一种处理带格式风格文本的要素内容抽取方法与流程
1.本发明属于文本处理技术领域,具体来说是一种处理带格式风格文本的要素内容抽取方法。
背景技术:
2.传统意义上债券信息收集主要依靠人工筛选或正则匹配的形式来进行,该场景下的工作效率和系统录入准确率都不甚高。而在ai时代,利用自然语言处理(nlp)技术对银行间市场中的非结构化文本进行结构化后入库,从而及时有效地管理各种债券信息,是十分具有实用效益的。
技术实现要素:
3.1.发明要解决的技术问题
4.本发明的目的在于解决现有的文本数据采集提取需要人工筛选录入,效率低下的问题。
5.2.技术方案
6.为达到上述目的,本发明提供的技术方案为:
7.本发明的一种处理带格式风格文本的要素内容抽取方法,所述方法具体包括如下步骤:
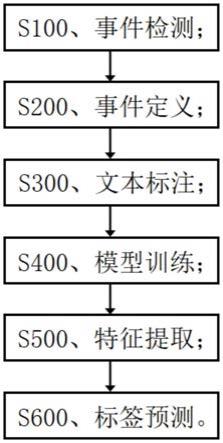
8.s100、事件检测;
9.s200、事件定义;
10.s300、文本标注;
11.s400、模型训练;
12.s500、特征提取;
13.s600、标签预测。
14.优选的,所述步骤s100具体为首先将文本中的事件触发词和事件元素都抽取出来如:发行人、债券品种、债券金额等实体元素。之后根据实体触发词和实体元素对应到相应的独立事件。
15.优选的,所述步骤s200具体为基于ideal平台上所发布的信息,确定事件类型,首先定义触发词如:违约、发行等事件触发词。之后基于触发词再定义相关事件元素。
16.优选的,所述步骤s300具体为如果任务为事件检测,则对文本进行事件类型、事件触发词、事件元素标注。如果任务为实体识别,对相关文本进行bio标注,其中b为begin代表某个实体类型开始,i为immediate表示某实体的中间位置,o为other代表其他,不是实体。
17.优选的,所述步骤s400中的模型训练具体为将批注好的句子级语料先进行分词,获取token级别的序列信息和注意力信息。将这些序列信息输入到预训练bert模型中,在bert模型中经过注意力机制、线性层来提取字向量表示,再输送到bilstm
‑
crf模型中,预测词向量的标签,将预测的标签和真实标签进行比较计算并反馈。不断重复这个过程,以得到
训练后用于要素级别实体抽取的模型。
18.优选的,所述步骤s500具体为进行预测时,模型会对输入的文本进行向量化,并通过bert获取信息向量,得到特征。
19.优选的,所述步骤s600具体为将获得的特征输入bilstm
‑
crf中,已经学习过的模型进行预测出标签,最后根据标签进行实体的抽取。
20.一种处理带格式风格文本的要素内容抽取系统,包括事件检测模块和要素级别实体抽取模块,所述事件检测模块采用bilstm
‑
maxpooling作为句子编码器,将文本生成对应的句子向量;采用bilstm
‑
crf对长文本中的句子进行标注,从而区分出每个相关的独立事件,所述要素级别实体抽取模块采用预训练好的bert模型进行特征提取,得到句子中每个字的嵌入向量,采用bilstm
‑
crf结构捕捉双向的语义依赖,再加入crf对标签之间的依赖性建模,利用crf来学习一个最优路径,进行实体级别的标签预测。
21.3.有益效果
22.采用本发明提供的技术方案,与现有技术相比,具有如下有益效果:
23.本发明的一种处理带格式风格文本的要素内容抽取方法及系统,所述方法具体包括如下步骤:s100、事件检测;s200、事件定义;s300、文本标注;s400、模型训练;s500、特征提取;s600、标签预测;系统包括事件检测模块和要素级别实体抽取模块,所述事件检测模块采用bilstm
‑
maxpooling作为句子编码器,将文本生成对应的句子向量;采用bilstm
‑
crf对长文本中的句子进行标注,从而区分出每个相关的独立事件,所述要素级别实体抽取模块采用预训练好的bert模型进行特征提取,得到句子中每个字的嵌入向量,采用bilstm
‑
crf结构捕捉双向的语义依赖,再加入crf对标签之间的依赖性建模,利用crf来学习一个最优路径,进行实体级别的标签预测,可以提升文本数据的采集和录入的时间,提升效率节约人工成本。
附图说明
24.图1为本发明的一种处理带格式风格文本的要素内容抽取方法的流程图;
25.图2为本发明的一种处理带格式风格文本的要素内容抽取系统的结构示意图。
具体实施方式
26.为了便于理解本发明,下面将参照相关附图对本发明进行更全面的描述,附图中给出了本发明的若干实施例,但是,本发明可以以许多不同的形式来实现,并不限于本文所描述的实施例,相反地,提供这些实施例的目的是使对本发明的公开内容更加透彻全面。
27.需要说明的是,当元件被称为“固设于”另一个元件,它可以直接在另一个元件上或者也可以存在居中的元件;当一个元件被认为是“连接”另一个元件,它可以是直接连接到另一个元件或者可能同时存在居中元件;本文所使用的术语“垂直的”、“水平的”、“左”、“右”以及类似的表述只是为了说明的目的。
28.除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同;本文中在本发明的说明书中所使用的术语只是为了描述具体的实施例的目的,不是旨在于限制本发明;本文所使用的术语“及/或”包括一个或多个相关的所列项目的任意的和所有的组合。
29.实施例1
30.参照附图1,本实施例的一种处理带格式风格文本的要素内容抽取方法,所述方法具体包括如下步骤:
31.s100、事件检测;
32.s200、事件定义;
33.s300、文本标注;
34.s400、模型训练;
35.s500、特征提取;
36.s600、标签预测。
37.步骤s100具体为首先将文本中的事件触发词和事件元素都抽取出来如:发行人、债券品种、债券金额等实体元素。之后根据实体触发词和实体元素对应到相应的独立事件。
38.步骤s200具体为基于ideal平台上所发布的信息,确定事件类型,首先定义触发词如:违约、发行等事件触发词。之后基于触发词再定义相关事件元素。
39.步骤s300具体为如果任务为事件检测,则对文本进行事件类型、事件触发词、事件元素标注。如果任务为实体识别,对相关文本进行bio标注,其中b为begin代表某个实体类型开始,i为immediate表示某实体的中间位置,o为other代表其他,不是实体。
40.步骤s400中的模型训练具体为将批注好的句子级语料先进行分词,获取token级别的序列信息和注意力信息。将这些序列信息输入到预训练bert模型中,在bert模型中经过注意力机制、线性层来提取字向量表示,再输送到bilstm
‑
crf模型中,预测词向量的标签,将预测的标签和真实标签进行比较计算并反馈。不断重复这个过程,以得到训练后用于要素级别实体抽取的模型。
41.步骤s500具体为进行预测时,模型会对输入的文本进行向量化,并通过bert获取信息向量,得到特征。
42.步骤s600具体为将获得的特征输入bilstm
‑
crf中,已经学习过的模型进行预测出标签,最后根据标签进行实体的抽取。
43.一种处理带格式风格文本的要素内容抽取系统,包括事件检测模块和要素级别实体抽取模块,所述事件检测模块采用bilstm
‑
maxpooling作为句子编码器,将文本生成对应的句子向量;采用bilstm
‑
crf对长文本中的句子进行标注,从而区分出每个相关的独立事件,所述要素级别实体抽取模块采用预训练好的bert模型进行特征提取,得到句子中每个字的嵌入向量,采用bilstm
‑
crf结构捕捉双向的语义依赖,再加入crf对标签之间的依赖性建模,利用crf来学习一个最优路径,进行实体级别的标签预测。
44.以上所述实施例仅表达了本发明的某种实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制;应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围;因此,本发明专利的保护范围应以所附权利要求为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1