一种基于视频的人体行为网络模型及识别方法
本发明涉及计算机视觉技术领域,特别涉及一种基于视频的人体行为网络模型及识别方法。
背景技术:
当今社会,计算机技术已经飞速发展起来,具有非常强大的功能,可以协助人类解决很多问题。基于视频序列的人体行为识别,作为多学科交叉的研究课题,是计算机视觉中的一个非常重要的子任务,应用非常广泛。
随着硬件技术的发展和物联网技术的推广,监控摄像头已经无处不在,但它只能起到实时记录的作用,并不具备智能分析功能,需要人工监视视频内容,容易造成误判,不能及时地做出适当有效的判断,无法满足视频监控的要求。基于视频的人体行为识别,可以对视频中的人体行为进行有效地识别,从而节省大量的人力物力,因此具有很重要的研究意义和研究价值。但是传统行为识别方法需要通过人工提取特征来对动作进行表述,容易受到摄像机不同视角、背景杂乱的影响,导致提取过程复杂且特征的表征能力较弱,局限性大,因此需要设计一种非常高效的人体行为识别方法。
中国发明专利cn109784418a《一种基于特征重组的人体行为识别及系统》公开了一种基于特征重组的人体行为识别方法。该方法选用过滤式和嵌入式特征等方法选择特征,并组合成一个初始化特征集,然后按特征出现频率将特征集划分为高频特征和低频特征,并对低频特征进行随机选择与高频特征重组成新的特征集,最后采用分类算法对新的特征集进行人体行为识别,计算每个行为类别的识别率。该方法虽然在一定程度上能够提高识别精度,但它不能进行端对端的训练,导致效率低下。
中国发明专利cn102811343b《一个基于行为分析的智能视频监控系统的原型》公开了一种基于行为识别的智能视频监控系统,从而对目标进行分类。该系统首先进行视频采集,然后将其进行处理,接着采用贝叶斯分类算法对视频行为进行分类,最后输送到报警模块,进行预警。该专利虽然提高了精度,但其只是对视频数据进行了有效地预处理,算法属于传统行为识别方法,并未对其创新,使得特征提取过程复杂,泛化能力差。
技术实现要素:
本发明针对现有技术的缺陷,提供了一种基于视频的人体行为网络模型及识别方法。
为了实现以上发明目的,本发明采取的技术方案如下:
一种基于视频的人体行为网络模型,其特征在于,包括:3d卷积层、block网络块、全局均值池化层和softmax激活函数层;其中,3d卷积层对输入的连续视频帧进行卷积以及提高维度;block网络模块一共有四个且结构相同,都是由改进的残差块以及se模块构成;改进残差块由bn层-relu激活函数-卷积层(3×3×3)-bn层-relu激活函数-卷积层(3×3×3)-shortcut连接构成;改进的se模块由:全局平均池化层-逐点卷积层(1×1×1)-relu激活函数-逐点卷积层(1×1×1)-sigmoid激活函数层构成;
在单个block网络模块里,连续的视频帧先经过残差块,可以解决模型退化以及梯度爆炸的问题,从而提取出有效地特征,然后改进的se模块对残差块输出的通过进行重要度判别,从而提高重要通道的利用率,加强有用特征的提取,压缩无用特征的使用;四个模块依次叠加,可以加深网络,使提取有效特征的能力最大化,从而提高识别精度;全局平均池化层不仅可以起到全连接层的作用,还可以有效地减少网络模型参数,同时在结构上做正则化防止过拟合;softmax激活层用于输出行为类别。
本发明还公开了一种基于视频的人体行为识别方法,包括以下步骤:
s1、对网络模型进行训练;
s2、将经过预处理后的连续视频帧输入到第一个3×3×3的卷积层中进行卷积操作,之后进入bn层进行归一化操作,最后进入relu激活函数层,进行非线性变换;其中,bn层用于将每层的输出规范为标准正态分布,即将均值归一化为0,将方差归一化为1;
s3、将relu激活函数层的输出输入到第一层block网络模块、第二层block网络模块、第三层block网络模块和第四层block网络模块进行特征提取后输入到全局平均池化层;其中,每一层block网络模块都是按照bn层-relu激活函数-卷积层(3×3×3)-bn层-relu激活函数-卷积层(3×3×3)-全局平均池化层-逐点卷积层(1×1×1)-relu激活函数-逐点卷积层(1×1×1)-sigmoid激活函数层-shortcut连接构成;
s4、所述全局均值池化层对输入数据做正则化防止过拟合后输出到softmax激活函数层,最后输出行为类别。
进一步地,s1的子步骤如下:
s11、采集人体行为数据并对其标注类别后制作成有效的视频数据集;最后,通过图像预处理的后,将视频数据集按照7:3的比列划分为训练集和测试集;
s12、通过网络模型提取图像的特征并对其进行向前传播得到训练类别,再由损失函数反向传播更新梯度参数;
s13、训练好网络模型后,选取测试集输入到上述完成训练的网络模型中,通过前向传播得到行为类别,从而获得识别准确率;
s14、结束网络模型的训练与测试。
进一步地,视频数据集制作为:首先,对校园的异常行为进行定义,异常行为包括:打架、脚踢、跑步、吸烟和摔倒;然后将该数据集输入到网络模型中进行预测,然后,通过视频监控的方式进行视频拍摄,从而获取视频数据集。
进一步地,在训练开始之前,将网络模型随机初始化,并使用sgd作为优化器,其中出示学习设置为0.01,然后每隔10个epochs除以10,mini-batch设置为16,总的epochs设置为100,使用交叉熵损失函数。
本发明还公开了基于上述网络模型的人体行为识别方法,包括以下步骤:
s1、对网络模型进行训练;
s2、将经过预处理后的连续视频帧输入到第一个3×3×3的卷积层中进行卷积操作,之后进入bn层进行归一化操作,最后进入relu激活函数层,进行非线性变换。其中,bn层用于将每层的输出规范为标准正态分布,即将均值归一化为0,将方差归一化为1。
s3、将relu激活函数层的输出输入到第一层block网络模块、第二层block网络模块、第三层block网络模块和第四层block网络模块进行特征提取后输入到全局平均池化层。其中,每一层block网络模块都是按照bn层-relu激活函数-卷积层(3×3×3)-bn层-relu激活函数-卷积层(3×3×3)-全局平均池化层-逐点卷积层(1×1×1)-relu激活函数-逐点卷积层(1×1×1)-sigmoid激活函数层-shortcut连接构成。
s4、所述全局均值池化层对输入数据做正则化防止过拟合后输出到softmax激活函数层,最后输出行为类别。
进一步地,s1的子步骤如下:
s11、采集人体行为数据并对其标注类别后制作成有效的视频数据集;最后,通过图像预处理的后,将视频数据集按照7:3的比列划分为训练集和测试集。
s12、通过网络模型提取图像的特征并对其进行向前传播得到训练类别,再由损失函数反向传播更新梯度参数。
s13、训练好网络模型后,选取测试集输入到上述完成训练的网络模型中,通过前向传播得到行为类别,从而获得识别准确率。
s14、结束网络模型的训练与测试。
进一步地,视频数据集制作为:首先,对校园的异常行为进行定义,异常行为包括:打架、脚踢、跑步、吸烟和摔倒;然后将该数据集输入到网络模型中进行预测,然后,通过视频监控的方式进行视频拍摄,从而获取视频数据集;
进一步地,在训练开始之前,将网络模型随机初始化,并使用sgd作为优化器,其中出示学习设置为0.01,然后每隔10个epochs除以10,mini-batch设置为16,总的epochs设置为100,使用交叉熵损失函数。
与现有技术相比,本发明的优点在于:
通过端对端的方式对网络模型进行快速训练,并通过将残差块与se模块的有效结合,提高了提取时空特征的能力,本发明简单、快捷,且识别精度高。解决了网络模型的参数较多以及准确率较低的问题。
附图说明
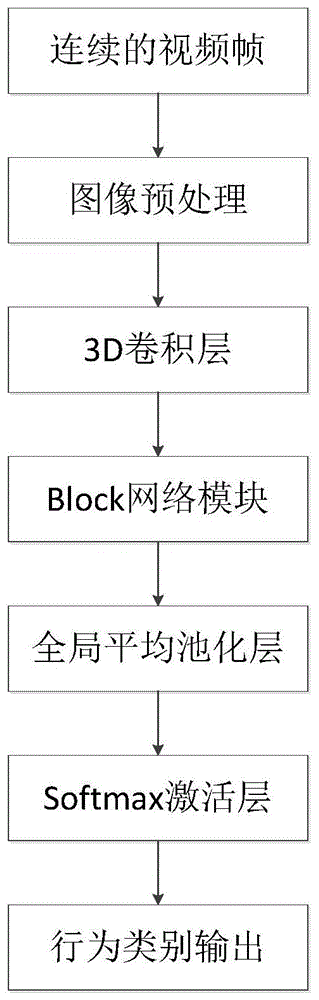
图1是本发明实施例人体行为识别网络模型结构示意图;
图2是本发明实施例relu函数示意图;
图3是本发明实施例单个block网络模块示意图;
图4是本发明实施例改进的残差块模块示意图;
图5是本发明实施例改进的se模块示意图;
图6是本发明实施例人体行为识别方法流程图;
图7是本发明实施例网络模型训练流程图;
具体实施方式
为使本发明的目的、技术方案及优点更加清楚明白,以下根据附图并列举实施例,对本发明做进一步详细说明。
如图1所示,为发明实施例提供的一种人体行为识别网络模型,其主要结构为3d卷积层、block网络模块、全局均值池化层和softmax激活函数层。
其中,在图像预处理阶段,针对相邻视频帧存在大量冗余信息问题,本发明采用二次稀疏采样的方法对视频进行图像帧提取。首先,采用间隔设置为2帧,对原始视频进行采样,得到序列的视频帧;在一次采样的基础上,对视频帧进行二次稀疏采样,从而得到最终的视频帧数据集。二次稀疏采样不仅剔除了相邻视频帧的冗余信息,还能以较少的帧数代表视频全局信息,有效地提高了识别精度。
将两次稀疏采样后的视频帧先进行随机裁剪,把图像尺寸缩减为128×171,然后再通过中心裁剪,将图像尺寸进一步缩减到112×112,为后续做准备;再通过水平翻转、去噪等操作对图像进行数据增强。
将处理好的连续视频帧输入到第一个3d卷积层中,用3×7×7的卷积核对图像进行时空卷积操作,扩大感受野,得到更多的行为特征,然后输入到block网络模块中进一步地提取特征;最后通过全局平均池化层进行处理后输入到所述softmax激活函数层进行行为类别输出。
进一步地,bn层(batchnormalization)用于将每层的输出规范为标准正态分布,即将均值归一化为0,将方差归一化为1,从而使得下层网络能够更好地学习,并使训练速度加快,提高网络模型的泛化能力。
进一步地,如图2所示,relu激活函数如式(1)
relu激活函数其实是分段函数,把所有的负值都变为0,而正值不变,可以进行非线性变换,因此是网络模型具有稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生,更利于行为识别网络模型的训练。
进一步地,如图3所示,一共有4个block网络模块,每个block网络模块主要由图4的改进残差块以及图5的改进se模块由上到下依次组成。
首先,传统残差块采用的是卷积层在前,然后连接bn层和relu激活函数层。由于bn层作为pre-activation不仅符合反向传播假设,信息传递无阻碍而且还能起到正则化的作用,故本发明将bn层、relu激活函数层放在卷积层之前。如图4所示,改进残差块由bn层-relu激活函数-卷积层(3×3×3)-bn层-relu激活函数-卷积层(3×3×3)-shortcut连接构成。
原来的se模块采用的是在全局平均池化层后面连接两层全连接层,这样就导致网络模型参数增多,影响网络模型的运行速度。由于逐点卷积的作用等价于全连接层,还可以权值共享,故如图5所示,与原来的se模块不同,本发明为了减少网络模型参数,采用了逐点卷积代替全连接层的方法。改进的se模块主要由全局平均池化层-3d逐点卷积层(1×1×1)-relu激活函数-3d逐点卷积层(1×1×1)-sigmoid激活函数层等构成。
因此将第一层3d卷积层的输出结果输入到block网络模块里,先经过残差块对特征提取,然后将其结果在输入到se模块里进行通道重标定操作,使得网络可以多学习一些重要的行为特征,依次类推,经过4个block网络模块后,将block输出的结果输入到全局平均池化层中进行下一步操作。
如图6和图7所示,本发明还公开了一种基于视频的人体行为识别方法,所述方法包括:
s1、对实施例1中所建立的网络模型进行训练,其主要步骤如下所示:
s11、采集了大量的人体行为数据并对其标注类别后制作成有效的数据集;然后将该数据集输入到网络模型中进行预测。其中,本发明所用到的数据集为自制数据集。首先,对校园的异常行为进行定义,如:打架、脚踢、跑步、吸烟和摔倒等五类异常行为;然后,通过视频监控的方式进行视频拍摄,从而获取视频数据集;最后,通过图像预处理的后,将数据集按照7:3的比列将数据集划分为训练集和测试集。在训练开始之前,将网络模型随机初始化,并使用sgd作为优化器,其中出示学习设置为0.01,然后每隔10个epochs除以10,mini-batch设置为16,总的epochs设置为100,使用交叉熵损失函数。
s12、通过网络模型提取图像的特征并对其进行向前传播得到训练类别,再由损失函数反向传播更新梯度参数。
s13、训练好网络模型后,选取一定数量人体行为数据作为测试集输入到上述完成训练的网络模型中,通过前向传播得到行为类别,从而获得识别准确率。
s14、结束网络模型的训练与测试。
s2、将经过预处理后的连续视频帧输入到第一个3×3×3的卷积层中进行卷积操作,之后进入bn层进行归一化操作,最后进入relu激活函数层,进行非线性变换。其中,bn层(batchnormalization)用于将每层的输出规范为标准正态分布,即将均值归一化为0,将方差归一化为1。
s3、将所述relu激活函数层的输出输入到第一层block网络模块、第二层block网络模块、第三层block网络模块和第四层block网络模块进行特征提取后输入到全局平均池化层。其中,每个block网络模块都是按照bn层-relu激活函数-卷积层(3×3×3)-bn层-relu激活函数-卷积层(3×3×3)-全局平均池化层-逐点卷积层(1×1×1)-relu激活函数-逐点卷积层(1×1×1)-sigmoid激活函数层-shortcut连接等构成。
s4、所述全局均值池化层对输入数据做正则化防止过拟合后输出到softmax激活函数层,最后输出行为类别。通过全局平均池化层对上一层所输入的数据进行展平以及正则化处理,从而防止网络模型的过拟合问题,同时直接实现了降维,更重要的是极大地减少了网络的参数,提高了网络模型数据的计算速度和识别效率。
本领域的普通技术人员将会意识到,这里所述的实施例是为了帮助读者理解本发明的实施方法,应被理解为本发明的保护范围并不局限于这样的特别陈述和实施例。本领域的普通技术人员可以根据本发明公开的这些技术启示做出各种不脱离本发明实质的其它各种具体变形和组合,这些变形和组合仍然在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!