面向露头地质体岩层分层的空间随机森林算法的制作方法
1.本发明涉及地质勘探技术领域,尤其涉及一种面向露头地质体岩层分层的空间随机 森林算法。
背景技术:
2.露头地质体是地上地质结构具有代表性的研究对象之一,常常作为地质研究工作 的首要目标。岩层划分是分析露头地质体结构的基础,对岩层的准确划分有助于分析地 质体的尖灭位置、与其它地质体的叠置关系、空间展布规律等信息。
3.人工野外地质考察是岩层划分的主要方法,但地质结构的复杂性导致资料获取难 度大、时间长、效率低,资料本身连续性差、局部精度差异大;岩层划分常常依赖于研 究人员的知识与经验,不同研究人员的分层结果和其精度往往有一定差异。而且,传统 方法针对地势陡峭的岩层划分显得极为困难,甚至于不可行。虽然目前出现了一些地层 分层、岩层分层的新方法,但仍旧缺少能够得到高精度分层结果的自动化分层方法。
4.倾斜摄影测量技术是指通过多台传感器,从不同视角对同一地物进行多次影像数 据采集的测量方法。倾斜摄影测量技术能够最大化获取到地物带有空间位置信息的倾斜 影像数据,这些数据具有很高的准确性和完整性,它颠覆了传统摄影测量技术。点云数 据是倾斜摄影测量数据的衍生数据,特征提取是点云分类的前提,提取出的特征是得到 理想分类结果的关键之一。强度信息、几何信息、表面粗糙度等属性信息是分类的常用 特征;由于点云携带有坐标信息,因此基于点的空间结构和空间关系得到的空间特征也 逐渐应用于分类中,但其仍旧处于初级阶段。
5.随机森林(random forest,rf)算法能够训练样本并预测输入数据类别,即对数 据进行分类。随机森林具有良好的性能表现,且其抗干扰能力很强;理论上的随机森林 不会产生过拟合现象,且即使在现实中存在不可忽略的噪声影响,随机森林也有较强的 抗过拟合能力。随着机器学习的高速发展和对随机森林算法的深入研究,随机森林算法 也逐渐应用于地学领域,如裂缝预测、地学知识图谱的建立、地上生物量和森林冠层覆 盖度估算、不连续林地叶面积指数反演、地震属性中河道砂体识别等。随机森林算法的 核心是数据的特征,但目前这些使用随机森林算法来分类的特征主要是基于应用领域内 的专业知识而提取的属性特征,缺乏空间特征,而地学研究对象内或对象间普遍存在着 空间关系、空间场景、空间邻近等空间特征,挖掘并集成这些空间特征,进一步开展集 成空间语义计算的随机森林算法研究,来解决这些研究对象的分类问题是一个有价值且 较新的研究方向。
技术实现要素:
6.本发明提供了一种面向露头地质体岩层分层的空间随机森林算法,用以解决现有技 术存在的上述问题。方法包括:
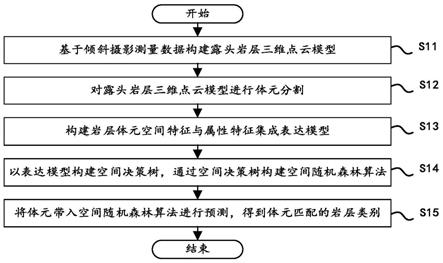
7.步骤s11,基于倾斜摄影测量数据构建露头岩层三维点云模型;
8.步骤s12,对露头岩层三维点云模型进行体元分割;
9.步骤s13,构建岩层体元空间特征与属性特征集成表达模型;
10.步骤s14,以表达模型构建空间决策树,通过空间决策树构建空间随机森林算法;
11.步骤s15,将体元带入空间随机森林算法进行预测,得到体元匹配的岩层类别。
12.优选地,所述基于倾斜摄影测量数据构建露头岩层三维点云模型包括如下步骤:
13.步骤s111,获取倾斜摄影测量数据;
14.步骤s112,设置坐标值范围,去除倾斜摄影测量数据中的无关地物数据;
15.步骤s113,通过去除无关地物数据后的倾斜摄影测量数据构建露头岩三维点云模 型。
16.优选地,对露头岩层三维点云模型进行体元分割采用八叉树构建算法,包括如下 步骤:
17.步骤s121,将露头地质体所在的三维空间作为一个体元,并设定一个长度阈值, 该长度阈值表示最小体元的边长;
18.步骤s122,将当前体元分割成八个相同的子体元,子体元具有相同的级别和大小;
19.步骤s123,依次判断当前级别体元是否包含点云数据,若不包含则忽略该体元, 则该体元不再参与计算;
20.步骤s124,将当前级别体元的边长与设定的长度阈值相比较,若大于长度阈值, 则继续分割;若小于长度阈值,则结束当前级别体元的分割;
21.步骤s125,递归地调用步骤s122~步骤s124直到所有体元都结束分割。
22.优选地,所述岩层体元空间特征与属性特征集成表达模型构建包括如下步骤:
23.基于倾斜摄影测量数据获取体元所包含点云数据的r、g、b各自的平均值,和露 头剖面在体元所在区域的表面粗糙度作为属性特征;
24.获取空间场景特征和空间度量关系特征作为空间特征。
25.优选地,所述露头剖面在体元所在区域的表面粗糙度,具体为对体元内所有点云 数据使用总体最小二乘法得到一个拟合平面,所有点云数据到拟合平面的标准差设为该 体元的粗糙程度。
26.优选地,所述空间度量关系特征以每个体元中心点的空间坐标值(x,y,z)以及 该体元所在位置的产状信息表示,产状信息的获取包括如下步骤:
27.从露头岩层表面任选不共线的三点,即确定一平面,此平面作为岩层层面,其产 状为通过所选取的三点求得该岩层层面的单位法向量法向量与产状 的关系由公式(1)表示:
[0028][0029]
式中,表示该坐标位置岩层层面的倾角,α表示该坐标位置岩层层面的倾向;体 元v表示为式(2):
[0030]
v=(id,x,y,z,r,g,b,a,e,c)
ꢀꢀꢀ
(2)
[0031]
式中,id表示体元的索引,id为其值;用x、y、z表示三维空间,x、y、z分别 为其对应的值,则(x,y,z)表示一个体元的位置;用r、g、b表示颜色空间,r、g、b 分别为其对应的值,
则(r,g,b)表示一个体元的颜色;用a表示粗糙度,a表示其对应 的值;用e表示产状,表示其对应的值;用c表示类别,c表示体元所在岩层 的类别值,当体元类别未知时,e=(
‑
1,
‑
1),表示值无意义;c=0,表示类别未知。
[0032]
优选地,统计所有样本的产状,用es表示,若共有λ组产状,则
[0033][0034]
若体元v
f
(x
f
,y
f
,z
f
)为常量,则每组产状和v
f
(x
f
,y
f
,z
f
)确定其对应的唯一法向 量,则es对应一组法向量值
[0035]
设每个体元都有与es相对应的一组垂直距离值h=(h1,h2,k,h
λ
),则对于样本,由 于其有确定的产状,则h中只有一个分量有意义;对于待分类体元,由于其产状未知, 则h中每个分量都有意义;
[0036]
待分类体元vw和所有样本vs,待分类体元vw的空间度量关系特征值的求取方 法为:
[0037]
步骤s131,对于体元vw的垂直距离值h
vw
的每一个分量1≤p≤λ,有对应有意义的若干个样本,依次计算并将差值按正负分别统计,和 至少有1个成立;
[0038]
步骤s132,若有且仅有成立,则体元vw在产状为e
p
的岩层的下方, vw在其法向量的垂直正方向上有一个最近的样本,记vw与该样本的垂直距离为 +δh;
[0039]
步骤s133,若有且仅有成立,则体元vw在产状为e
p
的岩层的上方, vw在其法向量的垂直负方向上有一个最近的样本,记vw与该样本的垂直距离为
ꢀ‑
δh;
[0040]
步骤s134,若和都成立,则体元vw在产状为e
p
的岩层的 中间,vw在其法向量的垂直正方向和负方向上分别有一个最近的样本,分别记vw 与这两个样本的垂直距离为+δh和
‑
δh;
[0041]
步骤s135,根据步骤s134~步骤s134,在vw垂直正方向和垂直负方向上分别获 得至多λ组(+δh,c)和(
‑
δh,c),将这λ组值记作类别集cs,则至多包含(2
×
λ)个类别c, 则vw所属类别在类别集cs中;
[0042]
步骤s136,设置阈值ω,ω须大于地质体最大岩层真厚度,则满足条件|
±
δh|>ω 的+δh或
‑
δh对应的类别不为vw所属的类别,从类别集cs中删除对应的组;
[0043]
步骤s137,对于所有+δh和
‑
δh,分别有最小绝对值|+δh|
min
和|
‑
δh|
min
,体元vw 到最小绝对值对应类别的所有样本分别有最小水平距离和体元vw到类 别集cs中其它类别的所有样本也分别有最小水平距离,将这些最小水平距离与和 比较,只要大于和就从类别集cs中删除对应的组;
[0044]
步骤s138,使类别集cs中只留下类别值,并对其进行去重,最后得到的类别集cs 包含vw所属类别;
[0045]
用m表示空间度量关系特征,m表示其值,则待分类体元的空间度量关系特征值 m
=cs;当共λ组产状,γ个类别时,待分类体元的空间度量关系特征值m至少有1个 分量,至多有λ(λ≤γ)个分量或γ(γ<λ)个分量,当分量个数为1时,该分量的 值即为该体元类别;对于样本,其类别为c
k
,则其空间度量关系特征值m=c
k
,k= 1,2,
…
,γ;
[0046]
则,对于任意一个体元v,都有表达式(3):
[0047]
v=(id,x,y,z,r,g,b,a,e,m,c)
ꢀꢀꢀ
(3)
[0048]
当体元v在特征m的值m只有一个分量时,其类别值c=m;当值m有多个分量 时,其类别值c∈m。
[0049]
优选地,所述空间场景特征采用fpfh表示,fpfh计算过程包括如下步骤:
[0050]
步骤s231,对点云模型中的任意一个点p求取其切平面的法向量;
[0051]
步骤s232,找到距离点p最近的k个点,这k个点称为点p的k邻近集;
[0052]
步骤s233,对于点p与其k邻近集点中的点p
δ
(1≤δ≤k),选取二者中一点为坐 标系原点o,另一点作为目标点q;为确保坐标系的唯一性,原点法向量与两点连线的 夹角应当最小,即需满足式(4):
[0053][0054]
其中,表示原点位置切平面法向量,为目标点位置切平面法向量,表示 从原点指向目标点的向量,表示从目标点指向原点的向量;
[0055]
步骤s234,根据原点o得到其坐标系(κ,ρ,ι)的表达式(5):
[0056][0057]
步骤s235,平移原点o的坐标系(κ,ρ,ι)到目标点q,点o与点q的空间关系用 一组角度相关的值来表示,见公式(6):
[0058][0059]
其中,θ为目标点q的法向量与坐标轴ρ之间的夹角,表示原点o的法向量 与原点o和目标点q的连线的夹角,β表示目标点q的法向量在坐标轴平面 ιqκ上的投影与坐标轴κ之间的夹角,则求出θ、和β,见公式(7):
[0060]
[0061]
其中,表示坐标轴ι的单位向量与目标点q处切平面的法向量的内积,表 示坐标轴κ的单位向量与目标点q处切平面的法向量的内积;则点p与其邻域k个 点的空间关系由三元组表示,且与的取值范围为[
‑
1,1],的取值范 围为[0,2π];
[0062]
步骤s236,对点p与其k邻近集中每个点都进行s233~s235的运算,得到k个三 元组将和进行τ等分,对于则将[
‑
1,1]等分为τ个区间, 统计每个区间中有多少个值,某个区间的频率为该区间值的个数与k的比值; 用同样的方法统计和的区间频率;
[0063]
步骤s237,点p在和总共有(3
×
τ)个区间,对其从1开始依次进行编 号,这个编号则为点p的空间结构子空间序号,则得到频率分布折线图和直方图;这个 频率分布直方图就是点p周围的空间结构;点云间的相似则表现为每个子空间相似,也 即是需要比较每个子空间序号的频率,在频率分布折线图上表现为图形的整体相似和峰 值的相似;这(3
×
τ)个频率值组成的(3
×
τ)元组被称为点p的简单点特征直方图(simple point feature histograms,spfh);
[0064]
步骤s238,对体元中每个点都进行步骤s231~步骤s237,则体元内的每个点都得 到一个spfh;对于任意一个体元v,通过公式(8)得到其快速点特征直方图fpfh:
[0065][0066]
其中,p为体元的中心点,η为体元内除中心点的点的数量,p
δ
为体元内除中心点 外的一点,δ=1,2,
…
,η,ω
η
为点p
δ
到中心点p的距离;式中spfh的相加是指对应的 子空间的频率相加;
[0067]
每个体元根据上述步骤都得到一个自己的fpfh频率分布图,每个fpfh共有τ个 区间,用s=(s1,s2,k,s
τ
)表示其纵值,则分量序号与直方图横轴序号一一对应;则体元fpfh的纵值s=(s1,s2,k,s
τ
)表征了体元的空间场景;用s表示空间场景特征,则 s=(s1,s2,k,s
τ
)为特征值,该特征和特征值都满足决策树和随机森林的特征性质;因此, 对于任意一个体元v,都有表达式(9):
[0068]
v=(id,x,y,z,r,g,b,a,e,m,s,c)
ꢀꢀꢀ
(9)
[0069]
其中,各标识的含义与公式(2)相同,s=s。
[0070]
优选地,每一个体元为随机森林的输入数据,体元的属性特征和空间特征为输入 特征,如式(10)所示:
[0071]
v=(r,g,b,a,m,s)
ꢀꢀꢀ
(10)
[0072]
定义以空间度量关系特征为根结点构建的决策树为空间决策树,对于训练样本集 vts、空间度量关系特征m和所有数据在空间度量关系特征m的取值m、其它特征组 成的特征集fs,建立空间决策树st的算法为:
[0073]
步骤s141,输入训练样本集vts、所有体元在空间度量关系特征m的取值m、空 间度量关系特征m和特征集fs;
[0074]
步骤s142,构建根结点,将训练样本集放在根结点;
[0075]
步骤s143,判断训练样本集vts是否为同一类,若为同一类,则类别值为根结点 值,根结点也为叶结点,返回决策树;
[0076]
步骤s144,若不为同一类,则设置空间度量关系特征m为根结点值,将所有数据 在空间度量关系特征m的取值m放在根结点;
[0077]
步骤s145,根据所有取值m建立根结点的分支,每一个取值对应一个分支;
[0078]
步骤s146,若第i个取值m
i
中只有一个分量,则建立该分支对应的子结点,该结 点为叶结点,结点值为分量值;
[0079]
步骤s147,若第i个取值m
i
中有多个分量,则找到训练样本集vts中类别值属于 m
i
的分量的所有样本,这些样本即为m
i
分支对应的子训练样本集,以子训练样本集和 特征集fs为输入样本和特征,按照前述的步骤构建m
i
分支对应的子决策树;
[0080]
步骤s148,对m的所有分支按步骤s146~步骤s147建立叶结点或子决策树后, 返回决策树。
[0081]
优选地,所述将体元带入空间随机森林算法进行预测,得到体元匹配的岩层类别 具体为:对随机森林中的每棵决策树,递归地根据决策树的结点找到体元对应的特征值, 根据该特征值进入决策树中该结点对应的分支,最终得到体元的类别;统计随机森林中 所有决策树对体元的分类结果,数量最多的类别即是随机森林对体元预测的类别。
[0082]
本发明的有益效果为:
[0083]
倾斜摄影测量数据中提取三维点云数据并构建体元模型,以地理信息科学为理论基 础,结合地质体岩层特性从点云数据中提取其属性特征和空间特征,基于经典随机森林 算法提出了空间随机森林算法,并将之应用于露头地质体岩层类别识别,以实现对露头 地质体的自动化岩层分层,为露头地质体的进一步研究奠定基础。
[0084]
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而 可依照说明书的内容予以实施,并且为了让本发明的上述和其他目的、特征和优点能够 更明显易懂,以下特举本发明的具体实施方式。
附图说明
[0085]
通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领域普通技 术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本发明 的限制。而且在整个附图中,用相同的参考符号表示相同的部件。在附图中:
[0086]
图1为本发明实施例提供的面向露头地质体岩层分层的空间随机森林算法的流程 图;
[0087]
图2为本发明实施例提供的研究区露头地质体位置图;
[0088]
图3为本发明实施例提供的点云模型去除无关地物前的图像;
[0089]
图4为本发明实施例提供的点云模型去除无关地物后的图像;
[0090]
图5为本发明实施例提供的八叉树算法示意图;
[0091]
图6为本发明实施例提供的地质体的产状及其与法向量的关系示意图;
[0092]
图7为本发明实施例提供的体元间垂直距离的转换示意图;
[0093]
图8为本发明实施例提供的空间度量关系特征在决策树中的应用示意图;
[0094]
图9为本发明实施例提供的点p与其k邻近集的示意图;
[0095]
图10为本发明实施例提供的原点与目标点的空间关系的示意图;
[0096]
图11为本发明实施例提供的点p与其k邻近集在的三分区、频率分布折线图和 频率分布直方图;
[0097]
图12为本发明实施例提供的特征s在空间随机森林中的应用方式;
[0098]
图13为本发明实施例提供的体元模型局部示意图;
[0099]
图14为本发明实施例提供的露头模型样本选择示意图;
[0100]
图15为本发明实施例提供的基于属性特征的经典随机森林岩层分层结果图;
[0101]
图16为本发明实施例提供的基于空间场景替代特征的经典随机森林岩层分层结果 图;
[0102]
图17为本发明实施例提供的基于属性特征和空间场景替代特征的经典随机森林岩 层分层结果图;
[0103]
图18为本发明实施例提供的基于属性特征和空间度量关系替代特征的经典随机森 林岩层分层结果图;
[0104]
图19为本发明实施例提供的基于属性特征、空间度量关系替代特征和空间场景替 代特征的经典随机森林岩层分层结果图;
[0105]
图20为本发明实施例提供的基于属性特征、空间度量关系特征和空间场景特征的 空间随机树种森林岩层分层结果图(保守预测);
[0106]
图21为本发明实施例提供的基于属性特征、空间度量关系特征和空间场景特征的 空间随机树种森林岩层分层结果图(激进预测);
[0107]
图22为本发明实施例提供的基于属性特征、空间度量关系特征和空间场景替代特 征的完全空间随机森林岩层分层结果图(保守预测);
[0108]
图23为本发明实施例提供的基于属性特征、空间度量关系特征和空间场景替代特 征的完全空间随机森林岩层分层结果图(激进预测);
[0109]
图24为本发明实施例提供的基于属性特征、空间度量关系特征和空间场景特征的 完全空间随机森林岩层分层结果图(保守预测);
[0110]
图25为本发明实施例提供的基于属性特征、空间度量关系特征和空间场景特征的 完全空间随机森林岩层分层结果图(激进预测);
[0111]
图26为本发明实施例提供的通过空间随机森林算法得到的露头地质体岩层分界线 与实际岩层分界线对比图。
具体实施方式
[0112]
下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的 示例性实施例,然而应当理解,以各种形式实现本公开而不应被这里阐述的实施例所限 制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围 完整的传达给本领域的技术人员。
[0113]
因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的 本发明的范围,而是仅仅表示本发明的选定实施例。基于本发明中的实施例,本领域普 通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护 的范围。
[0114]
应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一 个附图中被定义,则在随后的附图中不需要对其进行进一步定义和解释。
[0115]
请参阅图1,为本发明实施提供的一种面向露头地质体岩层分层的空间随机森林算 法的流程图。本实施例中,所述面向露头地质体岩层分层的空间随机森林算法包括如下 步骤:
[0116]
步骤s11,基于倾斜摄影测量数据构建露头岩层三维点云模型;
[0117]
步骤s12,对露头岩层三维点云模型进行体元分割;
[0118]
步骤s13,构建岩层体元空间特征与属性特征集成表达模型;
[0119]
步骤s14,以表达模型构建空间决策树,通过空间决策树构建空间随机森林算法;
[0120]
步骤s15,将体元带入空间随机森林算法进行预测,得到体元匹配的岩层类别。
[0121]
优选地,所述基于倾斜摄影测量数据构建露头岩三维点云模型包括如下步骤:
[0122]
步骤s111,获取倾斜摄影测量数据;
[0123]
如图2所示;露头剖面所在的地质体为研究对象,该区域地层主要为上古生界二 叠系中统下石盒子组,露头地质体没有植被覆盖,岩层露头良好,可观察到大套的含砾 中粗砂岩、含砾粗砂岩、粉砂岩、泥质粉砂岩,间夹薄层的细砂岩、泥岩。千里山剖面 所在地质体顶、底高程差约45m,剖面宽度约430m,地层走向为北西
‑
南东,各岩层相 互平行,平均倾向为62
°
,平均倾角为33
°
。研究该露头地质体的岩层分层有助于研 究该区域地层展布情况,为该区域的露头地质体精细研究、储层地质知识库建立等提供 基本资料。
[0124]
使用搭载一台相机传感器的dji phantom 4pro无人机对研究区域进行倾斜摄影测 量数据获取,航高60米,飞行5架次,相机倾角20
°
,影像航向重叠率80%、旁向重叠 率70%,最终获得的影像分辨率为1.90厘米,共获得746张影像。
[0125]
通过contextcapture center(smart3d)软件,将影像数据生成高密度三维点云数据, 即,点云模型。每个点都含有三维坐标值和颜色信息。
[0126]
步骤s112,设置坐标值范围,去除倾斜摄影测量数据中的无关地物数据;
[0127]
在当前点云模型中,除了要研究的露头地质体外,还存在部分无关地物:道路和房 屋。由于这些无关地物在露头地质体周围,且距离露头地质体有明显距离,因此直接设 置坐标值范围进行去除。去除无关地物前后的点云模型如图3和图4所示。
[0128]
步骤s113,通过去除地物数据后的倾斜摄影测量数据构建露头岩层三维点云模型。
[0129]
优选地,为了建立空间索引系统并简化点云数据,又不失去太多信息,本发明实施 例采用八叉树方法将露头地质体所在的三维空间分成细小的单元,这些单元称之为体 元。对露头岩层三维点云模型进行体元分割采用八叉树构建算法,包括如下步骤:
[0130]
步骤s121,将露头地质体所在的三维空间作为一个体元,并设定一个长度阈值, 该长度阈值表示最小体元的边长;
[0131]
步骤s122,将当前体元分割成八个相同的子体元,子体元具有相同的级别和大小;
[0132]
步骤s123,依次判断当前级别体元是否包含点云数据,若不包含则忽略该体元, 则该体元不再参与计算;
[0133]
步骤s124,将当前级别体元的边长与设定的长度阈值相比较,若大于长度阈值, 则继续分割;若小于长度阈值,则结束当前级别体元的分割;
[0134]
步骤s125,递归地调用步骤s122~步骤s124直到所有体元都结束分割。八叉树分 割如图5所示。
[0135]
优选地,所述岩层体元空间特征与属性特征集成表达模型构建包括如下步骤:
[0136]
基于倾斜摄影测量数据获取体元所包含点云数据的r、g、b各自的平均值,和露 头剖面在体元所在区域的表面粗糙度作为属性特征;
[0137]
获取空间场景特征和空间度量关系特征作为空间特征。
[0138]
优选地,所述露头剖面在体元所在区域的表面粗糙度,具体为对体元内所有点云 数据使用总体最小二乘法得到一个拟合平面,所有点云数据到拟合平面的标准差设为该 体元的粗糙程度。
[0139]
对于每一个体元,其内部都包含至少一个点。取体元内中心点(体元内所有点的中 心点)的坐标为体元的坐标;体元内所有点rgb颜色值的均值为体元的颜色值。对体 元内所有点使用总体最小二乘法得到一个拟合平面,这些点到拟合平面的标准差即为该 体元的粗糙度,表示这个体元对应的局部剖面的粗糙程度。
[0140]
优选地,所述空间度量关系特征以每个体元中心点的空间坐标值(x,y,z)以及 该体元所在位置的产状信息表示,产状信息的获取包括如下步骤:
[0141]
从露头岩层表面任选不共线的三点,即确定一平面,此平面作为岩层层面,其产 状为通过所选取的三点求得该岩层层面的单位法向量法向量与产状 的关系由公式(1)表示:
[0142][0143]
式中,表示该坐标位置岩层层面的倾角,α表示该坐标位置岩层层面的倾向;体 元v表示为式(2):
[0144]
v=(id,x,y,z,r,g,b,a,e,c)
ꢀꢀꢀ
(2)
[0145]
式中,id表示体元的索引,id为其值;用x、y、z表示三维空间,x、y、z分别 为其对应的值,则(x,y,z)表示一个体元的位置;用r、g、b表示颜色空间,r、g、b 分别为其对应的值,则(r,g,b)表示一个体元的颜色;用a表示粗糙度,a表示其对应 的值;用e表示产状,表示其对应的值;用c表示类别,c表示体元所在岩层 的类别值,当体元类别未知时,e=(
‑
1,
‑
1),表示值无意义;c=0,表示类别未知。
[0146]
在地质学中,岩层在空间中的产出状态用岩层产状来表示,岩层产状包含走向、 倾向和倾角,但一般用倾向α(0
°
≤α≤360
°
)和倾角来表示产状。对于已 知类别的体元(即样本),可以获取其产状:一种方法是在野外踏勘时测量体元所在岩 层层面的产状;另一种方法是根据样本与同一岩层面上其它体元构成的平面求得:根据 这多个体元的坐标可以求得所构成的平面的法向量,法向量和产状的关系如图6所示, 图中,面obec为岩层层面,其产状为向量为岩层层面的法向量,用表示;y轴为正北方向,平面xoy为水平面,平面yoz为垂直面,假设面obec过原 点o(0,0,0),则oa为岩层层面的单位法向量其长度为1,oa与垂直面的夹 角即为倾角oa在水平方向的投影
of与正北方向的夹角即为倾向α。根据该图可以 得到公式(1),则可求得该体元对应的产状。而对于未知类别的体元,由于其类别未知, 即其所在岩层未知,因此其产状未知,用(
‑
1,
‑
1)表示,表征为其值无意义。
[0147]
如此,在下文中,每个体元都为参与随机森林算法的一个数据,在三维空间中表现 为一个点。
[0148]
岩层分层是一个典型的分类问题,根据已知类别体元的特征进行归纳学习并建立规 则,然后根据该规则预测每个未知体元的类别,最后将同一类别的体元归为一个整体, 即是一个岩层。
[0149]
式(2)表达了体元的所有属性,对于随机森林的输入特征:id为体元的索引,每 个体元有独特的值;根据八叉树算法可知,每个体元具有独特的坐标值;由于rgb颜 色空间对不同颜色的物体具有区分性,同一岩层的体元有相似的值,不同岩层的体元有 不同的值;由于风化剥蚀等地质作用,同一岩层的体元对应的剖面有近似的粗糙程度, 不同岩层的体元对应的剖面有不同的粗糙程度。因此,红光波段r、绿光波段g、蓝光 波段b、表面粗糙度a可以作为经典随机森林算法的输入特征,将它们统称为体元的属 性特征。
[0150]
体元为空间数据,因此,可以根据体元内和体元间的空间结构和空间关系挖掘并提 取其空间特征。
[0151]
根据地理学第一定律,对体元类别预测时,可以认为:两个体元间的距离越近,其 类别越可能相同。
[0152]
岩层在空间中的产出状态用产状来表示,根据图6和公式(1)可知,当岩层产状 确定,岩层层面的法向量则确定。因此,过地质体上任意一点的岩层层面有且仅有一个, 其由所在岩层的产状和该点坐标共同确定;地质体上两点之间的空间度量关系与两点所 在岩层层面有关。
[0153]
将岩层层面所在平面的法向量方向称为该岩层层面上的体元的垂直方向,其中指向 +z方向的单位法向量的方向为正方向;将平面的延展方向称为在该岩层层面上的体元 的水平方向,平面沿+y方向的延展方向为正方向。则地质体中体元的垂直方向和水平 方向的数量与地质体的岩层产状数量相同。
[0154]
定义地质体上一点v到另一点v0的空间度量关系为:点v到过v0的岩层层面所在 平面的距离,以及v在该平面上的投影点v
′
与v0的直线距离所构成的二元组。因此可 知:对于v和v0,若其所在岩层产状相同,v到v0的空间度量关系与v0到v的空间度 量关系值相同;否则则不同。
[0155]
地理学第一定律中的“远近”在地质体的体元上既表现为垂直方向上的远近,又表 现为水平方向上的远近。可以理解为:在地质体上,体元v到v0的垂直距离越小,越 可能在同一岩层上;体元v到v0的水平距离越小,越可能在同一岩层上。不过,由于 岩层具有层叠特性,虽然在岩层分界线周围的体元的垂直距离非常小,但也可能不属于 同一岩层;由于岩层具有延展特性,虽然可能在同一岩层层面的体元间的水平距离非常 大,但仍旧属于同一岩层。因此,对于一个待分类体元,在地质体的每个垂直正方向、 垂直负方向、水平方向上都有距离最小的样本,该待分类体元的类别必然在这些最小距 离样本的类别中,且优先考虑垂直方向上最近的样本。
[0156]
随机森林算法的样本和待分类体元需具有相同特征,且体元与体元之间、特征的
值 与值之间必须性质相同且相互独立。空间度量关系虽然可以作为判断体元类别的一个特 征,但空间度量关系是根据两个体元而获得的,因此必须对空间度量关系进行转化才能 将之作为随机森林算法的特征。将一个待分类体元与所有样本进行比较,找到其垂直正 方向、垂直负方向和水平方向上距离最小的样本,这些样本的类别组成的类别集作为该 待分类体元的特征值;对于样本,其类别值即为特征值;这些特征值满足条件,且该特 征与其他特征相互独立,可以作为随机森林算法的特征,将这个特征称为空间度量关系 特征。
[0157]
为了便于计算,将两个体元间的垂直距离转换为两个体元分别与第三个体元的垂直 距离的差,如图7所示。在图7(1)中,在地质体上有体元v和v0,过v0的岩层层面 所在的平面为sp,v在sp上的投影为v
′
,v到sp的距离为h,v
′
到v0的距离为d; (2)中,v
f
(x
f
,y
f
,z
f
)是三维空间中地质体包围盒(以地质体中x、y、z坐标的最大绝 对值为坐标值构成的长方体)外沿
‑
z方向的任意一点(体元v
f
中心点),平面ψ是平 面sp沿
‑
z方向平移、过点v
f
(x
f
,y
f
,z
f
)的平面,则平面ψ与平面sp法向量相同,且与 地质体相离,v和v0在平面ψ上的投影分别为v
″
和v
″0,v和v0到平面ψ的距离分别 为h和h0。
[0158]
优选地,统计所有样本的产状,用es表示,若共有λ组产状,则
[0159][0160]
若体元v
f
(x
f
,y
f
,z
f
)为常量,则每组产状和v
f
(x
f
,y
f
,z
f
)确定其对应的唯一法向 量,则es对应一组法向量值
[0161]
设每个体元都有与es相对应的一组垂直距离值h=(h1,h2,k,h
λ
),则对于样本,由 于其有确定的产状,则h中只有一个分量有意义;对于待分类体元,由于其产状未知, 则h中每个分量都有意义;
[0162]
因此,统计所有样本的产状,用es表示,若共有λ组产状,则 这可以认为是露头地质体的所有产 状。若图7中体元v
f
(x
f
,y
f
,z
f
)为常量,则每组产状和v
f
(x
f
,y
f
,z
f
)可以确定其对应的 唯一法向量,则es对应一组法向量值
[0163]
设每个体元都有与es相对应的一组垂直距离值h=(h1,h2,k,h
λ
),则对于样本,由 于其有确定的产状,则h中只有一个分量有意义;对于待分类体元,由于其产状未知, 则h中每个分量都有意义。
[0164]
待分类体元vw和所有样本vs,待分类体元vw的空间度量关系特征值的求取方 法为:
[0165]
步骤s131,对于体元vw的垂直距离值h
vw
的每一个分量1≤p≤λ,有对应有意义的若干个样本,依次计算并将差值按正负分别统计,和 至少有1个成立;
[0166]
步骤s132,若有且仅有成立,则体元vw在产状为e
p
的岩层的下方, vw在其法向量的垂直正方向上有一个最近的样本,记vw与该样本的垂直距离为 +δh,vw在e
p
方向上最可能与该样本类别相同;
[0167]
步骤s133,若有且仅有成立,则体元vw在产状为e
p
的岩层的上方, vw在其法向量的垂直负方向上有一个最近的样本,记vw与该样本的垂直距离为
ꢀ‑
δh,vw在e
p
方向上最可能与该样本类别相同;
[0168]
步骤s134,若和都成立,则体元vw在产状为e
p
的岩层的 中间,vw在其法向量的垂直正方向和负方向上分别有一个最近的样本,分别记vw 与这两个样本的垂直距离为+δh和
‑
δh,vw在e
p
方向上最可能与这两个样本的类别相 同;
[0169]
步骤s135,根据步骤s134~步骤s134,在vw垂直正方向和垂直负方向上分别获 得至多λ组(+δh,c)和(
‑
δh,c),将这λ组值记作类别集cs,则至多包含(2
×
λ)个类别c, cs中可能有重复类别,可以知道,vw所属类别一定在类别集cs中;
[0170]
步骤s136,设置阈值ω,ω须大于地质体最大岩层真厚度,则满足条件|
±
δh|>ω 的+δh或
‑
δh对应的类别不为vw所属的类别,从类别集cs中删除对应的组;
[0171]
步骤s137,对于所有+δh和
‑
δh,分别有最小绝对值|+δh|
min
和|
‑
δh|
min
,体元vw 到最小绝对值对应类别的所有样本分别有最小水平距离和体元vw到类 别集cs中其它类别的所有样本也分别有最小水平距离,将这些最小水平距离与和 比较,只要大于和就从类别集cs中删除对应的组;
[0172]
步骤s138,使类别集cs中只留下类别值,并对其进行去重,最后得到的类别集cs 包含vw所属类别。
[0173]
用m表示空间度量关系特征,m表示其值,则待分类体元的空间度量关系特征值 m=cs;当共λ组产状,γ个类别时,待分类体元的空间度量关系特征值m至少有1个 分量,至多有λ(λ≤γ)个分量或γ(γ<λ)个分量,当分量个数为1时,该分量的 值即为该体元类别;对于样本,其类别为c
k
,则其空间度量关系特征值m=c
k
,k= 1,2,
…
,γ;则,对于任意一个体元v,都有表达式(3):
[0174]
v=(id,x,y,z,r,g,b,a,e,m,c)
ꢀꢀꢀ
(3)
[0175]
其中,各标识的含义与公式(2)相同。当体元v在特征m的值m只有一个分量时,其 类别值c=m;当值m有多个分量时,其类别值c∈m。
[0176]
使类别集cs中只留下类别值,并对其进行去重,最后得到的类别集cs一定包含vw 所属类别。
[0177]
根据空间度量关系特征值的特征可知,空间度量关系特征不能直接用于经典决策树 算法和经典随机森林算法。在决策树和随机森林中,建立决策树的目的是判断待分类数 据的类别;特征的本质作用为对样本集划分子集,使子集中的样本尽可能属于同一类别; 对待分类数据的预测,则是根据数据的特征值与决策树进行比对,直到得到待分类数据 的类别。空间度量关系特征直接表达了数据的类别或类别的范围,因此虽然样本在空间 度量关系特征的取值不完全包含待分类体元在空间度量关系特征的取值,但待分类体元 在空间度量关系特征的取值已经直接对样本集划分了子集。也即是:所有待分类体元在 空间度量关系特征的取值即是样本子集中包含的类别,有多少个取值则有多少个样本子 集;对于任一取值,所有样本中类别在其分量中的样本都被划分到该取值对应的样本子 集中,则一个样本可能存在于多个样本子集中,如图8所示。且空间度量关系特征值一 定包含了体元
的类别,因此空间度量关系特征应该作为决策树的根结点。
[0178]
对于露头地质体,同一岩层的岩体性质相同,其所在环境相同,风化剥蚀程度基本 一致;不同岩层的岩体性质不同,虽然所在环境相同,但风化剥蚀程度具有差异性。因 此,对于由点云构成的体元,相同岩层的体元具有相似的空间结构和空间关系;不同岩 层的体元具有不同的空间结构和空间关系。
[0179]
快速点特征直方图(fast point feature histograms,fpfh)是一种基于点的表面法 线和曲率的姿态不变的空间局部特征,它考虑估计法线之间的相互作用,通过统计的方 法获得点与邻域点的空间几何关系,并形成一个多维直方图。
[0180]
优选地,所述空间场景特征采用fpfh表示,fpfh计算过程包括如下步骤。
[0181]
步骤s231,对点云模型中的任意一个点p求取其切平面的法向量。
[0182]
步骤s232,找到距离点p最近的k个点,这k个点称为点p的k邻近集,将点p 与其k邻近集中的点两两连线,如图9所示;点p与其k邻近集(如k=5,(1)为点 p的5邻近,(2)为点p和p1的5邻近,p到p1的箭头表示p1是p的5邻近,但p 不是p1的5邻近)。
[0183]
步骤s233,对于点p与其k邻近集点中的点p
δ
(1≤δ≤k),选取二者中一点为坐 标系原点o,另一点作为目标点q;为确保坐标系的唯一性,原点法向量与两点连线的 夹角应当最小,即需满足式(4):
[0184][0185]
其中,表示原点位置切平面法向量,为目标点位置切平面法向量,表示 从原点指向目标点的向量,表示从目标点指向原点的向量。
[0186]
步骤s234,根据原点o得到其坐标系(κ,ρ,ι)的表达式(5):
[0187][0188]
步骤s235,平移原点o的坐标系(κ,ρ,ι)到目标点q,则有图10(原点与目标点 的空间关系);点o与点q的空间关系可以用一组角度相关的值来表示,见公式 (6):
[0189][0190]
其中,θ为目标点q的法向量与坐标轴ρ之间的夹角,表示原点o的法向量与 原点o和目标点q的连线的夹角,β表示目标点q的法向量在坐标轴平面ιqκ上的 投影与坐标轴κ之间的夹角,则可求出θ、和β,见公式(7):
[0191][0192]
其中,表示坐标轴ι的单位向量与目标点q处切平面的法向量的内积,表 示坐标轴κ的单位向量与目标点q处切平面的法向量的内积;则点p与其邻域k个 点的空间关系可由三元组表示,且与的取值范围为[
‑
1,1],的取值 范围为[0,2π]。
[0193]
步骤s236,对点p与其k邻近集中每个点都进行步骤(3)~(5)的运算,可以得 到k个三元组将和进行τ等分,对于则将[
‑
1,1]等分为τ个 区间,统计每个区间中有多少个值,某个区间的频率为该区间值的个数与k的 比值,如图11(点p与其k邻近集在的三分区、频率分布折线图和频率分布直方图 (k=20)),用同样的方法统计和的区间频率。
[0194]
步骤s237,点p在和总共有(3
×
τ)个区间,对其从1开始依次进行编号, 这个编号则为点p的空间结构子空间序号,则可以得到类似于图11(2)、9(3)所示 的频率分布折线图和直方图;这个频率分布直方图就是点p周围的空间结构;点云间的 相似则表现为每个子空间相似,也即是需要比较每个子空间序号的频率,在频率分布折 线图上表现为图形的整体相似和峰值的相似;这(3
×
τ)个频率值组成的(3
×
τ)元组被称 为点p的简单点特征直方图(simple point feature histograms,spfh)。
[0195]
步骤s238,对体元中每个点都进行步骤s231~步骤s237,则体元内的每个点都可 以得到一个spfh;对于任意一个体元v,通过公式(8)可以得到其快速点特征直方图 fpfh:
[0196][0197]
其中,p为体元的中心点,η为体元内除中心点的点的数量,p
δ
为体元内除中心点外的 一点,δ=1,2,
…
,η,ω
η
为点p
δ
到中心点p的距离;式中spfh的相加是指对应的子空 间的频率相加。
[0198]
每个体元根据上述步骤都可以得到一个自己的fpfh频率分布图,每个fpfh共有τ 个区间,用s=(s1,s2,k,s
τ
)表示其纵值,则分量序号与直方图横轴序号一一对应。地理 信息科学中,空间场景是体的一种内部结构表现,地质体点云的空间场景表现为体元中 不同点与其邻域的相对位置关系,则体元fpfh的纵值s=(s1,s2,k,s
τ
)表征了体元的空 间场景。用s表示空间场景特征,则s=(s1,s2,k,s
τ
)为特征值,该特征和特征值都满足 决策树和随机森林的特征性质。因此,对于任意一个体元v,都有表达式(9):
[0199]
v=(id,x,y,z,r,g,b,a,e,m,s,c)
ꢀꢀꢀ
(9)
[0200]
其中,各标识的含义与公式(2)相同,s=s。
[0201]
对于体元的空间场景特征而言,对体元进行比较,可以对体元空间场景特征中的部 分依次进行比较,因此可以使用信息增益比准则来依次选择最优分量。虽然空间场景特 征有多个分量,但它是一个特征,因此在决策树和随机森林中对应一个结点,当与其它 特征一起构建决策树和随机森林时,使用信息增益比准则的定义来选择最优特征。空间 场景特征在决策树和随机森林中的构建方式如图12所示。
[0202]
优选地,每一个体元为随机森林的输入数据,体元的属性特征和空间特征为输入 特征,如式(10)所示:
[0203]
v=(r,g,b,a,m,s)
ꢀꢀꢀ
(10)
[0204]
定义以空间度量关系特征为根结点构建的决策树为空间决策树,对于训练样本集 vts、空间度量关系特征m和所有数据在空间度量关系特征m的取值m、其它特征组 成的特征集fs,建立空间决策树st的算法为:
[0205]
步骤s141,输入训练样本集vts、所有体元在空间度量关系特征m的取值m、空 间度量关系特征m和特征集fs;
[0206]
步骤s142,构建根结点,将训练样本集放在根结点;
[0207]
步骤s143,判断训练样本集vts是否为同一类,若为同一类,则类别值为根结点 值,根结点也为叶结点,返回决策树;
[0208]
步骤s144,若不为同一类,则设置空间度量关系特征m为根结点值,将所有数据 在空间度量关系特征m的取值m放在根结点;
[0209]
步骤s145,根据所有取值m建立根结点的分支,每一个取值对应一个分支;
[0210]
步骤s146,若第i个取值m
i
中只有一个分量,则建立该分支对应的子结点,该结 点为叶结点,结点值为分量值;
[0211]
步骤s147,若第i个取值m
i
中有多个分量,则找到训练样本集vts中类别值属于 m
i
的分量的所有样本,这些样本即为m
i
分支对应的子训练样本集,以子训练样本集和 特征集fs为输入样本和特征,按照前述的步骤构建m
i
分支对应的子决策树;
[0212]
步骤s148,对m的所有分支按步骤s146~步骤s147建立叶结点或子决策树后, 返回决策树。
[0213]
以空间决策树为基础的随机森林为空间随机森林,空间随机森林中包含至少一棵空 间决策树。因此,空间随机森林共有两种构成方式:完全空间随机森林和空间随机树种 森林。其中,完全空间随机森林中只有空间决策树,构建方法与经典随机森林构建方法 相同,但由于空间决策树的根结点为空间度量关系特征,因此空间度量关系特征不参与 特征随机;空间随机树种森林中除了有空间决策树,还有经典决策树,构建空间决策树 的特征集为空间特征,构建经典决策树的特征集为属性特征,在构建每棵决策树前,要 先随机判断该棵决策树的性质,然后根据其性质从对应特征集中随机抽取特征。
[0214]
对空间随机森林进行建立以及对分类结果进行验证也使用分层抽样方法,且方法与 经典随机森林算法完全相同。
[0215]
优选地,所述将体元带入空间随机森林算法进行预测,得到体元匹配的岩层类别 具体为:对随机森林中的每棵决策树,递归地根据决策树的结点找到体元对应的特征值, 根据该特征值进入决策树中该结点对应的分支,最终得到体元的类别;统计随机森林中 所有决策树对体元的分类结果,数量最多的类别即是随机森林对体元预测的类别。
林算法中的替代特征,因此每棵决策树包含前述(1)、(4)部分数据。实验结果如表3 和图16所示,算法精度为26.55%。从结果可以看出,空间场景特征在不同局部空间结 构的表现不同,局部空间结构平缓的地方被预测为类别3,局部空间结构破碎情况较轻 但起伏较多的地方被预测为类别4,局部空间结构破碎严重的地方被预测为类别5,因 此空间场景特征能够用于识别不同局部空间结构的体元。但是,只使用空间场景特征的 经典随机森林算法不能进行岩层分层。
[0257]
表3基于空间场景替代特征的经典随机森林岩层分层统计表
[0258][0259]
(3)使用经典随机森林算法,特征集即有属性特征和空间场景 特征在经典随机森林算法中的替代特征,因此每棵决策树包含前述(1)、(2)、(4)部 分数据。实验结果如表4和图17所示,算法精度为26.98%。从结果可以看出,使用属 性特征和空间场景替代特征的算法结果与仅使用空间场景替代特征的结果基本相同,可 以认为空间场景替代特征基本上完全抑制了属性特征对体元类别预测的作用,在决策树 上一定表现为空间场景分量对应的结点比属性特征对应的结点深度更小,即更靠近根结 点,因此更应该先根据该特征对训练样本集划分子集或分类。使用属性特征和空间场景 替代特征的经典随机森林算法不能进行岩层分层。
[0260]
表4基于属性特征和空间场景替代特征的经典随机森林岩层分层统计表
量关系特征在经典随机森林算法中的替代特征和空间场景特征在经典随机森林算法中 的替代特征,因此每棵决策树包含前述(1)、(2)、(3)、(4)部分数据。实验结果如表 6和图19所示,算法精度为80.49%。从结果可以看出,使用所有特征的经典随机森林 算法能够进行一定程度的分层,但每一层含有较多其它类别,若要实现岩层分层还需进 行进一步处理。从上文的分析,可以推断当空间场景特征存在时,由于空间场景特征对 属性特征基本上完全抑制,空间度量关系特征的替代特征反而对体元类别预测有了巨大 作用,甚至可以对地质体进行初步的岩层分层。
[0267]
表6基于属性特征、空间度量关系替代特征和空间场景替代特征的经典随机森林岩层 分层统计表
[0268][0269]
(6)使用空间随机树种森林算法,特征集fs={r,g,b,a,m,s},森林中有两种决策 树,一种为经典决策树,一种为空间决策树,因此每棵决策树都包含前述第(5)部分 数据,决定当前决策树的算法;经典决策树中包含前述(1)、(2)部分数据,空间决策 树中包含第(1)、(4)部分数据。实验结果如表7、图20和图21所示;图20为保守预 测结果,保守验证精度为40.06%,图21为激进预测结果,激进验证精度为68.31%;一 般精度为54.57%。从结果可以看出,使用所有特征的经典随机森林算法能够进行一定 程度的分层,但每一层含有较多其它类别,若要实现岩层分层还需进行进一步处理。但 是,空间随机树种森林是经典决策树和空间决策树的结合,它的结果由经典决策树和空 间决策树共同决定。由于经典决策树和空间决策树在森林中的出现是随机的,只有森林 中决策树数量足够多时才可能满足1:1,而森林中实际上并不需要那么多树,因此它们 的比例是未知的,而实验1表明经典决策树不能进行岩层分层,若空间决策树可以进行 岩层分层,那么基于这两种树得到的空间随机树种森林算法是否能够用于分层并不能够 确定,这个算法得到的结果并不是稳定的。
[0270]
表7基于属性特征、空间度量关系特征和空间场景特征的空间随机树种森林岩层分层 统计表
[0271][0272][0273]
(7)使用完全空间随机森林算法,特征集此处使用空间场景 特征在经典随机森林算法中的替代特征,因此每棵决策树都包含前述(1)、(2)、(4) 部分数据。实验结果如表8、图22和图23所示;图22为保守预测结果,保守验证精度 为79.60%;图23为激进预测结果,激进验证精度为99.74%;一般精度为89.65%。从 结果可以看出,分层效果较理想。但这组实验中空间场景特征并不是一个特征,而是其 分量都为独立特征,因此只能作为对比实验。
[0274]
表8基于属性特征、空间度量关系特征和空间场景替代特征的完全空间随机森林
岩层 分层统计表
[0275][0276][0277]
(8)使用完全空间随机森林算法,特征集fs={r,g,b,a,m,s},每种特征根据自己 的性质用于随机森林,因此每棵决策树都包含前述(1)、(2)、(4)部分数据。实验结 果如表9、图24和图25所示;图24为保守预测结果,保守验证精度为79.90%;图25 为激进预测结果,激进验证精度为99.74%;一般精度为89.98%。从结果可以看出,分 层效果很理想。这组实验与第7组实验的结果差异较小,差异主要集中在边界附近,而 它们的算法差异主要在空间场景特征的使用方法(空间场景特征的使用方法不同导致属 性特征在决策树中对
应结点的深度也不同),因此可以推断:空间度量关系特征在极大 程度上决定了空间随机森林算法的类别预测效果,但在边界附近的体元类别主要受其它 特征影响。两组实验结果的激进精度完全相同,但实验8的保守精度高0.3%,一般精 度高0.33%,这说明空间场景特征根据其本质参与随机森林算法的运算结果好于空间场 景特征以经典决策树学习方法的特征选择方式参与随机森林算法的运算结果。
[0278]
表9基于属性特征、空间度量关系特征和空间场景特征的完全空间随机森林岩层分层 统计表
[0279][0280]
[0281]
在这8种对比实验中,根据每种特征自己的性质将其用于随机森林算法中的只有实 验5、实验6和实验8,这三种实验中,实验8的结果是最优的;其他5种对比实验与 实验8相比,实验8的结果也是最优的。将实验8的分层结果岩层分界线,与实际岩层 分界线进行对比(图26,蓝色表示实际岩层分界线,红色表示实验8确定的岩层分界线, 绿色为二者重叠部分),可以看到二者差异较小,表明了根据特征自己的性质将之用于 随机森林算法中,可以得到理想的岩层分层结果。
[0282]
对实验8的保守验证结果和激进验证结果进行统计,可以得到表10和表11两个混 淆矩阵,根据混淆矩阵可以得到表12的精度评价结果。
[0283]
表10完全空间随机森林(实验8)的混淆矩阵(保守)
[0284][0285][0286]
表11完全空间随机森林(实验8)的混淆矩阵(激进)
[0287]
[0288]
表12完全空间随机森林(实验8)的算法评价精度
[0289][0290][0291]
对表10、表11和表12进行分析,可以得出以下结论:
[0292]
(1)算法的总体预测效果理想。保守验证总体精度为79.8990%,kappa系数为 0.7508,表示刚好得到理想分类结果;激进总体精度为99.7427%,kappa系数为0.9968, 表示分类效果极为理想;且一般分类精度为89.98%;因此,算法的总体预测结果是很 理想的;
[0293]
(2)算法对类别3的预测效果最好;
[0294]
(3)从精确率看,在保守验证中,其它类别都可能被预测为类别1、类别2、类别3、 类别4或类别5,在这5种类别中,被错误预测为类别5的概率最大,被错误预测为类 别3的概率最小;不可能有其它类别被错误预测为类别6。在激进验证中,其它类别都 可能被预测为类别2、类别4或类别5,被错误预测概率差不多,不可能有其它类别被 错误预测为类别1、类别3和类别6;
[0295]
(4)从召回率看,在保守验证中,每种类别都可能被预测为其它类别(类别6除外), 尤其是类别1,被预测为其它类别的概率非常大,类别3被预测为其它类别的概率最小。 在激进验证中,类别1、类别5和类别6都可能被预测为其它类别,被错误预测概率差 不多,类别2、类别3和类别4都不可能被预测为其它类别;
[0296]
(5)根据f
‑
measure综合分析,可以知道算法对类别3有极为理想的预测结果,对 类别2和类别4有非常理想的预测结果,对类别5和类别6有较为理想的预测结果,对 类别1有一般的预测结果,因此实验8得到的岩层分层结果是理想的。
[0297]
对8种实验进行综合分析,可以得出结论:经典决策树具有类别越多,错分概率越 大的特点;相比于经典决策树和经典随机森林算法仅使用属性特征,引入空间特征的空 间决策树在很大程度上减小了这种错分概率。因此,本发明提出的完全空间随机森林算 法能够显著提高分类正确率,也就能显著提高对岩层正确分层的概率。空间随机森林算 法能够更好地对体元进行分类,并且这种用于露头地质体岩层分层的空间随机森林算法 是合理的。
[0298]
本发明不局限于上述可选实施方式,任何人在本发明的启示下都可得出其它各种 形式的方案,但不论在其结构上作何种变化,凡是落入本发明权利要求界定范围内的技 术方案,均落在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1