一种多线程安全高效读写有序数据的方法与流程
1.本发明涉及一种读线程与写线程同时对存储于同一容器内的数据进行读写操作的方法。
背景技术:
2.随着计算的硬件的不断发展,cpu所采用的多核结构带来了计算机工作模式的重大改革,使得计算机的性能得到很大提升,原有的单线程模式已经可以在多核情况下并行工作。数据在任何领域系统中都是存在的,如何去高效地读写数据是任何领域系统中都必须要解决的问题。在数据处理领域,对存储在某一容器内的数据进行各种排序来进行数据分析,这种情况非常普遍。
3.在现有的技术方案中,对存储于同一容器内的数据进行读写操作采用以下两种模式之一:如图1所示,为单线程情况下的工作模式。在该工作模式下,只有一个线程在对存储于容器内的数据进行读、写操作,因而读写不能同时进行,读和写是互斥的,从容器中读出数据的时候不能将数据写入同一容器中,在将数据写入容器的时候不能将数据从同一容器中读出。
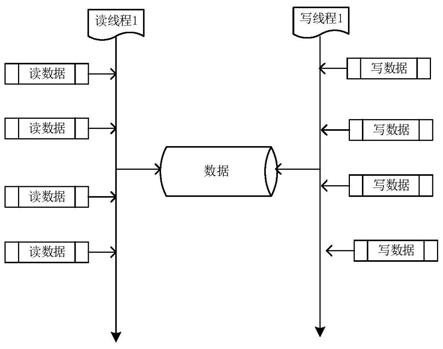
4.如图2所示,为多核情况下多线程的读写工作模式。在该工作模式下,对同一容器内存储的数据进行的读操作和写操作是在不同线程中进行的。为了解决两个线程相互冲突的问题,上述读写工作模式引入锁来解决,读线程与写线程同时抢占资源,若读线程先抢占到锁,则进行读操作,反之若写线程先抢占到锁,则进行写操作。图2所示的工作模式,虽然是两个线程在工作,但读线程与写线程的操作是互斥的,不能同时进行,性能上得不到提升。
技术实现要素:
5.本发明要解决的技术问题是:在现有的多核情况下多线程的读写工作模式中,读线程与写线程的操作是互斥的。
6.为了解决上述技术问题,本发明的技术方案是提供了一种多线程安全高效读写有序数据的方法,其特征在于,包括以下步骤:
7.容器利用n个node数据节点来存储任意数据类型的数据,n≥3,每个node数据节点包含previous字段、key字段、value字段及next字段,第n个node数据节点的previous字段用于存储指向第(n
‑
1)个node数据节点的指针,第n个node数据节点的key字段用于存储按照场景的需求需要排序的值,定义为key值,第n个node数据节点的value字段用于存储key字段的值对应的数据值,定义为value值,第n个node数据节点的next字段用于存储指向第(n+1)个node数据节点的指针,n=2,
…
,(n
‑
1);所有node数据节点按照key字段的值在容器内排序;
8.利用读线程实现对容器内存储数据的读操作,同时利用与读线程不同的写线程实现对同一容器内存储数据的写操作,对容器的读操作与写操作同时进行,其中:对容器的写
操作包括以下步骤:
9.步骤101:获得待存储的数据的key值及与key值相对应的value值,创建一个node数据节点;
10.新创建的node数据节点的previous字段及next字段为空,将key值存入新创建的当前node数据节点的key字段,将value值存入新创建的当前node数据节点的value字段;
11.步骤102:将新创建的node数据节点的key字段的值与容器内已存在的所有node数据节点的key字段的值进行匹配,若匹配成功,则进入步骤103,若匹配失败,则进入步骤104;
12.步骤103:将匹配到的已存在的node数据节点的key字段的值以及value字段的值用新创建的node数据节点的key字段的值以及value字段的值覆盖,返回步骤101;
13.步骤104:设容器内已存储有k个node数据节点,2≤k≤n,查找与新创建的node数据节点的key字段的值相匹配的key值区间,key值区间为由容器内已存储的相邻两个node数据节点的key字段的值组成的区间;
14.设v
k
表示容器内已有的第k个node数据节点的key字段的值,k=2,
…
,k,新创建的node数据节点的key字段的值为v;
15.设容器内已有k个node数据节点按照key字段的值降序排列,则有:
16.若v∈(v
k
,v
k
‑1),则v与key值区间(v
k
,v
k
‑1)相匹配,此时,先将新创建的node数据节点的previous字段的指针指向容器内已有的第(k
‑
1)个node数据节点,将新创建的node数据节点的next字段的指针指向容器内已有的第k个node数据节点,再将容器内已有的第(k
‑
1)个node数据节点的next字段的指针指向新创建的node数据节点,将容器内已有的第k个node数据节点的previous字段的指针指向新创建的node数据节点;
17.若v>v1,则v与key值区间(v1,+∞)相匹配,此时,先将新创建的node数据节点的next字段的指针指向容器内已有的第1个node数据节点,再将容器内已有的第1个node数据节点的previous字段的指针指向新创建的node数据节点;
18.若v<v
k
,则v与key值区间(
‑
∞,v
k
)相匹配,此时,先将新创建的node数据节点的previous字段的指针指向容器内已有的第k个node数据节点,再将容器内已有的第k个node数据节点的next字段的指针指向新创建的node数据节点;
19.设容器内已有k个node数据节点按照key字段的值升序排列,则有:
20.若v∈(v
k
‑1,v
k
),则v与key值区间(v
k
‑1,v
k
)相匹配,此时,先将新创建的node数据节点的previous字段的指针指向容器内已有的第(k
‑
1)个node数据节点,将新创建的node数据节点的next字段的指针指向容器内已有的第k个node数据节点,再将容器内已有的第(k
‑
1)个node数据节点的next字段的指针指向新创建的node数据节点,将容器内已有的第k个node数据节点的previous字段的指针指向新创建的node数据节点;
21.若v<v1,则v与key值区间(
‑
∞,v1)相匹配,此时,先将新创建的node数据节点的next字段的指针指向容器内已有的第1个node数据节点,再将容器内已有的第1个node数据节点的previous字段的指针指向新创建的node数据节点;
22.若v>v
k
,则v与key值区间(v
k
,+∞)相匹配,此时,先将新创建的node数据节点的previous字段的指针指向容器内已有的第k个node数据节点,再将容器内已有的第k个node数据节点的next字段的指针指向新创建的node数据节点;
23.对容器的读操作包括以下步骤:
24.获得待读取数据的key值,通过二分法获得容器中key字段的值与该key值相匹配的node数据节点,利用二分法进行匹配时,将待读取数据的key值不断与位于搜索范围中间位置的node数据节点的key字段的值进行匹配,已经匹配结果再基于node数据节点按照key字段的值在容器内升序或降低排列的方式不断将搜索范围减半,最终得到相匹配的node数据节点,在此过程中,若通过同步进行的写操作将待匹配的node数据节点删除,则将待读取数据的key值与删除的node数据节点的上一个node数据节点或下一个node数据节点进行匹配,并依据匹配结论将搜索范围减半。
25.优选地,所述n个node数据节点存放在数组中。
26.优选地,在所述步骤101之前还包括初始化数组,将数组的大小初始化为可以存储m个所述node数据节点,1≤m≤n;
27.当对数组进行扩容时,按照数组的已有大小成倍扩容,数组的大小为可以存储所述node数据节点的个数。
28.优选地,步骤102中,利用二分法进行新创建的node数据节点的key字段的值与容器内已存在的所有node数据节点的key字段的值的匹配。
29.本发明的另一个技术方案是提供了一种多线程安全高效读写有序数据的方法,其特征在于,包括以下步骤:
30.利用一个且仅有一个数组来存储日期类型数据,日期类型数据通过ushort数据格式存储,占用两个字节;设数组的长度为n,n≥3,则数组中第n个元素与第n个索引位置相对应,n=0,1,
…
,n
‑
1,即第n个索引位置指向数组中第n个元素;
31.将日期类型数据定义为与日期相关的数据,利用读线程实现对数组的读操作,同时利用与读线程不同的写线程实现对同一数组的写操作,对数组的读操作与写操作同时进行,其中:对数组的写操作包括以下步骤:
32.步骤111:依据所有待存入的日期类型数据对应的日期确定最小日期d
min
及最大日期d
max
,则有n=d
max
‑
d
min
,初始化一个长度为n的数组,数组中所有元素指向空;
33.步骤112:对所有待存入的日期类型数据进行写操作,其中,对当前一个待存入的日期类型数据进行写操作时,先将当前日期类型数据转换为ushort数据格式,再依据当前日期类型数据所对应的具体日期,利用步骤111确定的最小日期d
min
及最大日期d
max
,计算得到当前日期类型数据所对应的索引位置,将该索引位置指向转换为ushort数据格式的当前日期类型数据;
34.当写入一个新的日期类型数据时,若相应索引位置指向的数据不为空,则用新的日期类型数据替换该相应索引指向的旧日期类型数据,若相应索引位置指向的数据为空,则将该索引位置直接指向新的日期类型数据;
35.当写入一个新的日期类型数据时,若新的日期类型数据所对应的日期大于最大日期d
max
,则对数组进行扩容后,再将扩容后的数组的相应索引位置指向新的日期类型数据;
36.对数组的读操作包括以下步骤:
37.若需要读取某个具体日期的日期类型数据,则包括以下步骤:
38.步骤211:计算与具体日期相对应的索引位置,该索引位置=具体日期
‑
数组中已存储的最小日期
‑
1;
39.步骤212:直接读取数组中通过步骤211计算得到的索引位置所指向的日期类型数据,或者读取数组中通过步骤211计算得到的索引位置往后一个索引位置或往前一个索引位置所指向的日期类型数据,直至获得日期类型数据;
40.若需要读取某个日期区间的数据,则包括以下步骤:
41.步骤221:采用上述步骤211所记载的方法获得日期区间中下限日期对应的索引位置,定义为下限索引位置;
42.采用上述步骤211所记载的方法获得日期区间中上限日期对应的索引位置,定义为上限索引位置;
43.步骤222:获得数组中位于下限索引位置与上限索引位置之间的所有索引位置指向的日期类型数据。
44.优选地,步骤111中,依据所有待存入的日期类型数据所对应的最大日期及最小日期确定所述最小日期d
min
及所述最大日期d
max
;
45.或者依据所有待存入的日期类型数据所对应日期的规律确定所述最小日期d
min
及所述最大日期d
max
;
46.或者所述最小日期d
min
设定为所有待存入的日期类型数据所对应的日期中最小日期,所述最大日期d
max
设定为当前日期加固定天数,其中,固定天数的具体值根据经验确定。
47.优选地,在所述步骤112之后还包括:
48.步骤113:完成对所有待存入的日期类型数据的写操作后,再获得数组中指向日期类型数据所对应日期最小的索引位置,将该索引位置指向的日期作为所述最小日期d
min
后重新计算得到n,依据更新后的n重新初始化一个数组,将原数组中的数据放入到新的数组中,并将原数组的数据设置为空。
49.优选地,步骤112中,对数组进行扩容包括以下步骤:
50.计算新的日期类型数据所对应的索引位置,将数组大小扩容至计算得到的索引位置+1;
51.或者计算新的日期类型数据所对应的索引位置,将数组大小扩容至计算得到的索引位置+一个月的天数+1。
52.本发明针对数据处理领域中对存储在某一容器内的数据进行各种排序来进行数据分析的情况,设计了一种多线程安全高效读写有序数据的方法。采用本发明的技术方案后,一系列的数据在多线程的情况下任意一列的数据可以进行有序地存储与读取,实现读写同时进行以及多线程读写安全的无锁容器。
附图说明
53.图1为单线程情况下工作模式的流程图;
54.图2为现有的多核情况下多线程的读写工作模式的流程图;
55.图3为本发明的多核情况下多线程的读写工作模式的流程图;
56.图4为实施例1中的数据存储结构示意图;
57.图5为实施例1中初始化的数组示意图;
58.图6为实施例1中创建的node数据节点示意图;
59.图7为将张三对应的node数据节点插入图5所示的数组中的示意图;
60.图8为匹配李四对应的node数据节点的示意图;
61.图9为张三对应的node数据节点插入后,再插入李四对应的node数据节点的示意图;
62.图10为实施例1中将四条数据插入后的示意图;
63.图11为实施例1中构建双向链表的步骤;
64.图12为实施例1中的二分法查询示意图;
65.图13为实施例2中确认索引位置的示意图;
66.图14为实施例2中一个具体实例的确认数组长度的示意图;
67.图15为实施例2中写入数据的示意图;
68.图16为实施例2的数据压缩示意图;
69.图17为实施例2中读数据所用案例示意图;
70.图18为实施例2读数据的示意图。
具体实施方式
71.下面结合具体实施例,进一步阐述本发明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。此外应理解,在阅读了本发明讲授的内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本申请所附权利要求书所限定的范围。
72.如图3所示,在本发明中,利用读线程实现对容器内存储数据的读操作,同时利用与读线程不同的写线程实现对同一容器内存储数据的写操作,对容器的读操作与写操作同时进行,
73.实施例1
74.基于图3所述的工作模式,本实施例公开了一种支持任意数据类型的排序的读写方法。
75.本实施例中,数据存储结构采用如图4所示的双向链表+数组实现存储。本实施例中容器为数组,数组利用n个node数据节点来存储任意数据类型的数据,n≥3。每个node数据节点包含previous字段、key字段、value字段及next字段,其中:第n个node数据节点的previous字段用于存储指向第(n
‑
1)个node数据节点的指针;第n个node数据节点的key字段用于存储按照场景的需求需要排序的值,定义为key值;第n个node数据节点的value字段用于存储key字段的值对应的数据值,定义为value值;第n个node数据节点的next字段用于存储指向第(n+1)个node数据节点的指针,n=2,
…
,(n
‑
1)。
76.本实施例中以一张如下表1所示的学生成绩表,要求按照学生的成绩分数来排序读写为例进一步说明本发明。
77.[0078][0079]
表1
[0080]
针对上表所示的数据,则node数据节点有:
[0081]
1)key字段:用于存储学生成绩对应的分数;
[0082]
2)value字段:用于存储对应该分数的学生的分数以及需要信息(例如:一个学生的姓名、班级、性别、分数等);
[0083]
3)previous字段:该成绩分数比当前node数据节点高的node数据节点指针(如果node数据节点按照key字段的值升序排序,对应的是比当前node数据节点高的node数据节点;如果node数据节点按照key字段的值降序排序,则对应的是比当前node数据节点低的node数据节点)
[0084]
4)next字段:该成绩分数比当前node数据节点低(或者高)的node数据节点指针,同previous字段。
[0085]
则向数组写入数据包括以下步骤:
[0086]
第一步:初始化一个如图5所示的数组,数组大小为4可以存储4个node数据节点。若后续需要对数组进行扩容,则依据数组的已有大小成倍进行扩容。
[0087]
第二步:创建一个node数据节点,将其key字段及value字段赋予相应的值,previous字段的指针及next字段的指针指向空,如图6所示。
[0088]
第三步:通过二分法查找数组,找到node数据节点对应的key值,如果找到,则覆盖,没有找到,则找到对应数组的插入位置。如下图7,先插入张三对应的node数据节点,再如图9所示插入李四对应的node数据节点。
[0089]
1)由于数组里面没有数据,张三对应的索引位置为0,如图7所示。
[0090]
2)如图8所示,插入李四,通过二分法查找,数组中没有对应的值,则找到插入的位置0,将双向链表的node数据节点的previous字段的指针及next字段的指针赋值。
[0091]
3)将李四对应的node数据节点插入到0的位置,数组索引0后续的数据往后移动一个位置,如图9所示。
[0092]
4)将上表1中的四条数据全部插入后的数组如图10所示。
[0093]
上面的过程中:构建双向链表的步骤如图11所示:
[0094]
步骤1:将新插入的node数据节点的pervious字段及next字段的指针指向数组中的前node数据节点及后node数据节点。
[0095]
步骤2:然后再将数组中的前node数据节点及后node数据节点指向新插入的node数据节点。
[0096]
如果上述步骤1及步骤2反了,则在读的过程中,双向链表会出现断裂的情况。
[0097]
从数组读出数据包括以下步骤:
[0098]
本实施例通过二分法的逻辑获取对应的值所在的位置,找到对应的数据。
[0099]
结合图4,若要查询60分的同学信息,本实施例中的二分法包括以下步骤:
[0100]
第一步:找到数组长度为4的中间所以位置:4/2=2,则找到key字段为89分的node数据节点。
[0101]
第二步:比较89与60,因为60比89小,所以说明60在前半部分。
[0102]
第三步:再找0
‑
2的索引的中间位置,找到索引为1的位置,即找到key字段为79分的node数据节点。
[0103]
第四步:比较79与60的大小,重复上述步骤,直到找到60,索引为0。
[0104]
本发明在上述步骤中还采用了校正算法,因为在查找的过程中有可能数据会发生删除的操作。如数组本来为1、2、3、4、10、11、12、13,要找元素10,但在查的过程中发生了数据移动,变成了1、2、3、4、9、10、11、12、13。校正算法原理是根据最后一步比较值的大小,让指针前移或后移。
[0105]
如:以上算法在读取的过程中如果key字段为79分的node数据节点被删除了,就找到它的前一个node数据节点比较。如果前一个node数据节点的key字段的值比它小,那就找到key字段为79分的node数据节点的后一个node数据节点比较。
[0106]
实施例2
[0107]
本实施例公开了一种支持日期类型的排序的读写存储方法。日期类型数据在各个领域应用中非常常见,应用也非常灵活,例如:获取某一日期的数据,获取某一日期的前一条数据,获取某日期区间内的数据。因为应用比较灵活,所以性能与存储都是非常重要,本实施例公开一种支持日期类型的高效排序的读写存储方法,其同样适用于图3所示的工作模式。
[0108]
本实施例将日期类型数据节通过ushort数据格式进行校存储,占用两个字节,可以支持100年的数据存储。本实施例中,日期类型数据存储在一个而且仅有一个数组内,索引的存储非常低。设数组的长度为n,n≥3,则数组中第n个元素与第n个索引位置相对应,n=0,1,
…
,n
‑
1,即第n个索引位置指向数组中第n个元素。
[0109]
读数据包括以下步骤:
[0110]
第一步:初始化数组,将数组中所有的值指向空。在存储日期数据前,对数据的大概范围进行评估,初始化数据的大小。这样的好处避免频繁的扩容带来性能上损失。
[0111]
上述步骤中,对数据的大概范围进行评估包括:
[0112]
1)直接利用现有数据获得最小日期d
min
及最大日期d
max
。比如现有一张1亿条数据的数据表,可以找到这个数据表中的最大日期和最小日期分别作为最大日期d
max
及最小日期d
min
。
[0113]
2)根据数据表的使用规律来确定最大日期d
max
及最小日期d
min
。比如某张数据表只会存储某个日期后的数据或某个日期之前的数据,则可以进一步确定最大日期d
max
及最小日期d
min
。
[0114]
3)一般日期序列的数据,不是预测的数据,都是随着时间的推移产生的数据,可以将最大日期d
max
设置为当前的日期往后推30天。最小日期d
min
则参考上述第1)种方法进行确定。
[0115]
确定最大日期d
max
及最小日期d
min
后,计算得到数组长度n,n=d
max
‑
d
min
,如图13所示。
[0116]
例如需要对全国的天气进行历史十年和未来的数据进行存储:最小日期d
min
设置为20100103,则最大日期d
max
设置为20200103+30天=20200203。数组的长度n为最大日期d
max
与最小日期d
min
相减得到的天数:3650+30=3680。则本步骤种初始化为一个长度为3680的数组。与20100103对应的天气数据存储到数组的索引位置0指向的位置,与20200203对应的天气数据存储到数组的末位置,如图14所示。
[0117]
第二步:写数据
[0118]
如图15所示,在写数据的过程中,首先将日期类型数据转换成ushort格式数据,随后根据初始化好的最小日期d
min
、最大日期d
max
,计算出当前日期类型数据对应日期所对应的索引位置,将该索引位置指向当前日期类型数据。本发明中,将日期类型数据定义为与日期相关的数据。
[0119]
第三步:压缩数据
[0120]
在第一步初始化的过程当中,评估的日期数据可能与实际情况不相符,这个情况通过压缩的方式减少存储空间的浪费。如上面的案例中,存储数据是按照每个城市的天气进行分类存储,这种情况每个城市都是一个有序的数组。当某个城市是一个新产生的城市,并没有历史数据,而这个时候初始化的数组是按照历史数据的大小初始化,数组里面全部是空,对于数据的存储是一个极大的浪费。这个时候需要压缩。
[0121]
如图16所示,压缩算法包括以下步骤
[0122]
1)找到这个数组中日期最小的一个不为空的索引。
[0123]
2)对应这个索引位置的日期作为最小值,重新初始化一个数组,将原有的数据放入到新的数组中。这样数组的大小大大降低。
[0124]
3)将原来的数组的数据设置为空。
[0125]
第四步:增量数据的同步。
[0126]
当写入新的数据,如果原有的数据位置不为空,则用新的数据的替换原有的数据。当为空,则将该索引位置指向现有的数据。
[0127]
如果新的数据日期大于这个数组中最大索引位置对应的日期,这个时候说明数组需要扩容才能将这个数据放入到数组中。计算该日期对应的索引位置,将数组的大小扩容到该日期的索引位置+1。优化的算法是扩容到这个日期往后推一个月对应的索引位置+1。这样数组只需要一个月扩容一次。可以减少数组的频繁扩容带来的性能损失。这里的一个月不是固定值,可以在初始化设置这个参数。
[0128]
读数据包括以下步骤:
[0129]
一)精确读取
[0130]
本实施例的读数据并没有采用二分法的查找方法,而是先计算该日期在数组的索引位置。
[0131]
如图17案例中天气预报的数据。比如:上海的历史十年天气的数据,拿一个月的数据来作为案例。某个日期在数组中的索引算法为:当前日期减去数组中的最小日期的间隔天数
‑
1。比如:数组中最小日期是20100103,存储在0位置。读取20100115的天气数据,计算索引位置:20200115
‑
20100103的天数,即为12
‑
1=11。直接读取数组中索引位置为11的数据即可。如果该位置的数据为null,则表示不存在该数据;如果有则找到,返回对应的位置。读的性能保持在0(1)操作。
[0132]
二)前推、后推读取
[0133]
只需要在精确读取的基础上,通过该索引位置,索引+1、
‑
1读取,找到不为空为止。例如:上海的天气预报有些天气的数据是空缺的,要求是当这个日期的天气预报数据没有,以前一天或者后一天的数据作为该日期的数据。
[0134]
三)区间读取
[0135]
只需要计算两个区间日期的索引位置,通过该索引位置,获取这个区间内的不为空的数据。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1