一种中文指代表达下的跨模态实例分割方法
本发明涉及一种实例分割方法,尤其涉及一种中文指代表达下的跨模态实例分割方法。
背景技术:
基于自然语言描述的实例分割是一个重要而富有挑战性的问题,学术上称之为指代表达实例分割(referringimagesegmentation)。基于自然语言描述的实例分割与传统的计算机视觉语义分割不同,该任务要分割的对象是由自然语言进行所指定的。实例分割核心在于对象的自然语言和表观特征之间的交叉融合。该任务在机器人控制、图像对象检索和视频监控中特定目标的定位等具有广泛的应用,是计算机视觉和模式识别领域重点关注的内容之一。
以往的研究都采用不同的网络结构,取得了显著的研究成果,常用的方法是使用卷积神经网络提取图像特征向量和递归神经网络提取语言特征向量,然后级联预测边界框或掩模,最新一些基于自注意力的方法,如visualbert、vlbert、vilbert、niter等模型在视觉和语言信息的结合方面提升了算法的性能和精度,并且在指代表达理解和实例分割任务中得到验证。然而,这些方法都没有对中文语境的支持。
目前还没有相关模型支持中文语言描述的实例分割,所有的研究和实验都是以英文描述为基础进行的。传统的英文模式在自然语言处理过程中,对输入每个单词采取相同处理方式,忽视了不同单个词语的重要程度。由于两种语言的固有差异,英文以结构为中心,中文以语义为中心,如果用同样的方法来处理中文,就会出现匹配误差大的问题。英文句子的格式广泛使用冠词、助动词、连词和介词等来调节结构。同时,英文使用词性和时态来表达句子的意思,因此算法很容易识别和分析。然而,中文句式结构相对随意,很少使用助词,进而增加从句子中找出关键词的困难。并且在某些情况下,即使是同一句话,也能表达出不同的意思。因此,与英文相比,中文句子中对某些单词强调是必要的。所以,中文指代表达下的实例分割算法的核心是如何对中文句子进行准确的分词。而且,中文指代表达实例分割数据集是研究的基础,此类数据集还没有。
技术实现要素:
为了解决上述技术所存在的不足之处,本发明提供了一种中文指代表达下的跨模态实例分割方法,通过构建基于预训练的中文词嵌入矩阵,充分利用目标的语义信息,结合目标视觉特征形成中文指代表达的多模态注意力,实现基于中文语境下的跨模态实例分割。
为了解决以上技术问题,本发明采用的技术方案是:一种中文指代表达下的跨模态实例分割方法,包括以下步骤:
步骤1:建立语言处理模型,学习句子的词嵌入表示,然后使用sru将词嵌入序列编码为向量序列;
步骤2:在每个单词隐状态上应用线性层,并对输出进行归一化,计算单词的相对重要性的注意力权值;
步骤3:将隐状态与单词嵌入连接起来,丰富语言表示;
步骤4:引入词注意力机制,对于每一个查询词赋予相同权重,通过计算词的注意力权值,将重点放在注意力权值大的中文词语上。
进一步地,步骤1包括以下步骤:
s11:输入目标语言描述句子
el=embedding(sl)公式1
其中,embeding()表示词嵌入模型;
s12:然后使用sru将词嵌入序列编码为向量序列:
hl=sru(el)公式2
其中,hl是前向lstms和后向lstms在第l个字处的输出的串联。
进一步地,步骤2具体如下:
在每个单词隐状态hl上应用线性层,并对输出进行归一化,以计算一个表示单词的相对重要性的注意力权重al,表示如下:
上式中,
进一步地,步骤3包括以下步骤:
s31:将隐状态hl与单词嵌入el连接起来,丰富语言表示,al表示如下:
al=[el,hl]公式6
s32:使用每个单词的注意力权重来重新对归一化的特征向量进行加权表示,表示如下:
fl=rl*al公式7
其中,fl为第l个单词的相对重要性而生成的词注意力特征,以给定的指代表达传递辨别性信息。
进一步地,步骤4包括以下步骤:
s41:为简化计算过程,提高训练和推理速度,在sru基础上构建词注意力msru,sru方程如下:
ft=σ(wfxt+bf)公式9
rt=σ(wrxt+br)公式10
ht=rt⊙g(ct)+(1-rt)⊙xt公式12
上式中,xt、
s42:对于每一个中文查询词赋予相同权重,msru通过计算词的注意力权重,将重点放在注意力权值大的中文词语上,表示如下:
将步骤3获得的词的注意力权重转移到srucell中,词注意力权重al被利用来调节多模态交互的sru单元存储器;如果一个单词具有较高的注意力权重,将使得srucell从当前状态输出更多信息;相反,一个具有较低注意力权重的单词将允许较少的信息输入srucell,所以srucell状态将更多地依赖于早期记忆。
如上所述为中文指代表达的实例分割方法,其特征在于融合了对象实体的视觉特征和语言特征。为此,本发明提出了一种中文指代表达下的跨模态实例分割方法,并构建中文指代表达数据集,在此数据集基础上验证了中文语境下实例分割的有效性。本发明首先通过中文词嵌入模型对中文描述文本进行处理,利用预先训练好的向量矩阵将每一个中文单词生成词嵌入,并输入到sru模型中生成中文词向量;然后将中文词向量与视觉特征融合,形成跨模态表示;最后利用注意力机制生成注意力权值,使其能够集中在指代表达中的某些重要单词上,基于注意力sru控制多模态合并。
相比于现有技术,本发明具有以下有益效果:
1.提出了词注意力模块,通过学习每个中文单词的相对重要性,并对每个单词的矢量表示和相应的注意力分数进行重新加权,生成单词特有的跨模态特征来提高准确性;
2.以基于词注意力机制的时序神经网络单元(msrus,multimodalsimplerecurrentunits)代替标准的长短时时序网络单元(lstm,longshort-termmemory)作为多模态融合处理单元,并通过使用词注意力权重,使得多模态模块可以聚焦于更重要的中文单词;
3.为解决研究所需的数据集的问题,构建了中文指代表达实例分割数据集,用于模型的训练及测试。
附图说明
图1为本发明的框架图。
图2为本发明模型总体框架图。
图3为中文词嵌入示意图。
图4为单词注意力和amsru注意力模型框架图。
图5为词注意力可视化示意图。
图6为实体分割模型性能曲线图。
图7为利用中文指代表达分割结果图。
具体实施方式
下面结合附图和具体实施方式对本发明作进一步详细的说明。
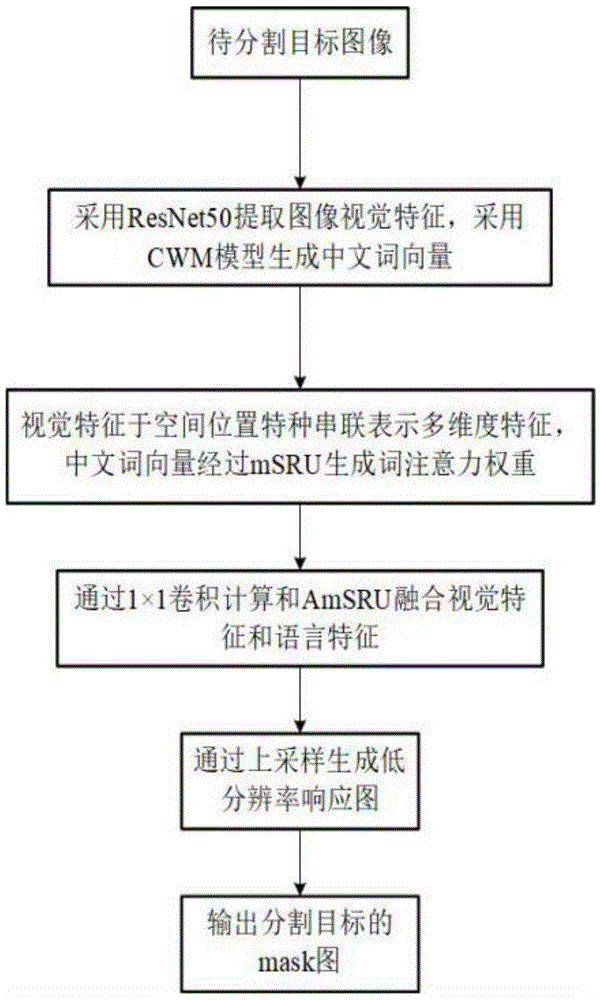
如图1所示,本发明提出了一种中文指代表达下的注意力跨模态实例分割方法,主要包括以下四个部分:第一,构建中文词嵌入方法,编码中文描述文本,生成词语向量。第二,计算单个词语的词注意力权重,生成词注意力响应图。第三,提取图像中的视觉特征,并与空间特征进行拼接。第四,融合视觉特征与语言特征,生成目标响应图。
如图2所示为模型总框架图,网络模型以图像和中文查询作为输入,该模型由三部分组成,其中左上部分为利用cnn网络提取视觉特征部分,该部分采用resnet50提取图像中的视觉特征,并于空间位置(spatiallocation)特征进行拼接,得到新的视觉特征向量。左下角为nlp(nlp,naturallanguageprocessing)处理部分,该部分包括中文嵌入模块(cwem,chinesewordembeddingmodule)、sru模块、动态滤波模块(dynamicfilters),中文嵌入模块cwem(cwem,chinesewordembeddingmodule)是利用预先训练好的字嵌入矩阵生成词向量,将词向量输入到sru(simplerecurrentunits),生成单词注意力权重。单词注意力模块(wam,wordattentionmodule)根据词语重要性来生成单词注意。将sru模块和wam模块的输出连接后经过一组动态滤波器,形成单词的注意力特征。视觉特征和单词注意力特征(语言特征)进行1×1卷积融合得到多模态特征mt,多模态特征包括视觉特征in、词注意力特征ft以及归一化的词注意力rt。amsru(attentionalmsru)模块使用词注意力控制每个多模态特征的输出,用以强调每个词语的重要信息,一个单词具有较高的注意力权重,将使得srucell从当前状态输出更多信息。相反,一个具有较低注意力权重的单词将允许较少的信息输入srucell。最后,将低分辨率的目标响应图进行上采样得到mask模式的输出。
用预先训练好的向量矩阵将每一个中文单词生成词嵌入,并输入到sru模型中生成中文词向量,如图3所示,首先进行中文句子的分词预处理,然后进行词向量进行跨模态合并。中文分词使用结巴分词方法将中文句子分解成具有特定语义意义的词。采用隐马尔可夫模型(hmm,hiddenmarkovmodel)和维特比(viterbi)算法来捕获新单词。中文嵌入以分割后的中文词为输入,通过预先训练好的词向量生成嵌入词,采用了256维的中文词汇向量,包含35万个词汇,向量被格式化为bcolz(bcolz是一个高压缩率,读写效率高的python库)。使用skip-gram、huffmansoftmax混合语言模型和word2vec工具进行训练。具体步骤如下:
步骤1:建立语言处理模型,学习句子的词嵌入表示,然后使用sru将词嵌入序列编码为向量序列;包括以下步骤:
s11:输入目标语言描述句子
el=embedding(sl)公式1
其中,embeding()表示词嵌入模型;
s12:然后使用sru(simplerecurrentunit)将词嵌入序列编码为向量序列:
hl=sru(el)公式2
其中,hl是前向lstms和后向lstms在第l个字处的输出的串联。
将词嵌入序列编码为词向量后,建立词注意力,利用注意机制来捕获中文词汇的语义结构,学习每个单词的相对重要性,并将每个单词的矢量表示与相应的注意力重新加权。如图4所示为单词注意力wam(wordattentionmodule)和amsru注意力模型框架图,该图左边是两个线性层神经网络生汉语单词注意在wam(wordattentionmodule),即将词嵌入模型中生成的词嵌入el和隐状态hl经过分别两个线性层fclinear和两个激活函数tanh和softmax后得到词注意力权重(attentionweight),将其表示为al。该图右边是amsru模块,该模块以wam的注意权值al作为输入,ct为t时刻的输出,ct-1为t-1时刻的输出。amsru模块借用了wam的注意权值al,用于控制sru单元进行多模态特性;amsru注意力模型使得网络关注更重要的信息,而不是平等地对待每一个文字。将关注重点放在句子中的重要词上,并对多模态信息进行自适应编码。具体步骤如下:
步骤2:在每个单词隐状态上应用线性层,并对输出进行归一化,计算单词的相对重要性的注意力权值;具体如下:
在每个单词隐状态hl上应用线性层,并对输出进行归一化,以计算一个表示单词的相对重要性的注意力权重al,表示如下:
上式中,
步骤3:将隐状态与单词嵌入连接起来,丰富语言表示;包括以下步骤:
s31:将隐状态hl与单词嵌入el连接起来,丰富语言表示,al表示如下:
al=[el,hl]公式6
s32:使用每个单词的注意力权重来重新对归一化的特征向量进行加权表示,表示如下:
fl=rl*al公式7
其中,fl为第l个单词的相对重要性而生成的词注意力特征,以给定的指代表达传递辨别性信息。
步骤4:引入词注意力机制,对于每一个查询词赋予相同权重,通过计算词的注意力权值,将重点放在注意力权值大的中文词语上。包括以下步骤:
s41:为简化计算过程,提高训练和推理速度,在sru基础上构建词注意力msru,sru方程如下:
ft=σ(wfxt+bf)公式9
rt=σ(wrxt+br)公式10
ht=rt⊙g(ct)+(1-rt)⊙xt公式12
上式中,xt、
使用两次sru单元,第一次利用中文词嵌入表达生成中文表达词嵌入,即rnn(递归神经),第二次用于跨模态合并过程,即mrnn。扩展了原始的跨模态简单回归单元算法,并引入了词注意力机制。
s42:对于每一个中文查询词赋予相同权重,msru通过计算词的注意力权重,将网络模型(msru)关注重点放在注意力权值大的中文词语上,表示如下:
将步骤3获得的词的注意力权重转移到srucell中,词注意力权重al被利用来调节多模态交互的sru单元存储器;如果一个单词具有较高的注意力权重,将使得srucell从当前状态输出更多信息;相反,一个具有较低注意力权重的单词将允许较少的信息输入srucell,所以srucell状态将更多地依赖于早期记忆。改进后的sru能够更加关注具有较高注意力权重的重要词。
模型进行端对端训练,训练分为有两个阶段。首先用低分辨率的尺度进行训练,不进行上采样,然后用高分辨率进行训练。基本参数设置为:中文字嵌入大小和隐藏状态大小均设置为256,动态过滤器数量设置为10。采用adamoptimizer优化器进行训练,初始学习率为1×10,batchsize为1,adam优化器初始学习率使用1×10-5,sru设置为3个层,损失函数采用交叉熵损失函数,整个训练过程loss曲线如图6所示。
为更好地表示在模型中注意机制的优点,如图5所示,在实验中可视化表示不同层次上的注意分布,(a)是分别为原始图像,(b)是带分割目标的ground-truth值。(c)表示模型的高分辨率预测结果,(d)进行上采样前的为低分辨率预测结果,(e)表示融合后的注意力heatmap图。对应的词如图片下方所示,图片下面是词注意力,较暗的颜色表示较高的注意权重。对应的查询句子分别是“水中的波浪”、“男人上方的黑色区域”。从图中可以看出图像中的预测反映了指代表达的实例分割。实验结果图如图7所示,图(a)、(b)、(c)以图像和中文查询作为输入,二值图作为输出,左边为输入图像,图片下方为中文查询,右边为词注意力相应图,中间为分割结果的二值图。如图7所示,实验结果表明,该发明在中文指代表达语境下,能够有效的实现实例分割。
本发明所构建数据集包括refcocog,refcoco和refcoco+,都是在microsoftcocoimagecollection上收集的。其中数据集refcocog是在非交互模式中收集的,而另外两个数据集refcoco和refcoco+是在双人游戏中交互收集的。在refcoco和re-fcoco+数据集中使用的语言往往比在re-fcocog中使用的语言更简洁,refcoco的平均长度是5.57,refcoco+是5.85,refcocog是11.72。gref数据集包含26711幅图像中的54,822个对象的85,474个中文参考表达。选择图像包含2到4个相同类别的物体。ref-coco包含142209个中文表达,在19,994张图片中包含50,000件物品,而refcoco+包含141,564个中文表达,在19,992张图片中包含49,856件物品。中文指代表达数据集包含130525个中文表达,涉及96654个不同的物体,在19,894张真实世界场景的照片中。
本发明首先引入提出了单词注意力模块,通过学习每个中文单词的相对重要性,并对每个单词的矢量表示和相应的注意分数进行重新加权,生成单词特有的跨模态特征来提高准确性。然后以注意力简单循环单元代替标准的注意力循环单元作为多模态处理器。并通过使用词注意力权重,使得多模态模块可以聚焦于更重要的中文单词。本发明为解决研究所需的数据集不足的问题,构建了中文指代图像分割数据集,用以模型的训练及测试。本发明在构建的数据集上测试后,验证了方法的有效性。
上述实施方式并非是对本发明的限制,本发明也并不仅限于上述举例,本技术领域的技术人员在本发明的技术方案范围内所做出的变化、改型、添加或替换,也均属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!