一种基于双模型的水华预测方法和装置与流程
本发明涉及水华预测领域,特别是指一种基于双模型的水华预测方法和装置。
背景技术:
近年来,由于人们大规模的生产,水体富营养化现象越来越普遍,造成了严重的水生态问题。水华是水体富营养化的典型特征之一,水华的爆发,破坏了生态系统结构,严重制约了经济建设和社会发展。水华已成为国内外治理的一大难题。因此,深入研究藻类水华的爆发过程,并对其爆发过程进行有效的预测和模拟具有重要意义。
目前,水华生成过程建模方法主要包括数据驱动建模和机理驱动建模。数据驱动建模主要是通过采集的大量数据建立多个量影响某个量或某几个量的线性关系或者非线性关系。该模型不需要分析其内部机理,只根据研究对象中的输入输出数据之间的关系进行建模,主要适用于很难从机理分析中发现系统规律的高度非线性和严重不确定系统。机理驱动模型主要包括生态变量和待定参数。它是从水华形成的过程机理出发,通过物理、化学规律建立关键变量与其它可测变量之间的数学方程,经推导后建立起来的描述形成过程的方程组的数学模型。由于藻类水华的爆发现象非常复杂,使得系统的结构性质并不清楚,因此单纯的机理驱动的建模方法并不适合随机性强梯级湖库汇流藻类水华预测。而在现有的水华预测方法中,大多采用单一的数据驱动模型,如一些神经网络模型、回归模型等等,但它们都限于常期静态稳定的湖库,对随机性很强的湖库汇流尚无短期预测成功案例。
时间序列分析法是根据系统观测到的时间序列数据通过曲线拟合和参数估计来建立数学模型的理论和方法。该方法适于描述和预测水华生成的随机过程,进而建立水华形成的时序模型。时间序列分析法的特点在于在已建立的模型中引入了时间变量,仅仅依靠过去时刻的若干组数据就可以对未来时刻的数据进行预测,这恰恰也反映了水华的生成过程是一个具有时变特性的动态过程。然而,传统的时间序列模型只适用于线性系统的建模分析,而水华的形成过程具有高度的非线性特征,故传统的时间序列模型并不适用。
技术实现要素:
本发明的主要目的在于克服现有技术中的上述缺陷,提出一种基于双模型水华预测方法,通过非常数指数修正改进的马尔萨斯模型(malthusianmodel)和逻辑斯蒂阻滞增长(logisticgrowthmodel)数学模型,充分考虑了水华的形成过程具有高度的非线性特征,能够实现水华的准确预测。
本发明采用如下技术方案:
一种基于双模型的水华预测方法,包括如下步骤:
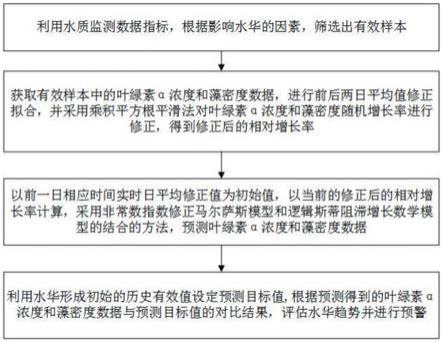
利用历史水质监测数据指标,根据影响水华的因素,筛选出有效特征样本;
获取有效样本中的叶绿素α浓度和藻密度数据,进行前后两日平均值修正拟合,并采用乘积平方根平滑法对叶绿素α浓度和藻密度随机增长率进行修正,得到修正后的相对增长率;
以前一日相应时间实时日平均修正值为初始值,以当前的修正后的相对增长率计算,采用非常数指数修正马尔萨斯模型和逻辑斯蒂阻滞增长数学模型的结合的方法,初期预测采用指数增长保证灵敏探测到水华趋势的苗头,超过目标预测值后转阻滞模型以缩小后期预测偏差,部分预测曲线与实测曲线整体走势完美契合,预测叶绿素α浓度和藻密度数据;
利用水华形成初始的历史有效值设定预测目标值;根据预测得到的叶绿素α浓度和藻密度数据与预测目标值的对比结果,评估水华趋势并进行预警。
具体地,所述影响水华的因素包括但不限于:温度、氮水平和磷水平。
具体地,所述获取有效样本中的叶绿素α浓度和藻密度数据,进行前后两日平均值修正拟合,具体为:
其中,t为自变量,取离散等距整数值:t=0,1,2,...,单位为小时,x(t)为实时值,
具体地,采用乘积平方根平滑法对叶绿素α浓度和藻密度随机增长率进行修正,得到修正后的相对增长率,具体包括:
增长率r(t)和相对增长率r(t)是t的非单调递增离散函数;
在δt时间段里,相对增加量计算为:
其中r′(t)为修正后得到的相对增长率。
具体地,以前一日相应时间实时日平均值为初始值,以当前的相对增长率计算,采用马尔萨斯非常数指数修正模型和逻辑斯蒂阻滞增长数学模型的结合的方法,预测叶绿素α浓度和藻密度数据,具体包括:所述马尔萨斯非常指数修正模型为:
x(t)=x(t-δt)er(t)δt
当t=t+δt时刻:
x(t+δt)=x(t)er(t+δt)δt
r(t+δt)≈r(t)+(r(t)-r(t-δt))=2*r(t)-r(t-δt)。
具体地,以前一日相应时间实时日平均值为初始值,以当前的相对增长率计算,采用马尔萨斯非常数指数修正模型和逻辑斯蒂阻滞增长数学模型的结合的方法,预测叶绿素α浓度和藻密度数据,具体包括:所述逻辑斯蒂阻滞增长数学模型为:
对于连续的逻辑斯蒂阻滞增长数学模型为:
对于离散的逻辑斯蒂阻滞增长数学模型为:
其中xm为阻滞参数,r为速率参数,δx为相邻两个时刻的差值。
具体地,所述xm的预估方法,具体为:
由:
当x(t+1)≈x(t),得:
xm≈x(t)≈x(t+1)。
可推知xm约为实测最大值。xm可通过历史数据,由历史边界预估。具体地,所述方法用于梯级拦坝的湖库汇流。
本发明另一方面还提供了一种基于双模型的水华预测装置,包括如下:
数据筛选模块:利用历史水质监测数据指标,根据影响水华的因素,筛选出有效样本;
修正模型:获取有效样本中的叶绿素α浓度和藻密度数据,进行前后两日平均值修正拟合,并采用乘积平方根平滑法对叶绿素α浓度和藻密度随机增长率进行修正,得到相对增长率;
预测模块:以前一日相应时间实时日平均值为初始值,以当前的相对增长率计算,采用非常数指数修正马尔萨斯模型和逻辑斯蒂阻滞增长数学模型的结合的方法,预测叶绿素α浓度和藻密度数据;
评估预警模块:利用水华形成初始的历史有效值设定预测目标值;根据预测得到的叶绿素α浓度和藻密度数据与预测目标值的对比结果,评估水华趋势并进行预警。
由上述对本发明的描述可知,与现有技术相比,本发明具有如下有益效果:
(1)本发明采用非常数指数修正马尔萨斯模型和逻辑斯蒂阻滞增长数学模型的结合的方法,充分符合藻类生成的非匀速增长的本质,且通过两种模型结合预测叶绿素α浓度和藻密度数据,实现了湖库汇流复杂情况下,繁杂藻类自身整体规律形成的随机数的短期预测,极大减小了预测误差,提高了预测精度。
(2)本发明在根据模型预测时,以前一日相应时间实时日平均值为初始值,以当前的修正后的相对增长率计算,且为了减少随机数据的误差,进行前后两日平均值修正拟合(使平均值更接近实测值),得到日平均值修正数据,并采用乘积平方根平滑法对叶绿素α浓度和藻密度随机增长率进行修正(曲线平滑削尖避免过拟合),得到修正后的相对增长率;本发明提出的平滑修正方法,能够消除现有技术中平滑存在的滞后问题,实现更准确的预测。
附图说明
图1是本发明实施例提出方法的整体流程图;
图2是逻辑斯蒂阻滞增长数学模型中阻滞参数xm的预估示意图,其中图(a)为某汇流断面9月蓝藻阻滞参数xm随机连续3天的示意图,图(b)为某汇流断面9月叶绿素α阻滞参数xm随机连续3天的示意图;图(c)为某汇流断面2月蓝藻阻滞参数xm随机连续3天的示意图;图(d)为某汇流断面2月叶绿素α阻滞参数xm随机连续3天的示意图;
图3是采用非常指数修正马尔萨斯模型和逻辑斯蒂阻滞增长数学模型的结合的方法预测叶绿素α浓度和藻密度数据示意图;图(a)是厦门某汇流9月蓝藻密度预测,其中图(b)是厦门某汇流9月叶绿素α浓度预测,其中图(c)是厦门某汇流1-2月蓝藻密度预测,其中图(d)是厦门某汇流1-2月叶绿素α浓度预测。
以下结合附图和具体实施例对本发明作进一步详述。
具体实施方式
本发明提出的方法包括:输入时序连续随机数,确定单位时间;利用前后单位时间平均法,滤波平滑前后2日平均值修正数据,得到日平均值修正数据;利用乘积平方根平滑法平滑前后2日随机增长率得到修正后的相对增长率;以前一日相应时间实时日平均值为初始值,以当前的修正后的相对增长率计算,采用非常数指数修正马尔萨斯模型和逻辑斯蒂阻滞增长数学模型的结合的方法,预测叶绿素α浓度和藻密度数据;并根据所述日平均值修正数据得到水华趋势的等效势能,根据所述修正后相对增长率得到水华趋势的等效动能,并利用水华趋势的势能和水华趋势的动能计算得出生物等效能量增长率;利用水华形成初始的历史有效值设定预测目标值,根据预测得到的叶绿素α浓度和藻密度数据与预测目标值的对比结果,以及生物等效能量增长率,共同评估水华趋势并进行预警。
如图1是本发明实施例提供的一种结合双模型和生物等效能量的水华预测方法的流程图,具体步骤如下:
s101:利用水质监测数据指标,根据影响水华的因素,筛选出典型有效样本;
获取厦门江东自动水质监测站水质监测数据,温度、氮水平和磷水平是导致浮游植物群落变化的重要影响因素,共选取了33413条有效数据来分析叶绿素α浓度和藻密度相应的水华趋势,本实施例中选取梯级拦坝的湖库汇流。
s102:获取有效样本中的叶绿素α浓度和藻密度数据,进行前后两日平均值修正拟合,得到日平均值修正数据,并采用乘积平方根平滑法对叶绿素α浓度和藻密度随机增长率进行修正,得到修正后的相对增长率;
获取有效样本中的叶绿素α浓度和藻密度连续数据,进行前后两日平均值修正拟合,过滤平滑数据随机性,得到日平均值修正数据,具体为:
其中,t为自变量,取离散等距整数值:t=0,1,2,...,单位为小时;x(t)为时序随机数;
现有技术中,常用的平均值修正方法通常是求取前一日的平均值,这样得出的平均值较实际值存在明显的滞后,滞后时间大致为一日,影响后续的预测效果,在本发明实施例中采取的是前后两日平均值的拟合,很好的解决了修正平均值的滞后问题,且较为准确。
由于数据均为随机的时序数据,各时刻的数据较为随机,如果用于后续计算必须进行平滑修正,这里采用的是乘积平方根平滑法;采用乘积平方根平滑法对前后两日的叶绿素α浓度和藻密度随机增长率进行修正,得到修正后的相对增长率,具体为:
其中,t为自变量,取离散等距整数值:t=0,1,2,...,单位为小时;
另一实施例中,也可以通过另外一个方式实现随机增长率的修正s103:以前一日相应时间实时日平均值为初始值,以当前的修正后的相对增长率计算,采用非常数指数修正马尔萨斯模型和逻辑斯蒂阻滞增长数学模型的结合的方法,预测叶绿素α浓度和藻密度数据;
具体地,以前一日相应时间实时日平均值为初始值,以当前的修正后的相对增长率计算,采用非常数指数修正马尔萨斯模型和逻辑斯蒂阻滞增长数学模型的结合的方法,预测叶绿素α浓度和藻密度数据,具体包括:所述非常数指数修正马尔萨斯模型为:
x(t)=x(t-δt)er(t)δt
当t=t+δt时刻:
x(t+δt)=x(t)er(t+δt)δt
r(t+δt)≈r(t)+(r(t)-r(t-δt))=2*r(t)-r(t-δt)。
具体地,以前一日相应时间实时日平均值为初始值,以当前修正后的相对增长率计算,采用非常指数修正马尔萨斯模型和逻辑斯蒂阻滞增长数学模型的结合的方法,预测叶绿素α浓度和藻密度数据,具体包括:所述逻辑斯蒂阻滞增长数学模型为:
对于连续的逻辑斯蒂阻滞增长数学模型为:
对于离散的逻辑斯蒂阻滞增长数学模型为:
其中xm为阻滞参数,r(t)为相对增长率速率参数,δx为相邻两个时刻的差值。
具体地,所述xm的预估方法,具体为:
由:
当x(t+1)≈x(t),得:
xm≈x(t)≈x(t+1)。
可推知xm约为实测最大值,xm可通过历史数据,由历史边界预估。
如图2,为逻辑斯蒂阻滞增长数学模型中阻滞参数xm的预估示意图,其中图(a)为某汇流断面9月蓝藻阻滞参数xm随机连续3天的示意图,图(b)为某汇流断面9月叶绿素α阻滞参数xm随机连续3天的示意图;图(c)为某汇流断面2月蓝藻阻滞参数xm随机连续3天的示意图;图(d)为某汇流断面2月叶绿素α阻滞参数xm随机连续3天的示意图;从图中可以看出,以随机连续3天的2日平均值估算,阻滞参数xm的计算结果接近该段2日平均值的最大值,与理论推导一致,且经数值计算,最大偏差约12%,为包络实测最大值,可以近似采取过去3天的最大值与实时增长率n日次方的乘积为阻滞参数xm。或根据历史最大值作为初始边界xm。
s104:利用水华形成初始的历史有效值设定预测目标值;根据预测得到的叶绿素α浓度和藻密度数据与预测目标值的对比结果,评估水华趋势并进行预警。
如图3是采用非常指数修正马尔萨斯模型和逻辑斯蒂阻滞增长数学模型的结合的方法预测叶绿素α浓度和藻密度数据示意图,其中图(a)是厦门某汇流9月蓝藻密度预测,其中图(b)是厦门某汇流9月叶绿素α浓度预测,其中图(c)是厦门某汇流1-2月蓝藻密度预测,其中图(d)是厦门某汇流1-2月叶绿素α浓度预测;
从图中可以看出,本实施例中根据《基于藻密度评价的水华程度分级标准》和现有技术设定的蓝藻密度的预测目标值为3000万个/升,对应的叶绿素α浓度值为150μg/l,以图(a)为例,可以看出,第6天蓝藻密度的预测曲线走向超过了预测目标值为3000万个/升,且同样在第7-9天蓝藻密度的预测曲线走向都超过了预测目标值为3000万个/升,这说明根据本发明提出的预测模型预测的蓝藻密度曲线,从第6天开始就预测到水华的发生,且根据蓝藻密度实测值与预测目标值的曲线走向可知,两者在第12天左右发生了相交,之后藻密度实测值呈现更高的值,这说明在第12天实际发生了水华。从图中数据表明,本发明提出的预测模型能够很好地且较早地预测出水华的发生,能够为及时治理提供更多的时间。
另外,拟合结果表明,在水华成形期间,相对于仅参照前一日的日平均值,本发明提出的日平均值修正方法得到的日平均值更接近实测值平均偏差约0%,缩小偏差约4.9-8.5%。最终逼近值的连续预测曲线与日平均值比对验证,偏差小于15%。这比现有技术中提出的预测模型的偏差都小。
此外,本发明实施例还提供一种基于双模型的水华预测装置,包括如下:
数据筛选模块:利用历史水质监测数据指标,根据影响水华的因素,筛选出有效样本;
修正模型:获取有效样本中的叶绿素α浓度和藻密度数据,进行前后两日平均值修正拟合,并采用乘积平方根平滑法对叶绿素α浓度和藻密度随机增长率进行修正,得到相对增长率;
预测模块:以前一日相应时间实时日平均值为初始值,以当前的相对增长率计算,采用非常数指数修正马尔萨斯模型和逻辑斯蒂阻滞增长数学模型的结合的方法,预测叶绿素α浓度和藻密度数据,初期预测采用指数增长保证灵敏探测到水华趋势的苗头,超过目标预测值后转阻滞模型以缩小后期预测偏差,部分预测曲线与实测曲线整体走势完美契合;
评估预警模块:利用水华形成初始的历史有效值设定预测目标值;根据预测得到的叶绿素α浓度和藻密度数据与预测目标值的对比结果,评估水华趋势并进行预警。
综上,本发明采用非常数指数修正马尔萨斯模型和逻辑斯蒂阻滞增长数学模型的结合的方法,初期灵敏探测,后期缩小偏差,整体走势完美契合,充分符合藻类生成的非匀速增长的本质,且通过两种模型结合预测叶绿素α浓度和藻密度数据,极大了减小了预测误差,提高预测精度;此外,本发明在根据模型预测时,以前一日相应时间实时日平均值为初始值,以当前的修正后的相对增长率计算,且为了减少随机数据的误差,进行前后两日平均值修正拟合,得到日平均值修正数据,并采用乘积平方根平滑法对叶绿素α浓度和藻密度随机增长率进行修正,得到修正后的相对增长率;本发明提出的平滑修正方法,能够消除现有技术中平滑存在的滞后问题,实现更准确的预测。本发明因解决了随机性数学根本问题,而具有普适性。
上述仅为本发明的具体实施方式,但本发明的设计构思并不局限于此,凡利用此构思对本发明进行非实质性的改动,均属于侵犯本发明保护范围的行为。
- 还没有人留言评论。精彩留言会获得点赞!