一种基于合成注意力机制的生成对抗网络
1.本发明属于深度学习领域,具体涉及合成注意力机制在生成对抗网络中的应用。
背景技术:
2.生成对抗网络(gan)最早出现在ian goodfellow的文章《generative adversarial networks》中,该文章首次提出“生成器-判别器”进行对抗训的方式。即生成器用来生成假样本,判别器用来判定样本的真假,通过交替训练,最终达到生成器生成的样本具有以假乱真的能力。研究生成对抗网络的意义不仅仅在于获得具有以假乱真能力的生成器,更重要的是说明我们掌握了一种概率模型和推断方法。
3.早期的gan面临一系列问题,如模型架构,训练过程的稳定性、收敛性、梯度消失,生成器的模式坍缩。dcgan(deep convolution gan)的出现为解决这一系列问题奠定了基础,dcgan提出一种生成器和判别器的架构,这两个架构能极大地稳定gan的训练。pggan(progressive growing gan)提出了一种渐进地训练策略使得生成器可以生成分辨率更大的高清图片。wgan(wasserstein gan)通过提出权值裁剪避免了gan的梯度消失问题,在wgan的基础上提出来的wgan-gp提出梯度惩罚来代替权值裁剪,实现了比wgan训练更稳定,生成的图像质量更高的目的。sagan(self-attention gan)通过将自然语言处理领域的注意力机制引入生成对抗网络,从而解决了基于卷积神经网络的gan的感受野范围太小的问题。
4.本发明提出的基于合成注意力机制的生成对抗网络syngan(synthesizer attention gan)通过改变sagan(self-attention gan)中自注意力矩阵的计算,使用合成器(synthesizer)生成注意力矩阵,解决了基于自注意力机制的生成对抗网络训练过程占用显存大,生成器易出现模式坍缩等问题。
技术实现要素:
5.为解决上述现有技术的不足,本发明提供一种基于合成注意力机制,可为生成对抗网络提供一种捕获长距离特征的能力。
6.为实现上述目的,本发明采用的技术方案为。
7.一种基于合成注意力机制的生成对抗网络,其特征在于建立含有谱归一化层,合成注意力层的生成器和判别器模型,结果表明在celeba数据集下,合成注意力生成对抗网络的fid(frechet inception distance)值从自注意力生成对抗网络的29.11降至26.4,且训练过程更稳定,包括以下步骤。
8.s1、对生成器(generator)和判别器(discriminator)的权重进行谱归一化(spectral normalization)以提高训练过程的稳定性。
9.s2、对生成器和判别器都使用合成注意力层来捕获数据的长距离特征。
10.进一步地,步骤s1中对生成器和判别器使用谱归一化的方法为。
11.s1-1:使用正态分布初始化列向量
12.s1-2:使用未归一化权值矩阵w∈rh×w通过幂迭代的方法计算列向量
13.s1-3:使用更新后的列向量3:使用更新后的列向量计算矩阵谱范数σ(w)。
14.s1-4:使用矩阵谱范数对未归一化矩阵w∈rh×w进行谱归一化。
15.进一步地,所述步骤s2中对生成器和判别器使用合成注意力层的具体方法为。
16.s2-1:输入数据与叉乘获得fa∈rn×n。
17.s2-2:输入数据x∈rc×n与wg∈rb×c叉乘获得fb∈rb×n。
18.s2-3:输入数据x∈rc×n与wa∈rc×c叉乘获得v∈rc×n。
19.s2-4:矩阵fa沿着第一个维度复制b份获得ha∈rn×n。
20.s2-5:矩阵fb沿着第一个维度复制a份获得hb∈rn×n。
21.s2-6:矩阵ha和矩阵hb对应位置元素相乘获得e∈rn×n。
22.s2-7:矩阵e第二维应用softmax归一化操作获得合成注意力矩阵a∈rn×n。
23.s2-8:矩阵v与矩阵a进行叉乘获得矩阵。
24.s2-9:矩阵o乘系数与输入数据x相加获得最终输出。
25.针对谱归一化的上述功能,提供谱归一化层作为合成注意力生成对抗网络稳定训练的应用。
26.针对合成自注意力机制的上述功能,提供合成注意力层作为合成注意力生成对抗网络降低显存占用,减少模式坍缩的应用。
27.一种包含谱归一化层与合成注意力层的生成对抗网络。
28.本发明相对于现有技术具有如下的优点及效果。
29.1、本发明舍弃自注意力机制计算输入数据的注意力矩阵的过程,采用根据输入数据合成的注意力矩阵,减少了网络训练时间。
30.2、本发明通过将合成注意力矩阵分解,不但可以减少网络训练参数数量,还在预防网络过拟合方面起到作用。
附图说明
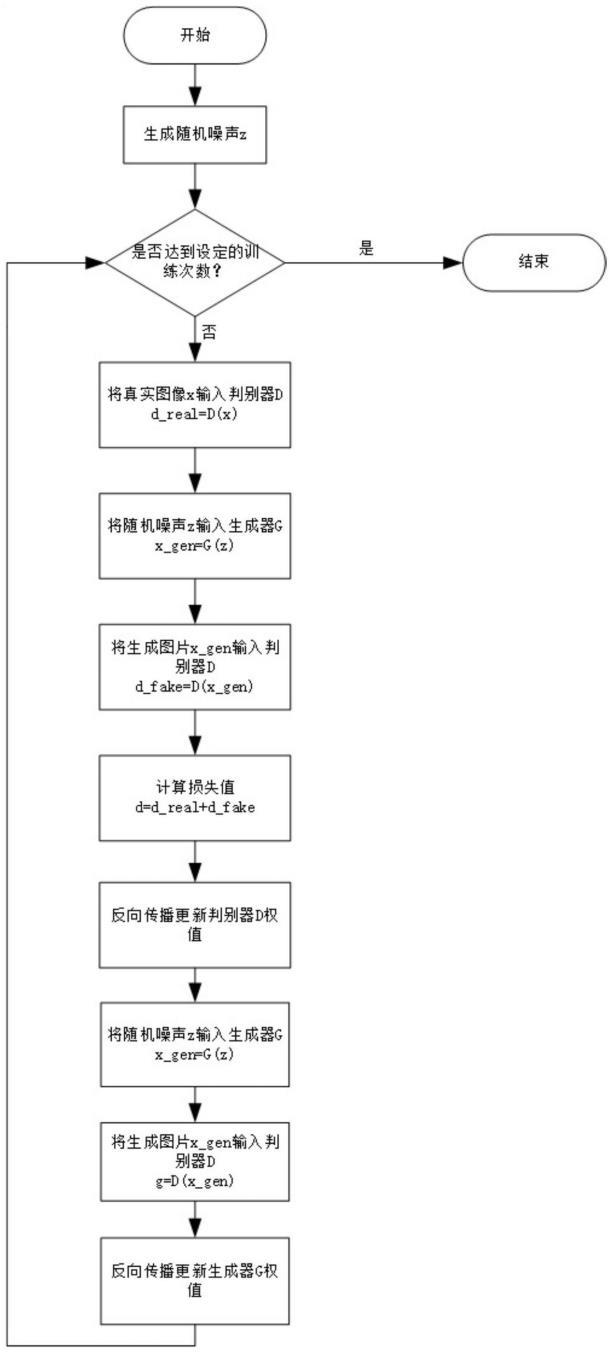
31.图1为训练生成对抗网络的流程图。
32.图2为本发明合成注意力机制的架构图,其中符号表示矩阵对应位置元素相加,表示矩阵乘法。
具体实施方式
33.以下实施例用于说明本发明,但不用来限制本发明的范围。
34.实施例1基于合成注意力机制的生成对抗网络的建立包括以下步骤。
35.步骤1:建立谱归一化层,用来嵌入生成器和判别器。
36.步骤2:建立合成注意力层,用来嵌入生成器和判别器。
37.步骤3:将谱归一化层和合成注意力层嵌入生成器。
38.步骤4:将谱归一化层和合成注意力层嵌入判别器。
39.步骤1中谱归一化层的具体实现方法为。
40.(1)使用正态分布初始化列向量
41.(2)用未归一化权值矩阵w∈rh×w更新列向量更新列向量
42.(3)使用更新后的列向量(3)使用更新后的列向量计算矩阵谱范数σ(w),
43.(4)使用矩阵谱范数对未归一化矩阵进行谱归一化,
44.步骤2中合成注意力层的具体实现方法为。
45.(1)输入数据x∈rc×n与wf∈ra×c叉乘获得fa∈ra×n,v
a-wfx。
46.(2)输入数据x∈rc×n与wg∈rb×c叉乘获得fb∈b×n,f
b-wgx。
47.(3)输入数据x∈rc×n与wa∈rc×c叉乘获得v∈rc×n,v=wax。
48.(4)矩阵fa沿着第一个维度复制份获得ha∈rn×n。
49.(5)矩阵fb沿着第一个维度复制a份获得hb∈rn×n。
50.(6)矩阵ha和矩阵hb对应位置元素相乘获得e∈rn×n。
51.(7)矩阵e第二维应用softmax归一化操作获得合成注意力矩阵a∈rn×n。
52.(8)矩阵v与矩阵进行叉乘获得矩阵o∈rc×n,o=v
×
a。
53.(9)矩阵o乘系数γ与输入数据x相加获得最终输出y∈rc×n,y=x+γo。
54.步骤3中的生成器可以为任意由卷积网络组成的生成器架构。
55.步骤4中的判别器可以为任意由卷积网络组成的判别器架构。
56.实施例2主要实验方法说明。
57.生成对抗网络的建立完成后即可按照图1训练生成对抗网络的流程图来对网络进行训练。
58.现对一些训练参数进行说明。
59.训练批大小设为64,总迭代次数设为1000000,训练采用的celeba数据集共包含202599张图片,所以对网络进行了315次训练,每1次训练完成将生成器和判别器网络参数保存,以便后续对网络生成质量进行评估。
60.生成器和判别器均使用adam优化器对网络权值进行更新,β1设为0,β2设为0.9。生成器的学习率设为0.0001,判别器的学习率设为0.0004。合成注意力层的参数γ初始值为0。
61.实施例3生成器的生成结果评估。
62.本实施例通过计算生成器生成样本的fid值来评价生成器的优劣,fid是计算真实图像和生成图像的特征向量之间距离的一种度量,更低的数值意味着生成样本的分布更逼近原始数据。fid值的具体计算公式为,
63.其中μ
x
表示真实图像的特征均值,μg为生成图像的特征均值,∑
x
为真实图像的协方差矩阵,∑g为生成图像的协方差矩阵,tr(
·
)为矩阵的迹。
64.fid值的具体计算步骤。
65.步骤1:加载经过预训练的inception v3网络。
66.步骤2:删除模型原本的输出层,将最后池化层数值作为输出,输出值为2048个值的向量。
67.步骤3:将真实图像输入inception v3网络,输出真实图像的特征向量。
68.步骤4:使用训练好的生成器生成图像并输入inception v3网络,输出生成图像的特征向量。
69.步骤5:按照公式计算生成器的fid分数。
70.对保存的315个训练完成的生成器模型,每个模型生成2048张随机图片来计算生成器fid值。经过计算得到本发明提出的基于合成注意力机制的生成对抗网络fid数值最低为26.4。
71.上述实例为本发明较佳的实施方式,但本发明的实施方式不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、代替、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1