一种基于特征-时间注意力机制的多模态情感识别方法
本发明涉及模式识别的技术领域,尤其涉及一种基于特征-时间注意力机制的多模态情感识别方法。
背景技术:
情感作为人类生活体验的一个重要基础,影响着人类的认知、感知和日常生活。1971年,心理学家ekman和friesen通过跨文化研究将人的情感分为6种基本的情感类别,依次为高兴(happy)、悲伤(sad)、吃惊(surprise)、愤怒(angry)、恐惧(fear)和厌恶(disgust),这6类情感类别具有通用性,并且可以在此基础上合成更多细粒度的次级情感类别。1997年,picard教授首先提出了“情感计算”的概念,情感计算涉及心理学、认知学、模式识别、语音信号处理、生理学、社会学、计算机视觉和人工智能等方面,它利用计算机获取人类的脸部表情、语音等信息来识别人类表现出的情感状态,从而使机器能够更好地理解人类的情感和行为,以此带来更流畅和高效的交互体验。
“多模态”的概念最早由duc等人提出,旨在利用表情和语音模态信息来识别人的身份和行为。多模态融合的方法一般有特征融合和决策融合。特征融合能够最大程度得保留各个模态的信息,但也存在着多个模态信息同步问题和因特征维度太大而出现的过拟合问题。决策融合是在各个模态模型得出情感识别结果后,对最后的结果以某种规则进行最后判决,灵活性高,实时性强,但由于最后只能获得各个模态上的判定结果,信息量较少,相对精度较低。
随着近年来深度学习技术的不断发展,越来越多的研究者将其应用于多模态情感识别,chen等人在2016年emotiw情感识别挑战赛中,在语音模态上使用声学统计特征等多种语音特征,在人脸表情模态上使用cnn特征等多种人脸表情特征,针对每种特征训练支持向量机、随机森林和逻辑回归分类器,并采用决策融合的方法来实现最后的情感识别,取得了远高于基线的成绩。noroozi等人提出了一种新型的基于语音和视频的决策融合方法的多模态情感识别系统,从语音中提取基于mfcc的特征,并从视频中计算面部标记的几何关系,在enterface’05数据库上取得了较好的识别效果。chao等人在2015年emotiw情感识别挑战赛中融合了使用长短时记忆神经网络聚合的语音和人脸表情特征,并对得到的特征采用svm分类器来实现最后的分类,实现特征融合方法的情感识别方法,在测试集上取得了很高的识别率。
由于用于训练神经网络的多模态数据较少,且多模态融合特征维度较高,深度网络极易出现过拟合且十分依赖人的先验知识,为此需要引入一种使网络自动关注局部有效信息地机制,即注意力机制。注意力机制在自然语言处理领域被提出并广泛应用,近年来也被迁移到模式识别任务中使用,表现出良好的提升效果。
技术实现要素:
发明目的:为了克服现有技术中存在的不足,本发明提供一种基于特征-时间注意力机制的多模态情感识别方法,该发明能够提升对于音视频中人物情感识别的准确率。
技术方案:为了实现上述发明目的,本发明提供了一种基于特征-时间注意力机制的多模态情感识别方法,包括以下步骤,
步骤1:构建情感识别网络模型,获取含有情感信息的音视频样本,对样本中的视频模态数据提取人脸灰度图像并使用深度残差网络编码为固定维度的特征向量得到视频初级特征矩阵;
步骤2:对样本中的音频模态数据提取梅尔频率倒谱系数,得到音频初级特征矩阵;
步骤3:将视频初级特征矩阵和音频初级特征矩阵分别进行下采样和帧级特征融合,得到融合特征矩阵,将融合特征矩阵输入特征自注意力机制模块,学习特征中更为重要的维度并提高其权重;
步骤4:将经过特征自注意力机制模块处理的融合特征矩阵输入双向门控循环单元网络,得到所有时刻的输出向量以及最后一个隐藏层的状态向量;
步骤5:使用时间注意力模块计算最后一个隐藏层的状态向量与所有时刻的输出向量之间的注意力,得到注意力权重,根据注意力权重对每一时刻的输出向量进行加权求和,得到高级特征向量;
步骤6:将高级特征向量输入全连接分类层,输出每一情感类别的预测概率,与实际概率分布之间计算交叉熵损失,并通过反向传播训练整个网络不断更新权重,得到训练后可以对音视频样本进行情感分类的神经网络模型;
步骤7:采集待检测的音视频并将其输入训练后的神经网络模型,得到情感分类结果。
进一步的,在本发明中:所述步骤1还包括,
步骤1-1:对视频模态数据以25fps的帧率提取图像序列并进行灰度化处理;
步骤1-2:对所有提取出的灰度图像帧进行人脸检测以及人脸68点关键点定位处理;
步骤1-3:根据定位处理得到的关键点,以31号关键点鼻尖为中心,以s为边长,裁剪出人脸正方形区域,并归一化为64×64的尺寸、[0,1]的像素值范围,边长s的取值为:
其中,xright和xleft分别表示表示人脸最左侧1号关键点与最右侧17号关键点的横坐标,xcenter和ycenter分别表示中心点的横纵坐标,width和height分别表示图像帧宽与帧高,min表示取最小值;
步骤1-4:将归一化后的人脸图像序列输入所述深度残差网络,并将每一幅人脸图像编码为128维的特征向量,得到视频初级特征矩阵v;其中,所述的深度残差网络包括17个卷积层与1个全连接层,除第一个卷积层外每2个卷积层以shortcut结构组成一个残差模块,卷积层的卷积核数量随网络深度增加而不断增加。网络权重通过随机初始化得到并在训练过程中通过反向传播不断更新。
进一步的,在本发明中:所述步骤2还包括,
步骤2-1:对所述的音频模态数据以16khz的采样率进行采样并将1024个采样点集合成一个观测单位,为1帧,帧长为64ms,且相邻两帧之间包括一段重叠区域,重叠区域的长度为帧移,帧移=音频采样率/视频帧率+1=641;
步骤2-2:对每一帧信号加汉明窗,得到加窗后的帧信号为:
s′(n)=s(n)×w(n,a)
其中,s′(n)表示加窗后的帧信号,s(n)表示加窗前的帧信号,n=0,1,...,n-1,n为帧长,w(n,a)为汉明窗函数,具体为:
其中,a为预设常量;
步骤2-3:对分帧加窗后的各帧信号进行离散傅里叶变换得到各帧的频谱,并对频谱取模平方得到功率谱,频谱计算和功率谱计算式为:
其中,s(k)表示频谱,p(k)表示功率谱,k=0,1,...,n-1,n为帧长;
步骤2-4:定义梅尔尺度三角形滤波器组,得到的滤波器频率响应hm(k)为:
其中,f(m)为中心频率,m=0,1,...,m,m为滤波器个数;
步骤2-5:每一帧的功率谱p(k)与所述滤波器组中的滤波器进行频率相乘累加并取对数,得到该帧数据在该滤波器对应频段的功率值h(m),即:
步骤2-6:功率值h(m)进行离散余弦变换得到梅尔倒谱系数向量c(l),该操作具体为:
其中,l=0,1,...,l,l为梅尔倒谱系数的阶数,即音频初级特征维度,向量c(l)以0.5倍下采样得到音频初级特征矩阵a
进一步的,在本发明中:所述步骤3还包括,
步骤3-1:对得到的视频初级特征矩阵v及音频初级特征矩阵a以相同间隔进行下采样,并归一化至相同的时间长度t,对于长度不足部分的数据采取填零处理;
步骤3-2:以拼接每一时刻对应的视频初级特征与音频初级特征的方式进行特征融合,得到融合特征矩阵x;
步骤3-3:将融合特征矩阵x输入特征自注意力机制模块,得到经过自注意力机制处理的融合特征矩阵x′:
其中,dk为尺度标度,softmax为逻辑回归函数,用于将xxt归一化为概率分布,计算公式为:
其中,xi为输入矩阵的第i列,c为输入矩阵的列数。
进一步的,在本发明中:所述步骤4还包括,
步骤4-1:构建双向门控循环单元网络,包括更新门和重置门,且在t时刻的更新门和重置门输出分别为:
zt=σ(wzxt+uzst-1)
rt=σ(wtxt+utst-1)
其中,zt和rt分别表示t时刻更新门和重置门的输出,wz、uz、wt、ut均为可训练的参数矩阵,xt为t时刻的输入向量,st-1为t-1时刻隐藏层的状态向量,σ为sigmoid激活函数,能够将结果映射至[0,1]范围内,其计算公式为:
其中,隐藏层的状态向量st的更新公式为:
其中,
步骤4-2:将经过自注意力机制处理的融合特征矩阵x′输入双向门控循环单元网络,得到所有时刻的输出向量ht,t=1,2,...,t,以及最后一个隐藏层的状态向量s0,每一时刻的输出向量为当前时刻的隐藏层向量通过一个全连接层得到,其维度设置为128,由于双向门控循环单元网络是双向的,因此输出向量ht与状态向量s0的维度均为256。
进一步的,在本发明中:所述步骤5还包括,
步骤5-1:计算输出向量ht和状态向量s0之间的相关性αt,计算公式为:
αt=softmax(νttanh(wss0+whht))
其中,v、ws和wh均为可训练的参数向量或矩阵,相关性αt即为t时刻的输出向量ht在时间维度上的注意力权重;
步骤5-2:根据注意力权重αt对所有时刻的输出向量ht进行加权求和,得到高级特征向量c0:
其中,高级特征向量c0的维度为256维。
进一步的,在本发明中:所述步骤6还包括,
步骤6-1:将得到的高级特征向量c0输入全连接层得到一个维度等同于分类数量的输出向量z,使用softmax函数映射为概率分布后计算其与样本实际概率分布之间的交叉熵l,l的计算式为:
其中,ri为样本实际概率分布,zi为第个输出神经元的值,zk为第个输出神经元的值,k为分类数量;
步骤6-2:以含有情感信息的音视频数据作为训练样本、以所述的交叉熵作为损失函数进行反向传播训练整个神经网络,并采用自适应矩估计算法进行训练优化,利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率,最终得到可以预测音视频样本情感分类概率的神经网络模型。
有益效果:本发明与现有技术相比,其有益效果是:结合特征注意力机制和时间注意力机制对进行情感识别,能够提升识别结果的准确性。
附图说明
图1为本发明所述方法的整体流程示意图;
图2为本发明中人脸区域提取的示意图;
图3为本发明中用于人脸图像特征编码的深度残差网络结构图;
图4为本发明中特征注意力机制模块的示意图;
图5为本发明中时间注意力机制模块的示意图;
图6为不同网络结构在enterface'05数据集下的实验结果对比图;
图7为不同网络结构在ravdess数据集下的实验结果对比图;
图8为本发明所述方法在enterface'05数据集下的归一化混淆矩阵;
图9为本发明所述方法在ravdess数据集下的归一化混淆矩阵。
具体实施方式
下面结合附图对本发明的技术方案做进一步的详细说明:
本发明可以用许多不同的形式实现,而不应当认为限于这里所述的实施例。相反,提供这些实施例以便使本公开透彻且完整,并且将向本领域技术人员充分表达本发明的范围。
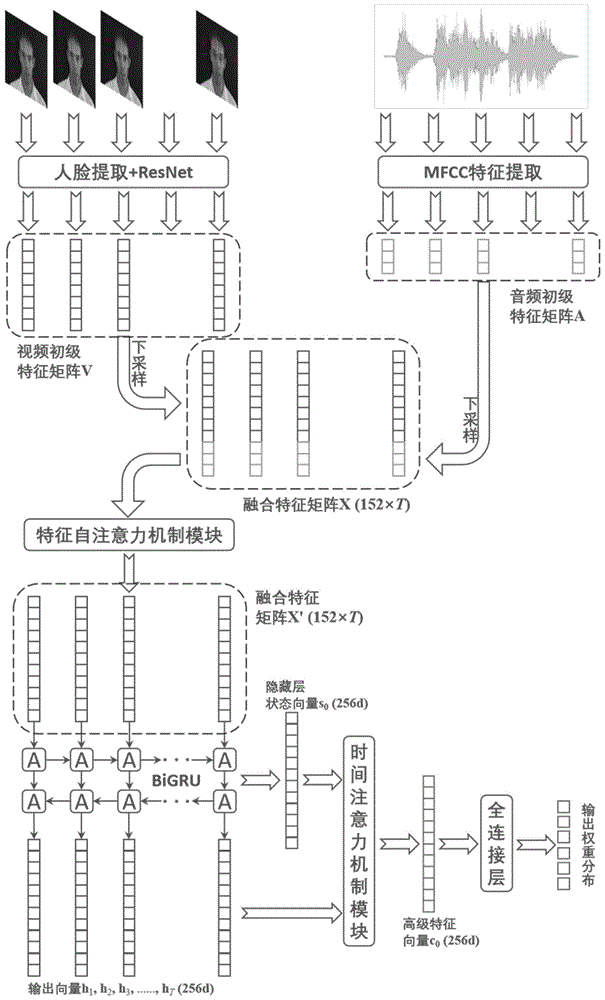
如图1所示,为本发明提出的一种基于特征-时间注意力机制的多模态情感识别方法的整体流程示意图,该方法具体包括以下步骤,
步骤1:构建情感识别网络模型,获取含有情感信息的音视频样本,对样本中的视频模态数据提取人脸灰度图像并使用深度残差网络编码为固定维度的特征向量得到视频初级特征矩阵;其中,深度残差网络,情感识别网络模型
具体的,该步骤还包括,
步骤1-1:对视频模态数据以25fps的帧率提取图像序列并进行灰度化处理;
步骤1-2:对所有提取出的灰度图像帧进行人脸检测以及人脸68点关键点定位处理;
步骤1-3:参照图2的示意,根据定位处理得到的关键点,以31号关键点鼻尖为中心,以s为边长,裁剪出人脸正方形区域,并归一化为64×64的尺寸、[0,1]的像素值范围,边长s的取值为:
其中,xright和xleft分别表示表示人脸最左侧1号关键点与最右侧17号关键点的横坐标,xcenter和ycenter分别表示中心点的横纵坐标,width和height分别表示图像帧宽与帧高,min表示取最小值;
步骤1-4:将归一化后的人脸图像序列输入深度残差网络,并将每一幅人脸图像编码为128维的特征向量,得到视频初级特征矩阵v;
其中,深度残差网络用于对图像进行特征提取的网络,是情感识别网络模型中的一部分。参照图3的示意,所述深度残差网络包括17个卷积层与1个全连接层,其中头部卷积层由64个7×7尺寸卷积核构成且步长为2,对特征图尺寸进行0.5倍下采样并将通道数升维至64维;深度残差网络还包括最大值池化层,其滑动窗口尺寸为3×3,步长为2,用于对特征图进行0.5倍下采样;除头部卷积层外每2个卷积层以shortcut结构组成一个残差模块,共计8个残差模块,且残差模块的卷积层的卷积核为3×3尺寸,各卷积层的参数一致,每个残差块中的首个卷积层步长为2其余为1,卷积层的卷积核数量随网络深度增加而不断增加,最终将特征图尺寸下采样至输入的、通道数升维至512维;一个滑动窗口尺寸等同于特征图尺寸的全局平均值池化层,将特征图尺寸下采样为1×1;全连接层用于将平化后的特征向量转换为期望的视频初级特征维度,本实施例中为128维。深度残差网络的权重通过随机初始化得到并在训练过程中通过反向传播不断更新。
步骤2:对样本中的音频模态数据提取梅尔频率倒谱系数,得到音频初级特征矩阵;
具体的,该步骤还包括,
步骤2-1:对所述的音频模态数据以16khz的采样率进行采样并将1024个采样点集合成一个观测单位,为1帧,帧长为64ms,且相邻两帧之间包括一段重叠区域,重叠区域的长度为帧移,帧移将决定由音频数据提取得到的帧数,为保证音频序列与视频序列帧数相等从而进行帧级特征融合,在本实施例中帧移=音频采样率/视频帧率+1=641;
步骤2-2:对每一帧信号加汉明窗,得到加窗后的帧信号为:
s′(n)=s(n)×w(n,a)
其中,s′(n)表示加窗后的帧信号,s(n)表示加窗前的帧信号,n=0,1,...,n-1,n为帧长,w(n,a)为汉明窗函数,具体为:
其中,a为预设常量,本实施例中a取0.46。
步骤2-3:对分帧加窗后的各帧信号进行离散傅里叶变换得到各帧的频谱,并对频谱取模平方得到功率谱,频谱计算和功率谱计算式为:
其中,s(k)表示频谱,p(k)表示功率谱,k=0,1,...,n-1,n为帧长;
步骤2-4:定义梅尔尺度三角形滤波器组,得到的滤波器频率响应hm(k)为:
其中,f(m)为滤波器m的中心频率,m=0,1,...,m,m为滤波器个数,本实施例中取22个。
步骤2-5:每一帧的功率谱p(k)与上述滤波器组中的对应滤波器进行频率相乘累加并取对数,得到该帧数据在该滤波器对应频段的功率值h(m),即:
步骤2-6:功率值h(m)进行离散余弦变换得到梅尔倒谱系数向量c(l),该操作具体为:
其中,l=0,1,...,l,l为梅尔倒谱系数的阶数,即音频初级特征维度,本实施例中取24,向量c(l)以0.5倍下采样得到音频初级特征矩阵a。
步骤3:将视频初级特征矩阵和音频初级特征矩阵分别进行下采样和帧级特征融合,得到融合特征矩阵,将融合特征矩阵输入特征自注意力模块,学习特征中更为重要的维度并提高其权重;
具体的,该步骤还包括,
步骤3-1:对得到的视频初级特征矩阵v及音频初级特征矩阵a以相同间隔进行下采样,并归一化至相同的时间长度t,对于长度不足部分的数据采取填零处理;
步骤3-2:以拼接每一时刻对应的视频初级特征与音频初级特征的方式进行特征融合,得到融合特征矩阵x;其中,融合后的特征维度为128+24=152,故x为一个行高为152、列宽为t的矩阵。
步骤3-3:将融合特征矩阵x输入特征自注意力机制模块,参照图4的示意,为特征自注意力机制模块的示意图,得到经过自注意力机制处理的融合特征矩阵x′,该过程使网络能够学习融合特征中更为重要的维度并将注意力集中,提高其权重并降低冗余维度的权重。
具体的,注意力机制可以被描述为一个查询矩阵到一系列(键-值)对矩阵的映射,其计算方式是先计算查询矩阵和各个键的相关性,得到每个键对应值的权重系数,即注意力权重,使用该权重对各值进行加权求和,最终得到经过注意力机制处理的值。对于本实施例中的特征自注意力机制模块,查询矩阵、键和值均来自同一输入,即融合特征矩阵x,经过自注意力机制处理的融合特征矩阵x′如下:
经过自注意力机制处理的融合特征矩阵x′的维度与融合特征矩阵x完全相同,其中,dk为尺度标度,即特征维度,用于防止融合特征矩阵x与自身乘积的结果过大,softmax为逻辑回归函数,用于将xxt归一化为概率分布,其计算公式为:
其中,xi为输入矩阵的第i列,c为输入矩阵的列数,softmax函数的输出即为用于与融合特征矩阵x相乘的权重矩阵,最终得到以注意力作为权重加权求和后的x′。
进一步的,在本实施例中,融合特征矩阵x首先在特征维度上被等分为四个小矩阵,每一个小矩阵分别输入特征自注意力机制模块,经注意力机制处理后再将结果合并。这种多头并行的处理策略能够使学习到的注意力鲁棒性更强,对于融合特征矩阵x中被填零的时间维度,通过预先构建一个蒙版使得特征注意力机制模块可以直接忽略这些维度。
步骤4:将经过特征自注意力机制模块处理的融合特征矩阵x′输入双向门控循环单元网络,得到所有时刻的输出向量以及最后一个隐藏层的状态向量;
具体的,该步骤还包括,
步骤4-1:构建双向门控循环单元网络,门控循环单元是循环神经网络中的一种,可以有效解决长期记忆和反向传播中的梯度爆炸问题且参数量较少,其结构包括更新门和重置门,且在t时刻的更新门和重置门输出分别为:
zt=σ(wzxt+uzst-1)
rt=σ(wtxt+utst-1)
其中,zt和rt分别表示t时刻更新门和重置门的输出,wz、uz、wt、ut均为可训练的参数矩阵,xt为t时刻的输入向量,st-1为t-1时刻隐藏层的状态向量,σ为sigmoid激活函数,能够将结果映射至[0,1]范围内,其计算公式为:
其中,隐藏层状态向量通过选择性地遗忘传递下来的某些维度信息,并加入当前节点输入的某些维度信息进行更新,隐藏层的状态向量st的更新公式为:
其中,
进一步的,本实施例中的双向门控循环单元是由两个门控循环单元上下叠加在一起组成的,在每一个时刻,输入会同时提供给这两个方向相反的门控循环单元,而输出则是由这两个单向的门控循环单元共同决定。
步骤4-2:将经过自注意力机制处理的融合特征矩阵x′输入双向门控循环单元网络,得到所有时刻的输出向量ht,t=1,2,...,t,以及最后一个隐藏层的状态向量s0,每一时刻的输出向量为当前时刻的隐藏层向量通过一个全连接层得到,本实施例中维度设置为128,由于双向门控循环单元网络是双向的,因此输出向量ht与状态向量s0的维度均为256。
步骤5:使用时间注意力模块计算最后一个隐藏层的状态向量s0与所有时刻的输出向量ht之间的注意力,得到注意力权重,根据注意力权重对每一时刻的输出向量进行加权求和,得到高级特征向量;
具体的,参照图5所示,该步骤还包括,
步骤5-1:计算输出向量ht和状态向量s0之间的相关性αt,计算公式为:
αt=softmax(νttanh(wss0+whht))
其中,v、ws和wh均为可训练的参数向量或矩阵,相关性αt即为t时刻的输出向量ht在时间维度上的注意力权重;
步骤5-2:根据注意力权重αt对所有时刻的输出向量ht进行加权求和,得到高级特征向量c0:
其中,高级特征向量c0的维度为256维。
此时高级特征向量c0已经过特征维度和时间维度的注意力机制处理,融合了多模态特征以及上下文信息,且对于重要的特征维度及时刻拥有更高的权重。
步骤6:将高级特征向量输入全连接分类层,输出每一情感类别的预测概率,与实际概率分布之间计算交叉熵损失,并通过反向传播训练整个网络不断更新权重,得到训练后可以对音视频样本进行情感分类的神经网络模型;
具体的,该步骤还包括,
步骤6-1:将得到的高级特征向量c0输入全连接层得到一个维度等同于分类数量的输出向量z,使用softmax函数映射为概率分布后计算其与样本实际概率分布之间的交叉熵l,l的计算式为:
其中,ri为样本实际概率分布,zi为第个输出神经元的值,zk为第个输出神经元的值,k为分类数量,即可识别的情感种类数,本实施例中为6类基本情绪的识别,包括愤怒、恶心、恐惧、喜悦、悲伤和惊讶,因此k=6。
步骤6-2:以已知真实标签的含有情感信息的音视频数据作为训练样本、以所述的交叉熵l作为损失函数进行反向传播训练整个神经网络,并采用自适应矩估计算法进行训练优化,利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率,最终得到可以预测音视频样本情感分类概率的神经网络模型。
其中,自适应矩估计算法的权值衰减设置为5e-5,且本实施例在训练神经网络时采取五折交叉验证,即选取训练样本中4/5的样本作为训练集、1/5的样本作为验证集,以32个样本作为一个小批次进行输入,学习率初始化为4e-3,每20个迭代周期衰减为原先的一半,共迭代100个周期。
步骤7:采集待检测的音视频并将其输入训练后的神经网络模型,得到情感分类结果。识别出的情感类别为6种基本情绪中的一个或多个。
为了验证本发明提出基于特征-时间注意力机制情感识别的有益效果,进行如下的实验:
在两大公开的主流多模态情感识别数据集enterface'05和ravdess上,分别使用基于无注意力机制、特征注意力机制、时间注意力机制和本发明的特征-时间注意力机制的网络进行情感识别,选取识别准确率和平均f1分数作为评价指标,得到的结果对比如下图6和图8所示,可以观察到本发明的特征-时间注意力机制方法在两个数据集上均取得了最好的识别效果,其中特征注意力模块和时间注意力模块均分别对结果有一定提升;同时为避免由于数据集中各类情绪样本数量不平衡导致的识别率无法完全客观地评价模型的问题,对于神经网络模型在两个数据集上的结果计算了归一化混淆矩阵,得到的结果如下图8和图9所示,其中矩阵对角线为这一类别的识别准确率,可以看出,模型在两个公开数据集的各个情感类别的识别上均取得了较高的识别准确率。
应说明的是,以上所述实施例仅表达了本发明的部分实施方式,其描述并不能理解为对本发明专利范围的限制。应当指出的是,对于本技术领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干改进,这些均应落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!