基于图像和文本多模态数据的产品外观风格评价方法和系统
本发明涉及多模态数据技术领域,具体地,涉及一种基于图像和文本多模态数据的产品外观风格评价方法和系统。
背景技术:
随着近年来逐渐提升的消费者综合要求和越来越多的商品种类,产品外观对消费者的购买决策的影响也越来越大。对许多日常消费品如收音机、吹风机等,产品外观正逐步成为影响产品成功的决定性因素。产品外观的美学风格对产品的综合外观十分重要,并且与所吸引的用户类型息息相关。美学风格一般是由特定词汇语义描绘的抽象审美概念,有一定的主观性和模糊性,其审美概念与特定词汇所传递给用户的美学联想可能存在差异,在实际中,常同时使用若干种不同的美学风格,以多个风格词汇和对应的多维美学风格值对产品进行描述。产品设计师所要传递的美学风格一般由产品图像来体现,而用户所实际体验的风格在用户反馈评论中常常有体现,两者的差异反映了产品风格呈现的成功度,越是成功的外观设计,其所要传递的美学风格与用户实际反馈的风格越是接近。
图像美学风格分析基于图像处理与分析,通过对图像和美学风格标签之间的映射关系进行建模,发掘图像所呈现美学风格的规律,可用于对产品图像的美学风格预测。美学风格具有较大的普适性,例如适用于风景、人物等图像的风格也可用于形容产品外观,因此基于已有的大型图像美学风格分类数据集学习的图像与美学风格映射关系,经过较小的调整即可适用于产品图像。ava(alarge-scaledatabaseforaestheticvisualanalysis)是一个包含超过250000张有标签图像的图像美学数据集,共有14种美学风格标签。在特定的产品领域下创建一个较小的有标签产品图像数据集,则仅需收集部分产品图像进行风格标注,经过数据增强后以较少的成本完成创建。
语义情感分析是近年来迅速发展的一种基于文本进行情感倾向分析的语义处理技术,能够通过对文本进行处理和分析,获得文本所体现的对一些特征的情感倾向。这些特征可以是具体事物如产品,也可以是抽象概念如某种美学风格。情感倾向一般是两极的,正面和负面倾向,情感倾向越偏向正面的,对应特征的体现程度越高。
传统的外观风格评价方法主要是专家打分法,方法本身存在主观性很强的缺点,对于外观风格评价这样的抽象和模糊的任务缺点更为明显。
专利文献cn106600385a(申请号:cn201611251457.5)公开了一种基于用户追踪的在线产品分析系统,包括用户评论数据模块、文本数据模块、图像数据模块、文件数据分析模块、图像数据分析模块、综合评价分析模块和用户交互模块,用户评论数据模块用于提取商品用户的评论数据,用户评论数据模块分别连接至文本数据模块和图像数据模块,文本数据模块连接至文件数据分析模块,文件数据分析模块连接至综合评价分析模块,图像数据模块连接至图像数据分析模块,图像数据分析模块连接至综合评价分析模块,综合评价分析模块连接至用户交互模块。而本发明基于模型和算法进行了训练,更为真实准确。
技术实现要素:
针对现有技术中的缺陷,本发明的目的是提供一种基于图像和文本多模态数据的产品外观风格评价方法和系统。
根据本发明提供的基于图像和文本多模态数据的产品外观风格评价方法,包括构建图像美学风格模型,使用图像美学风格预测算法,进行语义情感分析和多模态融合评价;
所述图像美学风格模型为多层卷积神经网络模型,以彩色图像为输入,以多维的图像风格分类为输出;
所述图像美学风格预测算法用于进行预训练和迁移学习,预测产品图像的风格类型;
所述语义情感分析包括:使用图像美学风格预测算法中的风格标签处理用户线上评论,计算用户反馈的产品风格倾向;
所述多模态融合评价包括:融合图像美学风格预测算法输出的产品风格预测和语义情感分析输出的产品风格反馈,提供外观风格方面的产品评价结果。
优选的,所述图像美学风格模型包括依次连接的:
-输入层,输入为被缩放为224*224大小的彩色图像,输入维度为b*224*224*3,其中b为批大小batch_size;
-4个卷积层,卷积核大小为9*9,步长为1,卷积核数目为64,激活函数为relu函数;
-批归一化层;
-1个池化层,采用最大池化,池化大小2*2;
-3个卷积层,卷积核大小为7*7,步长为1,卷积核数目为64,激活函数为relu函数;
-1个池化层,采用最大池化,池化大小2*2;
-3个卷积层,卷积核大小为5*5,步长为1,卷积核数目为128,激活函数为relu函数;
-dropout层,dropout概率为0.1;
-批归一化层;
-1个池化层,采用最大池化,池化大小2*2
-3个卷积层,卷积核大小为3*3,步长为1,卷积核数目为128,激活函数为relu函数;
-1个池化层,采用最大池化,池化大小2*2;
-flatten层,将b*14*14*128维的特征图展为一维b*14*14*128长度的向量;
-全连接层,输出风格分类结果,标签数为14,分别对应14种风格标签,激活函数为softmax。
优选的,所述图像美学风格模型的损失函数为最小化交叉熵损失函数,使用adam优化器进行权重更新,学习率设为0.0001。
优选的,所述图像美学风格预测算法采用迁移学习策略,首先在大型图像美学风格分类数据集ava上使用数据集的14种风格标签进行预训练,随后在特定产品领域下14种风格标签标注的小型产品图像风格数据集上进行微调,在无标签的测试集上进行测试;
测试图像的图像美学风格模型预测输出为该图像的风格预测结果,为14维向量p=(p1,p2…p14),p满足:
∑ipi=1
其中,pi表示该图像属于第i种风格的概率。
优选的,所述语义情感分析模块,使用图像美学风格预测算法中的14个风格标签处理线上用户评论,使用wordnet语义词典的同义查找方法lemma_names分别找到14个风格标签的同义词,将各个风格标签扩充为风格词集,包括以下步骤:
步骤1:对第i个风格标签词,分别在wordnet中查找该词对应的语义集合synsetsi;
步骤2:对synsetsi中的第j个语义synsetij,使用lemma_names方法找到其同义词集合lemij;
步骤3:将第i个风格标签词对应的所有同义词集合lemij组成第i个风格词集seti:
seti=∪jlemij。
优选的,所述语义情感分析包括:将风格标签扩充为风格词集后,从线上电商平台上收集预设产品的线上用户评论,对评论文本进行清洗和预处理,包括以下步骤:
步骤1:文本收集,使用python库urllib进行自动收集线上用户评论;
步骤2:文本清洗,包括筛除重复的语句,筛除不属于预设语言的语句,筛除只包含非文本内容的语句,剔除拼写错误的词;
步骤3:文本预处理,包括将所有字符转为小写字母,剔除不符合规范的标点符号,剔除停用词,将所有动词转为现在时态。
优选的,所述语义情感分析模块包括:对评论文本清洗和预处理后,依次对文本中的每个单词使用wordnet提供的语义相似度计算方法lin_similarity分别计算与14个风格词集的相似度,处理完所有文本后,统计所有词的相似度结果,得到用户反馈的风格倾向结果,第k个单词wk与第i个风格词集seti的相似度simk,i计算公式为:
simk,i,t为第k个单词wk与第i个风格词集seti中第t个词的相似度:
其中,synsetkm为第k个单词wk的语义集合synsetsk中的第m个语义,synsetitn为第i个风格词集seti中第t个词的语义集合synsetsit中的第n个语义,lin_similarity为wordnet提供的语义相似度计算方法;
统计所有词的相似度计算结果,用户反馈的对第i个风格的归一化倾向值oi为:
o'i=∑ksimk,i
oi=o′i/∑io′i
最后得出产品的用户反馈的风格倾向o=(o1,o2…o14),作为语义情感分析的输出。
优选的,所述多模态融合评价包括:将图像美学风格预测算法输出的风格预测值p和语义情感分析模块输出的风格倾向反馈值o进行比较;
p和o的每个对应位置元素之差的绝对值|pi-oi|表示从第i种美学风格的角度,产品图像所传达信息与用户反馈信息的差异大小;各个风格标签的|pi-oi|之和∑i|pi-oi|表示产品图像的整体美学风格与用户反馈的风格的差异大小;上述指标|pi-oi|和∑i|pi-oi|用于辅助评价产品在风格呈现方面的成功度,指标值越大,则产品图像与用户反馈的结果差异越大,产品在风格呈现方面越不成功。
优选的,所述多模态融合评价包括:将图像美学风格预测算法输出的风格预测值p和语义情感分析输出的风格倾向反馈值o进行比较后融合,得出综合的产品外观风格评价f=(f1,f2…f14),第i种美学风格的综合评价fi为pi和oi的融合结果:
f′i=(pi+oi)/(2*|pi-oi|)
fi=f′i/∑if′i
其中,pi表示该图像属于第i种风格的概率,oi表示用户反馈的对第i个风格的归一化倾向值。
根据本发明提供的基于图像和文本多模态数据的产品外观风格评价系统,包括图像美学风格模型、图像美学风格预测算法、语义情感分析模块和多模态融合评价模块;
所述图像美学风格模型为多层卷积神经网络模型,以彩色图像为输入,以多维的图像风格分类为输出;
所述图像美学风格预测算法用于进行预训练和迁移学习,预测产品图像的风格类型;
所述语义情感分析模块用于使用图像美学风格预测算法中的风格标签处理用户线上评论,计算用户反馈的产品风格倾向;
所述多模态融合评价模块用于融合图像美学风格预测算法输出的产品风格预测和语义情感分析输出的产品风格反馈,提供外观风格方面的产品评价结果。
与现有技术相比,本发明具有如下的有益效果:
(1)本方法融合了产品图像信息与用户反馈文本信息,基于数据建模与分析,能实现外观风格方面的产品评价,相比于传统的专家评定法具有更加客观、科学、准确的优点;
(2)本发明通过语义情感分析,能够对大量文本进行快速分析,在互联网大数据背景下有十分重要的作用;
(3)本发明通过多模态数据,融合了图像、文本、语音等不同模式的数据,多种信息源能够互相补充,对真实信息的反映相比单一模式数据更为准确。
附图说明
通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
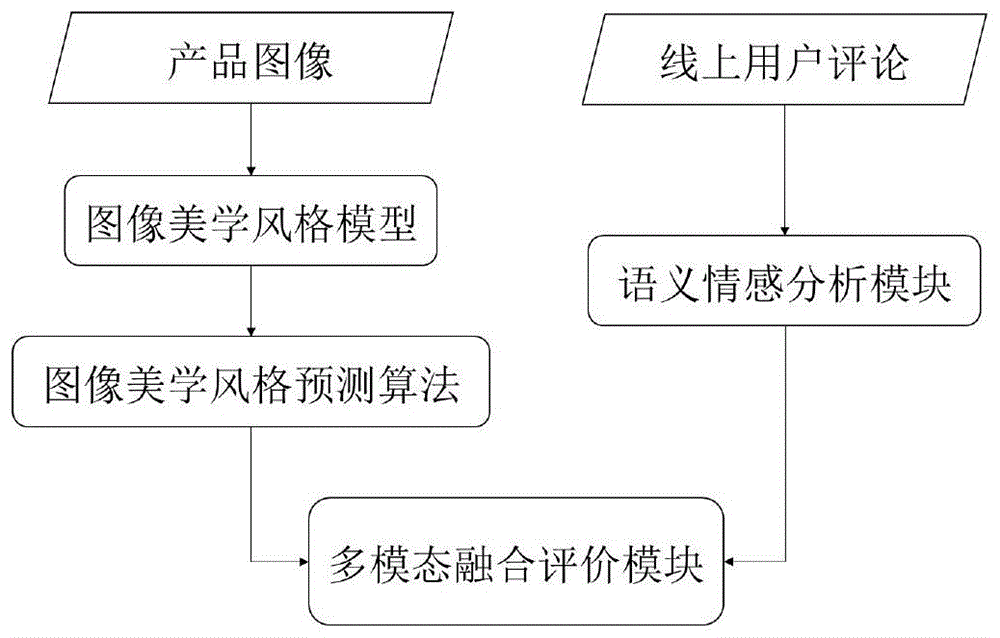
图1为本发明一种基于多模态数据的产品评价方法的流程图;
图2为本发明中图像美学风格模型的结构示意图。
具体实施方式
下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变化和改进。这些都属于本发明的保护范围。
实施例1:
根据本发明提供的基于图像和文本多模态数据的产品外观风格评价方法,包括构建图像美学风格模型,使用图像美学风格预测算法,进行语义情感分析和多模态融合评价;
所述图像美学风格模型为多层卷积神经网络模型,以彩色图像为输入,以多维的图像风格分类为输出;
所述图像美学风格预测算法用于进行预训练和迁移学习,预测产品图像的风格类型;
所述语义情感分析包括:使用图像美学风格预测算法中的风格标签处理用户线上评论,计算用户反馈的产品风格倾向;
所述多模态融合评价包括:融合图像美学风格预测算法输出的产品风格预测和语义情感分析输出的产品风格反馈,提供外观风格方面的产品评价结果。
如图2,所述图像美学风格模型包括依次连接的:
-输入层,输入为被缩放为224*224大小的彩色图像,输入维度为b*224*224*3,其中b为批大小batch_size;
-4个卷积层,卷积核大小为9*9,步长为1,卷积核数目为64,激活函数为relu函数;
-批归一化层;
-1个池化层,采用最大池化,池化大小2*2;
-3个卷积层,卷积核大小为7*7,步长为1,卷积核数目为64,激活函数为relu函数;
-1个池化层,采用最大池化,池化大小2*2;
-3个卷积层,卷积核大小为5*5,步长为1,卷积核数目为128,激活函数为relu函数;
-dropout层,dropout概率为0.1;
-批归一化层;
-1个池化层,采用最大池化,池化大小2*2
-3个卷积层,卷积核大小为3*3,步长为1,卷积核数目为128,激活函数为relu函数;
-1个池化层,采用最大池化,池化大小2*2;
-flatten层,将b*14*14*128维的特征图展为一维b*14*14*128长度的向量;
-全连接层,输出风格分类结果,标签数为14,分别对应14种风格标签,激活函数为softmax。
所述图像美学风格模型的损失函数为最小化交叉熵损失函数,使用adam优化器进行权重更新,学习率设为0.0001。所述图像美学风格预测算法采用迁移学习策略,首先在大型图像美学风格分类数据集ava上使用数据集的14种风格标签进行预训练,随后在特定产品领域下14种风格标签标注的小型产品图像风格数据集上进行微调,在无标签的测试集上进行测试;测试图像的图像美学风格模型预测输出为该图像的风格预测结果,为14维向量p=(p1,p2…p14),p满足:
∑ipi=1
其中,pi表示该图像属于第i种风格的概率。
所述语义情感分析模块,使用图像美学风格预测算法中的14个风格标签处理线上用户评论,使用wordnet语义词典的同义查找方法lemma_names分别找到14个风格标签的同义词,将各个风格标签扩充为风格词集,包括以下步骤:
步骤1:对第i个风格标签词,分别在wordnet中查找该词对应的语义集合synsetsi;
步骤2:对synsetsi中的第j个语义synsetij,使用lemma_names方法找到其同义词集合lemij;
步骤3:将第i个风格标签词对应的所有同义词集合lemij组成第i个风格词集seti:
seti=∪jlemij。
所述语义情感分析包括:将风格标签扩充为风格词集后,从线上电商平台上收集预设产品的线上用户评论,对评论文本进行清洗和预处理,包括以下步骤:
步骤1:文本收集,使用python库urllib进行自动收集线上用户评论;
步骤2:文本清洗,包括筛除重复的语句,筛除不属于预设语言的语句,筛除只包含非文本内容的语句,剔除拼写错误的词;
步骤3:文本预处理,包括将所有字符转为小写字母,剔除不符合规范的标点符号,剔除停用词,将所有动词转为现在时态。
所述语义情感分析模块包括:对评论文本清洗和预处理后,依次对文本中的每个单词使用wordnet提供的语义相似度计算方法lin_similarity分别计算与14个风格词集的相似度,处理完所有文本后,统计所有词的相似度结果,得到用户反馈的风格倾向结果,第k个单词wk与第i个风格词集seti的相似度simk,i计算公式为:
simk,i,t为第k个单词wk与第i个风格词集seti中第t个词的相似度:
其中,synsetkm为第k个单词wk的语义集合synsetsk中的第m个语义,synsetitn为第i个风格词集seti中第t个词的语义集合synsetsit中的第n个语义,lin_similarity为wordnet提供的语义相似度计算方法;
统计所有词的相似度计算结果,用户反馈的对第i个风格的归一化倾向值oi为:
o'i=∑ksimk,i
oi=o′i/∑io′i
最后得出产品的用户反馈的风格倾向o=(o1,o2…o14),作为语义情感分析的输出。
所述多模态融合评价包括:将图像美学风格预测算法输出的风格预测值p和语义情感分析模块输出的风格倾向反馈值o进行比较;
p和o的每个对应位置元素之差的绝对值|pi-oi|表示从第i种美学风格的角度,产品图像所传达信息与用户反馈信息的差异大小;各个风格标签的|pi-oi|之和∑i|pi-oi|表示产品图像的整体美学风格与用户反馈的风格的差异大小;上述指标|pi-oi|和∑i|pi-oi|用于辅助评价产品在风格呈现方面的成功度,指标值越大,则产品图像与用户反馈的结果差异越大,产品在风格呈现方面越不成功。
所述多模态融合评价包括:将图像美学风格预测算法输出的风格预测值p和语义情感分析输出的风格倾向反馈值o进行比较后融合,得出综合的产品外观风格评价f=(f1,f2…f14),第i种美学风格的综合评价fi为pi和oi的融合结果:
f′i=(pi+oi)/(2*|pi-oi|)
fi=f′i/∑if′i
其中,pi表示该图像属于第i种风格的概率,oi表示用户反馈的对第i个风格的归一化倾向值。
根据本发明提供的基于图像和文本多模态数据的产品外观风格评价系统,包括图像美学风格模型、图像美学风格预测算法、语义情感分析模块和多模态融合评价模块,如图1;
所述图像美学风格模型为多层卷积神经网络模型,以彩色图像为输入,以多维的图像风格分类为输出;
所述图像美学风格预测算法用于进行预训练和迁移学习,预测产品图像的风格类型;
所述语义情感分析模块用于使用图像美学风格预测算法中的风格标签处理用户线上评论,计算用户反馈的产品风格倾向;
所述多模态融合评价模块用于融合图像美学风格预测算法输出的产品风格预测和语义情感分析输出的产品风格反馈,提供外观风格方面的产品评价结果。
下面通过优选例对本发明进行更为具体的说明。
实施例2:
本发明基于图像美学分析和语义情感分析技术,借助当下发展成熟的线上电商平台,利用可快速获取的大量的产品图像和文本评论数据,进行数据建模分析,对产品图像风格进行自动预测,对评论文本进行自动的风格反馈分析,通过多模态数据的比较与融合,为外观风格方面的产品评价提供智能化的支持。
根据本发明提供的一种基于多模态数据的产品评价方法,包括以下步骤:
步骤1:构建特定产品领域的产品图像风格分类数据集。在互联网上收集特定产品领域的产品图像,参照ava数据集标准对美学风格进行人工标注后,进行数据增强步骤,形成小型的产品图像风格分类数据集;
步骤2:构建图像美学风格模型,使用ava数据集预训练模型,采用adam优化器,采用默认的学习率0.0001;
步骤3:使用构建的产品图像风格分类数据集微调模型,采用adam优化器,采用默认的学习率0.00005;
步骤4:在无标签的产品图像数据集上测试模型,产品图像对应的美学风格预测输出即为该产品图像的风格预测值p;
步骤5:根据图像美学风格预测算法中的14个风格标签,使用语义词典wordnet的lemma_names方法将各个风格标签扩充为风格词集seti;
步骤6:从amazom.com电商平台上收集用户评论,进行文本清洗和预处理;
步骤7:计算与统计所有单词分别与14个风格词集的相似度结果,得出某款产品的用户反馈的风格倾向o;
步骤8:比较风格预测值p和风格倾向反馈值o,得出产品外观的风格呈现成功度的相关结论,融合风格预测值p和风格倾向反馈值o,得到综合的产品外观风格评价f。
步骤1所述的构建产品图像风格分类数据集,产品图像的来源包括电商平台的商品描述、博客和相关产品的论坛等,产品图像被收集后统一缩放为224*224大小,参照的ava数据集的美学风格共有14种,数据增强步骤能够在不影响质量的情况下扩大数据集规模,增大数据的多样性,包括随机的旋转、裁剪操作。
步骤2所述的图像美学风格模型结构依次为输入层、依次堆叠的卷积层和池化层、全连接层和输出层,损失函数为最小化交叉熵损失函数。使用tensorflow和keras深度学习框架进行搭建。
步骤3所述的在步骤2的基础上使用产品图像风格分类数据集微调模型,由于步骤2的预训练使模型能够有效提取低层图像特征,微调所需要的数据集较小,并且使用较少的训练周期数即可达到可接受的测试集准确率。
步骤4所述的无标签的产品图像数据集包含与后续用户评论处理对应的产品图像,步骤3所给出模型根据输入的产品图像输出14种风格的预测值p,输出层的softmax函数使14个风格的预测值pi之和为1。
步骤5所述的将风格标签扩充为风格词集seti,首先用wordnet的语义查询方法获取第i个风格标签词的所有语义,然后遍历所有语义,使用wordnet的lemma_names方法查询得各语义的同义词,将第i个风格标签词的所有同义词归纳为它的风格词集seti。同义词组将以“_”符号相连归纳于风格词集中,在步骤6使用风格词集时,包含“_”符号的词仍以单词形式处理,wordnet的内置机制能够兼容地处理单词语义和词组语义。wordnet语义词典使用python语言提供的nltk(naturallanguagetoolkit)库运行。
步骤6所述的amazom.com电商平台上用户评论的收集、清洗和预处理,使用urllib库、nltk库和beautifulsoup库运行,用户评论应与图像美学风格预测所用的产品图片相对应。首先将使用urllib库获取电商平台用户评论网页的源代码,使用beautifulsoup库进行解析,提取出所有已验证用户的评论文本内容,通过对比文本内容筛除重复的语句,然后使用wordnet语义词典查找所有单词,此时不属于英语单词的词、拼写错误的词、表情符号等由于无法在wordnet中查找到而被筛选出来,经过人工筛选,筛除相应评论语句和剔除拼写错误的词。使用nltk库对清洗后的用户评论预处理,将所有字符转为小写字母,将单个或多个连续”!”、多个连续“.”、“;”、单个或多个连续“?”均转为句分隔符”.”,整理一些无特定含义或冗余、或易造成误解的词为停用词,将用户评论中属于停用词的单词剔除,最后将所有动词转为现在时态。
步骤7所述的计算每个单词分别与14个风格词集的相似度,单词与风格词集的相似度为该单词与风格词集中的单词相似度的最大值,单词与单词之间的相似度为两单词的语义集合之间的由lin_similarity方法计算出的最大相似度。统计所有单词分别14个风格词集的相似度simk,i作为用户反馈倾向结果,用户反馈的风格倾向值oi为所有单词与该风格的风格词集相似度simk,i之和,在所有风格之间归一化的结果,归一化使得用户反馈的14个风格的风格倾向值oi之和为1。
步骤8所述的比较风格预测值p和风格倾向反馈值o,每种风格的预测值和反馈值越接近,则风格呈现越成功,产品的外观风格呈现成功度为两向量p和o的l1距离。融合风格预测值p和风格倾向反馈值o需要综合考虑两者的平均值和距离,最终的外观风格评价结果f的元素fi为oi和pi的平均值与距离之商,在所有风格之间归一化的结果,归一化使得融合的14个风格的评价值之和为1。
本领域技术人员知道,除了以纯计算机可读程序代码方式实现本发明提供的系统、装置及其各个模块以外,完全可以通过将方法步骤进行逻辑编程来使得本发明提供的系统、装置及其各个模块以逻辑门、开关、专用集成电路、可编程逻辑控制器以及嵌入式微控制器等的形式来实现相同程序。所以,本发明提供的系统、装置及其各个模块可以被认为是一种硬件部件,而对其内包括的用于实现各种程序的模块也可以视为硬件部件内的结构;也可以将用于实现各种功能的模块视为既可以是实现方法的软件程序又可以是硬件部件内的结构。
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变化或修改,这并不影响本发明的实质内容。在不冲突的情况下,本申请的实施例和实施例中的特征可以任意相互组合。
- 还没有人留言评论。精彩留言会获得点赞!