基于大数据分析的拉晶方法、系统、计算机设备和存储介质与流程
1.本发明属于光伏单晶拉制生产技术领域,尤其是涉及基于大数据分析的拉晶方法、系统、计算机设备和存储介质。
背景技术:
2.直拉单晶生长过程主要包括稳温、引晶、放肩、等径、收尾等其它工步。目前单晶拉制过程主要是人工操作的集控系统来控制单晶生长,这种控制方式虽然能通过集控系统实现标准范围内的自动化操作,但决策部分仍需专业工程师进行操作控制,这种拉晶方式生产不稳定、拉晶生产效率低,人为因素太多,导致拉晶生产成本较大。
技术实现要素:
3.本发明提供基于大数据分析的拉晶方法、系统、计算机设备和存储介质,尤其是适用于太阳能直拉硅单晶生产,解决了现有技术中人工操作集控系统带来的拉晶质量不稳定、生产成本高的技术问题。
4.为解决上述技术问题,本发明采用的技术方案是:
5.基于大数据分析的拉晶方法,步骤包括:
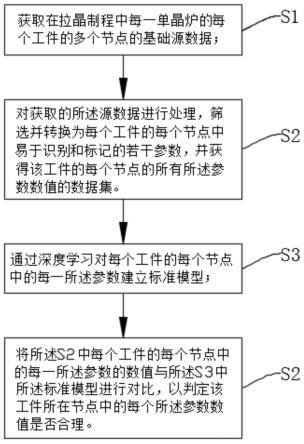
6.s1:获取在拉晶制程中每一单晶炉的每个工件的多个节点的基础源数据;
7.s2:对获取的所述源数据进行处理,筛选并转换为每个工件的每个节点中易于识别和标记的若干参数,并获得该工件的每个节点的所有所述参数数值的数据集;
8.s3:通过深度学习对每个工件的每个节点中的每一所述参数建立模型;
9.s4:将所述s2中每个工件的每个节点中的每一所述参数的数值与所述s3中所述模型进行对比,以判定该工件所在节点中的每个所述参数数值是否合理。
10.进一步的,在所述s4中,若该工件所在节点中的所有所述参数数值在所述模型范围内,则继续下一节点的运行;
11.若该工件所在节点中的某些所述参数数值不在所述模型范围内,则执行暂停或调整相应节点中的相关所述参数。
12.进一步的,所述s2中每一工件每一节点的所有所述参数类型与所述s3中每一工件每一节点的所有所述参数类型相对应;
13.优选地,所述参数按照生产区域、每一节点的首尾时间、上下节点之间的关联数据、以及每一节点中的不同功能等进行建立;
14.优选地,每一工件中每一节点的所有所述参数均被配制于拉制该工件所在单晶炉的终端显示器中显示。
15.进一步的,每一工件中每一节点的所述源数据均包括生产过程数据和/或原辅料数据和/或品质数据;
16.优选地,每一工件中的所述节点至少包括稳温节点、引晶节点、放肩节点、等径节点和收尾节点,且所述稳温节点、所述引晶节点、所述放肩节点、所述等径节点和所述收尾
节点为依次设置;
17.优选地,所述模型至少包括稳温节点模型、引晶节点模型、放肩节点模型、等径节点模型和收尾节点模型。
18.一种拉晶系统,所述系统包括:
19.获取源数据单元:用于获取在拉晶制程中每一单晶炉的每个工件的多个节点的基础源数据;
20.处理源数据单元:用于对获取的所述源数据进行处理,筛选并转换为每个工件的每个节点中易于识别和标记的若干参数,并获得该工件的每个节点的所有所述参数数值的数据集;
21.建立模型单元:用于通过深度学习对每个工件的每个节点中的每一所述参数建立模型;
22.判定参数单元:用于将所述处理源数据单元中每个工件的每个节点中的每一所述参数的数值与所述建立模型单元中的所述模型进行对比,以判定该工件所在节点中的每个所述参数数值是否合理。
23.进一步的,在所述判定参数单元中,当该工件所在节点中的所有所述参数数值在所述模型范围内,则继续下一节点的运行;
24.该工件所在节点中的某些所述参数数值不在所述模型范围内,则执行暂停或调整相应节点中的相关所述参数。
25.进一步的,所述处理源数据单元中每一工件每一节点的所有所述参数类型与所述建立模型单元中每一工件每一节点的所有所述参数类型相对应;
26.优选地,所述参数按照生产区域、每一节点的首尾时间、上下节点之间的关联数据、以及每一节点中的不同功能等进行建立;
27.优选地,每一工件中每一节点的所有所述参数均被配制于拉制该工件所在单晶炉的终端显示器中显示。
28.进一步的,每一工件中每一节点的所述源数据均包括生产过程数据和/或原辅料数据和/或品质数据;
29.优选地,每一工件中的所述节点至少包括稳温节点、引晶节点、放肩节点、等径节点和收尾节点,且所述稳温节点、所述引晶节点、所述放肩节点、所述等径节点和所述收尾节点为依次设置;
30.优选地,所述模型至少包括稳温节点模型、引晶节点模型、放肩节点模型、等径节点模型和收尾节点模型。
31.一种计算机设备,包括存储器和处理器;所述存储器存储有计算机程序;所述处理器,用于执行所述计算机程序,并在执行所述计算机程序时,使得所述处理器执行如上任一项所述的拉晶方法的步骤。
32.一种计算机可读存储介质,存储有计算机程序,当所述计算机程序被所述处理器执行时,使所述处理器执行如上任一项所述的拉晶方法的步骤。
33.与现有技术相比,采用本发明设计的基于大数据分析的拉晶方法、系统、计算机设备和存储介质,通过对基础源数据进行汇总、筛选、转换为每个工件的多个节点中易于识别和标记的若干与模型中相对应的参数数值的数据集;同时通过深度学习对每个工件的多个
节点中的每一所述参数建立模型;再将处理后的每个工件的多个节点中的每一参数的数值与模型中的参数范围进行对比,再判定该工件所在节点中的参数数值是否合理。
34.本发明技术方案可有效地在大数据与深度学习中进行智能拉晶,利用了大数据分析并执行优化方案,再将大数据与深度学习进行有机结合,提高拉晶质量和拉晶效率,降低拉晶成本。
附图说明
35.图1是本发明一实施例的基于大数据分析的拉晶方法的流程图;
36.图2是本发明一实施例的拉晶制程中的流程图;
37.图3是本发明一实施例的拉晶系统的结构示意图。
38.图中:
具体实施方式
39.下面结合附图和具体实施例对本发明进行详细说明。
40.本实施例提出基于大数据分析的拉晶方法,如图1所示,步骤包括:
41.s1:获取在拉晶制程中每一单晶炉的每个工件的多个节点的基础源数据。
42.具体地,在每一个单晶炉拉制每一个单晶工件中,都涉及若干节点,所述节点至少包括稳温节点、引晶节点、放肩节点、等径节点和收尾节点,且稳温节点、引晶节点、放肩节点、等径节点和收尾节点依次设置。每一节点的基础源数据均包括生产过程数据和/或原辅料数据和/或品质数据。
43.其中,生产过程数据包括设备名称、每一节点中的起止时间、批次编号、工艺模式、配方名称、直径测量值、热场温度值、主加热器功率测量、底部加热器功率测量、实际晶体拉速等。
44.原辅料数据包括备料日期、配料序号、每一节点中的人员班次、炉次、工件规格、坩埚类型、坩埚产地、原生多晶重量、回收料占比、整体重量等。
45.品质数据包括每一工件的单晶编号、长度、重量、直径、电阻率、寿命、氧含量、碳含量、缺陷等。
46.s2:对s1中获取的源数据进行处理,筛选并转换为每个工件的每个节点中易于识别和标记的若干参数,并获得该工件的每个节点的所有参数数值的数据集。
47.具体地,将每一节点的基础数据经过抽取、筛选并转换为该节点中易于识别和标记的若干参数,以获得易于与标准模块中的所述参数相比对的参数数值的数据集,也就是将输入的基础源数据中分散、凌乱、标准不统一的源数据整合,再转换为工件制程节点中的常用参数数据集,为后续参数判定分析提供依据。
48.进一步的,所有参数均按照生产区域、每一节点的首尾时间、上下节点之间的关联数据、以及每一节点中的不同功能等进行建立。且每一工件中每一节点的所有参数均被配制于拉制该工件所在单晶炉的终端显示器中显示,人员可实时监控到每一单晶炉台的变化情况。
49.s3:通过深度学习对每个工件的每个节点中的每一所述参数建立模型。
50.具体地,采用深度学习的方法对每个工件的每一节点的所有参数均建立一个模
型,以监控所有炉台的工件在制程中的节点分析和判断,以期获得质量符合标准的单晶工件。
51.进一步的,模型中每一工件的每一节点的每一个参数类型与步骤s2中每一工件每一节点的每一个参数类型相对应。
52.进一步的,模型至少包括稳温节点的模型、引晶节点的模型、放肩节点的模型、等径节点的模型和收尾节点的模型。
53.s4:将步骤s2中每个工件的每一个节点中的每一个参数的数值与步骤s3中的模型进行对比,以判定该工件在所在节点中的每个参数数值是否合理。
54.具体地,若该工件所在节点中的所有参数数值在模型范围内,则继续下一节点的运行。
55.若该工件所在节点中的某些参数数值不在模型范围内,则执行暂停或调整相应节点中的相关参数。
56.如图2所示,为拉晶制程中的流程图:
57.在拉制时,从处理源数据单元中的数据集中获取的工件稳温中的数据与稳温节点模型中的数据进行匹配,当实时数据与在稳温节点模型中的范围之内,则稳温开始。在整个稳温过程中,稳温节点模型可自调整相关参数数值以使其达到合格范围内,直至稳温结束。稳温节点模型并可自动判断稳温节点结束时的数据是否可以引晶;若可以继续进入引晶节点制程中;若不可以,调整至稳温前的工步中,从稳温节点的开始进行。
58.进入引晶节点制程中,从数据集中获取的工件引晶中的数据与引晶节点模型中的数据进行匹配,当实时数据与在引晶节点模型中的范围之内,则引晶开始。在整个引晶过程中,引晶节点模型可自调整相关参数数值以使其达到合格范围内,直至引晶结束。引晶节点模型并可自动判断引晶节点结束时的数据是否可以放肩;若可以继续进入放肩节点制程中;若不可以,回溯调整至稳温前的工步中,从稳温节点的开始逐步进行直至可以进入放肩节点制程中。
59.进入放肩节点制程中,从数据集中获取的工件放肩中的数据与放肩节点模型中的数据进行匹配,当实时数据与在放肩节点模型中的范围之内,则放肩开始。在整个放肩过程中,放肩节点模型可自调整相关参数数值以使其达到合格范围内,直至放肩结束。放肩节点模型并可自动判断放肩节点结束时的数据是否可以转肩;若可以继续进入转肩节点制程中;若不可以,回溯调整至稳温前的工步中,从稳温节点的开始逐步进行直至可以进入转肩节点制程中。
60.进入转肩节点制程中,从数据集中获取的工件转肩中的数据与转肩节点模型中的数据进行匹配,当实时数据与在转肩节点模型中的范围之内,则转肩开始。在整个转肩过程中,转肩节点模型可自调整相关参数数值以使其达到合格范围内,直至转肩结束。转肩节点模型并可自动判断转肩节点结束时的数据是否可以等径;若可以继续进入等径节点制程中;若不可以,回溯调整至稳温前的工步中,从稳温节点的开始逐步进行直至可以进入等径节点制程中。
61.进入等径节点制程中,从数据集中获取的工件等径中的数据与等径节点模型中的数据进行匹配,当实时数据与在等径节点模型中的范围之内,则等径开始。在整个等径过程中,等径节点模型可自调整相关参数数值以使其达到合格范围内,直至等径结束。等径节点
模型并可自动判断等径节点结束时的数据是否可以收尾;若可以继续进入收尾节点制程中;若不可以,回溯调整至稳温前的工步中,从稳温节点的开始逐步进行直至可以进入收尾节点制程中。
62.进入收尾节点制程中,从数据集中获取的工件收尾中的数据与收尾节点模型中的数据进行匹配,当实时数据与在收尾节点模型中的范围之内,则收尾开始。在整个收尾过程中,收尾节点模型可自调整相关参数数值以使其达到合格范围内,直至收尾结束。收尾节点模型并可自动判断收尾节点结束时的数据是否可以复投或停炉;若可以继续进入复投或停炉节点制程中;若不可以,回溯调整至稳温前的工步中,从稳温节点的开始逐步进行直至可以进入复投或停炉节点制程中。
63.一种拉晶系统,如图3所示,所述系统包括:
64.获取源数据单元:用于获取在拉晶制程中每一单晶炉的每个工件的多个节点的基础源数据。
65.处理源数据单元:用于对获取的源数据进行处理,筛选并转换为每个工件的每个节点中易于识别和标记的若干参数,并获得该工件的每个节点中的所有参数数值的数据集。
66.建立模型单元:用于通过深度学习对每个工件的每个节点中的每一参数建立模型。
67.判定参数单元:用于将处理源数据单元中每个工件的每个节点中的每一参数的数值与建立模型单元中的模型进行对比,以判定该工件所在节点中的每个参数的数值是否合理。
68.其中,判定参数单元包括当该工件所在节点中的所有参数数值在模型范围内,则继续下一节点的运行。当该工件所在节点中的某些参数数值不在模型范围内,则执行暂停或调整相应节点中的相关所述参数。
69.进一步的,处理源数据单元中每一工件每一节点的所有参数类型与建立模型单元中每一工件每一节点的所有参数类型相对应。
70.进一步的,参数按照生产区域、每一节点的首尾时间、上下节点之间的关联数据、以及每一节点中的不同功能等进行建立。
71.进一步的,每一工件中每一节点的所有参数均被配制于拉制该工件所在单晶炉的终端显示器中显示。
72.进一步的,每一工件中每一节点的源数据均包括生产过程数据和/或原辅料数据和/或品质数据。
73.进一步的,每一工件中的节点至少包括稳温节点、引晶节点、放肩节点、等径节点和收尾节点,且稳温节点、引晶节点、放肩节点、等径节点和收尾节点为依次设置。
74.进一步的,所述模型至少包括稳温节点的模型、引晶节点的模型、放肩节点的模型、等径节点的模型和收尾节点的模型。
75.一种计算机设备,包括存储器和处理器;其中,存储器存储有计算机程序;处理器是用于执行所述计算机程序,并在执行计算机程序时,使得处理器执行如上任一项所述的拉晶方法的步骤。
76.一种计算机可读存储介质,存储有计算机程序,当计算机程序被处理器执行时,使
处理器执行如上任一项所述的拉晶方法的步骤。
77.1、基于大数据分析的拉晶方法、系统、计算机设备和存储介质,通过对基础源数据进行汇总、筛选、转换为每个工件的多个节点中易于识别和标记的若干与模型中相对应的参数数值的数据集;同时通过深度学习对每个工件的多个节点中的每一所述参数建立模型;再将处理后的每个工件的多个节点中的每一参数的数值与模型中的参数范围进行对比,再判定该工件所在节点中的参数数值是否合理。
78.2、本发明技术方案可有效地在大数据与深度学习中进行智能拉晶,利用了大数据分析并执行优化方案,再将大数据与深度学习进行有机结合,提高拉晶质量和拉晶效率,降低拉晶成本。
79.以上对本发明的实施例进行了详细说明,所述内容仅为本发明的较佳实施例,不能被认为用于限定本发明的实施范围。凡依本发明申请范围所作的均等变化与改进等,均应仍归属于本发明的专利涵盖范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1