用于加速神经网络卷积和训练的系统和方法与流程
用于加速神经网络卷积和训练的系统和方法
背景技术:
1.人工神经网络是受生物神经网络(例如,大脑)启发的计算系统。人工神经网络(以下简称“神经网络”)包括互连的人工神经元集合,这些人工神经元对它们的生物学对应物进行松散建模。与生物学对应物一样,人工神经网络通过重复考虑示例来“学习”执行任务。例如,为了对水果进行分类,可以训练人工神经网络以通过考虑手动标记为“成熟”或“未成熟”的图像来区分成熟和未成熟的样本。这种训练调节了图像数据对人工神经元及其互连的影响。因此,图像属性(诸如颜色和纹理)可以自动与图像表示成熟或未成熟水果的概率相关联,最终允许已训练神经网络推断新的未标记图像表示成熟或未成熟水果的概率。
2.神经网络的任务是解决比水果分类复杂得多的问题。例如,神经网络正在适用于自动驾驶车辆、自然语言处理以及很多生物医学应用,诸如诊断图像分析和药物设计。负责解决这些问题的神经网络可能非常复杂,可能有数百万个连接的神经元。例如,在图像处理中,一些神经元层用作卷积过滤器,另一些神经元层池化卷积层的结果,还有一些神经元层对池化的结果进行排序。无论功能如何,每个神经元都需要快速访问存储,以获取在训练中确定的并且用于推理的值。因此,训练和推理需要访问高性能存储器。
附图说明
3.本公开在附图中以示例而非限制的方式示出。对于具有数字名称的元素,第一数字表示引入该元素的图,并且类似的引用指代图内与图之间的类似元素。
4.图1示出了用于人工神经网络的专用集成电路(asic)100,该asic 100具有使处理元件与存储器(例如,堆叠的存储器管芯)之间的连接距离最小化并且因此提高效率和性能的架构。
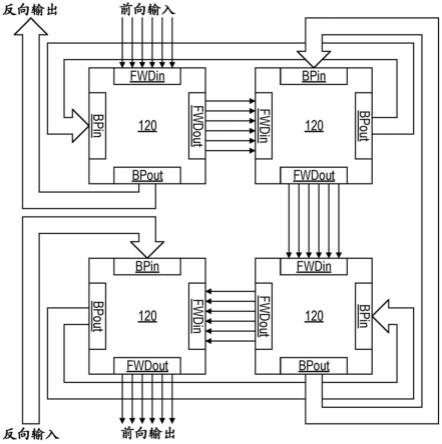
5.图2示出了被互连以支持并发的前向和反向传播的四个处理块120。
6.图3包括在单个处理块120上实例化的神经网络的功能表示300和阵列305。
7.图4描绘了处理元件400,该处理元件400是适合用作图3的每个处理元件320的电路系统的示例。
8.图5a到5h每个描绘了在输出o1、o2和o3被应用于连续的处理元件320时在相应的脉动处理周期期间图3的阵列305。
9.图6包括跨两个不同处理块被实例化的神经网络的功能表示600和脉动阵列605。
10.图7描绘了3d-ic 700,该3d-ic 700实例化图6所示的块120的阵列和神经网络的阵列610。
11.图8a描绘了图4的处理元件400,该处理元件400具有被提供用于支持反向传播的电路元件,使用粗线宽突出显示。
12.图8b描绘了类似于图4和图8a的处理元件400的处理元件800,其中相同标识的元件相同或相似。
13.图9a-图9h示出了在反向传播期间通过以图7所示的方式互连的处理块120和阵列610的信息流。
14.图10描绘了根据另一实施例的作为人工神经网络应用的管芯堆叠1000。
15.图11描绘了3d-ic 1100,该3d-ic 1100使用一对物理和电互连的ic管芯1105来实例化cnn,每个ic管芯1105包括卷积处理元件(cpe)1110的脉动阵列。
16.图12a-图12f包括图11的3d-ic 1100的简化视图,以将每个ic管芯1105示出为3
×
3脉动阵列,其中每个元件是cpe 1110。
17.图13描绘了具有前向传播输入开关1305和反向传播输入开关1310的块1300的四个实例,前向传播输入开关1305和反向传播输入开关1310一起支持上面结合图12a-图12f详述的连接性和相关信号流。
18.图14a-图14d描绘了设备架构1400,其中四个处理块1300可以通过开关1305和1310互连以实现用于卷积神经网络或用于在图3中详述的类型的处理元件网络的脉动阵列。
具体实施方式
19.图1示出了用于人工神经网络的专用集成电路(asic)100,该asic 100具有使处理元件与存储器(例如,堆叠的存储器管芯)之间的连接距离最小化并且因此提高效率和性能的架构。asic 100还支持用于训练的小批量和流水线、并发的前向和反向传播。小批量将训练数据拆分成小“批次”(迷你批次),而流水线以及并发的前向和反向传播支持快速高效的训练。
20.asic 100使用八通道接口chan[7:0]进行外部通信。靠近每个通道接口的一对分级缓冲器115缓冲进出存储器核心(未示出)的数据。缓冲器115允许速率匹配,使得从存储器读取和向存储器写入数据突发可以与处理块120阵列的常规流水线移动相匹配。在这种情况下,“块”是以矩形阵列(例如,正方形)布置的处理元件集合。块可以放置和互连,以允许块之间的高效通信。块内的处理元件可以作为脉动阵列操作,如下详述,在这种情况下,块可以“链接”在一起以形成更大的脉动阵列。尽管未示出,但存储器控制器(或状态机/定序器)可以集成在例如缓冲器115或块120中以保持处理流水线运行。缓冲器115可以通过一个或多个环形总线125互连以增加灵活性,例如允许将来自任何通道的数据发送到任何块,并且支持其中对网络参数(例如,权重和偏差)进行分区使得处理发生在神经网络的某些部分上的用例。
[0021]
asic 100被分成八个通道,每个通道可以用于小批量处理。一个通道包括一个通道接口chan#、一对分级缓冲器115、一系列处理块120和支持存储器(未示出)。这些通道在功能上相似。以下讨论仅限于以虚线边框为界的左上通道chan6。
[0022]
处理块120可以被描述为关于彼此并且参考推断方向上的信号流在“上游”或“下游”。从通道chan6开始,标记为“i”(用于“输入”)的处理块120从缓冲器115中的一个接收输入。该输入块120在左侧的下一块120上游。对于推理或“前向传播”,信息沿着完整的箭头移动通过块链120,从标记为“o”(用于“输出”)的最终下游块出现到另一级缓冲器115。对于训练或“反向传播”,信息从标记为“o”的最终下游块沿着虚线移动,从标记为“i”的最终上游块出现。
[0023]
每个块120包括四个端口,前向传播和反向传播每个有两个端口。图1左下角的符号示出了在每个块120中标识前向传播输入端口(fwdin)、前向传播输出端口(fwdout)、反
向传播输入端口(bpin)和反向传播输出端口(bpout)的阴影。在其中块120可以占据3d-ic的不同层的实施例中,块120被定向以最小化连接距离。如下文详述,每个块100包括处理元件阵列,每个处理元件可以并发处理和更新来自上游和下游处理元件和块的部分结果以支持并发的前向和反向传播。
[0024]
图2示出了被互连以支持并发的前向和反向传播的四个处理块120。细的平行的箭头组表示通过这四个块120的前向传播路径。实心箭头表示反向传播路径。在该示例中,前向和反向传播端口fwdin、fwdout、bpin和bpout是单向的,并且前向和反向传播端口集可以并发地使用。前向传播沿着顺时针方向从左上块开始穿过块120。反向传播从左下方逆时针进行。
[0025]
图3包括在单个处理块120上实例化的神经网络的功能表示300和阵列305。表示300和阵列305示出了前向传播并且为了便于说明而省略了反向传播端口bpin和bpout。下面分别详细介绍反向传播。
[0026]
功能表示300是典型的神经网络。数据从左侧传入,由一层神经元o1、o2和o3表示,每个神经元从一个或多个上游神经元接收相应的部分结果。数据从右侧离开,由另一层神经元x1、x2和x3表示,这些神经元传达了它们自己的部分结果。神经元通过加权连接w
ij
被连接,加权连接有时称为突触,其权重在训练中确定。每个权重的下标引用连接的起点和终点。神经网络按照图3所示的等式为每个输出神经元计算乘积之和。偏置项b
#
引用偏置神经元,为便于说明,此处省略偏置神经元。偏置神经元及其使用是众所周知的,因此省略了详细讨论。
[0027]
处理块120的阵列305是处理元件310、315和320的脉动阵列。在脉动阵列中,数据以逐步方式从一个处理元件传送到下一处理元件。对于每个步骤,每个处理元件根据从上游元件接收的数据计算部分结果,存储部分结果以预期下一步骤,并且将结果传递给下游元件。
[0028]
元件315和320执行与每个功能表示300的前向传播相关联的计算。此外,每个元件310中执行激活函数,该激活函数以本公开充分理解并且不必要的方式变换该节点的输出。在表示300中表示为神经元的层在阵列305中被描绘为数据输入和输出,所有计算由处理元件310、315和320执行。处理元件315包括简单的累加器,该累加器将偏差添加到累加值,而元件320包括乘累加器(mac或mac单元),每个乘累加器计算两个数的乘积并且将该乘积添加到累加值。在其他实施例中,每个处理元件320可以包括一个以上的mac。如下文详述的,处理元件310、315和320支持流水线式和并发的前向和反向传播,以最小化空闲时间并且因此提高硬件效率。图4描绘了处理元件400,该处理元件400是适合用作图3的每个处理元件320的电路系统的示例。元件400支持并发的前向和反向传播。为支持前向传播而提供的电路元件使用粗线宽突出显示。右下方的图405提供了元件400在前向传播状态之间转变的功能描述。首先,元件400接收来自上游块的部分和oj以及来自上游处理元件的前向传播部分结果∑f(如果有的话)作为输入。在一个计算周期之后,处理元件400产生已更新部分结果∑f=∑f+oj*w
jk
,并且将部分和oj传递给另一处理元件400。例如,参考图3的阵列305,标记为w
22
的处理元件320将部分和传递给标记为w
32
的下游元件,并且将输出o2传递给标记为w
23
的元件。
[0029]
返回图4,作为对前向传播的支持,处理元件400包括一对同步存储元件407和410、
前向传播处理器415、以及用于存储用于计算部分和的权重值或权重w
jk
的本地或远程存储部420。处理器415(所谓的“乘法累加”(mac))计算前向部分和并且将结果存储在存储元件410中。为了支持反向传播,处理元件400包括另一对同步存储元件425和430、反向传播mac处理器435、以及用于存储在训练期间用于更新权重w
jk
的值alpha的本地或远程存储部440。下面详细介绍了特定于反向传播的元件的功能。
[0030]
图5a到图5h每个描绘了在输出o1、o2和o3被应用于连续的处理元件320时在相应的脉动处理周期期间图3的阵列305。处理元件是相同或相似的,但是应用通过训练得到的相应权重。来自层305的四个输出中的每个输出的乘法累加结果mac
a-d
以数学方式表示。
[0031]
图5b描绘了一个处理周期之后的阵列305。具有权重w
11
的处理元件320对值o1进行计时,并且将部分和∑f=o1*w
11
传递给权重为w
21
的下游处理元件。尽管未示出,但是o1的下一值呈现在具有权重w
11
的处理元件320的输入上,以预期下一累加,保持“流水线”充满。
[0032]
接下来,在图5c中,具有权重w
12
的处理元件320对值o1进行计时,并且将部分和∑f=o1*w
12
传递给权重为w
22
的下游处理元件。同时,具有权重w
21
的处理元件320对值o2进行计时,并且将部分和∑f=o1*w
11
*o2*w
21
传递给权重为w31的下游处理元件。该过程在下一周期中继续,图5d,因此值o3开始向下传播通过阵列305并且有助于累加前向部分结果。
[0033]
转向图5e,标记为ba的累加器315将偏移添加到来自处理元件320的顶行的累加结果,并且所得到的乘积之和被处理为激活函数处理元件310应用的任何激活函数。因此产生了来自阵列305的第一前向部分结果。输出maca示出为未应用激活函数,因为该等式说明mac流经阵列305。
[0034]
图5f-图5h完成了所有四个部分和mac
a-d
的计算,因为来自神经网络的前一层的输出向下移动通过阵列305并且部分和向右移动。部分和依次呈现。尽管未示出,但每行处理元件在每个处理周期呈现连续的部分和。
[0035]
图6包括跨两个不同处理块被实例化的神经网络的功能表示600和脉动阵列605,先前详述的类型的一个块120通信耦合到下游块,该下游块包括阵列610,该阵列610具有由其相应权重k
ij
标识的八个处理元件和施加激活函数的一对处理元件。第二阵列610的处理元件可以在物理上与块120的处理元件相同。阵列605以上面结合阵列305详述的方式累加部分结果。附加层进一步从部分结果x
1-x4开始依次累加部分结果作为输入。任何数目的网络层都可以类似地组合以支持更复杂的计算。
[0036]
图7描绘了3d-ic 700,该3d-ic 700实例化图6所示的块120的阵列和神经网络的阵列610。块120集成在物理和电连接到上部管芯710,阵列610集成在上部管芯710上。在一个实施例中,脉动阵列的块相对于彼此布置和设置以最小化电连接715、导电的硅通孔的长度。可以布置处理元件以及相关电路和连接以最小化连接长度,从而最小化功耗和元件间延迟。
[0037]
在前向传播中,来自先前层(未示出)的输出o1、o2和o3传播(-y方向)通过块120,如先前详述的。部分和从右到左累加(-x)并且向上(z)传送到连接715上的阵列610作为输出x1、x2、x3和x4。然后这些输出在阵列610(x)上从左到右传播,因为部分和朝向输出out1和out2累加(-y)。
[0038]
图8a描绘了图4的处理元件400,该处理元件400具有被提供用于支持反向传播的电路元件,使用粗线宽突出显示。右下方的图表802提供了元件400在反向传播状态之间转
变的功能描述。元件400接收来自下游块的部分总和pk以及来自下游处理元件的反向传播部分结果∑b(如果有的话)作为输入。在一个计算周期之后,处理元件400向上游处理元件400产生已更新部分结果∑b=∑b+alpha*pk*oj*w
jk
。alpha通过控制响应于估计误差而改变权重的程度来指定学习速率。
[0039]
图8b描绘了类似于图4和图8a的处理元件400的处理元件800,其中相同标识的元件相同或相似。用于反向传播的mac 805包括四个乘法器和两个加法器。mac 805存储两个学习速率值alpha1和alpha2,它们可以不同地调节反向传播计算。对于每个计算,可能需要添加比例因子来强调或不强调计算对旧值的影响程度。在其他实施例中,处理元件可以具有更多或更少的乘法器和加法器。例如,可以通过重用硬件(例如,乘法器或加法器)来简化处理元件800,尽管这样的修改可能会降低处理速度。
[0040]
图9a-图9h示出了在反向传播期间通过以图7所示的方式互连的处理块120和阵列610的信息流。对于反向传播,在神经网络的最后一层执行的计算不同于所有其他层的计算。等式可能因实现而异。以下示例说明了用于输出层以外的层的硬件,因为它们需要更多的计算。
[0041]
图9a示出了简单的神经网络900,神经网络900包括输入层x[2:0]、隐藏层y[3:0]和产生误差e[1:0]的输出层z[1:0]。输出层的神经元z0(神经元也称为“节点”)在左下方示出为分为net
o0
和out
o0
。隐藏层的神经元y0在右下方示出为分为net
y0
和out
y0
。每个神经元设置有相应偏差b。为了便于说明,该图形表示表示支持如本文详述的并发的前向和反向传播的处理元件的脉动阵列。
[0042]
反向传播的输出层计算使用上一步的总误差。以数学方式表示n个输出outo:
[0043][0044]
在网络900中,n=2。每个权重的梯度是基于每个权重对总误差e
total
的贡献来计算的。对于每个输出节点o{
[0045]
对于连接到输出节点o的每个传入权重/偏差{
[0046]
使用链式法则确定权重/偏差的误差贡献并且对其进行调节。该图假定例如sigmoid激活函数,其导数是下面的等式4。考虑来自输出节点z0的总误差e
total
:
[0047][0048][0049]
[0050][0051][0052]
}
[0053]
}
[0054]
反向传播的隐藏层计算也是基于总误差,但等式不同。例如,一个实施例的工作方式如下:对于每个隐藏节点y{
[0055]
使用链式法则确定权重的误差贡献并且对其进行调节:
[0056][0057][0058][0059][0060][0061][0062]
}
[0063]
}
[0064]
如果神经网络有多个隐藏层,则误差项e
total
是下一层节点的误差,其可以通过节点的实际输出与期望输出之间的差异来计算。当调节下一层时,在上一次迭代中计算期望输出。
[0065]
反向传播从输出到输入起作用,因此在计算当前层的调节时,前一层的调节是已知的。该过程可以概念化为三层节点之上的滑动窗口,其中查看最右边层的误差并且使用它们来计算对进入窗口中间层的权重的调节。
[0066]
参考图9b,反向传播开始于计算相应节点node1和node2的输入z1和z2,每个输入z1和z2是激活函数导数与实际输出和期望输出之间的差异的乘积。
[0067]
转到图9c,权重k
41
的处理元件(1)将值x4传递给权重k
42
的处理元件,(2)将值z1传递给权重k
31
的处理元件,以及(3)计算并且存储已更新权重k
41
=k
41-alpha*z1*x4。接下来,如图9d所示,权重k
31
的处理元件的行为类似以更新权重k
31
(k
31
=k
31-alpha*z1*x3)。并发地,权重为k
42
的处理元件传递值z2,更新权重k
42
,并且将部分和p4=k
41
*alpha*z1*=x4+k
42
*alpha*z2*x4)传递给下层中权重为w
34
的处理元件。上层的其余处理元件的行为类似以更新它们的每个权重并且生成部分结果p
1-p3(图9e-图9g)。
[0068]
图9h示出了信号如何在反向传播中穿过下层(管芯705)。部分结果p
1-p4一起示出,但实际上,离开上层(管芯710)以便以相反的数字顺序进入下层,如图9b-图9g所示。为简洁起见,部分结果r
1-r3被描述为完整的数学表达式,而不是像对上层所做的那样逐步完成每个周期。
[0069]
图10描绘了根据另一实施例的作为人工神经网络应用的管芯堆叠1000。半导体管芯(例如,asic)1005是一种ic,它结合了处理元件或处理元件的块作为集成电路管芯(例如,dram管芯)堆叠内的一个或多个基础层。这些层被示出为单独的,但将被制造为使用例如硅通孔(tsv)或cu-cu连接而互连的堆叠的硅晶片或管芯,以便堆叠充当单个ic。在其他实施例中,管芯可以是分开的或在分开的堆叠中。
[0070]
顶层是半导体管芯1005,半导体管芯1005的电路系统与图1的asic 100的电路系统相似,相同标识的元件相同或相似。处理元件和相关组件互操作以进行前向和反向传播,例如以上面详述的方式。下层是存储器管芯1010,在这个示例中是dram,存储体1015布置成与处理元件120建立相对较短的连接。存储体1015形成具有垂直拱顶的高带宽存储器,用于存储例如部分结果。处理元件120因此可以访问高带宽存储器以支持例如学习和推理计算。存储体1015可以是完整的存储体或存储体的部分(例如,位单元组)。
[0071]
卷积神经网络
[0072]
卷积神经网络(cnn)通常用于例如图像分析。与上述示例一样,cnn可以使用脉动阵列来实现。在图像处理中,表示为像素值的二维矩阵的图像与一个或多个“内核”进行卷积。每个内核(表示为值小于图像矩阵的二维矩阵)在图像矩阵上滑动——通常从左上角开始——到内核矩阵适合的图像矩阵上的所有位置。例如,3
×
3内核矩阵可以在更大的图像矩阵中的每个3
×
3像素值分组上滑动。为每个分组记录内核矩阵和底层像素值分组的点积,以产生已过滤图像矩阵。
[0073]
卷积脉动阵列中的处理元件不同于先前结合例如图3详述的那些。反映它们在应用内核中的用途,卷积节点局部连接到其前一层的宽度和高度的小区域(例如,3
×
3或5
×
5的图像像素邻域),称为感受野。隐藏层权重可以采用应用于感受野的卷积滤波器的形式。
[0074]
图11描绘了3d-ic 1100,该3d-ic 1100使用一对物理和电互连的ic管芯1105来实例化cnn,每个ic管芯1105包括卷积处理元件(cpe)1110的脉动阵列。cpe 1110可以分组在块中,块相对于彼此布置和设置以最小化电连接1115的长度。虽然未示出,但每个cpe 1110具有存储器或可以访问存储器,例如dram存储器单元。
[0075]
cpe 1110的计算资源为本领域技术人员所熟知,因此省略详细讨论。简而言之,每个cpe 1110包括例如乘法器、加法器、整流线性单元、池化模块、以及用于存储输入、权重和部分和的寄存器。乘法器和加法器执行卷积以获取部分和。整流后的线性单元将合适的激活函数应用于部分和。每个cpe中的池化模块实现最大或平均池化操作,该操作存储在本地
缓冲器中。cpe 1110可以适于交替地支持卷积或其他功能,例如归于图3的处理元件320的功能。在上部和下部管芯1105两者中,部分和通过cpe 1110在相同方向上从右到左(-x)累加。然而,数据在相反方向上流动,在上部管芯1105中从上到下(-y),在下部管芯1105中从下到上(y)。管芯1105边缘处的连接1115允许部分和和数据在循环1120中流动到不同管芯中的最近邻cpe 1110。这些相对较短的信号路径以最小的功率和延迟沿着z维度传送信号。
[0076]
cnn通常将一个以上的内核应用于给定数据集(例如,图像矩阵)。3d-ic 1100将多个内核并发应用于同一数据集,从而节省时间。对在循环1120中流动的数据的支持允许3d-ic以将内核并发应用于数据集的不同部分的方式在图像数据上旋转多个内核。这种循环提高了并行性,进而提高了效率和速度性能。
[0077]
图12a-图12f包括图11的3d-ic 1100的简化视图,以将每个ic管芯1105示出为3
×
3脉动阵列,其中每个元件是cpe 1110。这些视图示出了3d-ic 1100如何利用ic管芯1105之间的数据嵌套循环,以实现快速高效的卷积。
[0078]
从说明mac循环的图12a开始,六个内核k1-k6被加载到上部和下部管芯1105的处理元件1110中。每个内核k#被分成三个子内核k#1、k#2,和k#3以匹配硬件的能力。接下来,如图12b所示,激活的小块1200(例如,图像矩阵1202的部分)被分割并且映射到处理元件1110,以再次匹配硬件的能力。然后激活1200通过cpe 1110与子内核交互(图12c),使得部分和在上层从右到左(-x)累加,在下层从左到右(x)累加。这个过程为每个内核生成乘法/累加输出。
[0079]
图12d示出了下一运动,即内核k1到k6在第一内核跨度循环中的运动,使得每个内核遇到cpe 1110的每一行至少一次。内核在每个管芯1105(
±
y)内以及在管芯1105(
±
z)之间在平面内移动,交替的管芯以相反的方向通过内核。然后,在图12e中,每个管芯1105中的激活1200的行被移动到同一管芯中的另一行。如右侧所示,该移动具有在图像数据1202上向下跨过内核k#的效果。
[0080]
在最后的移动中,如图12f所示,激活行1200从一列cpe 1110移动到另一列,从左到右(x)穿过底部ic管芯1105,直到顶部ic管芯1105(z)并且从右到左(-x)穿过顶部ic管芯1105。这种数据移动具有在图像1202之上向右跨过内核k#的效果,与图12e的效果正交,如上图所示图12f的右侧。
[0081]
图13描绘了具有前向传播输入开关1305和反向传播输入开关1310的块1300的四个实例,前向传播输入开关1305和反向传播输入开关1310一起支持上面结合图12a-图12f详述的连接性和相关信号流。在该实施例中,块1300还支持以上归于块310、315和320中的一个或多个的功能。
[0082]
块1300包括前向传播输入端口1315、前向传播输出端口1320、反向传播输入端口1325和反向传播输出端口1330。虽然未示出,但块1300另外包括前面详述的用于执行卷积的类型的cpe 1110的脉动阵列。每个开关1305可以根据信号的路由方式被置于四种模式中的一种。这些模式被描述为将信息传送到前向传播输入端口1315的第一直通模式(左上);绕过对应的前向传播输入端口1315的第二直通模式(右上);结合前两种模式的多通道模式(左下);以及旋转模式(右下)。
[0083]
图14a-图14d描绘了设备架构1400,其中四个处理块1300可以通过开关1305和1310互连以实现用于卷积神经网络或用于在图3中详述的类型的处理元件网络的脉动阵
列。架构1400支持前向和反向传播两者,无论是单独的还是并发的。其他实施例可以限于卷积、推理等。在该示例中,开关与块之间的信号路径是单向的。架构1400表示用于说明性大小和复杂性的过滤器的路径。对于更大的过滤器,可以根据需要使用类似的路由和交换在更大的距离上(例如,在更多的块之间)传递数据。
[0084]
图14b示出了开关1305和1310如何被配置用于并发的前向传播(推理)和反向传播(模型参数的调节)。该配置如上文结合图2详述的那样起作用;不执行卷积。前向信号路径进入左上块1300的前向输入端口1315,并且在顺时针方向上穿过剩余的下游块。延伸到前向输入端口1315与从前向输出端口1320延伸之间的信号路径使用常见的阴影样式突出显示。反向信号路径通过反向传播输入以及输出端口1325和1330沿着公共阴影的信号路径在相反的上游方向上前进。在该模式下不使用无阴影的信号路径。前向和反向传播可以单独或并发进行。
[0085]
图14c示出了架构1400的开关1305和1310如何被配置为卷积模式以支持以图12e所示的方式移动内核。交换机1305将一些块1300的反向传播输出端口1330连接到相邻块1300的前向传播输入端口1315。
[0086]
图14d示出了架构1400的开关1305和1310如何被配置为另一卷积模式以支持以图12f所示的方式移动内核。交换机1305和1310将一些块1300的前向传播输出端口1320连接到相邻块1300的反向传播输入端口1325。
[0087]
尽管已经结合特定实施例描述了主题,但也可以设想其他实施例。例如,为了便于说明,前述实施例详述了相对简陋的块和阵列;阵列的数目和每个阵列的处理元件变化很大,实际的神经网络可以有更多的阵列并且每个阵列可以有更多的处理元件。其他变化对于本领域技术人员将是很清楚的。因此,所附权利要求的精神和范围不应限于前述描述。只有那些明确引用“手段”或“步骤”的权利要求才应按照35u.s.c.
§
112的第6段所要求的方式进行解释。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1