将情绪相关元数据标注到多媒体文件的方法和装置与流程
将情绪相关元数据标注到多媒体文件的方法和装置
背景技术:
1.本发明在一些实施例中涉及媒体技术,并且更具体地、但不限于涉及电影标注软件。
2.和等流媒体和视频点播平台的推出,为电影业提供了向目标受众交付产品的新工具。因此,可供用户使用的在线视频内容急剧增加。这样的结果之一是观看者越来越难以从丰富的内容中发现与个人喜好相关的内容。传统的视频搜索工具只能通过通用指标来查找电影内容,无法全面地反映内容。此外,主观方面,制作电影的压缩版本的传统方法通常需要耗费大量的人力。这些方法通常也耗费大量时间,而且不一定能在用户之间正常转换。
技术实现要素:
3.本发明的目的是提供用于丰富电影元数据的装置、系统和方法。本发明的目的是提供创建有意义的、语义丰富的电影场景描述的装置、系统和方法。本发明的目的是提供用于高效地生成多媒体对象的压缩版本的装置、系统和方法。本发明的目的是提供用于创建电影的简约形式的装置、系统和方法,保持电影的整体色调和基本叙述。本发明的目的是提供用于根据更全面表示内容的指标来搜索和分类多媒体内容的装置、系统和方法。本发明的目的是为了促进观看者根据特定兴趣、色调、模式和/或情绪选择的优选多媒体对象类型的装置、系统和方法。
4.前述和其它目的通过独立权利要求的特征实现。其它实现方式在从属权利要求、具体说明和附图中显而易见。
5.根据本发明的第一方面,提供了一种用于概述具有主要叙述的多媒体对象的系统,包括:处理器,执行可读指令从而进行以下操作:执行数据分析以在所述多媒体对象的多个场景中的每个场景中标识所述场景中指示的一个或多个场景相关情绪;生成将所述多个场景中的每个场景与相应的一个或多个场景相关情绪关联的知识图;使用所述知识图计算多个分数,每个分数指示所述多个场景中的一个场景对传达所述主要叙述的相对重要性;根据所述多个分数选择所述多个场景的子集;根据所述子集生成所述多媒体对象的摘要。
6.根据本发明的第二方面,提供了一种用于概述具有主要叙述的多媒体对象的方法,包括:执行数据分析以在所述多媒体对象的多个场景中的每个场景中标识所述场景中指示的一个或多个场景相关情绪;生成将所述多个场景中的每个场景与相应的一个或多个场景相关情绪关联的知识图;使用所述知识图计算多个分数,每个分数指示所述多个场景中的一个场景对传达所述主要叙述的相对重要性;根据所述多个分数选择所述多个场景的子集;根据所述子集生成所述多媒体对象的摘要。
7.在本发明各个方面的实现方式中,所述数据分析包括对所述多媒体对象的预处理,所述预处理包括从所述多媒体对象中提取以下中的至少一个:视频文件;字幕文件;详细描述所述多媒体对象的章节的起始时间的章节文本文件;演员语音和非语音部分的音频
文件片段。
8.在本发明各个方面的可能实现方式中,所述数据分析包括:擦除描述所述多媒体对象的关联元数据;分析所述关联元数据以指示所述一个或多个场景相关情绪。
9.在本发明各个方面的可能实现方式中,所述数据分析包括根据场景本体实现语义提升以捕获所述多媒体对象的原始多媒体信息。
10.在本发明各个方面的可能实现方式中,所述数据分析包括与描述所述多媒体对象的特征的外部源互联。
11.在本发明各个方面的可能实现方式中,所述特征包括以下中的至少一个:所述多媒体对象的场景;所述多媒体对象场景中的活动;在所述多媒体对象中表演的演员;所述多媒体对象中描绘的人物。
12.在本发明各个方面的可能实现方式中,所述数据分析包括分析所述多媒体对象的描述性音频原声带以指示所述一个或多个场景相关情绪。
13.在本发明各个方面的可能实现方式中,所述数据分析包括从视觉情绪指示符中提取所述情绪,所述视觉情绪指示符包括以下中的至少一个:面部表情图像;身体姿势图像;情绪指示行为的视频序列。
14.在本发明各个方面的可能实现方式中,所述数据分析包括从听觉情绪指示符中提取所述情绪,所述听觉情绪指示符包括以下中的至少一个:表示音乐原声带的情绪;情绪暗示性发声指示符。
15.在本发明各个方面的可能实现方式中,所述数据分析包括从文本情绪指示符中提取所述情绪,所述文本情绪指示符包括以下中的至少一个:显式情绪描述符;暗示性情绪指示符。
16.除非另有定义,否则本文所用的所有技术和科学术语都具有与本发明普通技术人员公知的含义相同的含义。虽然与本文描述的方法和材料类似或等效的方法和材料可以用于本发明实施例的实践或测试,但下文描述了示例性方法和/或材料。如有冲突,以本说明书为准。此外,这些材料、方法和示例仅是说明性的,并不一定具有限制性。
附图说明
17.此处仅作为示例,结合附图描述了本发明的一些实施例。现在具体结合附图,需要强调的是所示的项目作为示例,为了说明性地讨论本发明的实施例。这样,根据附图说明,如何实践本发明实施例对本领域技术人员而言是显而易见的。
18.在附图中:
19.图1a为本发明一些实施例提供的可选的操作流程的示意性流程图;
20.图1b为本发明一些实施例提供的示例性系统的示意图;
21.图1c为本发明一些实施例提供的示例性系统的示意图;
22.图2为本发明一些实施例提供的示例性系统架构的示意图;
23.图3为本发明一些实施例提供的示例性系统架构的示意图;
24.图4为本发明一些实施例提供的示例性系统架构的示意图;
25.图5a为表示图4的示例性系统架构的各个方面的原理图;
26.图5b为表示图4的示例性系统架构的各个方面的原理图;
27.图6为本发明一些实施例提供的示例性系统架构的示意图;
28.图7为本发明一些实施例提供的示例性系统架构的示意图;
29.图8为本发明一些实施例提供的示例性系统架构的示意图;
30.图9为本发明一些实施例提供的示例性系统架构的示意图;
31.图10为本发明一些实施例提供的示例性系统架构的示意图;
32.图11为本发明一些实施例提供的示例性系统架构的示意图;
33.图12a为本发明一些实施例提供的示例性系统架构的示意图;
34.图12b为图12a的架构指示的场景的示意图。
具体实施方式
35.在详细解释本发明的至少一个实施例之前,应理解,本发明在应用时并不一定限于以下描述和/或附图和/或示例中阐述的组件和/或方法的构造和布置的细节。本发明具有其它实施例,或者能够以各种方式实践或执行。
36.本发明实施例包括一个或多个装置、一个或多个系统、一个或多个方法、一个或多个架构和/或一个或多个计算机程序产品。所述计算机程序产品可包括具有计算机可读程序指令的计算机可读存储介质,计算机可读程序指令使得处理器执行本发明的各方面。
37.所述计算机可读存储介质可以是能够保留和存储指令以供指令执行设备使用的有形设备。所述计算机可读存储介质可以为,但不限于,例如,电子存储设备、磁存储设备、光存储设备、电磁存储设备、半导体存储设备或上述设备的任意适当组合。
38.本文描述的计算机可读程序指令可以从计算机可读存储介质下载到相应的计算/处理设备,或者通过因特网、局域网、广域网和/或无线网络等网络下载到外部计算机或外部存储设备。
39.所述计算机可读程序指令可以完全在用户的计算机上执行,部分在用户的计算机上执行,作为独立的软件包执行,部分在用户的计算机上执行并且部分在远程计算机上执行,或者完全在远程计算机或服务器上执行。在最后的场景中,远程计算机可以通过任何类型的网络连接到用户的计算机,包括局域网(local area network,lan)或广域网(wide area network,wan),或者与外部计算机连接(例如,通过使用因特网服务提供商的因特网)。在部分实施例中,包括例如可编程逻辑电路、现场可编程门阵列(field-programmable gate array,fpga)或可编程逻辑阵列(programmable logic array,pla)等的电子电路可以通过利用所述计算机可读程序指令的状态信息来执行所述计算机可读程序指令,以定制电子电路,从而执行本发明的各方面。
40.本文结合根据本发明实施例的方法、装置(系统)和计算机程序产品的流程图说明和/或方框图来描述本发明的各方面。应理解,流程图和/或方框图的每个方框以及流程图说明和/或方框图中的方框的组合可以由计算机可读程序指令实现。
41.图中的流程图和框图阐述了本发明各个实施例提供的系统、方法以及计算机程序产品的可能实现方式的结构、功能以及操作。就此而言,流程图或框图中的每个方框可以表示模块、区段或指令的部分,包括用于实现指定逻辑功能的一个或多个可执行指令。在某些替代性实现方式中,方框中说明的功能可不按图中说明的顺序执行。例如,事实上,连续示出的两个方框可以几乎同时执行,或者有时候,方框可以按照相反的顺序执行,根据所涉及
的功能确定。还应注意的是,框图和/或流程图中的每个方框以及框图和/或流程图中的方框组合可以由基于专用硬件的系统执行,该系统执行特定的功能或动作,或者执行专用硬件和计算机指令的组合。
42.多媒体对象(如电影或视频)中的每个媒体片段可以具有描述在当前时刻对电影的感觉的特定情绪。本发明的各个方面可包括资源描述框架(resource description framework,rdf)架构等元数据模型,定义和开发所述元数据模型以作为视频内容知识图的基础。
43.本发明的各个方面可包括标注工具包、算法、流程、工具、接口和/或操作。在本发明的一些实施例中,一个或多个标注器可以负责填充语义模型中的可观察动作和情绪。标注器可以熟悉人物和情节。标注器可以试图根据活动和情绪来标记电影的部分内容。
44.情绪是电影的一个重要方面,它受各种因素的影响。情绪的标注可以基于不同的数据源,如背景音乐。电影分数最能反映制作团队的预期情绪,而不是人物或观看者的情绪。
45.决定以何种粒度来展示细节不是一件容易的事情。例如,在打架场景中,可以将场景中的每一拳标注为单独的活动,或者,也可以将电影的大部分片段标注为“人物x和y打架”。
46.本发明的方法和装置可以包括或涉及:结合具有视觉和/或音频情绪提示元数据的多媒体文件的标记;结合用于根据情绪对电影进行标注的装置;利用基于情绪的标注的特征;根据主要人物、情绪和/或相邻场景之间的元素的多样性,对场景和/或子场景的重要性进行评级;和/或存储基于情绪的标注作为知识图的结构化信息,例如在资源描述框架(resource description framework,rdf)三元组中。
47.本发明的实施例可用于利用语义技术的丰富性来丰富电影元数据和/或使用各种视频和/或音频处理技术创建有意义且语义丰富的电影场景描述。本发明可包括场景本体,在语义上定义概念,所述概念捕获电影中的时刻,例如基于情绪的时刻,以便使用有意义且语义丰富的表示捕获视频的原始多媒体信息。例如,语义信息可以从描述性音频原声带(如供视觉受损观众使用的原声带)和/或从电影字幕(如演员说的话)中提取。本发明可包括创建知识图,可查询知识图选择视频摘要。
48.在一些实施例中,基于情绪的标注方法可以利用知识图的结构化信息,所述知识图可以存储在可使用w3c标准化sparql协议和rdf查询语言(sparql)查询的rdf三元组中。语义模型或本体可以表示知识图中的数据,有助于知识图中可使用的各种特征、属性和资源标识电影相关场景。
49.本发明的实施例包括用于电影和/或视频标注的系统、架构、装置和方法。所述系统和架构可涉及所述方法的一个或多个步骤和/或可包括所述装置的一个或多个特征。
50.所述系统包括一种概述多媒体对象的系统。所述方法包括一种概述多媒体对象的方法。多媒体对象可以包括电影或任何其它合适的音频和/或视频对象,例如视频游戏或音乐文件。多媒体对象可以包括主要叙述。多媒体对象可以包括视频数据。多媒体对象可以包括音频数据。本文中所使用的术语“多媒体”是指一种或多种表达媒体,例如音频和/或视频。对多媒体对象进行概述可以包括生成多媒体对象的知识图。
51.系统可以包括用于执行用于实现所述方法的机器可读指令的处理器。系统可以包
括用于存储所述机器可读指令的存储器。可替换地和/或另外地,所述方法可以是手动的、自动的和/或部分自动的。
52.所述方法可以包括执行一个或多个数据分析,以在所述多媒体对象的一个或多个电影场景中标识所述场景中指示的一个或多个与场景相关的情绪和/或动作。所述方法可以包括生成知识图。知识图可以将一个或多个场景和相应的一个或多个场景相关情绪关联。
53.所述方法可以包括计算分数,所述分数指示一个或多个场景对于传达所述主要叙述的相对重要性。例如,得分低可以表示缺少主要人物和/或主题元素;可以表示和主题不强相关的叙述;和/或可以表示多余的主题元素,而得分高可以表示存在主要人物和/或主题元素;可以表示主要叙述;和/或可指示过渡性主题元素,其中,例如,叙述主题可以在主题高潮之前和之后发生重大转折。可以根据知识图的使用来进行计算。
54.所述方法可以包括根据所述分数选择所述场景的子集。所述子集可以包括较高评分的场景。所述方法可以包括根据所述子集生成所述多媒体对象的摘要。
55.所述方法可以包括对多媒体对象的预处理。分析可以包括对多媒体对象的预处理。预处理可以包括从多媒体对象中提取存储的数据。存储的数据可以包括一个或多个视频文件、字幕文件、详细描述多媒体对象的章节的起始时间的章节文本文件、演员语音和/或非语音部分的音频文件片段和/或任何其它合适的数据源。预处理可以为分析提供部分或全部信息。预处理可以提供技术改进,更丰富的场景特征指示符有助于检测关键情绪,以及与对象摘要相关的其它关键特征,例如动作和/或活动。本文中所使用的术语“活动”是指观看者可以观察到在多媒体对象中发生的事情。
56.分析可以包括擦除关联元数据。关联元数据可以描述多媒体对象。存储的数据可以包括关联元数据。关联元数据可以为分析提供部分或全部信息。包括关联元数据可以通过生成没有记录或轻易从其它存储的数据文件中提取的情绪相关信息,并且不需要根据个人用户的主观输入来提供改进。
57.分析可包括使用语义网络系统,使用现有和/或新颖的词汇表、域特定本体和/或万维网联盟推荐的rdf、rdfs、owl、r2rml和/或sparql等技术,将结构化和/或半结构化信息转换为关联数据,例如关联开放数据。分析可以包括实现语义提升。语义提升可以捕获多媒体对象的原始多媒体信息。语义提升可以遵循场景本体。语义提升可用于以语义方式表示视频内容和/或支持用户分析。语义提升可以通过以有意义和语义丰富的方式捕获多媒体对象的原始多媒体信息来提供改进,对于不同的人和/或机器阅读器,例如,在情绪检测和/或对象摘要方面,多媒体对象的原始多媒体信息可以不是可转换的。场景本体可有助于知识图具有语义丰富和/或机器可互操作性质。场景本体可有助于知识图全面描述多媒体对象的内容。
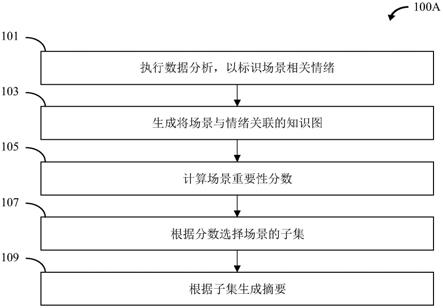
58.所述方法可以包括关联数据。所述方法可以包括发布数据,例如在互联网上发布数据。所述方法可以包括互联。所述方法可以包括将数据源之间的数据互联。关联数据可以配置为便于通过语义浏览器访问。关联数据可有助于通过资源描述框架(resource description framework,rdf)关联在数据源之间进行导航。数据源可以包括描述多媒体对象的特征的外部源。数据源可以包括存储的数据。互联可以改进知识图,使其外部信息的语义更丰富。
59.所描述的多媒体对象特征可以包括以下至少一个的一个或多个特征或属性:所述多媒体对象的一个或多个场景;所述多媒体对象场景中的活动;在所述多媒体对象中表演的演员;和/或所述多媒体对象中描绘的人物。在分析中包括特征可以通过提供语义丰富、可全面描述多媒体对象的内容和/或可以生成可靠的多媒体对象摘要的知识图来进行改进,对于关键叙述也适用。
60.存储的数据可以包括多媒体对象的描述性音频原声带。存储的数据可以包括描述性音频原声带的元素。原声带可以在更直接表示多媒体对象的创作者想表达的情绪方面进行改进,而不是仅仅依靠主观用户输入。
61.分析可以包括从视觉情绪指示符中提取情绪。视觉指示符可以包括面部表情图像、身体姿势图像和/或情绪指示行为的视频序列。所述视觉情绪指示符可以通过生成其它来源无法提供的丰富的社交和/情绪信息来进行改进,从而生成语义丰富的知识图,所述知识图可以全面描述多媒体对象的内容,和/或可生成可靠的多媒体对象摘要,对于关键叙述也适用。
62.所述分析可以包括从听觉情绪指示符(如指示情绪的音乐原声带和/或指示情绪的声音指示符)中提取情绪。听觉情绪指示符可以通过生成无法从其它来源获得的丰富的社交和/情绪信息来进行改进,从而生成语义丰富的知识图,所述知识图全面描述多媒体对象的内容,并生成可靠的多媒体对象摘要,对于关键叙述也适用。
63.分析可以包括从文本情绪指示符(如显式情绪描述符和/或暗示性情绪指示符)中提取情绪。这些文本情绪指示符可以通过生成在其它方面不明显的情绪信息来进行改进,从而生成语义丰富的知识图,该知识图全面描述多媒体对象的内容,并且可以生成适用于关键叙述的可靠摘要。
64.所述方法可以包括将电影划分成分量场景的方法。所述场景可以包括一个或多个动作和/或活动。所述方法可以包括标记所述分量场景中的一个或多个场景。可以根据检测到的一个或多个场景中固定的情绪进行标记。
65.如上所述,本发明的系统和架构可涉及所述方法的一个或多个步骤和/或可包括所述装置的一个或多个特征。所述架构可以包括所述系统的一个或多个特征。本发明的方法可以包括并且本发明的系统可以涉及对多媒体对象进行标注和/或概述的方法。本文中所使用的术语“多媒体”是指一种或多种表达媒体,例如音频和/或视频。所述方法的一个或多个步骤可以是手动的、自动的和/或部分自动的。所述方法可以包括一个或多个机器学习过程。
66.参考图1a,图1a示出了示例性多媒体对象概述过程100a。所述方法可以包括概述过程100a。
67.多媒体对象可以包括一个或多个电影或任何其它合适的音频和/或视频对象,例如视频游戏或音乐文件。多媒体对象可以包括主要叙述。多媒体对象可以包括视频数据。多媒体对象可以包括音频数据。对多媒体对象进行概述可以包括生成多媒体对象的一个或多个知识图。
68.过程100a可以从步骤101开始。在步骤101中,可以执行一个或多个数据分析。所述方法可以包括执行数据分析,例如在步骤101中所描述。数据分析可以在所述多媒体对象的一个或多个电影场景中标识所述场景中指示的一个或多个与场景相关的情绪和/或动作。
下文表1中第一列示出了示例性情绪。
69.分析可以涉及一组或多组存储的数据。存储的数据可以包括多媒体对象的信息。多媒体对象可以包括存储的数据。存储的数据可以包括一个或多个视频文件、字幕文件、详细描述多媒体对象的章节的起始时间的章节文本文件、演员语音和/或非语音部分的音频文件片段和/或任何其它合适的数据源。
70.存储的数据可以包括多媒体对象的描述性音频原声带。存储的数据可以包括描述性音频原声带的元素。原声带可以在更直接表示多媒体对象的创作者想表达的情绪方面进行改进,而不是仅仅依靠主观用户输入。
71.所述方法可以包括对多媒体对象的预处理。分析可以包括对多媒体对象的预处理。预处理可以包括从多媒体对象中提取存储的数据。预处理可以为数据分析提供部分或全部信息。预处理可以提供技术改进,场景的特征的更丰富的指示符可有助于检测关键情绪,以及与对象摘要相关的其它关键特征,例如动作和/或活动。本文中所使用的术语“活动”是指观看者可以观察到在多媒体对象中发生的事情。
72.数据分析可以包括擦除关联元数据。关联元数据可以描述多媒体对象。存储的数据可以包括关联元数据。关联元数据可以为数据分析提供部分或全部信息。包括关联元数据可以通过生成没有记录或轻易从其它存储的数据文件中提取的情绪相关信息,并且不需要根据个人用户的主观输入来提供改进。
73.数据分析可包括利用语义网络系统,利用现有和/或新颖的词汇表、域特定本体和/或万维网联盟推荐的rdf、rdf架构(rdfs)、网络本体语言(web ontology language,owl)、r2rml和/或sparql等语言技术,将结构化和/或半结构化信息转换为关联数据,例如关联开放数据。
74.数据分析可以包括实现语义提升。语义提升可以捕获多媒体对象的原始多媒体信息。语义提升可以遵循场景本体。语义提升可用于以语义方式表示视频内容和/或支持用户分析。语义提升可以通过以有意义和语义丰富的方式捕获多媒体对象的原始多媒体信息来提供改进,对于不同的人和/或机器阅读器,例如,在情绪检测和/或对象摘要方面,多媒体对象的原始多媒体信息可以不是可转换的。场景本体可有助于知识图具有语义丰富和/或机器可互操作性质。场景本体可有助于知识图全面描述多媒体对象的内容。
75.所述方法可以包括关联数据。所述方法可以包括发布数据,例如在互联网上发布数据。所述方法可以包括互联。所述方法可以包括将数据源之间的数据互联。关联数据可以配置为便于通过语义浏览器访问。关联数据可有助于通过资源描述框架(resource description framework,rdf)关联在数据源之间进行导航。数据源可以包括描述多媒体对象的特征的外部源。数据源可以包括存储的数据。互联可以改进知识图,使其外部信息的语义更丰富。
76.互联可有助于知识图具有语义更丰富的外部信息,而这些外部信息可能无法从电影内容或电影元数据中获得。例如,电影的元数据可以仅提供演员和被描绘的虚构人物之间的关联。将演员实体与外部源中的相应实体互联,可以提供更多关于演员的信息,如性别、出生日期等。
77.可以是与数据网等外部源互联。外部源可以包括公共的跨域知识图,例如dbpedia、wikidata和/或yago。例如,wikidata可用于电影数据和个人数据,如演员和电影
摄制组。其它实体的数据关联,如某一场景或片段的城市和国家,可以根据dbpedia的资源确定。
78.本发明的装置和方法可以包括一种有助于将实体与最合适的外部源互联的机制。互联可以用sparql表示。
79.所描述的多媒体对象特征可以包括以下至少一个的一个或多个特征或属性:所述多媒体对象的一个或多个场景;所述多媒体对象场景中的活动;在所述多媒体对象中表演的演员;和/或所述多媒体对象中描绘的人物。在数据分析中包括特征可以通过提供语义丰富、可全面描述多媒体对象的内容和/或可生成可靠的多媒体对象摘要的知识图来进行改进,对于关键叙述也适用。
80.数据分析可以包括从视觉情绪指示符中提取情绪。存储的数据可以包括视觉情绪指示符。视觉指示符可以包括面部表情图像、身体姿势图像和/或情绪指示行为的视频序列。所述视觉情绪指示符可以通过生成其它来源无法提供的丰富的社交和/情绪信息来进行改进,从而生成语义丰富的知识图,所述知识图可以全面描述多媒体对象的内容,和/或可生成可靠的多媒体对象摘要,对于关键叙述也适用。
81.数据分析可以包括从听觉情绪指示符(如指示情绪的音乐原声带和/或指示情绪的声音指示符)中提取情绪。存储的数据可以包括听觉情绪指示符。听觉情绪指示符可以通过生成可能无法从其它来源获得的丰富的社交和/情绪信息来进行改进,从而生成语义丰富的知识图,所述知识图全面描述多媒体对象的内容,并生成可靠的多媒体对象摘要,对于关键叙述也适用。
82.数据分析可以包括从文本情绪指示符(如显式情绪描述符和/或暗示性情绪指示符)中提取情绪。这些文本情绪指示符可以通过生成在其它方面不明显的情绪信息来进行改进,从而生成语义丰富的知识图,该知识图全面描述多媒体对象的内容,并且可以生成适用于关键叙述的可靠摘要。
83.所述方法的各个方面可以通过一个或多个用户接口实现。用户接口可以包括图形用户接口(graphic user interface,gui)。用户接口可以包括一个或多个接口特征。接口特征可以包括小部件和/或虚拟按钮。接口特征可以专门用于该方法的一个或多个步骤。接口特征可以用于避免主观的个别用户输入。
84.接口特征可有助于生成视频摘要可查询的基于情绪的知识图。基于情绪的知识图可以用来创建保留整体基调和故事的电影节略形式。所述方法可以包括利用标注信息创建基于情绪的知识图,以便在电影摘要中选择信息最丰富的场景。
85.所述方法可涉及基于知识的系统,包括表示多媒体对象信息的知识库。所述方法可以包括对种类、属性以及证实多媒体对象的概念、数据和/或实体之间的关系的表示和/或定义。基于知识的系统可以包括一个或多个推理引擎,用于推导新信息和/或发现不一致。所述方法可以包括在步骤103中生成知识图。知识图可以将一个或多个场景和相应的一个或多个场景相关情绪关联。本发明的各个方面可以避免需要用户情感或情绪来创建知识图。
86.所述方法可以包括在步骤105中计算分数,所述分数指示一个或多个场景对于传达主要叙述的相对重要性。例如,较低分数可以表示缺少主要人物和/或主题元素;可以表示和主题不强相关的叙述;和/或可以表示多余的主题元素。较高分数可以表示存在主要人
物和/或主题元素;可以表示主要叙述;和/或可以表示过渡性主题元素,其中,例如,叙述主题可以在主题高潮之前和之后发生重大转折。可以根据知识图计算分数。
87.所述方法可以包括在步骤107中根据分数选择场景的子集。所述子集可以包括较高评分的场景。选择可以包括设置一个或多个阈值以包含在所述子集中。
88.所述方法可以包括根据所述子集生成所述多媒体对象的摘要。生成摘要可以包括仅合并得分满足阈值的场景。生成摘要可以包括筛选得分不满足阈值的场景。生成摘要可以包括删除得分不满足阈值的场景。
89.本发明的系统和架构可以包括,并且本发明的方法和过程可以包括用于对多媒体对象进行标注和/或概述的系统。系统可以包括用于执行用于实现所述方法的机器可读指令的处理器。系统可以包括用于存储所述机器可读指令的存储器。
90.参考图1b,示出了软件系统100b。所述系统可以包括系统100b的任意或全部特征。所述系统可用于执行图1a所示的方法100a的任意或全部步骤。所述系统可以包括一个或多个模块,用于执行方法100a的一个、任意或全部步骤。如本文中所使用的术语“模块”是指一个或多个软件组件和/或一个或多个程序的一个或多个部分,并且还可以包括和/或涉及用于执行软件组件和/或程序部分的硬件。硬件可以包括执行指令的处理器和/或存储指令的存储器。程序可以包含一个或多个例程。程序可以包括一个或多个模块。如在以下段落中说明的,所述模块的表示可用于说明体现本发明的系统和/或实现本发明的方法的系统架构的功能特征。模块可以通过一个或多个接口并入所述程序和/或软件中。处理器执行的指令可以包括一个或多个模块。
91.图1b所示的系统100b用于根据其中的视觉和/或音频情绪提示对多媒体文件进行标注。系统100b包含两个主要部分,即语义提升部分102和视频摘要部分104。语义提升部分102根据情绪和/或活动创建知识图。系统100b可用于实现图1a中所示的过程100a的一个或多个步骤。
92.语义提升部分102可包括自动媒体处理模块106。媒体处理模块106可用于对用户选择的多媒体对象进行自动预处理。模块106可用于执行关于过程100a所述的预处理的任意步骤或所有步骤。模块106可从电影中提取视频、音频和/或字幕。模块106可提取详细描述电影章节的开始时间的章节文本文件、音频文件、演员声音片段等。
93.语义提升部分102可包括自然语言处理(natural language processing,nlp)模块108。自然语言处理模块108可用于对模块106处理的命名实体数据进行定位和分类。模块108可用于对模块106处理的非结构化多媒体数据进行命名实体识别。
94.语义提升部分102包括标注工具模块110。模块110可包括上文关于过程100a的步骤101所描述的图形用户接口。模块110有助于用户选择电影进行处理。模块110可有助于用户与模块106和108进行交互。模块110可包括关于过程100a的步骤101所描述的图形用户接口的任何或全部特征。
95.语义提升部分102包括本体模块112。本体模块112有助于模块108和110执行数据分析。本体模块112可有助于对模块106处理的命名实体数据进行分类。模块112可有助于对模块106处理的非结构化多媒体数据进行命名实体识别。本体模块112可有助于在语义上定义概念,所述概念捕获用户所选电影中的时刻,例如基于情绪的时刻,以便使用有意义且语义丰富的表示获取电影的原始多媒体信息。例如,语义信息可以从电影的描述性音频原声
带(如供视觉受损观众使用的原声带)和/或从电影字幕(如演员说的话和/或听力受损观众的视觉提示)中提取。语义信息可以从多媒体对象的一个或多个音频部分的一个或多个抄录中提取。抄录可包括对语音和/或非语音元素的描述。抄录可以包括一种或多种语言。语义信息可以从隐藏字幕、开放字幕和/或字幕中提取。语义信息可以从对话的译文、声音效果、相关音乐提示和/或任何其它合适的相关音频数据中提取。
96.语义提升部分102包括语义提升模块114和自动元数据模块116。自动元数据擦除模块116用于通过语义提升模块114从用户选择以处理的电影的电影文件中自动擦除元数据。自动元数据擦除模块116用于不需要模块106和108进行预处理的情况下擦除电影元数据。
97.语义提升模块114对数据进行语义提升并有助于电影内容的语义表示。语义提升模块114用于直接通过标注工具模块110、通过本体模块112和/或通过自动元数据擦除模块116处理多媒体对象的原始多媒体信息和/或处理后的多媒体信息。语义提升模块114通过标注工具模块110支持用户分析。
98.语义提升部分102包括外部源互联识别模块118。外部源互联识别模块118可有助于与电影元数据的外部源相连。例如,外部源互联识别模块118可有助于从一个或多个电影数据库应用编程接口(如imdb、dbpedia1、wikidata2和/或其它开放源数据)中擦除电影元数据。与外部源的互联可以使知识图具有语义更丰富的外部信息,而这些外部信息可能无法从电影内容或电影元数据中获得。
99.语义提升部分102包括电影知识图生成模块120。知识图生成模块120实现本体驱动的电影知识图的生成。知识图生成模块120生成语义丰富且可机器互操作的知识图,从场景、情绪、活动、演员等方面全面描述电影。知识图生成模块120可以将知识图存储为可使用sparql(例如通过sparql查询端点模块128)查询的资源描述框架(resource description framework,rdf)三元组,所述三元组可以与外部资源相连。语义模型或本体可以表示知识图中的数据,有助于知识图中的各种特征、属性和资源,这些特征、属性和资源可用于标识对电影相关任务(例如电影摘要)有用的电影场景。
100.视频摘要部分104包括摘要用户接口模块130、摘要应用编程接口(application programming interface,api)模块132和摘要主组件模块136。摘要主组件模块136可包括用于由用户来定制电影摘要的优选特征的场景模板选择和一般用途选择的模块,以及用于根据用户选择对电影场景进行评分的场景模板处理器和场景排名器。在用户通过接口模块130请求电影摘要时,摘要api模块132与摘要主组件模块136通信以选择最高排名场景的子集,该子集根据用户选择的模板进行排名,以包括在电影摘要138中。电影摘要138可以由模块136生成,以仅包括通过模块128从电影知识图模块120和/或外部电影元数据源中提取的排名后的电影数据对传达电影的主要叙述具有高度重要性的场景。
101.参考图1c,示出了说明性系统100c的说明性框图。系统100c可以包括系统100b的任意或全部特征。系统100c可用于执行图1a所示的方法100a的任意或全部步骤。系统100c可以包括一个或多个模块,用于执行方法100a的一个、任意或全部步骤。系统100c是以计算机141为基础。计算机141具有控制计算机141的操作和计算机141的相关组件的处理器143。计算机141包括ram 145、rom 147、输入/输出模块149和存储器155。处理器143执行在计算机141上运行的软件,例如操作系统157和包括过程100a的步骤的软件。通常用于计算机的
其它组件,例如eeprom或闪存或任何其它合适的组件,也可以是计算机141的一部分。
102.存储器155包括任何合适的存储技术,例如硬盘。存储器155存储包括操作系统157和应用159的软件以及系统100c的操作所需的数据151。例如,存储器155还可以存储包括多媒体对象的视频、文本和/或音频辅助文件。视频、文本和/或音频辅助文件也可以存储在高速缓存存储器或任何其它合适的存储器中。或者,例如,包括过程100a的那些计算机可执行指令的部分或全部可以在硬件或固件(未示出)中体现。计算机141执行由软件体现的指令以执行各种功能,例如过程100a的步骤。
103.输入/输出(i/o)模块149可包括与麦克风、键盘、触摸屏、鼠标和/或触笔的连接,计算机141的用户可通过这些连接进行输入。输入可以通过光标移动。输入可以包括在转移事件和/或转义事件中。输入/输出模块149还可以包括用于提供音频输出的扬声器和/或用于提供文本、音频、视听和/或图形输出的一个或多个视频显示设备。输入和输出可以与计算机应用功能相关,例如有助于实现过程100a的一个或多个步骤。
104.图1c中描绘的网络连接包括局域网(local area network,lan)153和广域网(wide area network,wan)169,但是也可以包括其它网络。例如,系统100c通过lan接口153与其它系统相连。系统100c可以在支持与一个或多个远程计算机(例如系统181和191)连接的网络环境中操作。系统181和191可以是个人计算机或服务器,包括上文关于系统100c描述的许多或全部元素。当用于lan联网环境中时,计算机141通过lan接口151与lan 153相连。当用于wan网络环境中时,计算机141可包括调制解调器151或用于通过wan 169建立通信的其它模块,例如互联网171。
105.应理解,示出的网络连接是说明性的,并且可以使用在计算机141、181和191之间建立通信链路的其它模块。假定存在各种公知协议,如tcp/ip、以太网、ftp、http等,并且系统100c可以在客户端-服务器配置中操作,以允许用户检索网页,例如,从基于网页的服务器获取。基于网页的服务器可用于将数据传输到任何其它合适的计算机系统,例如181和191。基于网页的服务器还可以将计算机可读指令连同数据一起发送到任何合适的计算机系统。计算机可读指令可以包括将数据存储在高速缓存存储器、硬盘、辅助存储器或任何其它合适的存储器中。数据连同计算机可读指令一起传输可使计算机系统根据需要迅速检索数据。由于计算机系统能够快速检索数据,因此基于网页的服务器不需要将数据流式传输到计算机系统。这可以为计算机系统带来好处,因为检索比数据流更快。因此,用户避免了等待运行应用的挫折感。传统的数据流处理需要大量使用处理器和高速缓存存储器。如所设想,当数据存储在计算机系统的存储器中时,检索数据可以避免了大量使用处理器和高速缓存存储器。任何传统的网页浏览器都可用于显示和/或操纵网页上检索的数据。
106.此外,计算机141使用的(多个)应用程序159可包括计算机可执行指令,所述计算机可读指令包括过程100a的步骤。
107.计算机141和/或系统181和191还可以包括各种其它组件,例如电池、扬声器和天线(未示出)。
108.系统181和191可以是便携式设备,例如笔记本电脑、智能电话或用于存储、传输和/或传达相关信息的任何其它合适设备。系统181和191可包括其它设备。这些设备可以与系统100c相同,也可以不同。这些差异与硬件组件和/或软件组件有关。
109.该方法可以包括且该系统可以涉及情绪图生成过程的一个或多个步骤。参考图2,
示出了示例性的基于情绪的知识图生成过程200。该方法可以包括且系统可以涉及情绪图生成过程200的一个或多个步骤。过程200可以由系统100b的一个或多个模块执行。过程200可以由图1b所示的语义提升部分102的一个或多个模块执行。过程200可以从步骤202开始。
110.在过程200的步骤202中,用户可以选择存储在dvd或任何合适的存储介质上的多媒体对象,例如电影和/或电影文件,以生成知识图。电影可以是任何合适的流派,例如动作片和/或惊悚片。
111.在步骤204中,视频预处理可以包括从电影中提取视频、音频和/或字幕。视频预处理可以提供多媒体对象数据。多媒体对象数据可以包括任何合适的数据,例如,详细描述多媒体对象的章节的起始时间的一个或多个章节文本文件;电影的多个音频文件,例如,一个音频文件用于一个可用原声带;相对较多的较小音频文件,可包括演员声音(对话)的片段和/或非语音部分的片段。步骤204可以由图1b所示的语义提升部分102的自动媒体处理模块106和/或nlp模块108执行。步骤204可以包括对提取的电影数据的自然语言处理。
112.在步骤206中,电影元数据可以从加载的电影中自动擦除,无需在步骤204进行预处理。或者或另外,电影元数据可以从外部源(例如外部源212)中擦除。步骤206可以由图1b所示的语义提升部分102的自动元数据擦除模块116执行。
113.步骤208示出了根据情绪对电影进行标注的算法和标注工具包的实现方式。步骤208可以由图1b所示的语义提升部分102的自动标注工具模块110执行。如上文关于图1a中示出的过程100a的步骤101所述,步骤208可包括与专用图形用户接口的一个或多个用户交互。步骤208可以包括数据分析的一个或多个步骤。步骤208可有助于用户执行过程200的任意或全部步骤。
114.在步骤210中,语义提升模块,例如图1b中所示的模块114,可以用于用语义表示电影并支持对电影的分析。实现抽象语义模型可以包括场景本体。场景本体可以包括媒体标注本体。语义表示的内容可有助于通过资源描述框架(resource description framework,rdf)关联在数据源之间进行导航。步骤210包括对数据进行语义提升并有助于电影内容的语义表示。步骤210可以包括对原始或预处理的电影数据进行语义提升。
115.过程200的步骤212包括与电影元数据的外部数据源互联。与外部源的互联使知识图具有语义更丰富的外部信息,而这些外部信息无法从电影内容或电影元数据中获得。外部源的电影元数据可以使用电影数据库应用编程接口(例如imdb、dbpedia、wikidata和/或其它开放源代码数据)进行擦除。步骤212可以由图1b中示出的语义提升部分102的一个或多个模块进行介导,例如自动元数据擦除模块116和/或互联识别模块118。
116.步骤214描绘了本体驱动的电影知识图的生成。在步骤214中,用户可遵循语义网页和关联数据最佳实践。用户可以创建新颖的本体和/或重用一个或多个现有本体。通过这种架构,生成的知识图谱可以具有丰富的语义和机器互操作性,并且可以全面地描述电影的内容,例如场景和场景内的活动,以及元数据,例如电影、演员的描述。步骤214可以由图1b中所示的语义提升部分102的一个或多个模块(例如知识图生成模块120)介导。
117.数据分析可以包括将多媒体对象解析为基于动作和/或基于情绪的分量的一个或多个过程。图3是示例性情绪标记过程300的图形描绘。过程300可以从步骤302开始。多媒体对象的数据分析,如图1的步骤101所示,可以包括过程300的任意或全部步骤。
118.步骤302包括分析具有开始时间t0和结束时间tn的电影。如步骤302所示,在确定
(例如通过数据分析)时,电影或其它多媒体对象可以被确定为包括动态复杂结构。在过程300中,整个电影可以被标记为在时间t0开始和在时间tn结束。
119.在步骤304中,通过数据分析确定结构包括一个或多个分量场景(sm)。步骤304可以包括对多媒体对象的场景进行标记。场景可以具有固定的开始时间和结束时间。步骤304可以包括将电影划分成分量场景。例如,在图1的步骤101中,数据分析可以包括将多媒体对象划分成分量场景。所述方法可以包括标记所述分量场景中的一个或多个场景。可以根据检测到的一个或多个场景中固定的一个或多个情绪进行标记。
120.如图3所示,可以通过数据分析确定第一场景(s0)在时间t0开始并且最后一个场景(sm)可以在时间tn结束。中间场景s
tn-50
和s
tn-10
可以通过数据分析确定,分别在时间t
n-50
和t
n-10
结束。场景可遵循整体叙述。场景过渡可以是明显的,也可以是微妙的。叙述的转变可以预示着一个新的场景。场景过渡可以例如通过位置、语调、情绪、事件、叙述阶段和/或主要叙述发展的变化来标识。
121.在步骤306中,可以通过数据分析确定每个场景包括一个或多个时间固定的、可观察的动作和/或活动,例如动作aw、a
x
、ay和az。动作可以相互重叠(未示出)。
122.在步骤308中,可以通过数据分析确定每个场景包括一个或多个时间固定的、可观察的、可能重叠的情绪。场景情绪可以与多媒体对象的整体流派不同。场景情绪可以设定某一特定场景的基调。下文表1显示了说明性场景情绪。
123.可以根据一个或多个情绪指示符进行标记,例如在给定场景中原声带的音调的听觉指示符,和/或人物的行为和/或面部表情的视听行为指示符。例如,与场景重叠的部分原声带的响度和/或强度可以表示愤怒的场景情绪。柔和的音乐可以温柔、忧郁和/或恐惧。高音可以表示欢乐和/或兴奋情绪。低音可以表示悲伤和/或严肃的情绪。表示笑声的听觉和/或视觉信号可以指示场景中的欢乐气氛,而哭泣和皱眉的面部表情可以表示悲伤的情绪。下文表1显示了说明性情绪指示符。
124.表1说明性情绪指示符。音乐强度和音色可以代表相对值。音乐的音高以大约赫兹表示,节奏以每分钟的节拍表示。
[0125][0126]
可替换地和/或另外地,可以根据多媒体对象的字幕中包括的情绪的显式和/或隐式暗示进行标记。可替换地和/或另外地,可以根据媒体数据库的擦除的外部数据进行标
记。
[0127]
该方法可以包括使用语义标注架构创建语义标注。例如,为了生成电影元数据,可以使用数据资源(如电影db api)来擦除电影元数据并将其提升到知识图中。媒体标注本体(下图中以“ma”为前缀)可以捕获所需的信息。知识图可以包括其它谓词,例如“hasdirector”。知识图可包括分类集以表示电影行业中的不同职业,例如导演。这些概念可以正式定义为多媒体场景本体的一部分。所述方法可以包括生成场景本体的一个或多个特征。知识图可包括场景本体,该场景本体可在图1a所示的过程100a的步骤103期间创建和/或可由图1b所示的系统100b的语义提升部分102的一个或多个模块(例如模块112、118和120)生成。参考图4,示出了说明性场景标注本体400;参考图5a,示出了本发明提供的资源描述框架架构的示例性图例501;参考图5b,如图5a所示的图例501所示,示出了说明性情绪时刻定义503。
[0128]
本体400在语义上定义概念,所述概念捕获电影中的时刻,以便以有意义且语义丰富的表示来转译视频的原始多媒体信息。本体400可以设计为可跨机器互操作,并且也易于被人们理解。
[0129]
如图4所示,根据图5a所示的图例501,在本体400中,确定场景402为在时间间隔408期间对应于现有媒体标注本体(media annotation ontology,ma)媒体资源406的现有ma媒体片段404。媒体资源406基于现有的rdfs资源410。场景402通过ma“ma:hasrelatedlocation”与现有位置412关联。例如,通过数据分析确定场景402包括时间间隔416的时刻414。确定时刻414并标记为包括情绪时刻418和/或可观察动作420。根据图5b中示出的情绪时刻定义503,根据图5a中示出的图例501,可以根据函数519等数据分析确定和标记情绪时刻418等情绪时刻,作为具有关联情绪521的性质。可以根据重要性对时刻414进行评分,例如,使用可扩展标记语言(extensible markup language,xml)布尔分数422的xml架构定义(xml schema definition,xsd)。分数422可以根据图5b中示出的情绪521和/或动作420和/或场景对于传达电影的主要叙述的重要性的其它相关线索,例如演员424在场景中。
[0130]
如图4中所示的本体400的场景本体的创建可以通过一个或多个算法过程来实现。参考图6,图6是示例性过程和/或算法600的流程图。算法600可用于标注电影。算法600可以从步骤601开始。步骤601可以包括起步算法600。算法600可包括分别参照图1a、图2和图3描述的过程100a、200和300的任意和/或全部步骤。过程100a、200和300可包括算法600的任意和/或全部步骤。算法600可以由图1b所示的系统100b的部分102的一个或多个模块执行。
[0131]
在步骤602中,特定电影可以由用户选择和/或加载。也可以加载存储的标注数据集来标注电影。也可以加载电影的元数据。步骤602可包括关于图2所示的过程200的步骤202所描述的任意和/或全部特征。
[0132]
在步骤604中,用户可以添加和/或编辑电影的标注。标注可以保存在标注数据库中。
[0133]
在步骤606中,算法和/或用户可填充媒体本体。本体可包括关于图4所示的本体400所描述的任意和/或全部特征。
[0134]
在步骤608中,用户和/或算法可以导出电影知识图。知识图可以存储为rdf三元组。知识图的导出可以由图1b所示的系统100b的模块120执行。步骤608可包括图1a所示的
过程100a的步骤103和/或图2所示的过程22的步骤212和/或214的任意和/或全部特征。过程100a的步骤103可包括步骤608中的任意和/或全部特征。
[0135]
算法过程的步骤可以由用户通过一个或多个用户接口实现。用户接口可包括关于图2所示的过程100a的步骤101和/或过程200的步骤208描述的gui的任意或全部特征。图1b所示的系统100b的模块110可以包括用户接口的一个或多个特征。
[0136]
参考图7,示出了用于有助于根据情绪进行标注的示例性标注工具包的示例性图形用户接口(graphical user interface,gui)700。用户接口可以包括gui 700的任意或全部特征。gui 700可有助于进行关于图1的100a、图2的200和图3的300所描述的过程的一个或多个步骤。标注工具包可以为标注器提供选项,以记录电影中观察到的活动和情绪的信息。gui700包括四个主要特征。
[0137]
特征702包括用于加载的电影的说明性全局动作、全局情绪和实体。用户能够选择特征702中的预定义动作、情绪和/或实体。用户能够在特征702中定义新的动作、情绪和/或实体。保存的动作、情绪和/或实体可以在电影中可用。
[0138]
特征704用于显示电影。特征704可包括用于观看电影的设备;用于收听原声带的设备;用于暂停电影的设备;用于跳过场景的设备和/或任何其它合适的电影显示设备。特征704可有助于用户检测在指定时间框架内观看的场景中的情绪和/或动作。
[0139]
特征706用于根据所表现的方面,例如场景、动作和/或情绪,显示和/或编辑标注细节。根据用户对特征708中的标注要求的选择,在特征706中提供了各种配置选项。每个标注方面都包括对应的选项。例如,如果用户想要定义一个新的动作,那么提供的选项包括确定时间轴编辑器的起点和终点。此外,动作中涉及的实体(例如,接收实体和执行实体)也被分配到特定的时间框架。
[0140]
gui 700用于有助于电影内容的语义建模。标注器从特征702中定义的关联动作的执行实体、参与活动和/或接收实体中作出选择。可以包括控制按钮以方便访问后续和/或以前的选项,以删除标注和/或其它合适的操作。所述操作可以根据一个或多个选定对象和/或区域来实现,所述选定对象和/或区域已经在特征708中选定。特征708用于有助于在场景、动作和/或情绪之间切换。
[0141]
特征708的面板用于创建和/或定义场景,以确定情绪等时刻状态,以及标注在指定时间内发生的活动。如图所示,面板的水平侧(从左到右)表示时间轴。垂直面分为三部分:“场景”、“动作”、“情绪”。
[0142]
用户接口,例如gui 700,可以包括在标注工具中。该工具可以包括用于执行多媒体对象的媒体标注的软件和/或硬件。参考图8,示出了标注工具的说明性系统架构800。标注工具可以包括关于图7的gui 700描述的之前描述的标注工具包。架构800可以包括图1b所示的系统100b的一个或多个特征。架构800可用于分别执行图1a的过程100a、图2的过程200、图3的过程300和图6的过程600中的一个或多个步骤。架构800可用于生成图7的本体700。
[0143]
在系统架构800中,通过用户接口804呈现电影的擦除元数据802。用户接口804可包括图7的gui 700的一个或多个特征。用户接口804与时间轴编辑器808中的电影的标注模块806进行交互。然后,标注工具的数据作为rdf三元组存储在知识图810中。
[0144]
本发明的方法和系统可以包括语义分析。本发明的方法和系统可以包括文本挖
掘。本发明的方法和系统可以包括深度学习。知识图数据可以根据搜索,返回与搜索术语密切相关的概念。例如,可以返回“出拳”和“踢脚”以进行更通用的“打架”搜索。如果活动只是字符串标签,那么语义分析可以避免在生成的活动中出现语义空白,从而机器无法理解同义词。语义分析还可以促进搜索通用概念,例如在摘要任务中。
[0145]
语义分析可包括构建简单知识组织系统(simple knowledge organization system,skos)分类,以便搜索能够从大范围的术语/概念(例如,打架)扩展到更详细的术语(例如,出拳)。使用skos可以丰富电影活动,使其具有更丰富的语义含义和上下文。分类法可以通过预处理动作电影脚本来创建大量的词库。
[0146]
利用语料库可以建立跳跃式word2vec模型。跳跃式模型可以获取电影脚本中的每个词和预定义窗口中的周围单词以构建词对。字对可以用作单层神经网络的训练数据。然后,训练的神经网络可以用于预测词的相关概率。
[0147]
参考图9,描绘了单层神经网络输入输出示例900,参考图10,描绘了说明性skos分类的一部分的可视化结构1000。示例900包括训练的神经网络的示例性输入和输出。示例900根据包括更广义的面向动作的词“打架”和更具体的面向动作的词“出拳”的说明性脚本的文本来说明计算的更具体的词“出拳”出现在更广义的词“打架”附近的概率。根据更特定词出现在更广义词附近的较高概率的阈值,用户可以将与更特定词关联的更特定概念并入与更广义词关联的更广义类别中,用更广义词的更广义标签来标记具有更具体概念的场景。
[0148]
图10中示出的结构1000示出了概念“skos:narrower”层次结构。为了建立活动分类,可以在知识图中为手工策划的活动创建抽象术语。抽象术语可以作为广义的skos概念,而手工活动可以定义为skos:narrower概念。
[0149]
该方法可以包括生成一个或多个将动作和/或情绪元数据与多媒体对象的场景互联的综合元数据本体。知识图可以包括元数据本体。
[0150]
接着,参考图11、图12a和图12b。图11描绘了本体1100,该本体1100包括根据本发明原理生成的多媒体元数据的说明性片段。同样地,图12a通过本体1200示出了图12a中示出的场景1207(包括图12b中描绘的帧1201)如何能够被转换为类型“so:observableaction”的三元组。
[0151]
在本体1100中,电影由标识符“movie123456”表示,如方框1102所示。在方框1103中,电影定义为媒体标注本体的一个概念:“mediaresource”的类型。电影元数据由多个电影属性丰富,包括:电影是通过“ma:createdin”谓词1105创建的;电影的导演使用“so:hasdirector”谓词1107,和演员使用“ma:features”谓语1109。
[0152]
类似地,其它实例具有与实例相关的多个属性,包括人类可读标签,如与”rdfs:label”谓词相关的虚线框1104所示。对每个实例进行分类,其中虚线框表示外部本体中的类型,例如方框1103表示“ma:mediaresource”。示出其它实例是指在场景本体中定义的类别,例如表示“so:fictionalentity”的方框1110。此外,每个实例可以通过外部资源的一个或多个关联进行丰富,例如以虚线点框1108示出的关联。
[0153]
在图12a中示出的本体1200中,示出电影1206包括通过“ma:isfragmentof”谓词1202与电影1204关联的场景1207。场景1207包括一个或多个时刻,例如图12a中的“so:observableaction”时刻1204,或者例如“so:moodmoment”(未示出)。场景和时刻标识符使
用时间戳进行标注。时间戳符合w3c关于媒体资源uri规范的建议。时间戳用uri片段符号“#”和参数“t=ts,te”来区分,其中ts表示媒体片段的开始时间,te表示结束时间。如图12a所示,场景1207用时间戳“scene#t=60,316”进行标注,表示场景1207从第60秒开始,到第316秒结束。
[0154]
如图12a所示,场景1207中包括的与时刻1204对应的可观察动作,例如动作1209,从195秒开始到209秒结束,例如,所述可观察动作可以包括人物1213在平面翼1215上行走,如图12b所示。可观察动作的实例通过“so:hasmoment”谓词(例如谓词1208)与场景实例关联。每个“observableaction”都定义一个活动,例如活动1210,或者有一个“so:performingentity”,例如so:performingentity 1203。或者“so:receivingentity”,例如so:receivingentity 1205,或者两者(如图12a所示)。“observableaction”和“scene”实例由一组时间三元组进行丰富,为了描述的简洁性,图12b中省略了这些时间三元组。
[0155]
该装置可以涉及且方法可以包括:查询电影知识图。语义提升模块可用于以语义方式表示视频内容和支持对多媒体对象进行分析。语义提升模块可以将情绪和/或相关活动用作提升电影和创建知识图的核心组件。
[0156]
如上所述,抽象语义模型可以根据场景本体设计,场景本体可以包括媒体标注本体的一个或多个方面。标注工具生成的结果数据可遵循相同的本体/架构。因此,可以生成语义知识图,实现复杂的推理和查询能力,以及支持新颖和个性化的面向客户的内容表示。
[0157]
如所公开,根据情绪进行的标注过程可有助于创建知识图。在本发明的一些实施例中,知识图反过来可有助于创建电影的较短视频摘要,例如包括不超过电影原始长度的25%的摘要。然而,摘要可保留电影中重要的叙述部分。
[0158]
在本发明的一些实施例中,电影的标注可以包括电影的手动和/或自动处理和语义提升。提升的自动部分可以包括自然语言处理(natural language processing,nlp)技术,例如电影音频解说。
[0159]
在研究下文附图和详细描述之后,本发明的其它系统、方法、特征和优点对于本领域技术人员来说是或变得显而易见的。希望所有这些其它系统、方法、特征和优点包含在本说明书中,在本发明的范围内,并且受所附权利要求的保护。
[0160]
对本发明各个实施例的描述只是为了说明的目的,而这些描述并不旨在穷举或限于所公开的实施例。在不脱离所描述的实施例的范围和精神的情况下,本领域技术人员可以清楚理解许多修改和变化。相比于市场上可找到的技术,选择此处使用的术语可最好地解释本实施例的原理、实际应用或技术进步,或使本领域其他技术人员理解此处公开的实施例。
[0161]
预计在本技术的专利有效期内,将开发出多媒体对象知识图生成和概述的许多相关过程,并且术语多媒体对象知识图生成和概述的范围意在先验地包括所有这些新技术。
[0162]
本文所使用的术语“约”是指
±
10%。
[0163]
术语“包括”、“具有”以及其变化形式表示“包括但不限于”。这个术语包括了术语“由
……
组成”以及“主要由
……
组成”。
[0164]
短语“主要由
…
组成”意指组成物或方法可以包括额外成分和/或步骤,但前提是所述额外成分和/或步骤不会实质上改变所要求的组成物或方法的基本和新颖特性。
[0165]
除非上下文中另有明确说明,此处使用的单数形式“一个”和“所述”包括复数含
义。例如,术语“化合物”或“至少一个化合物”可以包含多个化合物,包含其混合物。
[0166]
此处使用的词“示例性的”表示“作为一个例子、示例或说明”。任何“示例性的”实施例并不一定理解为优先于或优越于其它实施例,和/或并不排除其它实施例特点的结合。
[0167]
此处使用的词语“可选地”表示“在一些实施例中提供且在其它实施例中没有提供”。本发明的任意特定的实施例可以包括多个“可选的”特征,除非这些特征相互矛盾。
[0168]
在本技术中,本发明的各种实施例可以范围格式呈现。应理解,范围格式的描述仅为了方便和简洁起见,并且不应该被解释为对本发明范围的固定限制。因此,对范围的描述应被认为是已经具体地公开所有可能的子范围以及所述范围内的个别数值。例如,对于例如从1到6的范围的描述应被视为已具体公开了从1到3、从1到4、从1到5、从2到4、从2到6、从3到6等的子范围以及该范围内的单个数字例如1、2、3、4、5和6。不论范围有多广,这都适用。
[0169]
当此处指出一个数字范围时,表示包括了在指出的这个范围内的任意所列举的数字(分数或整数)。短语“在第一个所指示的数和第二个所指示的数范围内”以及“从第一个所指示的数到第二个所指示的数范围内”和在这里互换使用,表示包括第一个和第二个所指示的数以及二者之间所有的分数和整数。
[0170]
应了解,为了描述的简洁性,在单独实施例的上下文中描述的本发明的某些特征还可以组合提供于单个实施例中。相反地,为了描述的简洁性,在单个实施例的上下文中描述的本发明的各个特征也可以单独地或以任何合适的子组合或作为本发明的任何合适的其它实施例提供。在各个实施例的上下文中描述的某些特征未视为那些实施例的基本特征,除非没有这些元素所述实施例无效。
[0171]
此处,本说明书中提及的所有出版物、专利和专利说明书都通过引用本说明书结合在本说明书中,同样,每个单独的出版物、专利或专利说明书也具体且单独地结合在此。此外,对本技术的任何参考的引用或标识不可当做是允许这样的参考在现有技术中优先于本发明。就使用节标题而言,不应该将节标题理解成必要的限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1