一种基于图神经网络的密集事件描述方法
本发明涉及视频描述技术领域,具体为一种基于图神经网络的密集事件描述方法。
背景技术:
视频描述是将视频中的信息内容用语言进行描述,主要针对视频中发生的一件事进行文字表述,而密集事件描述是在此基础上对视频中发生的多个事件进行划分并分别进行描述,该研究领域是将计算机视觉与自然语言处理相结合的一个研究方向,是具有现实意义和研究价值的研究方向,现有技术能够将视频用文字描述但无法确定其具体发生时间,也并未考虑视频时序上的问题,本发明则希望获取较为精确的事件发生时间以及准确的语言描述,可得到视频中不同事件发生的起始、终止时间及事件描述。
针对视频特征提取问题,与图像不同,视频具有时序意义,虽然已经出现3d卷积等提取带有时序信息的特征,但提取效果仍然不够好。针对密集事件描述的时间划分问题最常见的方法是动作概率分布曲线,将事件提案划分拆分为两个阶段,首先通过单帧图像分析得到当前时间点是否为动作的概率估计,应用在整个视频帧序列上则可得到横坐标对应视频时长方向的动作概率分布曲线,然后从高概率的区域产生候选时序动作区域提议,最后将候选提议特征送入动作分类器给出时序动作检测的结果,但该方法容易出现提案缺少的情况,视频中的事件无法全面识别。视频描述的研究主要包含基于语言模板的描述生成和基于序列学习的描述生成。基于语言模板的方法会将检测得到的关键词与预先定义好的语言模板结合生成句子序列,但该方法不够灵活,局限于模板的个数以及种类,无法形成多样性的句子,而基于序列学习的语言描述是利用卷积神经网络+循环神经网络的框架生成更加灵活多变的语言句子,但由于视频是带有时序信息的图片组成,因此时序信息对语言的描述是很重要的,很好的利用时序信息能够更好地完成于语言描述。
针对相关技术中的问题,目前尚未有有效的解决方案。
技术实现要素:
本发明为了解决现有技术无法准确描述视频中出现多个事件的问题,技术方案采用光流法、3d卷积网络和2d卷积网络对视频提取特征,并通过对视频构建空间图和时间图更好地学习视频中时间维度和空间维度信息,以便更好地进行密集事件描述。本发明的目的在于将一段视频中所有的密集事件发生时间进行分割,依次用语言文字对每个事件进行描述。
发明点包括:通过光流法、3d卷积网络和2d卷积网络三种方式对视频提取特征,其中,光流法提取视频动作特征,3d卷积网络提取视频视觉特征,2d卷积网络提取视频对象,若其中任意一种方式缺失,则对视频的特征获取不完整。为获取对象间的关系,对2d卷积网络识别后的对象建立空间图,通过现有的图卷积神经网络技术更新对象特征,使其带有相邻对象特征。建立固定大小的锚边框并针对不同起始时间生成不同候选时间区域,通过非极大值抑制筛选iou大于阈值的时间区域,输出时间区域对应的起始终止时间。为每一个时间区域建立时间图获取时间区域前后帧的信息,将时间区域中每组长特征作为图节点,使用现有的gat网络对其节点更新。最后将特征通过lstm解码成语言文字,并与之前的时间区域相对应输出。
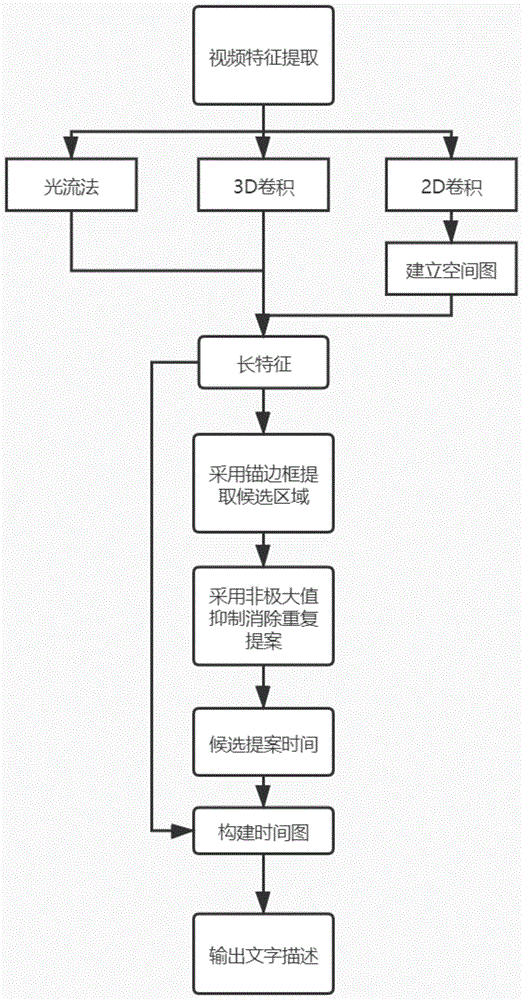
一种基于图神经网络的密集事件描述方法,具体包括以下步骤:
(1)利用光流法、3d卷积网络和2d卷积网络分别对视频数据提取特征,其中,光流法提取视频动作特征,3d卷积网络提取视频视觉特征,2d卷积网络提取视频对象;
(2)为获取视频中对象间的关系,对步骤(1)每组中2d卷积网络提取的对象建立空间图,通过图卷积网络迭代生成的对象特征与光流法、3d卷积特征拼接为该组的长特征;
(3)为使各组长特征带有前后组的信息更好地划分事件区域,将步骤(2)得到的各组的长特征按时间顺序输入至lstm网络,得到各组带有上下文信息的特征,并将所有组的特征按时间顺序拼接为视频特征;
(4)采用锚边框对视频特征进行检测,划分为不同事件的候选时间区域,其中,锚边框是事先固定好的不同大小的窗口,通过按不同起始时间滑动获取多个时间区域;
(5)提取每个候选时间区域视频特征,通过两层卷积层预测每个候选区域的分数,采用非极大值抑制筛选时间区域,将所有的候选时间区域按照分数从大到小的顺序进行排列,计算分数最高的候选时间区域与其余候选时间区域的交并比(iou),删除iou大于阈值的时间区域,剩余时间区域即为该视频中发生事件的时间区域,每个区域的开始时间和结束时间即为密集事件描述中每个事件的起始终止时间;
(6)为了对每个剩余的时间区域更好地解码成文字描述,每组的长特征获取该时间区域其他组的特征信息。提取步骤(5)剩余的每个时间区域的视频特征,对每一个时间区域构建时间图,通过gat更新节点特征得到密集事件特征;
(7)将步骤(6)中每组的密集事件特征通过lstm解码成对应文字输出,该输出为最终的事件描述,每个描述与步骤(4)的起始时间终止时间相对应,该模型输出为事件的起始时间、终止时间和文字描述。
所述步骤(1)的3d卷积采用c3d模型,2d卷积采用目标检测模型,获取前20个对象类别及对象的特征作为密集事件描述关注对象,每16帧作为一组提取3d卷积特征和光流特征,并从中随机选出一帧作为关键帧提取对象类别和特征。
所述步骤(2)的空间图节点为关键帧的20个对象类别和对象的特征,不同对象间的联通度由物体类别词向量的余弦相似度计算,高于阈值则联通,反之不联通。
所述步骤(6)的构建时间图的节点为每个时间区域不同组的长特征。
所述步骤(6)的模型gat使用的是2层的多头注意力机制的gat,由于无法用公式计算每组特征的关系,使用gat网络通过多个注意力矩阵,从多个角度建模联通关系。
有益效果
本发明提出的一种基于图神经网络的密集事件描述方法能够将视频特征尽可能提取完整,通过空间图的方式构造空间物体联系更有利于判断事件的是否发生。通过锚边框的方式提取完整的提案,保证不丢失视频中发生事件的提案。最后通过为候选区域建立时间图,得到事件时序信息使生成文字描述更加合理准确。
附图说明
图1为本发明的方法流程图
图2为本发明的方法模型图
图3为本发明的空间图构造模型
具体实施方式
以下结合附图对本发明的实施方式作进一步说明,但本发明的实施不限于此。
本发明流程图如图1所示,以下进一步展开说明。
如图2所示,一种基于图神经网络的密集事件描述方法,具体包括:
如图所示,视频在0至69秒为一个男人在演奏乐器,38秒至59秒为一个女人在发出笑声,输入的数据为视频帧序列v={v1,v2,…,vl},l为视频总帧数。
步骤(1)包括以下步骤:
(1-1)对视频采用光流法处理:将视频的16帧作为一组作为输入提取动作特征,本视频共有n=l/16组,前后帧对比计算其x方向和y方向的变化梯度,输出通道为2的动作特征fl={fl1,fl2,…,fln},如图2(a)第一分支所示;
(1-2)对视频采用3d卷积处理:使用预训练好的c3d模型,将视频按每16帧为一组输入至模型中,输出视觉特征fc={fc1,fc2,…,fcn},如图2(a)第二分支所示;
(1-3)对视频采用2d卷积处理:在每16帧中随机产生一帧作为关键帧,利用在其他数据集上预训练好的fasterr-cnn目标检测模型,将关键帧中对象类别及特征检测出来,对象类别检测分数由高到低排列,取前20个对象类别所对应的对象特征作为2d卷积网络提取的视频对象的特征fo={fo1,fo2,…,fon}。
步骤(2)包括以下步骤:
(2-1)针对(1-3)提取的目标特征fo构建空间图g,如图3所示,g将20个对象类别和特征编码为20个图节点,通过预先定义好的词向量获取每个对象类别词向量,两两计算词向量余弦相似度,若余弦相似度高于60%,则说明两个节点连通,否则说明两个节点不连通,以此建立邻接矩阵a,令a=a+i保证存在自连接,其中i为单位矩阵。通过现有的图卷积神经网络对节点更新得到更新后的对象特征fg={fg1,fg2,…,fgn},即将特征矩阵输入图卷积神经网络,得到更新后的对象特征fg,如图2(a)第三分支所示,其中,所述的图卷积神经网络的训练方式采用梯度下降对各层权重矩阵训练,每一层权重矩阵共享;
(2-2)每16帧产生一个动作特征fl,视觉特征fc,对象特征fg,分别表示前后帧变化,当前段视觉特征,当前段物体联系,将每一组拼接为长特征f={fl,fc,fg};
步骤(3)包括以下步骤:
采用长短时记忆模型lstm对步骤(2-2)得到的每组长特征向量再次进行编码,将所有组的长特征f={fl,fc,fg}输入至lstm,输出结果带有前后帧内容的视频特征f={f1′,f2′,...,fn′},其中,fn′表示lstm对第n组视频再次编码后的特征,用于更好地确定行为类型;
步骤(4)包括以下步骤:
对步骤(3)得到的视频特征f采用锚边框对不同时间段进行检测,如图2(b)所示,锚边框是事先固定好的不同大小的窗口,锚边框大小分别设置为2、4、8、16、32、64这6个尺度,尺度单位为组,将锚边框按不同起始时间滑动获取多个候选时间区域,图中第二行及以下的矩形为锚边框,是训练前预定义的多尺度窗口。
步骤(5)包括以下步骤:
(5-1)对候选时间区域采用全卷积的方式对候选时间区域进行分类和回归,即将候选时间区域的视频特征依次输入两层1×1×1的卷积层来预测每个候选时间区域包含密集事件的概率分数,以此判断是否有事件发生;其中,每个候选时间区域的视频特征是由该时间区域包含的所有组的长特征拼接而成。
(5-2)为消除步骤(4)中存在候选时间区域的重复现象,采用非极大值抑制策略来消除时间重叠区域过多及分数较低的候选时间区域,即将所有的候选时间区域按照概率分数从大到小的顺序进行排列,计算分数最高的候选时间区域与其余候选时间区域的交并比(iou),本实施例中将时间区域重复度高于80%的候选时间区域,以及概率分数低于0.8的候选时间区域删除,满分为1,保留的候选时间区域分数作为视频中发生事件的时间区域,表达式如下:
其中
在本例中,n为2,p1={0.0,69.19},p2={38.05,59.52}。
步骤(6)具体如下:
针对每个密集事件发生时间区域p,将其分组,提取每组的长特征f={fl,fc,fg},每个长特征为一个节点,将该时间区域内所有组的长特征输入现有的多头注意力机制的图神经网络gat,得到更新后节点的长特征f′,即完成时间图节点的更新;如图2(c)所示,展示了为时间区域p构建一个时间图的过程。
步骤(7)针对步骤(6)中产生更新后的长特征f′,采用lstm作为解码器,将一个时间区域的不同组的长特征f′依次输入至lstm,解码成相应单词,在本例中,输出为”start:0.0end:69.19amanisplayingthebagpipesinfrontofpeople.””start:38.05end:59.52thepeopleonthecouchinfrontofhimstartlaughing.”。
步骤(6-1)中,使用现有的多头注意力机制的图神经网络gat更新时间图节点,注意力系数计算方法为:
其中,αij为节点j到节点i的注意力系数,ni为节点i的相邻节点,fi、fj为节点i和j的特征向量,w为每一个节点的线性变换权重矩阵,a为权重向量,leakyrelu为激活函数,||表示将两个向量拼接起来。
多头注意力机制通过k个独立的注意力机制计算隐藏状态,然后取其平均值作为与该节点相关联的节点特征h′i,并将其与本节点特征相加作为更新后的长特征f′:
其中,
综上所述,借助于上述技术方案,本发明提出的一种基于图神经网络的密集事件描述方法通过将视频进行特征提取、事件提案划分、语言文字描述等一系列操作,最后可将所有事件均以文字的形式描述出来,能够尽可能的找到所有视频中发生的事件,并依次进行较高准确率的文字描述,无需人工进行编辑,让查看者可清楚明了的知道其发生的所有内容,弥补了现有密集事件描述技术存在的缺陷。
- 还没有人留言评论。精彩留言会获得点赞!