方法的步骤,包括重新排序步骤和/或插入或删除步骤。
[0193]
本公开的特征和优点基于详细说明书中是显而易见的,因此,所附权利要求书旨在覆盖落入本公开的实质和范围内的所有系统和方法。如本文所用,不定冠词“一个”和“一个”表示“一个或多个”。类似地,复数术语的使用不一定表示多个,除非它在给定的上下文中是明确的。此外,由于通过研究本公开,容易发生许多修改和变化,因此不希望将本公开限制于所示和所描述的确切结构和操作,因此,所有适当的修改和等同物均落入本公开的保护范围之内。
[0194]
如本文所用,除非另有特别说明,术语“或”包括所有可能的组合,除非在不可行的情况下。例如,如果声明组件可以包括a或b,则除非另有具体说明或不可行,否则组件可以包括a、b、或a和b。作为第二示例,如果声明组件可以包括a、b或c,则除非另有具体说明或不可行,否则组件可以包括a、b、c、a和b、a和c、b和c、或a和b和c。
[0195]
从考虑本文公开的实施例的说明和实践来看,其他实施例将是显而易见的。本说明书和示例仅被视为示例,所公开的实施例的真实范围和实质由权利要求书指示。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1