一种本地Docker镜像信息采集系统及其采集方法与流程
本申请涉及对docker镜像信息的漏洞扫描的技术领域,尤其涉及一种本地docker镜像信息采集系统及其采集方法。
背景技术:
随着虚拟化技术的高速发展,容器技术逐渐成为各类行业和业务的主流部署方式,容器是基于镜像来创建生成的,镜像是构建容器的基础。具体的说,镜像可以是一种文件系统,而容器是镜像运行的实例。其中,作为容器基础的docker镜像是一种分层结构,镜像的每一层都称为一个镜像层,其中,下层镜像层是上层镜像层的变更基础,镜像的变更都发生在上一层,也就是说,上层镜像层是在下层镜像层的基础上进行变更。
随着容器技术应用的推广和普及,容器安全问题也日益引起关注,当需要使用容器技术时,需要获得容器的镜像,docker镜像安全从而成为容器安全的一个重要方面。docker镜像包含了容器运行时的基本系统环境,包括文件系统和应用软件,若其中存在安全漏洞,当容器基于包含漏洞的docker镜像运行时,攻击者即可利用docker镜像中携带的漏洞进行攻击,因此,检查docker镜像的安全性是一个重要的环节。而镜像文件中的打包和叠加层存储的形式使得对其进行信息采集和深度分析的难度增加。开发人员的不规范使用、开源软件漏洞、恶意软件注入等在镜像中的打包注入让基于镜像的容器环境和业务环境存在很多安全隐患。
面对这样的情况,通常使用的漏洞扫描的方法是通过镜像信息采集和分析对其进行解析以供进一步分析,一般是使用开源软件clair通过分层的方式解析docker镜像,将docker镜像按逐层解压分析的方式来进行,但这样的方式无法以镜像为单位进行分析,在镜像层与层之间具有文件覆盖情况时,还需要进行额外的分析,并且这种解析方法需要在主机内存中解压文件,这就对主机资源带来了额外的性能消耗。
另外,专利号为cn109933342a的申请文件公开了一种从本地docker镜像中提取文件内容的方法及装置,该发明专利首先对本地镜像进行存储引擎解析,并根据存储引擎的不同进行不同的适配,以逐层叠加的还原镜像文件,这种方式采用了以镜像为单位进行解析的方式,然而其对不同存储引擎的适配和调用带来了额外的计算消耗,同时适配的工作还带来了额外的系统故障点,对本地docker镜像系统可能带来一定的稳定性影响。
综上,现有镜像的漏洞扫描大多基于层信息进行逐层分析,这样就会带来额外的计算消耗和资源消耗,而少数以镜像为单位的扫描需要适配不同的叠加存储引擎,通过外部构建叠加存储的方式进行信息镜像信息还原,这样的方式带来额外的适配和更多的故障点,对原有系统和业务可能带来稳定性影响,具有一定缺陷。
技术实现要素:
本申请提供一种本地docker镜像信息采集系统,包括获取基础信息模块、挂载采集文件夹模块、建立新镜像模块、执行采集模块以及存储模块;
所述获取基础信息模块用于获取本地待采集的docker镜像的基础信息;所述镜像基础信息至少包括id、标签和仓库名;
所述挂采集文件夹模块能够为每个待采集的镜像配置相应的采集文件夹和挂载路径;
建立新镜像模块用于在镜像上增加新镜像层,建立能够将镜像信息拷贝到采集文件夹的新镜像;
执行采集模块用于启动新镜像对应的容器,容器运行,将镜像信息拷贝到采集文件夹,完成采集任务;
所述存储模块用于提供底层存储基础。
其中,还包括容器管理模块,用于维护和管理以新镜像为运行基础的容器的运行状态;容器管理模块包括获取容器状态模块、处理容器异常模块以及回收容器模块。
所述获取容器状态模块用于持续性的获取容器状态信息;所述处理容器异常模块用于通过获取到的容器状态信息判断容器是否异常;所述回收容器模块用于将完成信息采集的容器回收。
其中,所述存储模块包括镜像基础信息存储模块、采集任务存储模块以及采集结果存储模块;所述基础信息获取模块与所述存储模块交互存储。
其中,所述镜像基础信息还包括扫描时间、镜像大小和镜像架构。
本申请还包括一种本地docker镜像信息采集系统的镜像信息采集方法,步骤具体包括:
s10,获取本地待采集的docker镜像的基础信息,所述镜像基础信息至少包括id、标签和仓库名;
s20,建立镜像信息采集任务,为待采集的docker镜像提供采集文件夹挂载目录;
s30,在镜像的原始镜像层上增加能够将镜像文件内容拷贝到采集文件夹的新镜像层,从而形成新镜像;
s40,在以新镜像为运行基础的容器运行时,执行将镜像文件内容拷贝到采集文件夹的操作。
其中,在步骤s40中,还包括:所述采集文件夹为虚拟文件夹,在通过新镜像启动容器时,增加外部磁盘映射指令,将虚拟的采集文件夹内容映射至根目录下的实体文件夹,作为容器的运行基础。
其中,在步骤s10中,使用dockerapi或者容器指令获取本地待采集的docker镜像的基础信息,形成基础信息列表。
其中,遍历基础信息列表,判断是否已经为内容相同的镜像进行过镜像信息的采集,如果已经为内容相同的镜像进行过采集,则将已完成的采集结果关联至该镜像,跳过该镜像,进行下一个任务。
其中,在步骤s40之后,还包括步骤s50,在逐步启动以新镜像为运行基础的容器后,对容器状态持续监控,当容器正常停止运行时,删除容器;当容器异常停止运行时,记录错误并删除容器。
本申请实现的有益效果如下:
本发明基于原生容器环境构建采集系统,为待扫描镜像添加镜像层形成新镜像,并基于新镜像构造新容器,在安全环境下运行新容器进行信息采集,通过这样的方式能够屏蔽对镜像存储方式的不同而引起的额外适配和程序处理工作,从而提高系统运行效率。同时,在采集任务构建中,通过镜像id区别镜像唯一性,以去除重复内容镜像的采集任务,从而实现更高性能的镜像信息采集。并且,本发明使用技术主要基于原生容器环境,基于原生api或指令构建镜像和容器编译、运行、状态维护、存储等功能,没有外部运行时环境的引入和适配,因此可以极大程度降低采集系统故障点、减少采集系统对原有系统的影响,保障系统整体稳定性。
附图说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请中记载的一些实施例,对于本领域技术人员来讲,还可以根据这些附图获得其他的附图。
图1a、1b为docker镜像的内容进行更改时镜像层文件的逻辑结构图。
图1c为容器运行时将镜像作为一个整体进行读取时的逻辑结构图。
图2为本申请本地docker镜像信息采集系统的逻辑结构图。
图3位本申请本地docker镜像信息采集方法的步骤流程图
具体实施方式
下面结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
docker是一个开源的应用容器引擎,让开发者可以打包应用以及依赖包到一个可移植的容器中,然后发布到任何流行的linux或windows机器上,也可以实现虚拟化,容器是完全使用沙箱机制,相互之间不会有任何接口。
一个完整的docker有以下几个部分组成:客户端(client)、守护进程(daemon)、镜像(image)以及容器(container)。
其中,docker镜像类似于虚拟机中的镜像,是一个包含有文件系统的面向docker引擎的只读模板,任何应用程序运行都需要环境,而镜像就是用来提供这种运行环境的,docker镜像是一种多层文件结构,每一层都被称为一个镜像层(layers),我们可以将docker镜像的多层结构看成一个统一文件系统(联合文件系统),docker进程认为整个文件系统是以读写方式挂载的。所有的docker镜像都起始于一个基础镜像层,当进行修改或者增加新的内容时,就会在当前镜像层之上,创建新的镜像层。也就是说,当产生变更时,属于下层的原始的镜像文件不会发生变化,所有的变更都发生在顶层。
docker容器,是docker镜像的一个应用实例,容器可以被创建、启动、停止、删除,各个容器之间是相互隔离的,互不影响。docker容器类似于一个轻量级的沙盒,可以将其看作一个极简的linux系统环境(包括root权限、进程空间、用户空间和网络空间等),以及运行在其中的应用程序。
当docker容器从docker镜像启动时,docker在所有的镜像层之上创建一个可写层,docker镜像本身不变。这个可写层有运行在cpu上的进程,而且有两个不同的状态:运行态(running)和停止态(exited)。当有一个docker容器正在运行时,从运行态到停止态,对它所做的一切变更都会永久地写到容器的文件系统中,而不是写入到docker镜像中。
dockerfile是一个用来构建镜像的文本文件,文本内容包含了构建镜像所需的指令和说明。比如,dockerfile从from命令开始,紧接着跟随各种方法、命令和参数,可以使用dockerbuild指令建立镜像,使用指令dockerrun启动容器。
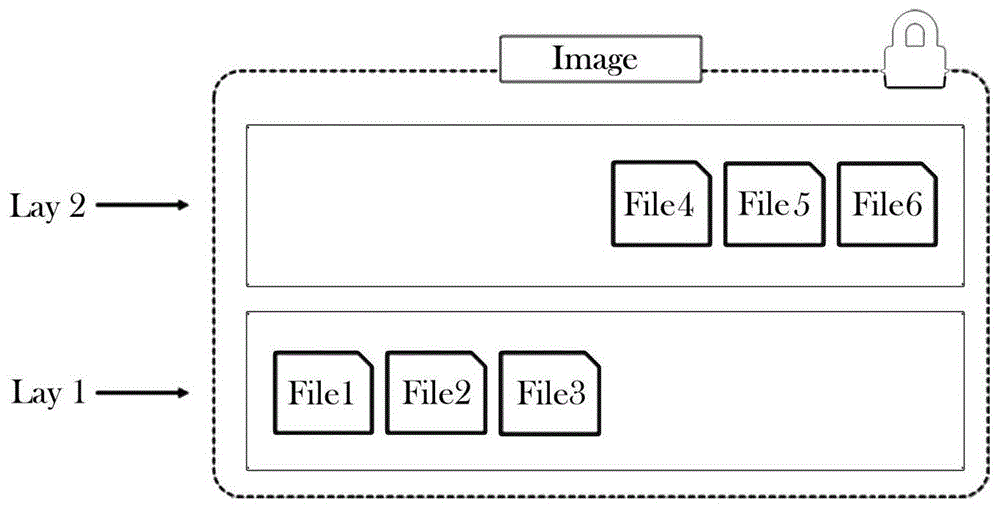
docker镜像所使用的分层存储的概念,除当前层外,之前的每一层都是不会发生改变的,换句话说,任何修改的结果仅仅是在当前层进行标记、添加、修改,而不会改动当前层下面的其他层,如图1a、图1b所示,镜像image的第一层镜像层(lay1)包括文件1、文件2和文件3,在第一层之上的第二层(lay2)包括文件4、文件5和文件6,在第二层之上的第三层(lay3)对文件5做出了更改,使用文件7替换了文件5,由于镜像是用上层的层文件对下层的层文件做出修改,因此第二层中的文件5在第二层上不会被直接替换,而是在第三层上做出替换的更改。
而以这个docker镜像为基础,启动镜像对应的容器后,在docker服务的帮助下,能够以单层的方式读取镜像的内容,如图1c所示,容器启动后,虽然docker镜像的层文件在基本存储方式上没有改变,但容器运行起来以后,从用户的角度上来看,docker对镜像的读取就是在读一个整体,也就是说,把镜像的多层结构在逻辑上合并为一层,逻辑结构上的合并状态如图1c所示,得到的是原有的镜像文件经过多层更改后最终的状态。
根据以上的docker技术,本申请提供一种本地docker镜像信息采集系统,包括获取基础信息模块、挂载采集文件夹模块、建立新镜像模块、执行采集模块以及存储模块;
还包括容器管理模块,用于维护和管理以新镜像为运行基础的容器的运行状态;容器管理模块包括获取容器状态模块、处理容器异常模块以及回收容器模块。
所述获取容器状态模块用于持续性的获取容器状态信息;所述处理容器异常模块用于通过获取到的容器状态信息判断容器是否异常;所述回收容器模块用于将完成信息采集的容器回收。
所述获取基础信息模块用于获取本地待采集的docker镜像的基础信息;所述镜像基础信息至少包括id、标签和仓库名;通过id、标签和仓库名,能够定位到一个镜像,并且能够确定这个镜像是否在本地。
所述挂采集文件夹模块能够为每个待采集的镜像配置相应的采集文件夹和挂载路径;
建立新镜像模块用于在镜像上增加新镜像层,建立能够将镜像信息拷贝到采集文件夹的新镜像;
执行采集模块用于启动新镜像对应的容器,容器运行,将镜像信息拷贝到采集文件夹,完成采集任务;
所述存储模块用于提供底层存储基础,包括镜像基础信息存储模块、采集任务存储模块以及采集结果存储模块;所述基础信息获取模块与所述存储模块交互存储。
本申请还提供了一种本地docker镜像信息采集方法,所述方法的步骤具体包括:
1、获取本地主机中待采集的docker镜像的基础信息:
该步骤中,使用dockerapi或者容器指令能够获取本地主机中docker镜像的基础信息。
api(applicationprogramminginterface,应用程序编程接口)是一些预先定义的函数,能够提供应用程序与开发人员基于某软件或硬件得以访问一组例程的能力,而又无需访问源码,或理解内部工作机制的细节。dockerapi就是docker给应用程序的调用接口。
使用dockerapi时,由系统识别本地主机容器环境,并适配不同容器版本进行api调用获取信息;使用容器指令时,则是使用docker系统指令获取信息。
其中,需要获得的docker镜像的基础信息至少包括镜像id、镜像仓库名(repository)以及镜像标签(tag)。
docker镜像是需要放到统一的仓库中的,以便不同的主机可以使用相同的镜像,根据仓库名、标签和id,能够具体定位一个镜像(仓库名、标签之间采用“:”分隔),以及确认这个镜像是否在本地。
具体的,在本实施例中,遍历本地主机中所有镜像,将所有镜像的基础信息形成基础信息列表,其中,表1为使用dockerapi获取的主机中的docker镜像形成的基础信息列表:
表1
保存上述镜像的基础信息列表,保存方式可以使用数据库存储、文件存储或程序内存存储。
本实施例中,docker镜像的基础信息包括镜像id、镜像仓库名(repository)以及镜像标签(tag),在其他一些实施方式中,基础信息还可以包括扫描时间、镜像大小、镜像架构等。
2、根据上一步骤中得到的的docker镜像列表,为待采集的每个镜像增加镜像层,该镜像层用于将镜像中的文件信息拷贝入采集文件夹,也就是在原始镜像的顶层,增加了一层用于信息采集的镜像层,从而形成新镜像,具体的增加镜像层及形成新镜像的步骤为:
建立镜像信息采集任务,遍历列表中所有增加镜像层后建立的新镜像,为镜像信息采集任务配置相应的虚拟的采集文件夹和挂载路径,在新镜像启动时增加外部磁盘映射指令,将上一步中所配置的采集文件夹映射至根目录下的实体文件夹中,为新镜像的容器提供运行基础,运行新镜像的容器,容器自动完成采集任务,将镜像文件拷贝到采集文件夹中。
比如,基于上一步中获取的docker镜像基础信息列表中的镜像仓库和标签信息,通过dockerfile构造镜像编译文件,以表1列表中编号为1,名称为alpine:3.3镜像为例:首先为镜像alpine:3.3提供执行采集镜像信息任务时的采集文件夹和挂载路径,比如,我们建立一个虚拟的采集文件夹infocatch,增加拷贝命令使镜像文件能够通过采集文件夹的挂载路径/infocatch拷贝到虚拟的采集文件夹infocatch中,从而建立新镜像;在通过新镜像启动容器时,增加外部磁盘映射指令,将虚拟的采集文件夹infocatch映射至根目录下的实体文件夹,根据拷贝命令和挂载路径将镜像文件拷贝到虚拟的采集文件夹中,同时映射至根目录下的实体文件夹内,运行容器完成采集任务。
其中,具体的构造的dockerfile命令,如下所示:
fromalpine:3.3
(这里使用from命令,是将仓库名为alpine,标签为3.3的镜像作为原始镜像);
runmkdir-p/infocatch
(执行run语句,使用mkdir–p命令,创建在/这个目录下的名为infocatch的文件夹,执行run语句会在原始镜像层之上增加新的镜像层);
cmd[“cp-r`find/-typed-path/infocatch-prune-o-print|sed1d`/infocatch”]
(执行cmd语句,通过cp–r命令,将除infocatch以外的文件和文件夹拷贝到infocatch文件夹中);
dockerbuild-talpine:3.3-infocatch.
(将增加了镜像层后的镜像文件,通过dockerbuild命令编译为名为alpine:3.3-infocatch的新镜像:其中,.代表当前文件夹,也就是使用当前文件夹的dockerfile创建名为alpine:3.3-infocatch的新镜像)。
dockerrun-itd-v/root/infocatch/a6fc1dbfa81a7fc3119a3a28ce05d1d3f31898169603af669c75640880150de7:/infocatch:rw—namealpine:3.3-infocatch-containeralpine:3.3-infocatch
(执行dockerrun命令,将以镜像名为alpine:3.3-infocatch的新镜像作为运行基础的容器命名为alpine:3.3-infocatch-container,以原始镜像id作为其镜像信息采集任务中实体文件夹的名称,将实体文件夹命名为:a6fc1dbfa81a7fc3119a3a28ce05d1d3f31898169603af669c75640880150de7将虚拟的采集文件夹infocatch映射至实体文件夹a6fc1dbfa81a7fc3119a3a28ce05d1d3f31898169603af669c75640880150de7作为容器运行的基础,执行dockerrun指令运行alpine:3.3-infocatch-container容器,运行后,alpine:3.3-infocatch-container容器自动完成镜像信息采集,将容器运行时的原始镜像内容拷贝到采集文件夹中)。
具体的,当新镜像构建成功后,docker会返回一个镜像的整体id,运行容器时,就可以通过这个id读写容器的方式,将所有镜像当做一个整体来进行读写,在整体的底层指向多层内容。
在dockerfile命令语句中,cmd语句是最后执行的,也就是说,容器运行以后,会将原始文件的所有文件信息复制到挂载的卷中。在容器启动后,我们能够得到docker对原始镜像的多层镜像文件以单层结构的读取,从而得到逻辑结构上合并后的镜像文件,通过cmd语句中的cp–r的拷贝命令,将此时合并状态的原始镜像文件拷贝出来,对其进行漏洞扫描,就相当于是对合并成一层的的最终状态的镜像进行扫描,此时不需要分层解析,也不需要使用多个引擎,直接进行漏洞扫描即可。
由于新镜像容器也会执行原始镜像容器所有的指令操作,因此为了保证运行安全,新镜像容器需要在安全环境中运行。
在具体实施中,在遍历待采集的docker镜像时,通过镜像id区别镜像唯一性,判断是否已为内容相同的镜像进行过镜像信息采集任务,如果已经为内容相同的镜像进行过采集任务,则将已完成相同内容采集的镜像采集结果关联至该镜像采集结果,并跳过该镜像采集任务。
3、采集任务完成后,删除所启动的新镜像容器。
该步骤中,在上一步逐步启动新镜像容器后,循环遍历主机上新镜像容器,当容器正常停止运行时,删除容器;否则,当容器异常停止运行时,记录错误并删除容器。
尽管已描述了本申请的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例作出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本申请范围的所有变更和修改。显然,本领域的技术人员可以对本申请进行各种改动和变型而不脱离本申请的精神和范围。这样,倘若本申请的这些修改和变型属于本申请权利要求及其等同技术的范围之内,则本申请也意图包含这些改动和变型在内。
- 还没有人留言评论。精彩留言会获得点赞!