用于标记、检查和校正P&ID的标记预测的技术的制作方法
用于标记、检查和校正p&id的标记预测的技术
技术领域
1.本公开总体上涉及在工厂和基础设施项目中的管路和仪表图(p&id)的使用,并且更具体地涉及用于标记、检查和校正以仅图像格式的p&id的预测的技术。
背景技术:
2.许多工程领域利用功能图。与表示元件的特定位置、大小和形状的物理模型相比之下,功能图与位置、大小和形状无关,而是聚焦于工艺流程上。在工厂和基础设施设计和维护的领域中,常见类型的功能图是p&id。图1是示例p&id 100的一部分的视图。p&id包括表示元件(例如,阀、泵,容器、仪器等)的符号110、提供元件的描述(例如,名称、代码、属性等)的文本框120、表示元件(例如,管路、电线等)之间的连接的连接130、以及其它信息(例如,标题框、图例、注释等)(未示出)。
3.典型的工厂或基础设施项目可能具有在许多年的过程中已经创建的数百个相关p&id。这些p&id通常可能以缺少关于其中表示的符号、文本框和连接的机器可读信息(例如,元数据)的仅图像格式(例如,作为诸如jpg或png的图形文件,或作为仅图像pdf等)可得。有时,仅图像p&id源自打印文档的扫描,并且质量差、具有低分辨率、视觉伪影、不清醒或模糊部分等。
4.以仅图像格式,p&id中的信息难以验证并且难以使用。越来越期望创建工厂和基础设施的数字孪生(twin),并且p&id中的信息在创建这样的模型时是通常有用的。然而,由于以仅图像格式的信息在很大程度上对于设计和建模应用是达不到的,所以获得这样的信息通常涉及冗长的手动检查和数据输入。即使利用仅图像格式来更新p&id本身也是困难的。通常,为了进行改变,需要手动重新创建整个p&id,来以可更容易编辑的机器可读形式表示信息。
5.解决以仅图像格式的p&id问题的一种可能的方法是使用机器学习来从p&id中自动提取信息并将其以机器可读形式存储。然而,用于p&id数据提取的机器学习算法的部署提出了辅助技术挑战。通常,机器学习需要大量的带注释数据,人工智能可以根据所述带注释数据推断机器学习模型。对于p&id数据提取,该带注释数据可以采取标记的示例p&id的形式,其包括文本框、符号、连接等的描绘(例如,光栅图像)和对应的机器可读标记。然而,这样的标记的示例p&id已经很少存在,并且出于使用现有软件应用和工作流程来训练机器学习算法的目的而特别创建标记的示例p&id是艰巨的任务。典型的p&id可以包括数千个文本框、符号和连接。然而,现有软件应用和工作流程通常缺乏用于提高重复任务的效率的任何显著的自动化或支持。虽然当仅存在几十个元件时其可能是可工作的,但是当元件的数量调节成数千个时,其被证明是不切实际的。
6.在处理用于p&id数据提取的机器学习算法的输出时面临类似的技术挑战。输出可以采取标记的p&id的形式,其中机器学习算法已经正确地预测了大多数标记,但是存在几个错误。可能期望使用户检查预测的标记并校正错误。然而,使用现有软件应用和工作流程,这是艰巨的任务。类似于在创建用于训练的标记的数据集合时,对于提高重复任务的效
率的任何显著自动化或支持的缺乏阻碍了预测的标记的检查和校正,从而使得工作流程不切实际。
7.因此,存在对用于标记、检查和校正以仅图像格式的p&id的预测的改进技术的需要。
技术实现要素:
8.在示例实施例中,提供了用于有效地标记、检查和校正以仅图像格式(例如,jpg、png、仅图像pdf等)的p&id的预测的技术。标记应用加载仅图像p&id并对其进行预处理以光栅化p&id、针对p&id调整大小和/或颜色上分离p&id。为了标记p&id中的文本框,标记应用执行ocr算法以预测每一个文本框周围的边界框和每一个文本框内的机器可读文本,并且在其用户界面中显示这些预测。标记应用提供用于接收对于每一个预测的边界框和预测的机器可读文本的用户确认或校正的功能性。为了标记p&id中的符号,标记应用接收用户输入以在符号周围绘制边界框并将符号分配给装备的种类。在存在特定符号的多次出现的情况下,标记应用提供用于复制并自动检测和分配边界框和种类的功能性。在复制中,标记应用将给定符号周围的边界框复制到另一符号周围,并将待分配的种类复制到另一符号。在自动检测和分配中,标记应用自动检测对应于给定符号的其它相同符号、将边界框放置在其周围并且自动地向其分配与给定符号相同的种类。为了标记p&id中的连接,标记应用接收用户输入以定义对应符号处的连接点,并且创建连接点之间的连接。
9.除了在此发明内容中讨论的那些之外,各种附加特征可以由标记应用实现,以提供自动化、提高工作流程效率或提供其它益处。此发明内容旨在简单地作为对读者的简要介绍,并且不指示或暗示本文中提及的示例涵盖本公开的所有方面,或者是本公开的必要或基本方面。
附图说明
10.描述涉及示例实施例的附图,其中:图1是示例p&id的一部分的视图;图2是可以用于针对以仅图像格式(例如,jpg、png、仅图像pdf等)的p&id进行标记、检查标记和校正预测的示例标记应用的高级框图;图3a-3b是用于将机器可读标记分配给以仅图像格式的p&id的高级步骤序列;图3c是用于示例冲突检测算法的步骤序列;图4是示出主窗口中的光栅化p&id的示例标记应用的用户界面的屏幕截图(shot);图5是示出第一文本框的正确预测的边界框和正确预测的机器可读文本的示例标记应用的用户界面的屏幕截图;图6是示出第二文本框的错误预测的边界框和错误预测的机器可读文本的示例标记应用的用户界面的屏幕截图;图7是示出对第二文本框的错误预测的边界框的校正的示例标记应用的用户界面的屏幕截图;图8是示出对第二文本框的错误预测的机器可读文本的校正的示例标记应用的用
户界面的屏幕截图;图9是示出绘制符号的边界框的示例标记应用的用户界面的屏幕截图;图10是示出选择装备的种类的示例标记应用的用户界面的屏幕截图;图11是示出复制操作的示例标记应用的用户界面的屏幕截图;图12是示出将边界框和种类自动分配给符号的示例标记应用的用户界面的屏幕截图;图13是示出标记符号的第一属性的示例标记应用的用户界面的屏幕截图;图14是示出标记符号的第二属性的示例标记应用的用户界面的屏幕截图;图15是示出定义连接点和创建连接的示例标记应用的用户界面的屏幕截图;图16是示出标记连接的属性的示例标记应用的用户界面的屏幕截图;以及图17是示出形成文本关联的示例标记应用的用户界面的屏幕截图。
具体实施方式
11.图2是可以用于针对以仅图像格式(例如,jpg、png、仅图像pdf等)的p&id进行标记、检查标记并校正预测的示例标记应用200的高级框图。标记应用200可以是独立的软件应用或较大软件应用(例如,设计和建模软件应用)的部件。软件可以被划分为在终端用户本地的一个或多个计算设备(统称为“本地设备”)上执行的本地软件210,以及在一些情况下,在经由网络(例如,互联网)可访问的远离终端用户的一个或多个计算设备(统称为“云计算设备”)上执行的基于云的软件212。每一个计算设备可以包括处理器、存储器/存储装置、显示屏和用于执行软件、存储数据和/或显示信息的其它硬件(未示出)。本地软件210可以包括在本地设备上操作的前端客户端220和一个或多个后端客户端230。在一些情况下,基于云的软件212可以包括在云计算设备上操作的一个或多个后端客户端230。前端客户端220可以提供用户界面功能性以及执行与以下操作相关的某些非处理密集操作:将机器可读标记分配给以仅图像格式的p&id、并且在一些情况下检查以仅图像格式的p&id的预测的机器可读标记并校正预测的机器可读标记。预测的机器可读标记可以由p&id数据提取应用(未示出)的机器学习算法提供。p&id数据提取应用可以是单独的软件或标记应用200是其一部分的相同较大软件应用的另一部件。(一个或多个)后端客户端230可以执行与将机器可读标记分配给以仅图像格式的p&id以及校正预测的机器可读标记相关的某些更加处理密集的操作(例如,光学字符识别(ocr)操作)。前端客户端220和(一个或多个)后端客户端230可以同时对不同的任务进行操作,使得用户可以在一个或多个后端客户端230正在执行不同的任务的同时利用标记应用200的用户界面来执行任务,而无需等待其完成。
12.图3a-3b是用于将机器可读标记分配给以仅图像格式的p&id的高级步骤300的序列。这样的步骤可以作为生成被用作用于训练p&id数据提取应用的机器学习算法的输入的标记的数据集合的一部分来执行。在这种情况下,当初始执行步骤300时,p&id中可能没有用于文本框、符号和连接的现有机器可读标记。可替代地,步骤300中的至少一些可以作为对由p&id数据提取应用的机器学习算法输出的预测的标记校正错误的一部分来执行。在这种情况下,当执行步骤时,p&id中可能存在用于至少一些文本框、符号和连接的现有预测的机器可读标记,并且所述步骤可以用于通过分配校正的标记来校正这样的预测。
13.在步骤310处,标记应用200加载缺少描述文本框、符号、连接等的机器可读信息
(例如,元数据)的以仅图像格式(例如,jpg、png、仅图像pdf等)的p&id。在一些情况下,p&id源自打印文档的扫描。
14.在步骤320处,标记应用200对p&id进行预处理以光栅化p&id、针对p&id调整大小和/或颜色上分离p&id。光栅化可能涉及解压缩、转换和/或提取操作以产生光栅化的p&id。调整大小可能涉及将分辨率(例如,每英寸点数(dpi))改变为更容易显示和/或处理(例如,通过ocr算法)的分辨率。颜色上分离可能涉及分离颜色通道以促进更容易的处理(例如,不同颜色的文本可以重叠,如果不分离,这可能干扰ocr算法)。
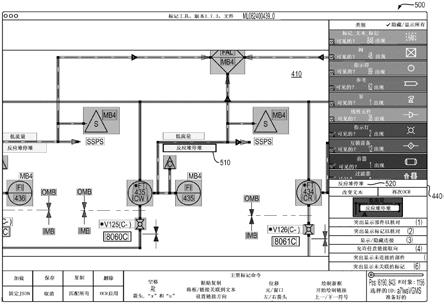
15.在步骤330处,标记应用200在其用户界面的主窗口内显示光栅化的(以及调整大小的和颜色上分离的)p&id。图4是示出主窗口410中的光栅化p&id的示例标记应用200的用户界面的屏幕截图400。用户界面还包括命令菜单420、列出用于符号和连接的可能标记的类别菜单430、用于显示用于当前选择的文本框的预测的机器可读文本的文本检测结果框440、以及用于显示放大的p&id的一部分的视图的放大部分窗口450。
16.在步骤340处,标记应用200通过执行多个子步骤来标记p&id中的文本框。子步骤可以取决于标记是生成被用作用于训练p&id数据提取应用的机器学习算法的输入的标记的数据集合的一部分还是作为对由p&id数据提取应用的机器学习算法输出的预测的标记校正错误的一部分而变化。在标记是生成标记的数据集合的一部分的情况下,在子步骤342处,标记应用200执行ocr算法,该ocr算法预测包围p&id中的每一个文本框的边界框以及p&id中的每一个文本框内的文本。可替代地,在标记是对预测的标记校正错误的一部分的情况下,可以跳过子步骤342,并且根据与p&id相关联的数据(例如,java描述语言对象符号(json)文件)加载的预测的边界框根据p&id数据提取应用的机器学习算法输出。
17.在子步骤344处,标记应用200显示文本框中的每一个的预测的边界框和预测的机器可读文本。预测的边界框(例如,用于视图中的那些文本框)可以在主窗口410中示出,而预测的机器可读文本(例如,用于当前选择的文本框)可以在检测结果框440中示出。一些预测可能是正确的,而其它预测可能包括错误。图5是示出第一文本框的正确预测的边界框和正确预测的机器可读文本的示例标记应用200的用户界面的屏幕截图500。在该示例中,当前选择的文本框用于反应堆停堆(reactor trip)。突出显示边界框510,同时在检测结果框440中示出预测的机器可读文本“反应堆停堆”。图6是示出第二文本框的错误预测的边界框和错误预测的机器可读文本的示例标记应用200的用户界面的屏幕截图600。在该示例中,当前选择的文本框用于阀。突出显示边界框610,同时在检测结果框440中示出预测的机器可读文本“注释1”。如可以看到的,边界框610没有完全包围文本框(切断“5”的部分),并且预测的机器可读文本漏掉字符(缺少“5”)。
18.在子步骤346处,对于每一个项目,标记应用200接收预测的边界框或预测的机器可读文本是正确的确认,或者接收对预测的边界框或预测的机器可读文本的校正。每一个文本框可以标记有标志,直到接收到对应的确认或校正。为了促进快速检查,可以准许用户使用快捷方式(例如,键盘上的箭头键)滚动通过所有文本框或仅带标志的文本框。
19.在可以与其它子步骤342-346同时发生的子步骤348处,当一个边界框的多于预定义百分比的面积被包含在另一个边界框内时,标记应用200检测文本框的边界框的冲突,并自动删除一个边界框并且将相关的机器可读文本合并为另一个边界框的机器可读文本。这样的冲突检测可以解决与多行文本相关的ocr问题(其ocr算法倾向于分离而不是如通常期
望的那样分组在一起),并且以其它方式加速标记。
20.图3c是可以在子步骤348(以及还在下面进一步讨论的子步骤359)中使用的示例冲突检测算法的步骤301的序列。在步骤311处,冲突检测算法接收用于p&id的边界框的当前集合和对标记应用200的主窗口410中的p&id的可见部分的指示。边界框x-轴坐标和y-轴坐标可以维持在分类列表中。在步骤321处,冲突检测算法对x-轴坐标和y-轴坐标执行二等分(例如,左二等分)以返回冲突的潜在候选。x-轴和y-轴二等分可以与速度处理并行地执行。为了这样做,当进行任何修改时,冲突检测算法可以保持每一个坐标的边界框的更新列表有序。在步骤331处,冲突检测算法将用于x-轴坐标和y-轴坐标的二等分集合合并,并且仅保留适合两种情况的冲突的潜在候选。为了避免不必要的计算,合并可以聚焦于主窗口410中的p&id的可见部分。在步骤341处,冲突检测算法管理重叠的边界框。一些项目可以重叠(例如,符号内部的文本框)。在这种情况下,冲突检测算法可以为最小的一个选择边界框。在步骤351处,可以特别地处理对角边界框。在步骤311中,x-轴坐标和y-轴坐标上的二等分假定水平或垂直矩形边界框。为了适应(accommodate)在对角方向上布置的临时边界框,可以特别地检验与其的潜在冲突以避免伪冲突检测。在步骤361处,可以应用自定义用户过滤器以进一步减少冲突的潜在候选。最后,在步骤371处,返回剩余的边界框(如果有的话)。
21.图7是示出对第二文本框的错误预测的边界框的校正的示例标记应用200的用户界面的屏幕截图700。在该示例中,用户操纵主窗口410中的指针以拖动边界框610的拐角,使得其完全包围文本框(包括“5”的全部)。可替代地,用户可以拖动放大部分窗口450中的拐角以进行类似的校正。图8是示出对第二文本框的错误预测的机器可读文本的校正的示例标记应用200的用户界面的屏幕截图800。在该示例中,用户操纵检测结果框440中的文本光标以校正文本(添加漏掉的“5”)。在一些情况下,ocr算法(作为背景过程运行)可以检测校正的边界框并自动校正预测的机器可读文本。如果这样的自动校正本身不包括错误,则可以不需要检测结果框440中的校正。
22.在步骤350处,标记应用200通过执行多个子步骤来标记p&id中的符号。子步骤可以取决于标记是生成被用作用于训练p&id数据提取应用的机器学习算法的输入的标记的数据集合的一部分还是作为对由p&id数据提取应用的机器学习算法输出的预测的标记校正错误的一部分而变化。在子步骤352处,响应于用户界面中的用户输入,标记应用200在p&id中的符号中的至少一些符号的相应符号周围绘制边界框。在作为生成标记的数据集合的一部分来执行子步骤352的情况下,在符号周围可以不存在退出边界框,并且所述绘制可以创建新的边界框。可替代地,在执行子步骤352是对预测标记校正错误的一部分的情况下,可以在符号周围存在现有的预测边界框,并且所述绘制可以校正预测边界框以改变其大小或形状。图9是示出绘制符号的边界框的示例标记应用200的用户界面的屏幕截图900。在该示例中,符号是阀。用户操纵主窗口410中的指针910以拖动边界框920的拐角,使得其包围阀。可替代地,用户可以拖动放大部分窗口450中的拐角。
23.在子步骤354处,响应于用户界面中的用户输入,标记应用200向给定符号分配装备的种类。在作为生成标记的数据集合的一部分来执行子步骤354的情况下,可以不存在退出种类,并且该步骤可以向符号分配种类。可替代地,在执行子步骤354是对预测标记校正错误的一部分的情况下,可以存在现有的预测种类,并且该步骤可以校正预测种类。图10是
示出选择装备的种类的示例标记应用200的用户界面的屏幕截图1000。在该示例中,用户在类别菜单430中选择种类“阀”1010。然后将符号标记为阀。可以使用各种用户界面机制来促进有效的选择。例如,为了易于识别,可以以不同的颜色显示装备的不同种类。
24.在许多p&id中,特定符号在附图中出现多于一次,并且单独地标记这样的符号的每一个实例可能是高度重复的。当标记是生成被用作用于训练p&id数据提取应用的机器学习算法的输入的标记的数据集合的一部分或者作为对由p&id数据提取应用的机器学习算法输出的预测标记校正错误的一部分(例如,需要多次进行相同的校正)时,这可能发生。这样的重复可以以各种方式被解决。在子步骤356处,响应于用户界面中的用户输入,标记应用200将给定符号周围的边界框复制到另一符号周围,并将待分配的装备的种类复制到另一符号。图11是示出复制操作的示例标记应用200的用户界面的屏幕截图1100。在该示例中,用户选择边界框920和种类“阀”并将其复制(例如,通过按压命令菜单420中的按钮1110)并拖动表示1120以设置在阀的每一个实例期间。
25.可替代地,在子步骤358处,响应于用户界面中的用户输入,标记应用200使用图像检测算法来自动检测p&id中的与给定符号对应的其它相同符号,将边界框放置在其它符号周围,并且自动地向其分配与给定符号相同的种类。用户仅必须进行快速核对,而不是繁琐地在周围绘制边界框并为每一个其它符号选择种类。其它符号可以各自标记有标志,直到从用户接收到对于自动放置的边界框和自动选择的种类的对应确认或校正。为了促进快速检查,可以准许用户使用快捷方式(例如,键盘上的箭头键)滚动通过标记的符号。图12是示出了将边界框和种类自动分配给符号的示例标记应用200的用户界面的屏幕截图1200。在该示例中,用户选择边界框920和种类“阀”并且触发自动分配(例如,通过按压命令菜单420中的按钮1210)。标记应用200的图像检测算法自动检测符号1220、1230,在其周围自动绘制边界框,并向其分配种类“阀”。一些符号1220被正确地检测到,并且可能被用户确认。符号1230被错误地检测到,并且可能被用户校正。
26.在可以与其它子步骤352-348同时发生的子步骤359处,当一个边界框的多于预定义百分比的面积被包含在另一个边界框内时,标记应用200检测符号的边界框的冲突,并且自动删除边界框。上面在图3c中阐述的步骤可以用于执行符号的冲突检测。一些较大的符号可以包括较小的符号。通过冲突检测,可以确保较大的符号将利用应用于整个符号的单个边界框和种类来标记。
27.在步骤360处,标记应用200标记p&id中的符号的属性。该步骤可以取决于标记是生成被用作用于训练p&id数据提取应用的机器学习算法的输入的标记的数据集合的一部分还是作为对由p&id数据提取应用输出的预测标记校正错误的一部分而变化。在作为生成标记的数据集合的一部分来执行步骤360的情况下,可以不存在符号的退出属性。在将种类分配给符号时,用户可以选择该种类的属性列表上的多个属性中的每一个的值。每一个属性可以具有在用户没有主动做出选择的情况下使用的默认值。可替代地,在执行步骤360是对预测标记校正错误的一部分的情况下,可以存在现有的预测属性,并且该步骤可以校正预测属性。属性列表中的属性的用户选择的属性值可以覆盖预测的属性值。图13是示出标记符号的第一属性的示例标记应用200的用户界面的屏幕截图1300。在该示例中,用户在类别菜单430中选择种类“阀”1010。由边界框920包围的符号然后被标记为阀。阀可以具有多个属性,除了其它之外还包括类型属性(例如,门阀、球形阀、球阀、止回阀等)、开放属性(例
如、打开、锁定打开、常闭、锁定关闭等)。在此,用户为属性列表1310中的类型属性1320选择值“球形”1330。图14是示出标记符号的第二属性的示例标记应用200的用户界面的屏幕截图1400。在该示例中,用户选择属性列表1310中的开放属性1410的值“常闭”1330。
28.当标记应用200复制供其它符号使用的给定符号的边界框和种类时,或者当标记应用200自动检测给定符号的边界框和种类并将其应用于其它符号时,也可以复制或应用给定符号的属性。以这种方式,用户可以免于重复地输入p&id中的相同符号的属性。
29.在步骤370处,标记应用200通过执行多个子步骤来标记p&id中的连接。子步骤可以取决于标记是生成被用作用于训练p&id数据提取应用的机器学习算法的输入的标记的数据集合的一部分还是作为对由p&id数据提取应用的机器学习算法输出的预测标记校正错误的一部分而变化。在子步骤372处,响应于用户界面中的用户输入,标记应用200定义对应符号处的连接点。在作为生成标记的数据集合的一部分来执行子步骤372的情况下,可以不存在退出连接点,并且可以定义新的连接点。可替代地,在执行子步骤372是对预测标记校正错误的一部分的情况下,可以存在现有的预测连接点,并且定义可以移动现有的连接点或利用不同的连接点替换它们。标记应用200可以在没有用户输入的情况下自动地将连接点的位置调整为在符号的边界处。在子步骤374处,标记应用200创建连接点之间的连接。标记应用200可以自动地将连接与每一个连接点的符号相关联。图15是示出定义连接点和创建连接的示例标记应用200的用户界面的屏幕截图1500。在该示例中,用户已经指示了两个连接点1510、1520。响应于此,标记应用200已经在其之间创建了连接1530。
30.在步骤380处,标记应用200标记p&id中的连接的属性。该步骤可以取决于标记是生成被用作用于训练p&id数据提取应用的机器学习算法的输入的标记的数据集合的一部分还是作为对由p&id数据提取应用的机器学习算法输出的预测标记校正错误的一部分而变化。在作为生成标记的数据集合的一部分来执行步骤380的情况下,可以不存在连接的退出属性。可替代地,在执行步骤380是对预测标记校正错误的一部分的情况下,可以存在现有的预测属性,并且该步骤可以校正预测属性。用户可以从连接属性列表中选择属性的值。图16是示出标记连接的属性的示例标记应用200的用户界面的屏幕截图1600。在该示例中,用户已经从连接属性列表1620中选择了值“电气”1610。
31.在步骤390处,标记应用200将文本框中的至少一些与p&id中的相应符号或连接相关联,由此建立文本关联。该步骤可以取决于标记是生成被用作用于训练p&id数据提取应用的机器学习算法的输入的标记的数据集合的一部分还是作为对由p&id数据提取应用的机器学习算法输出的预测标记校正错误的一部分而变化。在作为生成标记的数据集合的一部分来执行步骤390的情况下,可以不存在退出关联。可替代地,在执行步骤390是对预测标记校正错误的一部分的情况下,可以存在现有的预测关联,并且该步骤可以校正预测关联。用户可以选择符号或连接,并然后选择将与其相关联的一个或多个文本框,从而将其链接在一起。当选择符号、连接或文本框时,与其相关联的项目可以被突出显示以使得能够快速检查关联。文本框可以与多个符号或连接相关联,并且符号或连接可以与多个文本框相关联。为了加速关联过程,标记应用200可以自动地将文本框与符号相关联,其中其相应的边界框重叠。图17是示出形成文本关联的示例标记应用200的用户界面的屏幕截图1700。在该示例中,用户已经选择了用于阀的符号1710,并然后通过按压键盘上的键并利用指针选择相应的文本框来指示其应当与两个文本框1720、1730相关联。
32.在步骤395处,标记应用200以机器可读格式存储用于文本框、符号和连接以及其之间的关联的机器可读标记。机器可读格式可以与仅图像格式分离,例如,与包括p&id图像的jpg文件、png文件或仅图像pdf文件相关但分离的json文件。可替代地,机器可读格式可以被集成到存储p&id图像的文件中。取决于使用情况,机器可读格式可以被提供作为用于训练p&id数据提取应用的机器学习算法的输入,或者可以被提供给设计和建模应用(例如,供构建模型/数字孪生使用)。
33.应当理解,虽然步骤300以序列示出,但是步骤300可以以各种不同的顺序执行。一些步骤300可以仅部分地在给定时间执行,并且这样的部分执行与其它步骤或其部分的执行交错。例如,p&id中的一些文本框可以被标记,然后一些符号可以被标记,然后一些更多的文本框可以被标记,然后一些更多的符号可以被标记,等等。此外,可以省略一些步骤300。例如,可能不存在用于需要校正的文本框的标记,并且可以省略校正子步骤324。
34.通常,应当理解,可以容易地对以上描述的内容进行各种适应和修改,以适合各种实现方式和环境。虽然以上讨论了技术的许多方面可由在特定硬件上执行的特定软件过程实现,但应理解,所述技术中的一些或全部也可由不同硬件上的不同软件实现。除了通用计算设备之外,硬件可以包括专门配置的逻辑电路和/或其它类型的硬件部件。最重要的是,应当理解,以上描述意在仅通过示例的方式被采取。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1